计算机网络自顶向下做题总结一(应用层)
文章目录
- 计算机网路自顶向下做题总结一
-
- 第一章
-
- 1.1、复习题
- 1.2、作业题
- 1.3、第一次实验wireshark入门
- 第二章
-
- 2.1、telnet在windows使用
- 2.2、SMTP协议和HTTP协议
- 2.3、DNS——域名系统,因特网的目录服务
- 2.4、 P2P文件分发
- 2.5、视频流和内容分发网
- 2.6、套接字编程实践——UDP\TCP的客户端和服务器端
- 2.7、 复习题和作业题
-
- 2.7.1 、复习题
- 2.7.2、 作业题
- 2.8、套接字编程作业
- 2.9、WireShark实验——http
-
- 2.9.1、基本HTTP GET/response交互
- 2.9.2、HTTP条件Get/response交互
- 2.9.3、检索长文件
- 2.9.4、具有嵌入对象的HTML文档
- 2.9.5、HTTP认证
- 2.10、WireShark实验——DNS
-
- 2.10.1、nslookup
- 2.10.2、Ipconfig
- 2.10.3、使用Wireshark追踪DNS
计算机网路自顶向下做题总结一
第一章
1.1、复习题
-
主机≈端系统,对于客户端,主机就是端系统,而对于服务器,主机约等于端系统;端系统比如移动设备、PC机等;Web服务器是不是端系统,他是建立在端系统上的软件。
-
维基百科是这样描述外交协议的:外交是一个国家、城市或组织等在国际关系上的活动,其目的在于建立能够满足彼此需求的关系[1]。如互派使节、进行谈判、会谈。一般来说外交是国家之间通过外交官就和平、文化、经济、贸易或战争等问题进行协商的过程体系。一般来说国际条约首先是由外交官协商而成,然后由国家的政治家批准签署生效的。国家、国际间的外交为邦交或国交,城市、城际间的外交为**友好城市**。
-
不同的人对于协议的认知不同,这就需要一个交换数据的标准。好比江南人和上海人交流都用普通话交流才能让大家都听得懂。
-
6种接入技术比如:局域网、DSAM接入、移动蜂窝网和wifi、电话。住宅接入:电话、DSAM接入;公司接入:移动蜂窝网;广域无线接入:WIFI、卫星
-
HFC是混合光纤和同轴电缆的网络接入,在用户之间是属于共享的,通过不同的光纤接入到各家用户,然后出来回合到一条大光纤,接着接到同轴电缆,电缆头。HFC和DSAM接入一样是混合式接入,下行HFC可能出现碰撞,因为假设多家用户同时发送分组信息,相当接近的时间同时达到大光纤就会发生分组碰撞。
-
我们这边有移动公司的光纤接入、有DSAM宽带接入、
-
以太LAN的传输速率大概是50Mbps
-
同轴电缆、双绞铜线、光纤
-
拨号调制解调器接入速率范围:;HFC速率范围:42.8Mbps下行,上行30.7Mbps;DSL速率范围:有两种,第一种1993年的12Mbps下行和1.8Mbps下行。2006年55Mbps下行和15Mbps上行;FTTH速率范围: 下行20Mbps,上行
-
今天最为流行的无线因特网接入技术是卫星无线电信道和局域网,4G、5G等广域网无线接入
-
t = L/R1+L/R2
-
电路交换网络无需存储转发,直接发送,没有排队时延。TDM可以更好地实现并发,每个时间间隙都能独占带宽,能够使用较低资源实现较高的需求。而FDM则无法保证每个用户独占带宽。
-
a:10个用户;b:因为电路交换需要预留资源而分组交换无需预留资源,当两个或者更少的用户同时传输的时候,当某个用户进行传输而另外一个用户进行传输时存储转发分组非常的快,往往处于当前用户的分组发送出去和另外的用户刚正在发送分组的状态。3个用户同时传输,存在排队时延。
-
等级相同的ISP,他们无需额外的线路费用,直接连接起来,利用了已有的线路资源,同时一方无法正常工作而另外一方能工作的情况下能保证用户正常的网络接入。IXP是通过内容服务和提供挣钱的。
-
谷歌通过和低级的ISP直接连接来绕过高级的ISP,也和部分高级的ISP连接,达到提供服务和减少资源费用的消耗。动机:减少资源消耗、获取资源和盈利
-
端到端跨越某一个路由,时延包括排队时延、传输时延、传播时延、处理时延。其中传播时延是固定的。排队时延和处理时延受和传输时延受传输的分组长度L的影响而变化。
-
完成
-
如图所示:

