计算机体系结构----指令系统(二)
本文仅供学习,不作任何商业用途,严禁转载。绝大部分资料来自----计算机系统结构教程(第二版)张晨曦等
计算机体系结构----指令系统(二)
- 2.1 指令系统结构的分类
- 2.2 寻址方式
- 2.3 MIPS 指令系统结构
- 2.3.1 MIPS的寄存器
- 2.3.2 MIPS的数据表示
- 2.3.3 MIPS的数据寻址方式
- 2.3.4 MIPS的指令格式
- 1. I类指令
- 2. R类指令
- 3. J类指令
- 2.3.5 MIPS的操作
- 2.3.6 MIPS的控制指令
- 2.3.7 MIPS的浮点操作
指令系统是计算机系统结构的主要内容,是软硬件交界面的主要部分。本章重点讲述指令系统的功能设计和格式设计,并介绍一个经典 RISC 处理器的 MIPS 指令系统。
2.1 指令系统结构的分类
首先,需要说明一下,这里所说的“指令系统结构”是指指令系统的结构ISA(Instruction Set Architecture)。
CPU 中用来存放操作数的存储单元主要有三种:堆栈、累加器、通用寄存器组。据此.可以把指令系统的结构分为堆栈型结构、累加器型结构以及通用寄存器型结构。在通用寄存器型结构中,根据操作数的来源不同,又可以进一步分为寄存器-存储器型结构(简称 RM结构)和寄存器-寄存器型结构(RR 结构)。RM 结构的操作数可以来自存储器,而 RR 结构的操作数则都是来自通用寄存器组的。由于在 RR 结构中,只有 load 指令和 store 指令能够访问存储器,所以也称为 load-store 结构。
对于不同类型的结构,指令系统中操作数的位置、个数以及操作数的给出方式(显式或隐式)是不同的。显式给出是用指令字中的操作数字段给出,隐式给出则是使用事先约定好了的单元。在堆栈型结构中,操作数都是隐式的,即堆栈的栈顶和次栈顶中的数据,运算后的结果写人栈顶。在这种结构中,只能通过 push/pop 指令访问存储器。在累加器型结构中,其一个操作数是隐式的,即累加器,另一个操作数则是显式给出的,是一个存储器单元运算结果送回累加器。在通用寄存器型结构中,所有操作数都是显式给出的,它们或者来自通用寄存器组,或者有一个操作数来自存储器。运算结果写入通用寄存器组。
表 2.1 是表达式 Z=X+Y 在 4 种类型的指令系统结构上的代码,这里假设 XY、Z 均保存在存储器单元中,并且不能破坏 X 和Y的值。
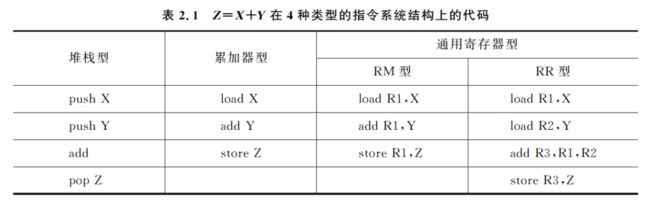
堆栈型和累加器型计算机的优点是指令字比较短,程序占用的空间比较小。但是,它们都有着难以克服的缺点。在堆栈型机器中,不能随机地访问堆栈,难以生成有效的代码,而且对栈顶的访问是个瓶颈。而在累加器型的机器中,由于只有一个中间结果暂存器(累加器),所以需要频繁地访问存储器。
虽然早期的大多数计算机都是采用堆栈型结构或累加器型结构的指令系统,但是自1980 年以后,大多数计算机都采用了通用寄存器型结构。通用寄存器型结构在灵活性和提高性能方面有明显的优势,主要体现在:
(1) 寄存器的访问速度比存储器快很多。
(2) 对编译器而言,能更加容易、有效地分配和使用寄存器。在表达式求值方面,通用寄存器型结构具有更大的灵活性和更高的效率。例如,在一台通用寄存器型结构的机器上求表达式 ( A × B ) − ( C × D ) − ( E × F ) (A \times B)- (C \times D)-(E \times F) (A×B)−(C×D)−(E×F)的值时,其中的乘法运算可以按任意的次序进行,操作数的存放也更加灵活,对流水处理也更合适,因而更高效。但是在堆栈型机器上,该表达式的求值必须按从左到右的顺序进行。对操作数的存放也有较多的限制。
