yolov4、yolov5优化策略
一、yolov4优化策略
1.Mosaic data augmentation:四张图像拼接成一张进行训练,现在一个batch相当于以前4个batch。
2.Random Erase:用随机值或训练集的平均像素值替换图像的区域。
3.Self-adversarial-training(SAT):引入噪音点来增加难度。
4.DropBlock :(之前的dropout是随机选择点,现在吃掉一个区域)。

5.Label Smoothing:自觉不错(过拟合),让它别太自信,标签01改为,0.95,0.05,效果
使用之后效果分析(右图):簇内更紧密,簇间更分离。

6.CIOU损失:参考上篇文章:区分(GIOU、DIOU、CIOU)(正则化、归一化、标准化)-CSDN博客
7.SOFT-NMS:在目标检测中,NMS用于通过选择具有最高置信度得分的框来删除冗余的边界框。然而,当检测算法产生具有类似置信度分数的重叠框时,这有时会导致重要边界框的消除。
Soft-NMS通过对重叠框的置信度分数应用衰减函数来解决这个问题,这个函数基于其与最高得分框之间的重叠程度降低较低得分框的得分。其思想是保留较低得分框的信息,同时优先考虑最高得分框。这使得Soft-NMS在重叠框的情况下更加容忍,并有助于提高目标检测的准确性。
8.SPPnet(Spatial Pyramid Pooling)空间金字塔:V3中为了更好满足不同输入大小,训练的时候要改变输入数据的大小,V4在最后的卷积层和全连接层之间加入SPP层。具体做法是,在conv层得到的特征图是256层,每层都做一次spatial pyramid pooling。先把每个特征图分割成多个不同尺寸的网格,比如网格分别为44、22、11,然后每个网格做max pooling,这样256层特征图就形成了16x256,4x256,1x256维特征,他们连起来就形成了一个固定长度的特征向量,将这个向量输入到后面的全连接层。

9.CSPNet(Cross Stage Partial Network):CSPNet中的跨阶段部分连接将网络的特征图分成两部分,其中一部分通过多个卷积层进行处理,而另一部分则通过较少的层进行处理。两条路径的输出然后使用连接操作进行组合,生成的特征图再由另一组卷积层进行处理。这种方法允许不同阶段之间更好的信息流动,从而提高准确性并降低计算成本。
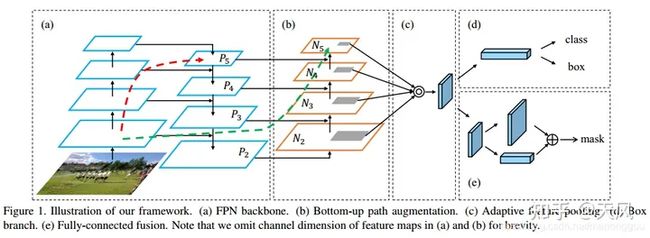
10.PAN(Path Aggregation Network):PAN通过一种保留空间和语义信息的方式,将不同层次的特征结合起来。这是通过一种自上而下和自下而上的特征聚合过程实现的。就是融合FPN(a),加了自下而上的路径,p2已经有了全局信息。
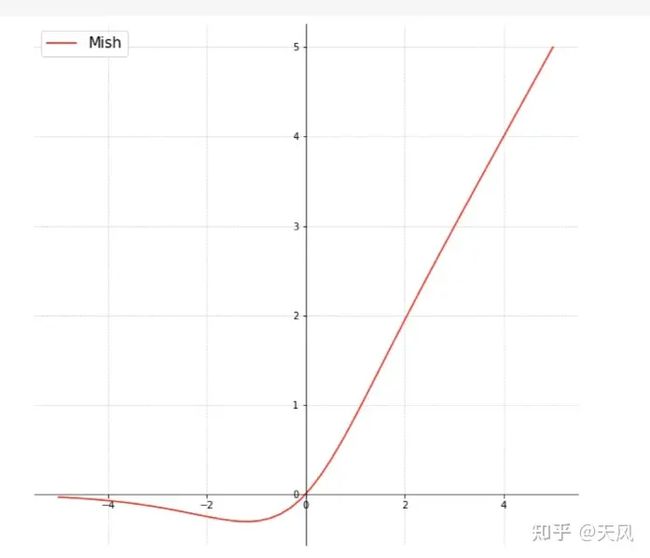
11.激活函数Mish
ReLU函数:f(x)=max(αx,x)

Relu有点太绝对了,Mish更符合实际,但是计算量确实增加了,效果会提升。
二、yolov5 优化策略
1.Conv模块:由一个Conv2d、一个BatchNorm2d和激活函数构成。如下图所示。Conv模块完成了对特征图的下采样、升维降维、归一化、非线性等。

2.C3模块:C3由三个Conv模块和一个Bottleneck模块组成,得名C3。在backbone中,C3是更为重要的提取特征的模块。其结构图如下使用残差结构,将输入与输出相加,避免梯度消失的问题。

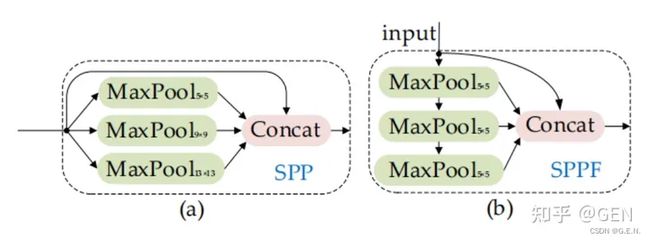
3.SPPF:SPP是空间金字塔池化,yolov5作者在SPP的基础上改进为SPPF。SPPF在输出相同的情况下速度更快。
4.FPN+PAN:和Yolov4中一样,都采用FPN+PAN的结构 。
5.Mosaic data augmentation:同v4,四张图像拼接成一张进行训练,现在一个batch相当于以前4个batch。
6.自适应锚框计算
Yolov5每次训练时会自适应的计算不同训练集中的最佳锚框值,从而帮助网络更快的收敛。
7.CIoU loss :同v4.