科研学习|论文解读——Task complexity and difficulty in music information retrieval
摘要:
关于音乐信息检索(MIR)中任务复杂度和任务难度的研究很少,而文本检索领域的许多研究发现任务复杂度和任务难度对用户效率有显着影响。本研究旨在通过探索 i) 任务复杂度和任务难度之间的关系; ii) 影响任务难度的因素; iii) MIR中任务难度、任务复杂度和用户搜索行为之间的关系来弥补这一差距。采用一种新型的MIR系统,对51名参与者进行了实证用户实验。参与者在3个复杂级别上搜索6个主题。结果表明:i) 音乐搜索中的感知任务难度受任务复杂度、用户背景、系统支持度、任务不确定性和愉快性等因素影响; ii) MIR中感知到的任务难度与发现歌曲数量、点击次数和任务完成时间等效率指标显着相关。这些发现对音乐搜索任务的设计(在研究中)或用例(在系统开发中),以及未来的基于用户效率指标来检测任务难度的MIR系统都有意义。
1 引言
音乐信息检索 (MIR) 作为一个研究领域在近几十年蓬勃发展,开发了许多方法来利用新的搜索技术,如音频指纹和模式匹配 (Downie, 2003; Downie et al,2014; Schedl, Gomez&Urbano, 2014)。MIR系统对用户音乐搜索行为的影响尚未得到充分研究(Hu & Kando, 2012, 2014;Hu et al,2015;Lee & Cunningham, 2013)。特别是,目前还没有研究关注MIR中的任务复杂度或任务难度,也没有研究它们对音乐搜索中用户交互的影响,尽管在文本信息检索 (IR) 领域已经发现,任务复杂性和难度可以影响信息的寻找和使用 (Bystr€om & J€arvelin, 1995; Kelly, Arguello, Edwards, & Wu, 2015; Liu, Liu, Gwizdka, & Belkin, 2010; Wildemuth & Freund, 2009; Wildemuth, Freund, & Toms, 2014)。虽然这两个概念有时在文献中被交替使用,但区分任务复杂度和任务难度是很重要的。在本研究中,我们采用了Wildemuth等人 (2014) 的说明,即任务复杂度是由研究人员或专家根据现有的认知复杂性框架设计和商定的,因此被认为是客观的;而任务难度是指用户对任务难度的感知。
本研究旨在探讨音乐搜索情境下的任务复杂性和任务难度对用户音乐搜索效率的影响。在受控环境中进行了一个任务驱动的用户实验。任务是根据认知复杂性框架设计的(Arguello, Wu, Kelly, & Edwards, 2012;Krathwohl, 2002)。使用一种新的MIR系统从搜索会话中收集用户行为数据。通过问卷调查和焦点小组访谈收集用户背景和看法。通过对定量和定性数据的分析,回答以下研究问题:
RQ1:用户对任务难度的感知是否与音乐搜索中的任务复杂度相关?
RQ2:用户、MIR系统和任务的其他哪些因素也会影响用户对任务难度的感知?
RQ3:音乐搜索中任务复杂度、任务难度、用户效率和满意度之间的关系是什么?
前两个问题旨在找出任务难度的构成,以及文本检索中对任务复杂度和任务难度的发现是否也适用于MIR领域。一方面,音乐搜索,类似于搜索其他信息,确实涉及搜索者的认知负荷。另一方面,音乐搜索可能是以娱乐为导向的(Hu & Kando, 2014; Laplante & Downie, 2011),因此搜索者可能对什么是困难有不同的解释。第三个问题旨在调查任务复杂度、任务难度、用户效率和用户满意度之间可能存在的关系。这项研究的结果可能有助于我们进一步理解为什么音乐搜索中的任务是困难的,并为未来的MIR研究中确定任务难度提供方法上的影响。
2 相关工作
2.1 文本检索中的任务复杂度和难度
近年来,在文本IR领域,人们一直在积极研究任务复杂度和任务难度的评估,以及它们与搜索结果和用户行为的关系。许多研究已经考察了任务复杂度的增加如何影响搜索过程、搜索者的表现以及搜索结果。Bystr€om和J€arvelin (1995)提出了一个从自动化信息处理任务到真正的决策任务的不同复杂程度的任务分类框架。作为一项概念性研究,揭示了任务复杂性、信息类型、信息渠道和信息来源之间的关系。根据这个框架,Bailey、Moffat、Scholer和Thomas (2015) 最近的一项研究将文本检索会议 (TREC) 中过去的主题重新分类为三类任务复杂性:记忆、理解和分析。