-
a:吞吐量为min{R1,R2,R3}=500kbps;b:t=4MB/500kbps;c:过程如上
-
端系统A和端系统B发送一个大文件,那么首先从应用层出发,报文message加上了该层的首部信息,到达传输层,传输层同样将message加上自己的首部信息,变成了报文段segement达到了网络层,网络层加上自己的首部信息变成了数据段datagram,之后链路层加上自己的首部信息变成了帧frame,通过物理链路层,一个一个比特传向下一个结点,然后该结点的物理层上穿帧信息到链路层,链路层解去首部信息得到数据段上传到网络层,依次上到达端系统B。(忽略了中间的链路交换机或者路由器,他们的层次协议可能不是5层)。分组交换中,分组是车,链路是公路,交换机是立交桥询问方向,目的端系统是城市B。
-
完成
-
一个层次可以执行的5个任务

-

1.2、作业题
1.3、第一次实验wireshark入门
-
安装wireshark软件、打开wireshark软件
-
选择要捕获的接口、点击开始捕获,这里选择wlan
-
在浏览器里面输入实验网址http://gaia.cs.umass.edu/wireshark-labs/INTRO-wireshark-file1.html
-
回到wireshark软件,在筛选框输入http,点击应用,然后停止捕获。
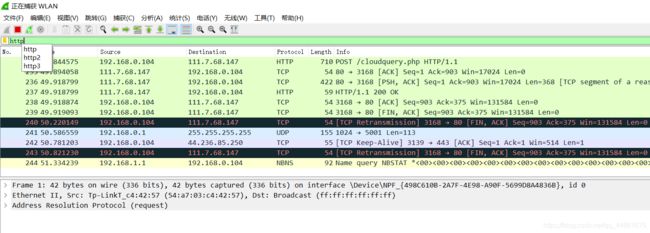
-
找到自己的主机ip,可以在命令行输入ipconfig来看自己的ip地址,然后找到主机主机发出的http get

-
展开该项,查看对应的以太网帧、ip数据段、tcp段、http
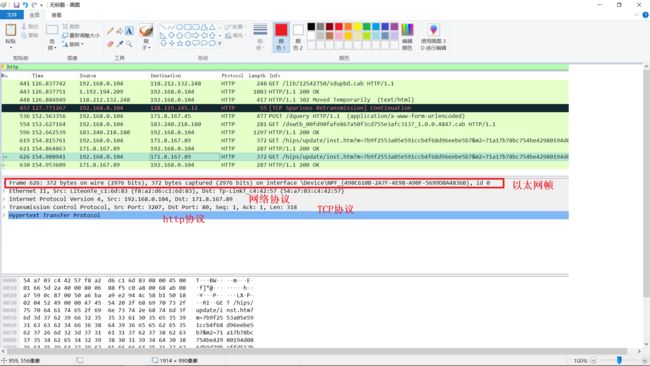
-
重点来看http,展开它
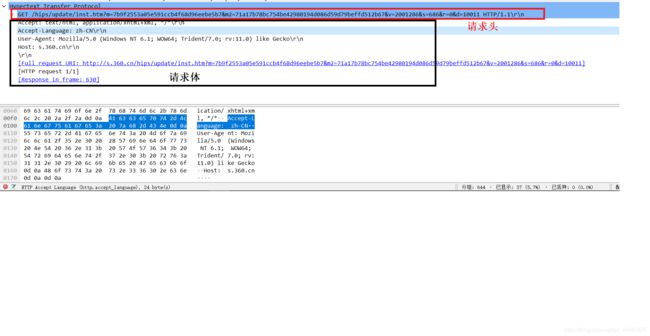
实验需要提交的问题
-
列出上述步骤7中出现在未过滤的分组列表窗口的协议列中的3种不同的协议。
-
从HTTP GET消息发送到HTTP OK回复需要多长时间? (默认情况下,分组列表窗口中的时间列的值是自Wireshark开始捕获以来的时间(以秒为单位)。要想以日期格式显示时间,请选择Wireshark的“视图”下拉菜单,然后选择“时间显示格式”,然后选择“日期和时间”。)