(3) 寄存器可以用来存放变量。这能带来许多好处:
- 由于寄存器比存储器快,所以将变量分配给寄存器能加快程序的执行速度;)
- 能够减少对存储器的访问 ;
- 可以用更少的地址位(相对于存储器地址来说)来对寄存器进行寻址。从而有效地减少程序的目标代码所占用的空间。
由于通用寄存器型结构是现代指令系统的主流,所以后面主要针对这种类型的结构进行讨论。
从编译器设计者的角度来看,总是希望 CPU 内部的所有寄存器都是平等、通用的。但许多以往的计算机都不是这样的,它们将这些寄存器中的相当一部分用作专用寄存器,导致了通用寄存器数量的减少。如果通用寄存器的数量太少,即使将变量分配到寄存器中,也可能不会带来多少好处。因此,现代计算机中寄存器的个数已越来越多。
还可以根据 ALU 指令的操作数的两个特征来对通用寄存器结构进行进一步的细分一个是 ALU 指令的操作数个数。对于有三个操作数的指令来说,它包含两个源操作数和个目的操作数:而对于只有两个操作数的指令来说,其中一个操作数既作为源操作数,又作为目的操作数。另一个特征是 ALU 指令中存储器操作数的个数,它可以是 0~3 中的某一个值,为 0 表示没有存储器操作数。
基于上述 ALU 指令的两个特性及其组合,可以得到 5 种组合类型,如表 2.2 所示。
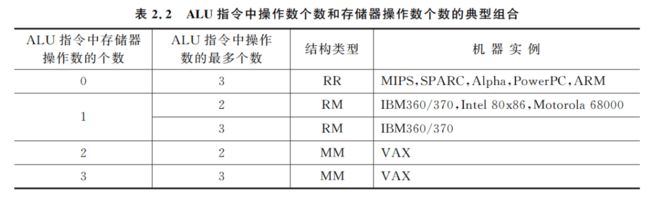
表 2.2 将通用寄存器型结构进一步细分为三种类型: 寄存器-寄存器型(RR 型)、寄存器-存储器型(RM 型)和存储器-存储器型(MM 型)。这三种通用寄存器型结构的优缺点如表 2.3 所示,表中(m,n)表示指令的 个操作数中有m 个存储器操作数。当然,这里的优缺点是相对而言的,而且跟所采用的编译器以及实现策略有关。

一般来说,指令格式和指令字长越单一,编译器的工作就越简单,因为编译器所能做的选择变少了。如果指令系统的指令格式和指令字长具有多样性,则可以有效地减少目标代码所占的空间。但是这种多样性也可能会增加编译器和 CPU 实现的难度。另外,CPU 中寄存器的个数也会影响指令的字长。
从以上的分析可以看到,通用寄存器型结构比堆栈型结构和累加器型结构更具有优势。在通用寄存器型结构中,存储器-存储器型在现代机器中已不采用,而寄存器-寄存器型因其简洁性和两个源操作数的对称性而备受青睐。特别是在第 3 竟我们将看到,寄存器-寄存器型结构对于实现流水处理也更方便。
2.2 寻址方式
寻址方式在计算机组成原理课程中已经学过了,这里只简单地做个概述。寻址方式(Addressing Mode)是指指令系统中如何形成所要访问的数据的地址。一般来说,寻址方式可以指明指令中的操作数是一个常数、一个寄存器操作数或者是一个存储器操作数。对于存储器操作数来说,由寻址方式确定的存储器地址称为有效地址(Effective Address)。
表 2.4 列出了一些操作数寻址方式。在该表以及本书后面的章节中采用类 C 语言作为描述硬件操作的标记。左箭头(<-)表示赋值操作,Mem 表示存储器,Regs 表示寄存器组;方括号表示内容,如 Mem[ ] 表示存储器的内容,Regs[ ] 表示寄存器的内容。这样,Mem[Regs[R1]]指的就是由寄存器 R1 中的内容作为地址的存储器单元中的内容。