其他研究则着手测量用户在不同复杂度的任务下的搜索行为。Aula, Khan, & Guan (2010) 的研究发现,当搜索任务更加复杂时,用户的搜索行为会变得不那么系统。用户改变了他们的搜索方法,在结果页上花费了更多的时间,或者为困难的任务制定了更多的查询 (可用于录屏内容)。最近的一项研究 (Arguello et al, 2012) 显示,更复杂的任务需要用户和系统之间有明显更多的互动。除了任务的复杂度,感知到的任务难度也被证明对搜索行为有重大影响。在Kim (2006) 的研究中,发现用户对任务难度的感知是探索性和事实性任务中搜索有效性的一个很好的指标和预测因素,这一点由查询重构的数量、花费的时间和浏览的页面来反映。Haerem和Rau (2007) 研究了任务难度和用户专业知识之间的关系。发现新手和专家在具有不同目标和感知任务难度的任务中表现出不同的表现 (年级可否换成社会阅历?)。最近,Liu等人 (2010) 调查了用户的搜索行为和任务难度。他们发现用户不仅在困难的任务上花费更多的时间,而且还发出更多的查询,查看更多的检索项目,并在检索项目上花费更多的时间。
为了总结以前关于任务复杂度和任务难度的研究,Wildemuth等人 (2014) 回顾了交互式信息检索(IIR)的106篇论文,研究了这些研究中如何定义“任务复杂度”和“任务难度”的概念以及任务描述。尽管在文本IR领域对这一主题的研究很活跃,但对MIR中的任务复杂度和任务难度的研究却很少。在这项研究中,我们旨在通过探索和评估任务复杂度、任务难度、它们对搜索行为的影响以及对 MIR 任务和系统设计的影响来弥合这一差距。
2.2 音乐信息检索中的任务
已经有一些用户研究涉及MIR中的各种搜索任务。Iwamura (2001) 的一项早期研究探讨了在只知道旋律的情况下搜索歌曲标题的可能性,并发现这并不是一件容易的事。Salaba和Zhang (2012) 的一项研究调查了给定的MIR系统支持两种用户任务的程度:规定任务 (例如,根据标题确定作品) 和用户根据个人兴趣自行分配的开放任务。尽管结果表明开放式任务的失败次数比规定的任务多,但该研究并未明确讨论任务复杂性或难度的问题。最近,Music Information Retrieval Evaluation eXchange (MIREX) 举办了第一次用户体验大挑战 (GC14UX),其中三个新颖的MIR系统通过最终用户的交互进行了评估 (Hu et al., 2015)。这是MIREX中首次使用用户任务。任务是“为用户自己创作的一个关于难忘时刻的短视频寻找背景音乐”(第5页),目的是灵活和真实地反映用户的生活。
其他研究在用户需求评估的背景下探索了不同的任务 (Lee & Cunningham, 2013)。为了设计用于系统评估的真实音乐搜索任务,许多研究分析了用户在搜索音乐时提出的查询。Downie和Cunningham (2002) 通过分析发布在一个流行音乐新闻组上的与音乐有关的请求,研究了用于描述音乐信息需求的特征。他们发现人们经常通过书目描述(如标题、艺术家)、歌词、流派、类似作品和情感(即心情、情绪)来搜索音乐。Lee(2010)沿着这条研究路线,分析了一个问答网站上发布的音乐查询。研究结果显示,大多数查询都是已知项目的搜索,有各种各样的描述性信息,包括知道或听过这些项目的背景情况。随后的一项研究 (Lee & Waterman, 2012) 对音乐用户进行了大规模调查,并确定了用户对音乐服务的需求。基于这些发现,最近一项关于MIR评估的研究综合了一份音乐使用场景清单,在此基础上可以开发音乐搜索任务,比如听音乐录音、发现新音乐、创建播放列表/电台等。(Hu et al,2015)。
然而,这些研究都没有考虑任务复杂度和任务难度在MIR过程中的构念,也没有考虑它们对用户搜索行为的影响。由于音乐搜索任务复杂度和任务难度的含义在文本IR和MIR中可能存在差异,本研究将探讨音乐搜索任务复杂度和难度之间的关系,并得出其原因和影响。
3 研究设计
为了回答研究问题,我们用不同复杂程度的任务和一个新的MIR系统进行了一个用户实验。本节描述了系统、任务、措施和实验程序。
