python爬取多个网页内容——招聘网站
python爬虫思路:

此次爬虫获取leipin网站上的招聘信息(liepin_ningde)。
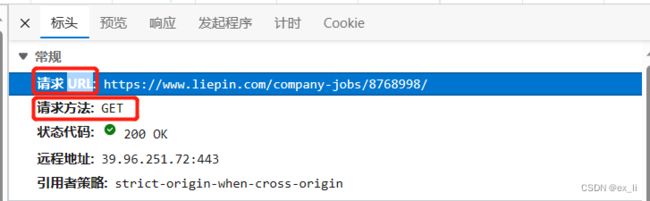
首先右击网页——检查——获取网页代码。点击网络,刷新网页,得到网页URL以及请求方法。、
首先在python环境中安装各种库。
import requests
from faker import Factory
import parsel
import csv
from selenium import webdriver
import time
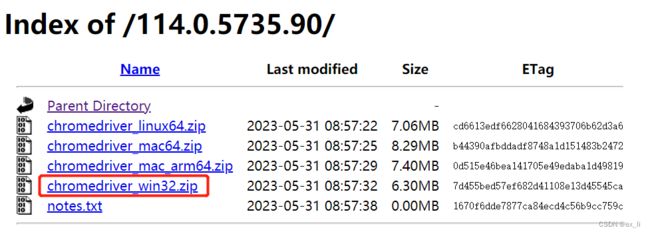
import random从网站http://chromedriver.storage.googleapis.com/index.html 中获取与chrome浏览器相对应版本的chromedriver.exe(chrome浏览器版本的获取方式为在浏览器的地址框中输入chrome://version/得到版本号)。


由于我的电脑版本是win10,因此下载下面的32位的文件。
将下载好的文件放入python环境中。我的文件路径是:C:\Users\lenovo\anaconda3\Lib\site-packages\selenium\webdriver\chrome。

环境配置好之后在代码中引入webdriver,代码如下:
driver = webdriver.Chrome('C:\\Users\\lenovo\\anaconda3\\Lib\\site-packages\\selenium\\webdriver\\chrome\\chromedriver.exe')
driver.get('https://www.liepin.com/company-jobs/8768998/')
driver.implicitly_wait(10)
time.sleep(2)
首先获取一个岗位详细信息页面的链接。可用以下按钮得到岗位的详细链接。
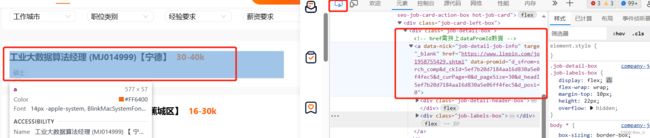
由于该页面的详细链接在job-detail-box类下的a模块,并且链接的属性是href。因此代码如下:
(url是岗位详细信息的链接)
url_list = driver.find_elements_by_css_selector('.job-detail-box a')
for index in url_list:
url = index.get_attribute('href')
print(url)
#url_list_all.append(url)
print(type(url_list))以上 url_list是ningde页面下的第一个页面中所有岗位详细信息的链接。通过换页观察不同页下链接的规律,以此获得所有页面下的岗位详细信息的所有链接。(在这里代码获取了4页),并将获得的每一页的链接放在url_list_all中。
url_list_all = url_list
for i in range(2,5):
driver_1 = webdriver.Chrome(
'C:\\Users\\lenovo\\anaconda3\\Lib\\site-packages\\selenium\\webdriver\\chrome\\chromedriver.exe')
driver_1.get('https://www.liepin.com/company-jobs/8768998/pn'+str(i)+'/')
url_list_1 = driver_1.find_elements_by_css_selector('.job-detail-box a')
url_list_all = url_list_all + url_list_1
#url_list_all = set(url_list_all)
for index_1 in url_list_1:
url_1 = index_1.get_attribute('href')
print(url_1)
#url_list_all.append(url_1)
print(len(url_list_1))接着获取每个岗位详细信息下的
['职位名', '薪资', '城市', '经验', '学历', '福利', '岗位标签', '公司', '详情页','岗位介绍']
并将这些信息写入到csv文件中另外将岗位的名称、岗位介绍以及详情页链接写入到txt文本中。
在页面中指中信息,就可得到具体的信息,::text表示文本,get()表示获取,只有一个信息用get(),获取多个信息用getall()(如福利待业和岗位标签)。

