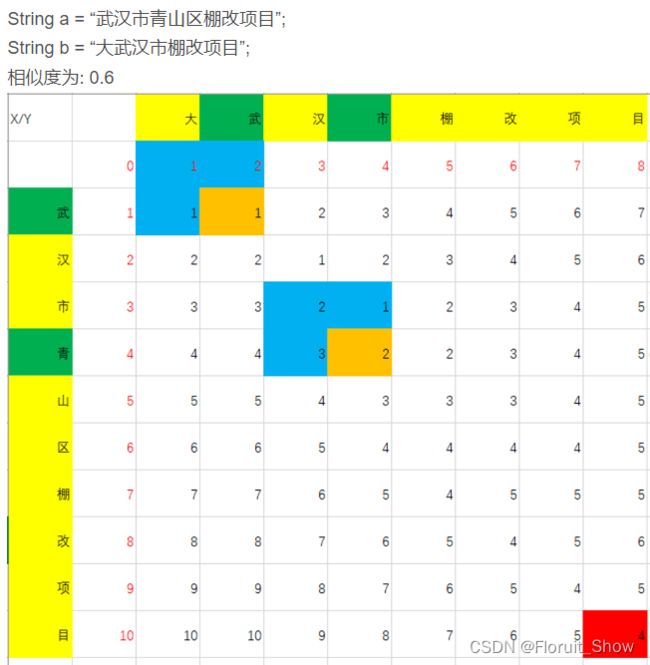
字符串相似度匹配算法_莱茵斯坦距离算法
package day0330;
public class LevenshteinDistanceUtil {
public static void main(String[] args) {
String a = "WN64 F98";
String b = "WN64 F98 ";
System.out.println("相似度:" + getSimilarityRatio(a, b));
}
/**
* 获取两字符串的相似度
*
* @param str
* @param target
* @return
*/
public static int getSimilarityRatio(String str, String target) {
int max = Math.max(str.length(), target.length());
System.out.println("两个字符串中最大长度:" + max);
System.out.println("莱茵斯坦距离:" + compare(str, target));
return Math.round((1 - (float) compare(str, target) / max) * 100);
}
/**
* 获取莱茵斯坦距离d[n,m]
*
* @param str
* @param target
* @return
*/
private static int compare(String str, String target) {
int d[][];// 矩阵
int n = str.length();
int m = target.length();
int i; // 遍历str的
int j; // 遍历target的
char ch1;// str的
char ch2;// target的
int temp;// 记录相同字符在某个矩阵位置值的增量,不是O就是1
if (n == 0) {
return m;
}
if (m == 0) {
return n;
}
d = new int[n + 1][m + 1];
// 初始化第一列
for (i = 0; i <= n; i++) {
d[i][0] = i;
}
// 初始化第一行
for (j = 0; j <= m; j++) {
d[0][j] = j;
}
// 遍历str
for (i = 1; i <= n; i++) {
ch1 = str.charAt(i - 1);
// 去匹配target
for (j = 1; j <= m; j++) {
ch2 = target.charAt(j - 1);
// 这里加32是为了不区分大小写
if (ch1 == ch2 || ch1 == ch2 + 32 || ch1 + 32 == ch2) {
temp = 0;
} else {
temp = 1;
}
// 左边+1,上边+1,左上角+temp取最小
d[i][j] = min(d[i - 1][j] + 1, d[i][j - 1] + 1, d[i - 1][j - 1] + temp);
}
}
return d[n][m];
}
/**
* 获取最小值
*
* @param one
* @param two
* @param three
* @return
*/
private static int min(int one, int two, int three) {
return (one = one < two ? one : two) < three ? one : three;
}
}
原理
两个字符串之间的Levenshtein Distance莱文斯坦距离指的是将一个字符串变为另一个字符串需要进行编辑操作最少的次数。其中,允许的编辑操作有以下三种。
- 「替换」:将一个字符替换成另一个字符
- 「插入」:插入一个字符
- 「删除」:删除一个字符
两个字符串均不为空串
当两个字符串均不为空串时,这里假设字符串A为horse、字符串B为ros进行举例分析。由于上述三种类型的操作不会改变字符串中各字符的相对顺序,故我们可以这样进行思考。每次仅对字符串A末尾进行操作,即只考虑 字符串A的前i个字符 和 字符串B的前j个字符 的莱文斯坦距离。其中。这里的i、j均为从1开始计数。则 字符串A的前5个字符 和 字符串B的前3个字符 的莱文斯坦距离lev(5,3),就是最终我们所求的字符串A、字符串B之间的莱文斯坦距离
- 「插入」
假设我们把 horse 变为 ro 的莱文斯坦距离记为u,即:
# 字符串A的前5个字符 和 字符串B的前2个字符 的莱文斯坦距离为 u
lev(5,2) = u
则 horse 期望变为 ros,其所需的编辑次数不会超过 u+1。因为 horse 只需先经过u次编辑操作变为 ro,然后在尾部插入s字符即可变为 ros
- 「删除」
假设我们把 hors 变为 ros 的莱文斯坦距离记为v,即:
# 字符串A的前4个字符 和 字符串B的前3个字符 的莱文斯坦距离为 v
lev(4,3) = v
则 horse 期望变为 ros,其所需的编辑次数不会超过 v+1。因为 horse 只需先进行一次删除操作变为 hors,再经过v次编辑操作即可变为 ros
- 「替换」
假设我们把 hors 变为 ro 的莱文斯坦距离记为w,即
# 字符串A的前4个字符 和 字符串B的前2个字符 的莱文斯坦距离为 w
lev(4,2) = v
则 horse 期望变为 ros,其所需的编辑次数不会超过 w+1。因为 horse 只经过w次编辑操作即可变为 roe,然后通过一次替换操作,将尾部的e字符替换为s字符即可
至此,在这个例子中不难看出,horse、ros的莱文斯坦距离满足如下的递推公式
lev(horse, ros) = lev(5,3)
= min( lev(5,2)+1, lev(4,3)+1, lev(4,2)+1 )
= min(u+1, v+1, w+1)
特别地,这里对通过替换途径实现的方式做一定的说明。如果 某字符串A的第i个字符 与 某字符串B的第j个字符 完全相同,则其所需的编辑次数肯定不会超过 lev(i-1, j-1)。因为无需进行替换
通过上面的分析过程,我们其实不难看出。如果期望 字符串A的前i个字符 与 字符串B的前j个字符 完全相同。可以有如下三种途径操作方式进行实现。而最终的莱文斯坦距离就是下面三种实现方式中次数最小的一个
- 在 字符串A的前i个字符 与 字符串B的前j-1个字符 完全相同的基础上,进行一次**「插入」**操作
- 在 字符串A的前i-1个字符 与 字符串B的前j个字符 完全相同的基础上,进行一次**「删除」**操作
- 在 字符串A的前i-1个字符 与 字符串B的前j-1个字符 完全相同的基础上,如果字符串A的第i个字符与字符串B的第j个字符不同,则需要进行一次**「替换」**操作;如果字符串A的第i个字符与字符串B的第j个字符相同,则无需进行任何操作
推演过程