3.1 系统
Moodydb是一个由研究小组内部开发的新型MIR系统 (Hu, Kando, & Yuan, 2011; Hu, Sanghvi, et al., 2008)。它是一个基于网络的音乐情绪分类和检索系统。它是基于内容的,因为它从音乐音频中提取突出的频谱特征 (如Mel-frequency Cepstral Coefficients,Casey et al,2008),并自动将音乐作品分为五个情绪类别:热情的、欢快的、苦乐参半的、愚蠢/古怪的和攻击性的。自2007年以来,这五个类别一直被用于MIREX的音频情绪分类 (AMC) 任务 (Hu, Downie, Laurier, Bay, & Ehmann, 2008)。对于自动分类,Moodydb采用了Weka工具包中支持向量机的顺序最小优化 (SMO) 实现 (Witten & Frank, 1999)。Moodydb还支持通过情绪相似性来检索音乐,情绪相似性是通过歌曲的情绪特征之间的距离来计算的。给定一首种子歌曲,Moodydb会返回一组具有相似情绪的歌曲,并在屏幕上显示这些歌曲和它们的专辑封面。关于该系统的技术细节,请参考Hu, Sanghvi et al (2008) 的文章。
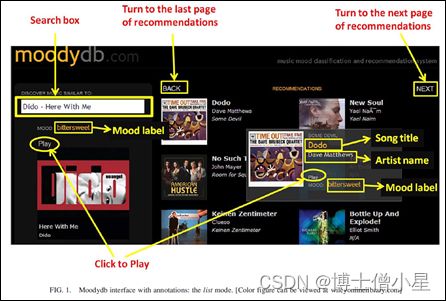
当用户开始使用Moodydb时,他或她在搜索框中输入部分歌名或艺术家名字。Moodydb具有自动完成功能,并显示与文本查询相匹配的歌曲列表。在用户选择其中一首歌曲作为种子歌曲后,Moodydb将检索出一组与种子歌曲有相似情绪的歌曲作为推荐。然后,用户可以检查和播放这些歌曲。当光标悬停在一首推荐歌曲上时,会出现一个小面板,显示该歌曲的详细信息,包括基本元数据 (如标题、艺术家)、基于内容的情绪分类器分配的情绪标签、专辑封面和一个“播放”按钮。由于知识产权的限制,在Moodydb中播放的每个音频片段被限制在一首歌中间的30秒摘录。
Moodydb提供了两种呈现推荐歌曲的模式,列表模式和视觉模式,如图1和图2所示。在列表模式中,推荐的歌曲被安排在两列中,根据它们与种子歌曲的情绪相似度,从页面的顶部到底部进行排序。一首歌曲列得越高,它就被确定为与种子歌曲越相似。在一排的两首歌曲之间,左边的歌曲比右边的歌曲更相似。每个页面上最多有10首推荐歌曲。视觉模式使用专辑图像的大小来表示相似程度。一首歌曲的专辑图片越大,它被确定为与种子歌曲越相似 (Hu, Kando, & Yuan, 2011)。本研究中提出的实验将两种模式分配给相同数量的参与者,并比较了使用两种模式进行搜索的感知任务难度。

Moodydb中有750首歌曲,主要由西方流行歌曲组成。我们承认,与商业音乐服务相比,音乐收藏是有限的,因为它受到研究人员所拥有的音乐音频文件的限制。尽管存在此限制,但使用该系统有几个原因:i) 心情是用户搜索音乐的一个重要入口 (Lee & Downie, 2004; Lee & Waterman, 2012; Vignoli, 2004),而现有的支持按心情搜索音乐的系统很少;ii) 使用内部系统可以控制系统功能,如不同的可视化模式;iii) Moodydb已经在以前的研究中使用过 (Hu, 2011; Hu & Kando, 2014),因此使用同一系统可以进行跨研究比较;以及iv) 可以获得服务器端的日志以进行更详细的分析。例如,每个用户在每个任务上的完成时间和歌曲播放时间都准确地记录在服务器日志中。
3.2 任务
由于对MIR中任务复杂度和任务难度的研究很少,本研究采用了Krathwohl的认知复杂性框架 (2002)。它在教育领域被广泛认可,并被用于交互式IR (Arguello et al, 2012; Kelly et al, 2015)。在这个框架中,最低的层次是“记住”,这涉及到事实调查任务。下一个层次是“理解”,即“通过解释、推断、比较和/或解释来确定信息的含义” (Kraswohl, 2002, p.215)。第三个层次是“分析”,这个层次的任务更加复杂,它涉及到区分材料的各个部分,检测各部分之间以及各部分与整体之间的关系。
