线上问题排查实例分析|关于 Redis 内存泄漏
Redis 作为高性能的 key-value 内存型数据库,普遍使用在对性能要求较高的系统中,同时也是滴滴内部的内存使用大户。本文从 KV 团队对线上 Redis 内存泄漏定位的时间线维度,简要介绍 Linux 上内存泄漏的问题定位思路和工具。
16:30 问题暴露
业务反馈缩容后内存使用率90%告警,和预期不符合,key 只有1万个,使用大 key 诊断,没有超过512字节以上的大 key。
16:40 确认内存泄漏
发现该系统中有部分实例内存明显偏高达到300~800MB,正常实例只有10MB左右,版本号为4ce35dea,在9月份时已经有发现49bdcd0b这个较老版本有内存泄漏情况发生,现象看起来一样,说明内存泄漏问题一直存在,未被修复,于是开始排查该问题。
17:30 开始排查社区版本
排查问题先易后难,先排除是不是社区的版本Bug问题:
不需要从最新修复一直倒叙确认到3系列的 commit 提交,因为如果是严重的内存泄漏,3系列的旧版本也一定会有 backport 修复记录。
查看3.2.8的commit记录,只有一次内存泄漏相关提交:Memory leak in clusterRedirectBlockedClientIfNeeded.
本次提交只修复了在 cluster 出现 key 重定向错误时对 block client 处理时对一个指针的泄漏,不可能出现如此大的泄漏量。3.2.8的社区版已上线数年,但在社区内未搜索到相关内存泄漏问题,因此推测是我们的某些定制功能开发引入的 Bug。
18:10 整理监控和日志
整理当前已知监控和日志信息,分析问题的表面原因和发生时间
1、监控信息
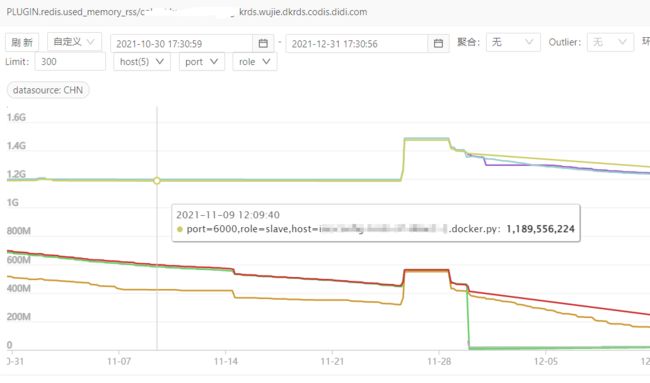
odin 监控只能看到最近两个月的内存使用曲线,从监控上可以得到三点信息:
两个月前已经发生内存泄漏
内存泄漏不是持续发生的,是由于某次事件触发的
内存泄漏量大,主实例使用内存800MB,从实例使用内存10MB
2、日志信息
排查发生内存泄漏的容器日志:


Redis 在10月11日被创建后,只有在20日出现有大量日志,之后无日志,日志有以下内容:
Redis 横向扩容 slot 迁移
主从切换
AOF 重写
搜索该系统的历史短信告警,在10月11日11:33分出现三次内存使用率达到100%的告警,因此可以推测出现 key 淘汰
Manager平台操作信息:

垂直扩容
横向扩容
Redis 重启
综合 Redis 的日志和平台日志信息,虽然未能直接发现问题原因,可以确定内存泄漏发生在10月20日11:30左右,由以下单个事件或者混合触发的:
主从切换
key 迁移
key 驱除
18:00 打印内存 dump 信息
在实例上使用 GDB 把泄漏实例的所有内存 dump 出来,初步发现内存上有很多 key(647w个),不属于本节点,info 里数据库只有1.6W个 key, 怀疑是slot 迁移有问题。
18:30 第一次 diff 代码
由于3.2.8自研版本有两个重大修改:
slot 的所属 key 集合记录,把跳跃表改为了4.0以后的基数树结构,从社区的 unstable 分支 backport 下来的;
支持多活
由于出问题的系统没有使用多活功能,且恰巧事发时有 slot 迁移,因此重点怀疑 slot 迁移中 rax 树相关操作有内存泄漏,首先查看了相关代码,有几个疑似的地方,但都排除掉了。
20:30 尝试使用工具定位
memory doctor
Redis4 引入的内存诊断命令,3系列未实现
3.2.8版本使用 jemalloc-4.0.3作为内存分配器,尝试使用 jeprof 工具分析内存使用情况,发现 jemalloc 编译时需要提前添加--enable-prof编译选项,此路不通
使用 perf 抓取 brk 系统调用,未发现异常(实际上最近两个月也未发生泄漏)
valgrind 作为最后手段,不确定是否可以复现
22:00 组内沟通进展
和组内同学沟通下午的调查情况,仍然怀疑 rax 泄漏,其次多活或者 failover 混合动作触发的 case 导致泄漏。
第二天10:00 重新整理思路
使用 hexdump 观察昨天的内存 dump 文件,发现泄漏内存为 SDS 字符串数据类型,且连续分布。