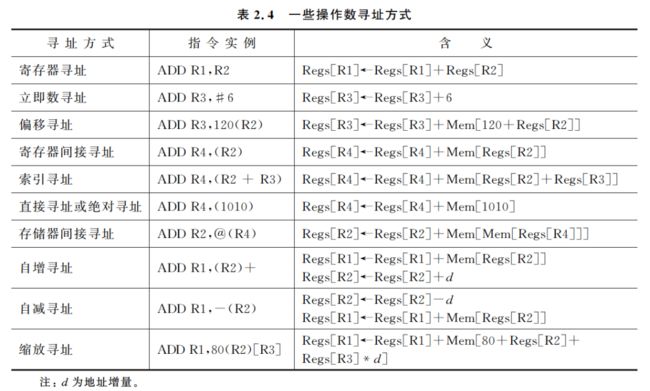
表 2.4 中没有包括 PC 相对寻址。PC 相对寻址是一种以程序计数器(PC)作为参考点的寻址方式,主要用于在转移指令中指定目标指令的地址。2.6.6 节将讨论这些指令。另外,在表 2.4 的自增/自减寻址方式和缩放寻址方式中,用变量 d 来指明被访问的数据项的大小(如 4 个字节或者 8 个字节等)。只有当所要访问的数据元素在存储器中是相邻存放时,这三种寻址方式才有意义。
采用多种寻址方式可以显著地减少程序的指令条数,但同时也可能增加计算机的实现复杂度以及指令的平均执行时钟周期数(Cycles Per Instruction,CPI)。所以,有必要对各种寻址方式的使用情况进行统计分析。以确定应采用什么样的寻址方式。
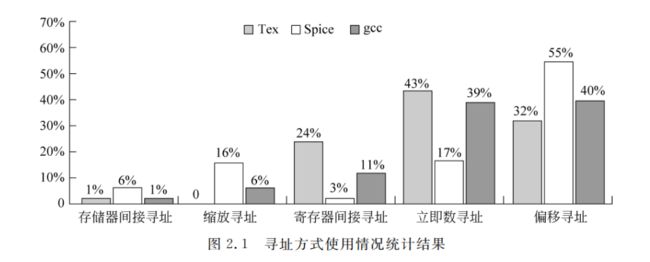
图 2.1 是在 VAX 机器上运行 gcc,Spice 和 Tex 基准程序,并对各种寻址方式的使用情况进行统计的结果。这里只给出了使用频度超过 1%的寻址方式。之所以选择在已过时了的 VAX 结构上进行测试,是因为它的寻址方式最多。
从图 2.1 可以看出,立即数寻址方式和偏移寻址方式的使用频度最高。立即数寻址方式主要用于 ALU 指令、比较指令和用于给寄存器装入常数等。对指令系统的结构设计而言,首先要确定是所有的指令还是只有部分指令具有立即数寻址方式。表 2.5 是在与图 2.1 相同的机器和程序的条件下统计的立即数寻址方式的使用频度。表中的数据表明,大约 1/4 的 load 指令和 ALU 指采用了立即数寻址。

表示寻址方式的方法有两种,一种是隐含在指令的操作码中,另一种是在指令字中设置专门的寻址字段,用以直接指出寻址方式。这两种方法在不同的机器上都有采用。相比而言,设置寻址字段的方法更加灵活,操作码短,但需要设置专门的寻址方式字段,而且操作码和寻址方式字段合起来所需要的总位数可能会比隐含方法的总位数多。
寻址方式中,关于物理地址空间的信息存放是一个需要注意的问题。通常一台机器会同时存放宽度不同的信息。如何在存储器中存放这些不同宽度的信息呢?下面以 IBM370为例进行讨论。IBM370 中的信息有字节、半字(双字节),单字(4 字节)和双字(8 字节)等宽度。主存宽度为 8 字节。采用按字节编址,各类信息都是用该信息的首字节地址来寻址的。如果允许它们任意存储,就很可能会出现一个信息跨存储字边界而存储于两个存储单元中,如图 2.2(a)所示。在这种情况下,读出该信息需要花费两个存储周期,这显然是不可接受的。为了避免出现这个问题,可以要求信息宽度不超过主存宽度的信息必须存放在一个存储字内,不能跨边界。为了实现这一点,就必须做到:信息在主存中存放的起始地址必须是该信息宽度(字节数)的整数倍,即满足以下条件。== 注意地址是按字节寻址的,即地址0000 与 0001 差了1byte ,8bits==。
字节信息的起始地址为 : X … X X X X
半字信息的起始地址为: X … X X X 0
单字信息的起始地址为: X … X X 00
== 双字信息的起始地址为: X … X 000== 2 3 = 8 2^3 = 8 23=8 公式中的3表示3个地址比特位,8表示3个地址比特位表示8个字节