在设计任务时,也有必要考虑Moodydb系统的承受力:Moodydb的“决定它如何被使用”的特性 (Norman, 1988, p.9)。首先,Moodydb是一个推荐系统,因此涉及歌曲推荐的任务将是最合适的。第二,歌曲的一些特征没有显示在界面上,但可以作为音乐搜索的标准,如声音的性别或节奏/速度。使用这些作为选择标准会涉及到对歌曲的一定程度的理解,从而导致更高的任务复杂性。第三,一首歌曲可以有很多方面,如情绪、流派、节奏等。一个涉及对这些多个方面进行评价的任务可以进一步提高复杂性,达到“分析”的水平。表1中列出了三个认知层次的设计任务。
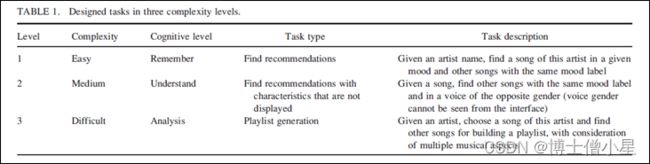
Level 1任务旨在使用给定标准查找歌曲,这些标准可以从系统界面上显示的元数据进行评估。它只需要用户寻找情绪标签,而不需要听或评估歌曲。Level 2任务更进了一步,要求用户听歌,根据听到的音乐做出判断。这个任务近似于认知框架中的“理解”水平,尽管什么构成“理解”一段音乐仍然是一个悬而未决的问题 (Levitin,2011)。人们可能认为“理解”音乐需要了解音乐的主题或主题和/或能够辨别音乐的特征,例如旋律、速度和/或乐器。然而,除了用户熟悉的歌曲外,音乐主题往往很难在短时间的聆听中判断。此外,对于普通用户来说,一些音乐特征 (例如乐器、音高) 可能难以判断。因此,Level 2任务中的判断设计得足够简单,以至于判断不需要经过深思熟虑的思考,这可能会使任务过于复杂。Level 3任务涉及更深思熟虑的判断,因为它要求用户生成一个播放列表,要求检索到的歌曲在某种程度上是连贯的。它还需要考虑多个音乐方面。因此,Level 3任务可以被视为处于“分析”层次。
对于每项任务,设计了两个主题来平衡由音乐熟悉度和偏好引入的可能偏见。在对任务进行量化时,还有进一步的考虑。首先,我们试图包括著名的艺术家,使主题对参与者更有趣,从而更接近现实生活中的经验(Hu et al, 2015)。第二,研究人员试图平衡女性和男性艺术家。第三,由于数据集有限,研究人员试图将有多首歌曲的艺术家纳入系统,这样参与者可以有更多的选择自由,使话题更接近真实世界的情况。最后,所有级别的题目都要求有三首歌曲 (答案),以使各任务的衡量标准 (如任务完成时间) 具有可比性。表2显示了每个任务中的题目。

3.3 测量
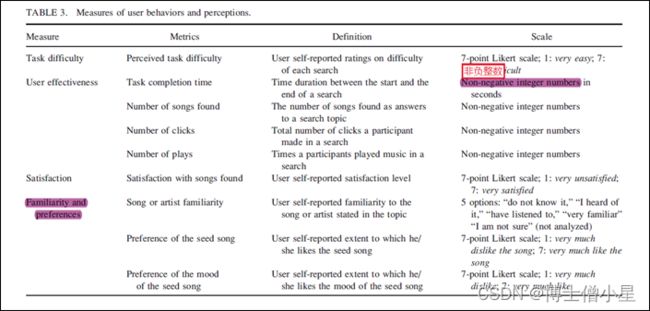
为了回答研究问题,我们收集了用户感知的任务难度、用户效率、满意度以及用户对歌曲的熟悉度和偏好的度量。这些指标、定义和量表见表3。参与者交互由开放式Web分析 (OWA) 跟踪工具记录 (http://www.openwebanalytics.com/),并根据日志计算用户交互指标。
3.4 实验流程
实验以分批方式进行,每批有6到9名参与者同时进行任务。参与者在实验开始时填写了一份实验前调查问卷,在实验结束时填写了一份实验后调查问卷。实验前的问卷收集了人口统计信息、计算机和搜索专业知识以及音乐背景信息。实验后的调查问卷询问了参与者在搜索过程中的一般经验。
在进行任务之前,有一个10分钟的关于如何使用Moodydb系统的培训课程。参与者有机会练习使用该系统并提出问题。每个参与者都被分配到表2中的所有六个主题。主题的顺序和复杂程度是使用希腊-拉丁方设计随机分配的,这样 i) 1/3的参与者分别从 Level 1、Level 2 和 Level 3 的题目开始; ii) 每一层的两个题目依次排列,以减少不同层级题目之间来回切换的认知负担; iii) 每个级别的两个题目在参与者之间交替位置 (例如,一半的参与者在题目2之前搜索题目1,另一半在题目1之前搜索题目2) 。一半的参与者使用了两种演示模式中的每一种。在搜索每个题目后,参与者完成了一份包含用户感知问题的搜索后调查问卷。参与者提交答案的在线系统促进了题目切换。在完成所有六个题目后,对每批参与者进行了小组访谈,就任务和搜索过程征求了详细的意见。整个过程持续了大约1.5小时,每个参与者都可以控制在每个任务上花费的时间。参与者在实验前签署同意书,并在实验后支付象征性费用。
4 结果和讨论
4.1 参与者
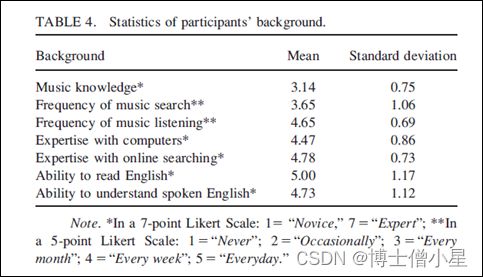