每隔4、5行都会出现OO TT SS等字符,对应 SDS 类型的 sdshdr 结构体。

每个泄漏的 key 字符串大约在80字节左右,因此使用时 sdshdr8(为了节约内存,sds 的 header 有五种 sdshdr5,sdshdr8、sdshdr16、sdshdr32、sdshdr64,其中8指的是长度小于1<<8的字符串使用的 sdshdr)。

以TT那行为例,结合 SDS 字符串的 new 函数分析,key 字符串长度为84字节等于0x54,结合代码看,sh->len和sh->alloc都是0x54,第三个字节标识 type 类型,sdshdr8 的 type 值刚好是0x1,因此可以确认泄漏的是 sds 类型的 key 值,并且排除 rax 树泄漏的可能,因为内存 dump 和 rax 树的存储结构不符。附典型的 rax 存储结构:
14:00 根据dump的分析重新排查代码
排除了 rax 树的泄漏,同时综合 redis 使用 sds key 的情况,此时把怀疑重点放在了 write 等 dict 的释放方法上,以及 rdb 的加载时 key 的临时结构体变量。
此时 diff 代码,不再局限有变更的代码,以功能为粒度进行走读代码,但把重点放在了 failover 时的 flushdb 和 loadRDB 操作上。
17:00 排查slot迁移代码
在上一轮代码走读中,再次排除了 failover,key 淘汰的代码有内存泄漏的可能,因此重新怀疑 slot 迁移中的某些动作导致 key 字面值的内存泄漏,尤其是 slot 清空等操作。
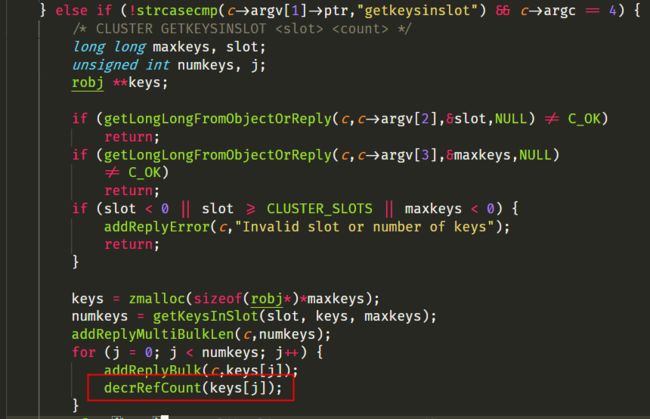
18:30 找到根因
在 slot 迁移过程中,会遍历旧节点中的所有 key,然后把遍历得到的 key 从旧节点迁移到新节点中。

这个功能在3.2.8代码中没有被改动,但其调用的 getKeysInSlot 函数有了修改。getKeysInSlot 是遍历 rax 树,拿到待迁移 key 列表,对每个 key 从 rax 树中取出完整字符串,来拷贝创建 obj 类型指向 sds 字符串;这些字符串作为数组指针类型返回给了出参 keys,但在上层调用把这些字符串返回给客户端后,没有释放这些字符串,导致了内存泄漏的发生。
原生的3.2.8代码中 getKeysInSlot 函数,由于使用的是跳跃表,该跳跃表中的每个节点都是一个 key 的 obj 类型,因此只需要返回这个 key 的指针即可,无需内存拷贝动作,因此上层调用中也就不需要内存释放动作。这个根因查明,也反过来解释了很多疑问:
为什么刚开始只有老版本才有内存泄漏,新版本未发现。原因是老版本的实例上线时间长,有水平扩容的需求较多,内存泄漏的实例也就较多。
泄漏的内存为什么连续分布?原因是在一次 slot 迁移动作中,这些 key 遍历动作都是连续进行的。
这个系统为什么泄漏比例这么高?原因是该系统中 key 占用的内存比 value值更高,key 通常80字节,而 value 大多是0、1等数值。
20:00 修复动作
相比较根因的查找,修复就简单多了,只需添加一行代码即可。
后续思考
1、代码 review 需要从功能视角去走读代码,不能只关注 diff 不同。在本次调查中,第一遍走读代码只关注 diff 点,是无法发现问题的。
2、对内存泄漏的排查,在代码设计阶段是避免此类问题的效率最优解,代码 review 阶段比测试阶段代价要小,测试阶段发现要比上线后排查容易得多,越是工程后期修复 bug 越难。具体在该函数设计中,由于内存申请和释放没有内聚性,导致内存泄漏很容易出现,而这个函数在3系列使用跳跃表时是没有问题的,因为不涉及到内存的申请释放。开发和 QA 在测试中引入工具进行功能覆盖测试,动态工具如 valgrind、sanitizers 等,线上工具如memleak、perf等。