这就是所谓的信息存储的整数边界概念。图 2.2(b)是图 2.2(a)中的信息按整数边界存储后的情况。从图 2.2 中可以看出,按整数边界存储,可能会导致存储空间的浪费。所以这是在速度和占用的空间之间进行权衡。为了保证访问速度,现在的计算机一般都是按整数边界存储信息的。

2.3 MIPS 指令系统结构
为了进一步加深对指令系统结构设计的理解,下面讨论 MIPS 指令系统结构。之所以选择 MIPS,是因为它不仅是一种典型的 RISC 结构,而且还比较简单,易于理解和学习。后面各章中使用的例子几乎都是基于该指令系统结构的。
1981 年,Stanford 大学的 Hennessy 及其同事们发表了他们的 MIPS 计算机,后来,在此基础上形成了 MIPS 系列微处理器。到目前为止,已经出现了许多版本的 MIPS。下面介绍 MIPS64 的一个子集,并将它简称为 MIPS。
2.3.1 MIPS的寄存器
MIPS64 有 32 个64 位通用寄存器: R0,R1,…,R31。它们被简称为 GPRs(General-Purpose Registers),有时也被称为整数寄存器。R0的值永远是 0。此外,还有== 32 个 64 位浮点数寄存器:F0,F1…,F31。它们被简称为 FPRs(Floating-Point Registers)==。它们既可以用来存放 32 个单精度浮点数(32 位),也可以用来存放 32 个双精度浮点数(64 位)。存储单精度浮点数(32 位)时,只用到 FPR 的一半,其另一半没用。MIPS 提供了单精度和双精度(32 位和 64 位)操作的指令。而且还提供了在 FPRs 和 GPRs 之间传送数据的指令另外,还有一些特殊寄存器,例如浮点状态寄存器。它们可以与通用寄存器交换数据浮点状态寄存器用来保存有关浮点操作结果的信息。
2.3.2 MIPS的数据表示
MIPS 的数据表示有:
(1) 整数,字节(8 位),半字(16 位),字(32 位)和双字(64 位)。
(2) 浮点数,单精度浮点数(32 位),双精度浮点数(64 位)。
之所以设置半字操作数类型,是因为在类似于 C 的高级语言中有这种数据类型,而且在操作系统等程序中也很常用,这些程序很重视数据所占的空间大小。设置单精度浮点操作数也是基于类似的原因。
MIPS64 的操作是针对 64 位整数以及 32 位或 64 位浮点数进行的。字节、半字或者字在装入 64 位寄存器时,用零扩展或者用符号位扩展来填充该寄存器的剩余部分。装入以后,对它们将按照 64 位整数的方式进行运算。
2.3.3 MIPS的数据寻址方式
MIPS 的数据寻址方式只有立即数寻址和偏移量寻址两种,立即数字段和偏移量字段都是16 位的。寄存器间接寻址是通过把 0 作为偏移量来实现的,16 位绝对寻址是通过把R0(其值永远为 0)作为基址寄存器来完成的。这样实际上就有了 4 种寻址方式。
MIPS 的寻址方式是编码到操作码中的。
MIPS 的存储器是按字节寻址的,地址为 64 位。由于 MIPS 是 load-store 结构,GPRs 和 FPRs 与存储器之间的数据传送都是通过 load 和 store 指令来完成的。与 GPRs 有关的存储器访问可以是字节、半字、字或双字。与 FPRs 有关的存储器访问可以是单精度浮点数或双精度浮点数。所有存储器访问都必须是边界对齐的。
2.3.4 MIPS的指令格式
为了使处理器更容易进行流水实现和译码,所有的指令都是 32 位的,其格式见图 2.10。这些指令格式很简单,其中操作码占 6 位。MIPS 按不同类型的指令设置不同的格式,共有三种格式,它们分别对应于I类指令、R 类指令J类指令。在这三种格式中,同名字段的位置固定不变。