参与者是通过香港大学的广告以及研究人员社交网络的Facebook账户招募的。为了避免不同文化背景可能带来的偏见,要求参与者在香港出生和长大,能说和听懂粤语。共有51名参与者(28名女性)分8个批次加入实验。他们的平均年龄为20.9岁,专业包括社会科学 (13)、科学 (13)、工程 (7)、商业 (7)、艺术 (7)和医学 (4)。表4显示了参与者在音乐知识、音乐聆听、搜索以及计算机和英语技能方面的背景统计。由于大多数歌曲都有英文歌词,所以收集了自我报告的英语能力。
RQ1:任务复杂度与用户感知的任务难度
由于这两个指标都是顺序量表,计算了Spearman的等级相关系数,结果显示任务复杂度和感知任务难度之间存在显著的相关关系:ρ=0.442 (p<.001)。该值为中等相关性 (Corder & Foreman, 2009),与IR研究 (如Kelly et al.(2015)报道的相关性为0.413) 相当。应用Kruskal-Wallis测试,观察在不同复杂程度的任务中,用户对任务难度的感知是否存在差异。结果表明,感知任务难度在不同的任务复杂度水平上存在显著差异(p<.001)。后续的两两比较表明,用户感知的任务难度在复杂度Level 1级别 (median = 2) 的任务显著低于复杂度Level 2和Level 3的任务 (median=3;p <.001)。这一结果验证了基于认知复杂性框架设计的任务复杂度在一定程度上与用户感知的难度匹配,低复杂度的任务被认为比其他任务更容易。正如一位受访者在焦点小组访谈中所反映的:
- 更困难的是那些有更详细说明的...然后你必须知道他们的情绪、节拍和节奏之类的。(参与者8对Level 3任务的评论)
然而,在复杂度Level 2和Level 3级别的任务之间感知的任务难度没有显着差异 (p=5.483)。根据“任务”部分中描述的任务设计,Level 3级别的任务涉及在多个方面比较多首歌曲,而Level 2级别的任务侧重于歌曲的一个方面 (即声音性别),而不考虑歌曲之间的相互关系。因此,根据认知负荷框架,这两个任务确实处于不同的复杂程度。他们被认为具有相似难度的结果似乎表明还有其他因素影响用户感知的任务难度。同样,在IR研究中,也发现用户并不总是认为认知更复杂的任务更困难 (Kelly et al., 2015)。参与度、享受度和用户期望等其他因素被提及可能与任务难度相关 (Kelly et al., 2015),用户特征 (如领域知识) 以及系统因素 (如语料库覆盖率) 也是如此 (Liu, 2015;Wildemuth et al., 2014)。我们将在以下小节中进一步分析这些因素。
RQ2:影响任务难度的用户和系统因素
用户背景
检查参与者的背景与感知任务难度的可能关系,包括人口统计信息 (例如性别、年龄)、自我报告的音乐知识、计算机知识、在线搜索能力等。每个用户进行六次搜索时,对这些搜索中的每一个的感知困难进行平均。对于二元变量、性别和演奏乐器的能力,进行了Mann-Whitney Utests,结果显示两组之间的感知任务难度没有显着差异 (性别, p=.917; 演奏乐器能力, p=.169)。还比较了参与者的学习专业,结果表明差异不显着:要么有四个主要群体 (艺术、科学、社会科学、商业、p=.135, Kruskal-Wallis),要么有两个主要群体 (硬科学、其他、p=.233、Mann-Whitney)。
对于序数 (例如,音乐搜索的频率) 和数字 (即年龄) 变量,计算了任务难度和用户自述背景在各个方面的 Spearman 等级相关系数。 结果 (表5) 表明,感知任务难度与音乐知识中度相关 (r=.334),与用户年龄(r=-.280)弱相关 (Corder & Foreman, 2009)。 有趣的是,与音乐知识的相关性是正相关的,这意味着用户觉得他们对音乐的了解越多,她/他倾向于报告的难度就越大。也许这些用户在搜索过程中基于他们更丰富的音乐知识有更多的考虑。用户的年龄与平均感知难度呈负相关,表明年轻用户比老年用户感知到的难度更大。鉴于相关性相当弱的事实,有必要进一步研究年龄对 MIR 中感知任务难度的可能影响。

还计算了感知任务难度与用户偏好和熟悉程度之间的Spearman's相关关系。在P=.05的水平上,没有明显的相关关系。换句话说,歌曲偏好、情绪偏好或对种子歌曲/艺术家的熟悉程度并不影响用户感知的任务难度。
系统因素