具体代码信息如下:
f = open('data\\CATL_job.csv', mode="a", encoding='utf-8', newline='')
# 写入表头
csv_writer = csv.DictWriter(f, fieldnames=['职位名', '薪资', '城市', '经验', '学历', '福利', '岗位标签', '公司', '详情页','岗位介绍'])
csv_writer.writeheader()
for index in url_list_all:
per_url = index.get_attribute('href')
# time.sleep(random.randint(1,2))
Fact = Factory.create()
ua = Fact.user_agent()
headers = {'User-Agent':ua}
# 发送请求
response = requests.get(url=per_url, headers=headers)
# 获取数据
# print(response.text)
# 解析数据,提取我们想要的数据内容
# 把获取下来的html字符串转成可解析对象
selector = parsel.Selector(response.text)
title = selector.css('.job-apply-content .name-box .name::text').get() # '.job-apply-content .name-box .name'定位标签
salary = selector.css('.job-apply-content .name-box .salary::text').get()
city = selector.css('.job-apply-content .job-properties span:nth-child(1)::text').get() # get()获取一个,返回字符串
exp = selector.css('.job-apply-content .job-properties span:nth-child(3)::text').get()
edu = selector.css('.job-apply-content .job-properties span:nth-child(5)::text').get()
labels = selector.css('.job-apply-container-desc .labels span::text').getall() # 福利#getall()获取所有标签,返回列表
# 把列表合并成字符串
labels_char = ','.join(labels)
job_keys = ','.join(selector.css('.job-intro-container .tag-box ul li::text').getall())
# print(title,salary,city,exp,edu,labels)
company = selector.css('.company-info-container .company-card .content .name::text').get()
job_info = '\n'.join(selector.css('.job-intro-container .paragraph dd::text').getall())
print(title, salary, city, exp, edu, labels_char, job_keys, company, job_info)
# 把数据写到字典里面
dit = {'职位名': title, '薪资': salary, '城市': city, '经验': exp, '学历': edu,
'福利': labels_char, '岗位标签': job_keys, '公司': company, '详情页': per_url,'岗位介绍':job_info}
# 创建文件
# 写入数据
# 写入表头
csv_writer.writerow(dit)
# 保存岗位
file = f'data\\job_information.txt'
with open(file, mode='a', encoding="utf-8")as w:
w.write(str(title))
w.write(job_info)
w.write('\n')
w.write(per_url)
w.write('\n')
以下是一些代码的信息解释,如想详细了解需要自行百度或者系统化学习。
#导入数据请求模块
#前期pip install requests
import requests
#导入faker
from faker import Factory
#随机生成ua(换不同的浏览器身份请求,反爬)
Fact = Factory.create()
ua = Fact.user_agent()
#请求url地址.右击网页,检查,网络
url = ''
#模拟伪装.把python代码伪装成浏览器发送请求,,目的是为了防止被反爬
headers = {
#User-Agent 用户代理,表示浏览器基本身份信息(开发者工具里面复制粘贴)
'User-Agent': }(其中ua可以复制粘贴,也可以随机生成)
#发送请求
response = requests.get(url = url,headers = headers)
print(response)
#返回response [200] 表示请求成功
#获取数据
print(resopnse.text)#获取响应的文本数据,返回字符串数据类型 html字符串数据内容
#解析数据(css选择器 根据标签属性提取数据提取)
import parsel
#把获取下来的html字符串数据内容转成可解析对象
selector = parsel.Selector(response.text)
#selector.css(‘定位标签’)
#css是按照标签来的。ctrl+F可以通过字符串选择器找寻定位数据
title = selector.css('.job-apply-content .name-box .name::text').get()
print(title)
#保存数据,把数据保存本地文件
#基本数据保存在csv表格里面
#岗位职责保存在文本里面
import csv #内置模块
#创建文件
f = open('data.csv',mode = 'a',encoding = 'utf-8',newline = '')#a是追加保存,newline是换行符
csv.DictWriter(f,fieldnames = [])
#把数据写入到字典里面
dit = {
'职位名':title
。。。。。
}
selenium:模拟人的行为去操作浏览器
#导入自动化测试模块
from selenium import webdriver
import time
#selenium模拟人的行为操作浏览器
#1、打开浏览器
driver = webdriver.Chrome()
#2、访问网站
driver.get('网址')
#隐式等待,让网页数据加载完成
driver.implicitly_wait(10)
time.sleep(3)
#3、获取岗位详情页的url地址
url_list = driver.find_elements_by_css_selector('.job-detail-box a')
for index in url_list:
url = index.get_attribute('href')
print(url)