1. I类指令
I类指令包括所有的 load 和 store 指令,立即数指令,分支指令,寄存器跳转指令,寄存器链接跳转指令。其格式如图 2.10(a)所示,其中的立即数字段为 16 位,用于提供立即数或偏移量。
- load 指令
访存有效地址为 Regs[rs]+immediate,从存储器取来的数据放入寄存器 rt。 - store 指令
访存有效地址为 Regs[rs]+immediate,要存人存储器的数据放在寄存器 rt 中。 - 立即数指令
Regs[rt]<-Regs[rs] op immediate - 分支指令
转移目标地址为 PC+immediate,Regs[rs]为用于比较的值。 - 寄存器跳转、寄存器跳转并链接
转移目标地址为 Regs[rs]。
2. R类指令
R 类指令包括 ALU 指令,专用寄存器读/写指令,move 指令等。
ALU 指令为
Regs[rd] <- Regs[rs] funct Regs[rt]
funct 为具体的运算操作编码。
3. J类指令
J类指令包括跳转指令,跳转并链接指令,自陷指令,异常返回指令。在这类指令中,指令字的低 26 位是偏移量,它与 PC 值相加形成跳转的地址。
2.3.5 MIPS的操作
MIPS 指令可以分为 4 大类: load 和 store,ALU 操作,分支与跳转,浮点操作。除了 R0 外,所有通用寄存器与浮点寄存器都可以进行 load 或 store。表 2.12 给出了load 和 store 指令的一些具体例子。单精度浮点数占用浮点寄存器的一半,单精度与双精度之间的转换必须显式地进行。浮点数的格式是 IEEE 754。

在下面解释指令的操作时,我们采用了类似 C 语言的描述语言。在前面已经给出了几个符号的含义,其他符号的意义如下。
- x ← n y x \gets {_ny} x←ny表示从 y 传送 n 位到 x。 x , y ← z x,y \gets z x,y←z表示把z 传送到x 和y。
- 用下标表示字段中具体的位。对于指令和数据,按从最高位到最低位(即从左到右)的顺序依次进行编号,最高位为第零位,次高位为第一位,以此类推。下标可以是一个数字,也可以是一个范围。例如, R e g s [ R 4 ] 0 Regs[R4]_0 Regs[R4]0表示寄存器 R4 的符号位, R e g s [ R 4 ] 56..63 Regs[R4]_{56..63} Regs[R4]56..63表示 R4 的最低字节。
- Mem 表示主存,按字节寻址。
- 上标用于表示对字段进行复制的次数。例如 0 32 0^{32} 032表示一个 32 位长的全零字段。
- 符号 # # \#\# ## 用于两个字段的拼接,并且可以出现在数据传送的任何一边。下面举个例子。假设 R8 和 R6 是 64 位的寄存器,则
R e g s [ R 8 ] 32..63 ← 32 ( M e m [ R e g s [ R 6 ] ] 0 ) 24 # # M e m [ R e g s [ R 6 ] ] Regs[R8]_{32..63} \gets _{32}(Mem[Regs[R6]]_0)^{24}\#\# Mem[Regs[R6]] Regs[R8]32..63←32(Mem[Regs[R6]]0)24##Mem[Regs[R6]]表示的意义是:以 R6 的内容作为地址访问主存,得到的字节按符号位扩展为 32 位后存入R8 的低 32 位,R8 的高 32 位(即 R e g s [ R 8 ] 0..31 Regs[R8]_{0..31} Regs[R8]0..31)不变。