由于Moodydb系统中有两种可视化模式,因此使用Mann-Whitney 测试来比较使用这两种可视化模式时用户感知的任务难度,结果表明没有显着差异(p=.183)。 通过分析焦点小组讨论来确定其他与系统相关的因素,在这些讨论中,用户被问及他们对给定搜索题目的感觉有多难或容易,以及为什么。与系统功能相关的问题经常被提及。下面的第一句话显示了对系统没有显示任务所需信息的抱怨。第二句是关于情绪标签的不准确性。
- 有一些任务要求我们找到一首女声但原曲是男声的歌曲,我觉得很难找到特定的人声,因为系统无法提供这样的细节,我必须点击播放,播放,播放以寻找所需的歌曲。 (参与者3评论 Level 2级别任务)
- …但是只有5个情绪标签,然后我发现很多歌曲都有攻击性,苦乐参半的情绪标签,但歌曲可能不属于攻击性类别… (参与者2评论Level 3级别任务)
也有人提到了音乐收藏的规模,一些参与者认为,如果音乐收藏的规模更大,任务可能会更容易:
- 我发现“Cold Play, Fix U”是最难的,要找一个情绪相近的女声,因为它很难找,我必须点击每一页,结果有限,所以我觉得更难。(参与者30评价Level 2级别任务)
总之,任务难度可能受到Moodydb提供的信息的充分性和准确性以及音乐收藏的规模的影响。未来的研究需要对这些可能的因素进行量化。
任务相关因素
有趣的是,复杂度Level 2级别 (“理解”) 和Level 3级别 (“分析”) 的任务被认为具有相似的难度。 在焦点小组中,这两项任务被称为最困难的任务的次数大致相同 (Level 2级别和Level 3级别任务分别为16次和13次)。对于Level 2级别任务,除了缺乏系统提供的语音性别信息 (文本或视觉) 外,参与者还提到区分语音性别本身可能并不总是直接的 (Weninger、Wollmer & Schuller, 2011)。
- 当我看相册的时候,我看到相册上有一个女性或男性,然后我发现有些相册上没有人,只有图片,所以我认为这是更困难的任务。(参加者26评论Level 2级别任务)
- 我不能通过表演者的名字来识别,我需要听,有时我无法核实西方 (歌手) 的声音,因为一些女性也有一个较低的声音,我不确定。(参加者28评论Level 2级别任务)
Liu (2015) 认为,没有直截了当的答案是任务难度的19个原因之一。MIR也不例外。当没有给出明显或准确的答案时,用户必须更仔细地倾听才能做出符合任务要求的判断。
Level 3级别任务的汇报略有不同。除了涉及音乐多个方面的固有认知复杂性外,一些参与者还提到了必须依赖个人偏好的不确定性。
- 这是最困难的,因为我不知道该选择什么。(参与者31评论Level 3级别任务)
值得注意的是,不确定性绝不是所有用户遇到困难的原因。对于某些用户来说,不确定性意味着乐趣而不是困难或挫折 (见下文)。Liu的框架 (2015) 也包括了任务的不确定性,并将其归入用户与任务的互动方面,表明其对用户的依赖性。
参与者还提到了愉快性。他们指出,当他们喜欢一项任务时,其难度就会降低,即使该任务在设计上很复杂。
- 播放列表任务更容易…我可以听歌,我有点喜欢享受它。(参与者10 评论Level 3级别任务)
这一观察结果与音乐信息搜索中确定的享乐性质一致 (Hu & Liu, 2010; Hu et al., 2015; Laplante & Downie, 2011)。在这项研究中,虽然许多参与者评论说Level 3级别任务很有趣,但没有人认为Level 2级别任务很有趣。他们中的一些人甚至认为Level 2级别任务是“最不愉快的”。这项任务令人不快的性质可能使它看起来更加困难,即使它的复杂程度在设计上是中等的。为了进一步验证,我们计算了任务难度、用户效率和任务满意度在不同复杂度水平之间的Spearman相关性。显著性结果如表6所示(52个人)。对于所有任务,当任务难度增加时,会涉及更多的点击和播放。Level 2级别任务的任务完成时间与任务难度呈中度正相关,而Level 3级别任务则没有这种相关性。也就是说,在Level 2级别任务上花费时间越长的用户会觉得这个任务越难,但是当他们在Level 3级别任务上花费的时间越多时,他们就不一定觉得难了。这些观察表明音乐检索中“任务完成时间”指标的一个新方面。与文本IR类似,我们也可以为消极的用户效率和更高的任务难度设置一个度量,但对于那些令人愉快的任务却没有这样的度量,如Level 3级别中的任务。当任务令人愉快时,任务完成时间可能不一定表明用户效率或与感知困难有关。
