python爬虫基础知识
使用python进行网络爬虫开发之前,我们要对什么是浏览器、什么HTML,HTML构成。请求URL的方法都有一个大概了解才能更清晰的了解如何进行数据爬取。
什么是浏览器?
网页浏览器,简称为浏览器,是一种用于检索并展示万维网信息资源的应用程序,这些信息资源可为网页,图片,影音或其他内容,它们由统一资源标志符标志。
浏览器是网页运行的平台,常用的浏览器有IE、火狐(Firefox)、谷歌(Chrome)、Safari和Opera等。我们平时称为五大浏览器。
不同浏览器的内核是不同的,内核负责对网页中代码的解析与渲染。同一份网页代码,在不同的内核中可能会有不同的效果。如一些网页在Chrome中可以正常打开,但在IE中却无法正常显示。
什么是网页
网页是由HTML,CSS,Javascript构成的纯文本文件。存储在各地机房的web服务器中,文件扩展名一般是.htm或.html。一般通过浏览器来阅读。
什么是HTML
超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。您可以使用 HTML 来建立自己的 WEB 站点,HTML 运行在浏览器上,由浏览器来解析。
HTML 标签是由尖括号包围的关键词,比如
HTML标签通常是成对出现的,比如 和
开始和结束标签也被称为开放标签和闭合标签
DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>网页title>
head>
<body>
<h1>我的第一个标题h1>
<p>我的第一个段落。p>
body>
html>
简单的Python爬虫示例
通过requests.get方法获取网页内容。fake_useragent.UserAgent().random伪装访问服务器网页的客户端浏览器类型、版本等。
pip install requests
pip install fake_useragent
pip install lxml
import requests
import fake_useragent
import lxml
# 获取url
url = 'https://www.runoob.com/html/html-tutorial.html'
# UA 伪装 你不能顶着我是python爬虫包的名义去爬网站
head = {
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
"User-Agent": fake_useragent.UserAgent().random
}
# 发送请求
response = requests.get(url, headers=head)
# 获取相应的数据
res_text = response.text
print(res_text)
response.close()
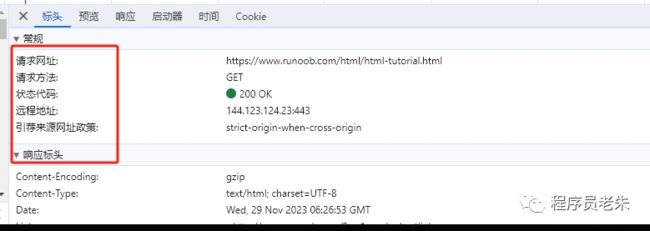
GET/POST请求方法
我们可以通过chrome浏览器查看GET和POST请求的数据。如果你是开发人员也可以通过Postman这种API调试工具去获取模拟请求。
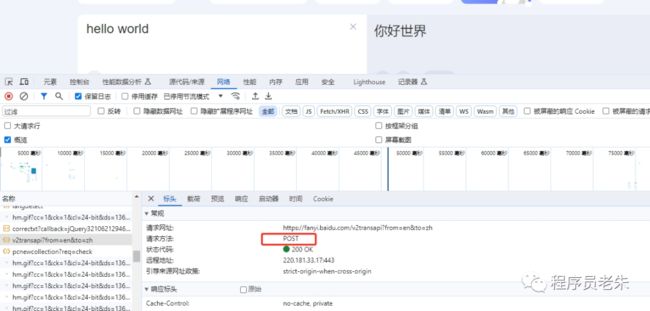
GET请求比较简单,但POST请求,我们要向web服务器发送一些污染数据,这个时候网站一般需要用户登录或者申请API获取授权才能操作。
比如我们要用到百度翻译的话,要去百度翻译云申请开发者账号和服务。然后通过类似下面的Post方法传递数据并请求方法。
import requests
import random
import json
from hashlib import md5
API_URL = 'http://api.fanyi.baidu.com/api/trans/vip/translate'
def translate_text(query, from_lang="en",to_lang="zh"):
appid = '你申请的appid'
appkey = '你申请的秘钥'
salt = random.randint(32768, 65536)
signstr = appid + query + str(salt) + appkey
sign = md5(signstr.encode("utf-8")).hexdigest()
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = {'appid': appid, 'q': query, 'from': from_lang, 'to': to_lang, 'salt': salt, 'sign': sign}
# Send request
r = requests.post(API_URL, params=payload, headers=headers)
return r.json()
result = translate_text(entext)
print(json.dumps(result, indent=4, ensure_ascii=False))
txt = result['trans_result'][0]['dst']
print(txt)
Xpath的基础学习
下面是一段HTML代码,把代码保存为test.html文件。
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>测试title>
head>
<body>
<div>
<p>测试1p>
div>
<div class="user">
你好
<p>小林p>
<p>小王p>
<p>小赵p>
<p>小含p>
<a href="http://www.user.com/" title="人物" target="_self">
<span>this is spanspan>
a 标签内容
a>
<a href="" class="du">du a 标签a>
<img src="http://www.baidu.com/meinv.jpg" alt="" />
div>
<div class="content">
<ul>
url列表内容
<li>
<a href="http://www.ulli.com" title="qing">
baidu li 列表
a>
li>
<li>
<a href="http://www.ulli1.com" title="qin">
163 li 列表
a>
li>
<li><a href="http://www.ulli2.com" alt="qi">li a 内容a>li>
<li><a href="http://www.ulli3.com" class="du">li a class du 内容1a>li>
<li><a href="http://www.ulli4.com" class="du">li a class du 内容2a>li>
<li><b>li b 1b>li>
<li><i>li b 2i>li>
<li><a href="http://www.ulli5.com" id="feng">li a id feng 1a>li>
ul>
div>
body>
html>
我们可以根据html代码的标签、属性、定位获取标签的信息。
from lxml import etree
tree = etree.parse("./test.html")
# xpath 返回的数据都是列表
# 寻找测试1对应的p标签
# 会寻找符合规则的所有标签
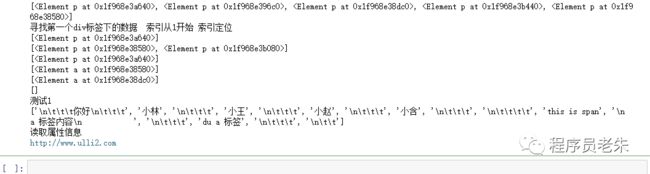
print(tree.xpath("/html/body/div/p"))
print("寻找第一个div标签下的数据 索引从1开始 索引定位")
print(tree.xpath("/html/body/div[1]/p"))
# 两个p标签
# 属性定位 @attr(class、id) = 'xxx'
print(tree.xpath("/html/body/div/p[1]"))
print(tree.xpath("/html/body/div[@class='user']/p[1]"))
print(tree.xpath("/html/body/div[@class='content']/ul/li[1]/a"))
# / 表示一个层级目录 // 表示多个层级目录 一般和属性定位配合使用 不限制后面的使用
print(tree.xpath("//div[@class='content']/ul/li[1]/a"))
print(tree.xpath("//div[@class='contnet']/ul/li"))
# 取标签下的文本值 /text() 该标签下的直系文本内容 //text() 该标签下的所有文本内容
print(tree.xpath("/html/body/div[1]/p/text()")[0])
print(tree.xpath("/html/body/div[@class='user']//text()"))
# 读取属性值 /@attr
print("读取属性信息")
print(tree.xpath("//div[@class='content']/ul/li[3]/a/@href")[0])