MIPS 中所有的 ALU 指都是寄存器-寄存器型(RR 型)或立即数型的。运算操作包括算术和逻辑操作(加、减、与、或、异或和移位等),表 2.13 中给出了一些例子。所有这些指令都支持立即数寻址模式,参与运算的立即数是由指令中的 immediate 字段(低 16 位)经符号位扩展后生成的。
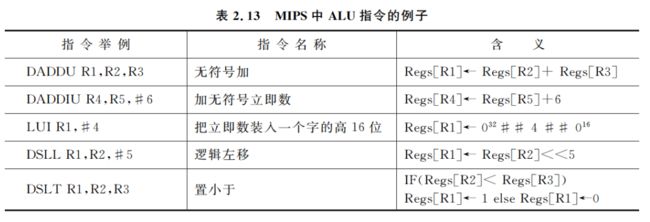
R0 的值永远是 0,它可以用来合成一些常用的操作,例如,
DADDIU R1,R0,# 100 给寄存器 R1装入常数 100
又如,
DADD R1,R0,R2 把寄存器 R2中的数据传送到寄存器 R1
2.3.6 MIPS的控制指令
表 2.14 给出了 MIPS 的几种典型的跳转和分支指令。跳转是无条件转移的,而分支则都是条件转移的。根据跳转指令确定目标地址的方式不同以及跳转时是否链接,可以把跳转指令分成 4 种。在 MIPS 中,确定转移目标地址的一种方法是把指令中的 26 位偏移量左移 2位(因为指令字长都是 4 个字节)后,替换程序计数器的低 28 位;另一种方法是由指令中指定的一个寄存器来给出转移目标地址,即间接跳转。简单跳转很简单,就是把目标地址送入程序计数器。而跳转并链接则要比简单跳转多一个操作: 把返回地址(即顺序下一条指令的地址)放入寄存器 R31。跳转并链接用于实现过程调用。
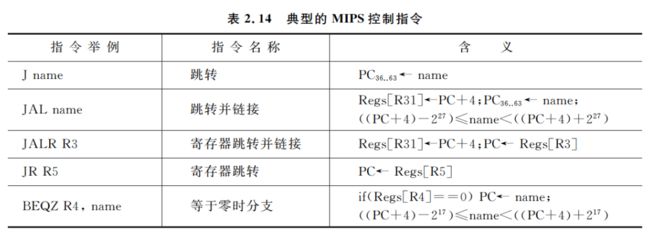
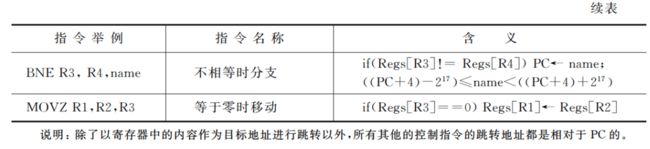
所有的分支指令都是条件转移的。分支条件由指令确定,例如,可能是测试某个寄存器的值是否为零。该寄存器可以是一个数据,也可以是前面一条比较指令的结果。MIPS 提供了一组比较指令,用于比较两个寄存器的值。例如,“置小于”指令,如果第一个寄存器中的值小于第二个寄存器的,则该比较指令在目的寄存器中放置一个 1(代表真);否则将放置一个 0(代表假)。类似的指令还有“置等于”、“置不等于”等。这些比较指令还有一套与立即数进行比较的形式。
有的分支指令可以直接判断寄存器的内容是否为负,或者比较两个寄存器是否相等。
分支的目标地址由 16 位带符号偏移量左移两位后和 PC 相加的结果来决定。另外,还有一条浮点条件分支指令,该指令通过测试浮点状态寄存器来决定是否进行分支。
2.3.7 MIPS的浮点操作
浮点指令对浮点寄存器中的数据进行操作,并由操作码指出操作数是单精度(SP)还是双精度(DP)的。在指令助记符中,用后缀 S 和 D分别表示操作数是单精度还是双精度浮点数。例如,MOV.S 和 MOV.D分别表示把一个单精度浮点寄存器或一个双精度浮点寄存器中的值复制到另一个同类型的寄存器中。MFC1 和 MTC1 是在一个单精度浮点寄存器和一个整数寄存器之间传送数据。另外,MIPS 还设置了在整数与浮点之间进行相互转换的指令。
浮点操作包括加、减、乘、除,分别有单精度和双精度指令。例如.加法指令 ADD.D(双精度)和 ADD.S(单精度),减法指令 SUB.D 和 SUB.S 等。浮点数比较指令会根据比较结果设置浮点状态寄存器中的某一位,以便于后面的分支指令 BCIT(若真则分支)或 BC1F(若假则分支)测试该位,以决定是否进行分支。