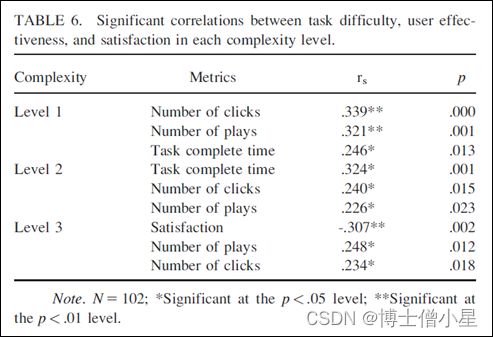
值得注意的是,满意度仅与Level 3级别任务的任务难度呈负相关。当用户对Level 3级别任务的答案感到更满意时,他们会报告任务更容易。然而,对于Level 2级别任务,用户满意度与任务难度无关。换句话说,即使他们对答案感到满意,他们可能仍然觉得任务很困难。我们推测这种差异可能归因于任务被认为不愉快的事实。
RQ3:任务复杂度、感知任务难度、用户效率和满意度
计算 Spearman 等级相关系数以研究任务复杂度/难度与用户效率/满意度测量之间可能存在的关系。 显着的相关系数如表7所示,按相关强度排序。

表7中的系数显示出中等 (|0.3|
任务复杂度和感知任务难度都与点击次数、播放次数和任务完成时间密切相关。值得注意的是,与任务复杂度的相关性强于感知任务难度的相关性。 另一方面,任务复杂度和感知难度都与检索到的歌曲数量或满意度无关。 为了进一步了解这种关系,图3和图4分别显示了跨任务复杂度和感知任务难度的用户效率和满意度度量的箱线图。
任务复杂度
应用单因素方差分析 (ANOVA) 来分析用户效率指标在不同任务复杂度级别的任务之间是否存在显着差异。结果显示所有这些效率指标存在显着差异。对于任务完成时间 (F=31.11, p<.001),Level 1级别和Level 3级别 (p<.001) 以及 Level 2级别和Level 3级别 (p<.001) 之间存在显着差异。平均而言,用户在Level 3级别完成任务的时间明显长于 1 级 (多180.15秒) 和Level 2级别 (多140.03秒)。尽管Level 1级别和Level 2级别之间的差异不显着 (p=.217),但平均而言,Level 2级别任务比Level 1级别任务花费的时间更长 (多 40.57秒)。结果表明,设计的任务复杂度水平确实对用户的任务完成时间有影响。设计的任务越复杂,用户完成任务所需的时间就越长。
对于找到的歌曲数量 (F=15.88, p <.001),虽然任务只要求三首歌曲,但在许多情况下,用户写下了三首以上的歌曲。后续配对比较表明Level 1级别和Level 2级别之间 (均值差异为 0.41, p<.001) 以及Level 3级别和Level 2级别之间 (均值差异为 0.39, p<.001) 之间存在显着差异。有趣的是,Level 1级别和Level 3级别的任务找到的歌曲数量相似 (平均 53.41和3.39, p=.969),而Level 2级别任务平均得到更少的答案 (平均 53.00)。虽然预计可以为最不复杂的任务找到更多歌曲,但令人惊讶的是,Level 3级别任务 (设计上最复杂的任务) 没有得到更少的答案。
对于点击次数 (F=45.05, p<.001) 和播放次数 (F=45.60, p<.001),事后比较显示所有配对之间存在显着差异。从图 3c、d 可以看出,这两个指标的值随着任务复杂程度的增加而增加。换句话说,更复杂的任务确实涉及更多的用户点击和歌曲播放。
通过Kruskal-Wallis测试来比较不同任务复杂度水平的用户满意度,结果不显著(p=.922)。在不同的任务复杂度中,用户普遍相当满意(所有级别的中位数为55,图3e)。

感知任务难度
与任务复杂度类似,进行了单因素方差分析 (ANOVA),结果表明所有用户效率指标在感知任务难度等级之间存在显着差异。对任务完成时间的事后测试 (F=7.56, p<.001) 显示,感知任务难度等级1级别 (即最低难度) 的任务所花费的时间明显少于感知难度等级 3及以上的任务。同样,等级2的任务比等级5及以上的任务花费的时间更少。没有其他显著的配对。
关于找到的歌曲数量的事后测试 (F=4.21, p<.001)发现,感知任务难度等级为5的任务比等级为3的任务得到了更多的歌曲。此外,等级为7的歌曲比第1、2、3、4和6级的歌曲要少得多。这些结果表明,发现的歌曲数量对感知到的任务难度的影响没有一致的模式(图4b),除了用户在感知到的7级 (最难) 的主题中找到的歌曲较少这一事实。
对于点击次数 (F=10.90, p<.001),除了感知任务难度等级7外,用户在难度等级较高的主题上有更多的点击次数(图4c)。对于播放次数 (F=10.26, p<.001),用户播放级别1和级别2的歌曲少于级别5、6和7。用户感知满意度的Kruskal-Wallis测试显示,不同任务难度等级之间存在显著差异 (p=0.03),但事后比较没有发现任何在p=0.05水平上存在显著差异的配对。这意味着测试的功效很低, 可能是由于样本量较小 (n范围从6(等级7)到69(等级2)。然而,从箱线图 (图4e),我们可以看到,难度较高级别 (5、6、7) 的满意度中值低于难度较低级别 (1、3、4)。
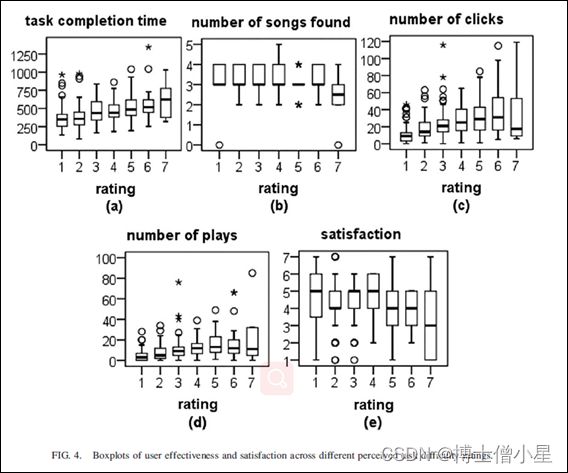
总的来说,这些发现与文本检索领域的发现一致。首先,用户行为 (即点击次数、播放次数) 的增加与更高的任务复杂度和任务难度等级相关 (表7)。在文本检索中,人们普遍认为,更多的用户搜索行为与用户感知的困难和/或用户在搜索中挣扎的事实有关 (White & Dumais, 2009)。其次,任务完成时间与任务难度相关 (图 4a)。一般来说,被认为容易的任务 (Level 1级别和Level 2级别) 比被认为困难的任务 (5、6、7 级)花费的时间更少。Liu, Liu, Cole, Belkin, and Zhang (2012) 认为用户搜索行为可以用来检测用户是否遇到了困难的任务。为了验证这种前提在 MIR 中的适用程度,我们进行了线性回归分析,以预测来自其他测量的感知任务难度 (表8)。除播放次数外,所有用户效率指标在预测感知任务难度等级方面均具有统计学意义。

为了进一步检验指标的预测能力,我们进行了一个分类实验,实验设置与Liu et al. (2012) 的研究相似。具体来说,任务难度等级为1到3的搜索会话被组合成一个“容易”类 (202个会话),而任务难度等级为5到7的搜索会话被组合成一个“困难”类 (69个会话)。基于任务复杂度和用户效率度量,使用逻辑回归建立了一个二元分类模型来预测会话是容易还是困难。分类性能通过5倍交叉验证进行评估,其中80%的数据用于训练,20%的数据用于测试。由于该数据集中最大的类是“容易”,我们将预测的“容易”类别的性能与多数投票的基线结果 (即预测每个会话为“容易”)进行了比较。从表9可以看出,预测模型优于基线,F(0.5)测量值与Liu等人 (2012) 构建的模型相当 (全时段水平变量模型为0.87) 。重要的预测变量包括任务复杂度 (B= -.567, p=.014),任务完成时间 (B=-.002, p=.040),找到的歌曲数 (B=.740, p=.007),点击数 (B=-.020, p=.032),满意度 (B=.227, p=.046)。换句话说,这些指标有助于预测一个任务是否被认为容易。
5 结论与讨论
通过用户实验,本研究揭示了音乐搜索中的任务难度受任务、用户和系统因素的影响。最低复杂度 (“记住”) 的任务被认为比复杂度较高的任务更容易。用户自述的音乐知识与任务难度呈正相关,而用户年龄则呈弱负相关。尽管 Moodydb 系统的可视化模式不影响感知难度,但系统提供的信息的充分性和准确性以及音乐收藏的规模被认为是使任务变得困难的原因。此外,与任务-用户交互有关,没有直接答案、任务的不确定性和愉快性,也可能影响任务难度。特别是,任务的乐趣似乎是任务完成时间和感知难度之间的中介因素 (表6)。如果一项任务是令人愉快的 (即复杂度Level 3级别的任务),即使用户在其上花费了大量时间,它也可能并不困难。这些发现对MIR研究的任务设计具有启示意义。除了认知复杂性框架外,在设计和/或控制任务难度时,还需要考虑任务的不确定性和愉快性、用户背景和系统支持性。
这项研究还揭示了几个与任务难度相关的用户效率指标:点击次数,播放次数和任务完成时间 (表7)。此外,这些指标与任务复杂度一起,可以在一定程度上预测任务是否困难 (表8和表9)。这朝着可以根据用户行为指标检测用户感知难度的MIR系统又迈进了一步。 当用户遇到困难时,这样的系统可以提供进一步的用户支持。
未来的研究应包括量化更多可能影响音乐搜索任务难度的系统因素,如提供的信息量和收集量。用户的文化背景也可能是相关的,因为用户对文化不熟悉的音乐可能更难寻找。此外,可以探索基于用户行为指标的任务难度实时预测,以便在音乐搜索过程中发现困难的任务。