-
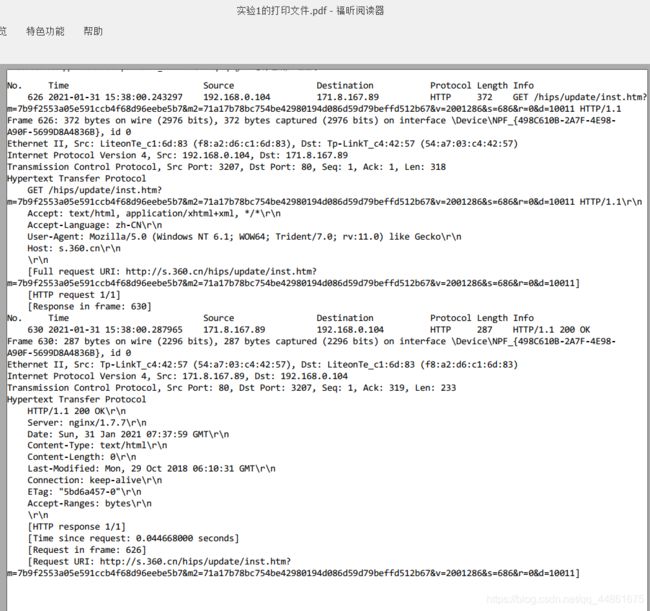
gaia.cs.umass.edu(也称为wwwnet.cs.umass.edu)的Internet地址是什么?您的计算机的Internet地址是什么?
从上图看,经过dns解析,得到的目标主机的ip地址为171.8.167.89,我的计算机的IP地址为:192.168.0.104
-
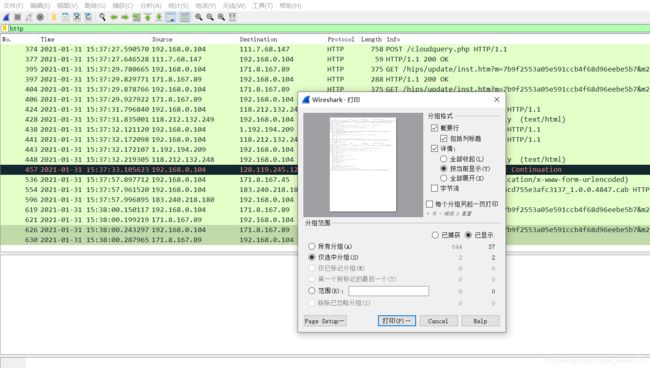
打印问题2提到的两个HTTP消息(GET和OK)。要这样做,从Wireshark的“文件”菜单中选择“打印”,然后选择“仅选中分组”和“按当前显示”按钮,然后单击确定。
第二章
2.1、telnet在windows使用
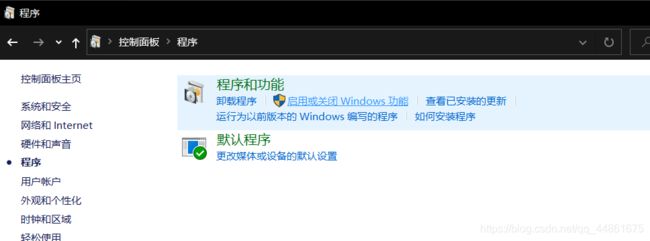
刚开始是提示未知命令:

需要我们启用:(控制面板-程序-启动或关闭windows功能-telent 端)
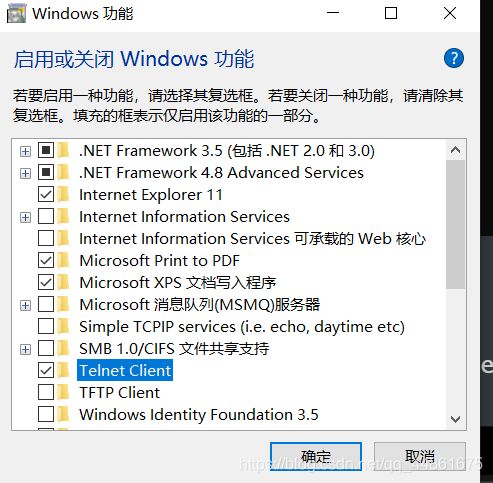
点击确定,启用完成。
测试:
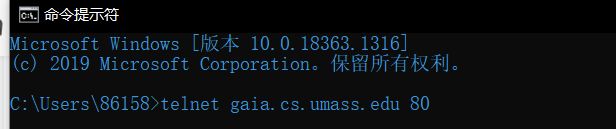
按下回车,进入主机服务器

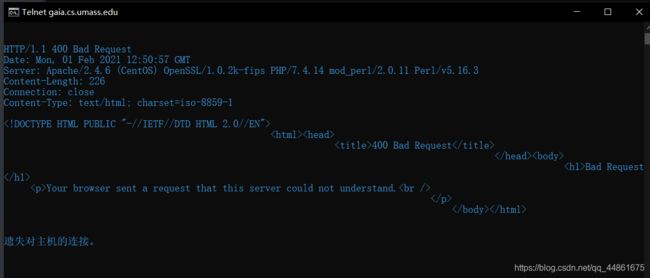
或者输入telnet gaia.cs.umass.edu 80
然后按下ctrl+],之后出现telnet客户端,然后按下回车输入请求信息

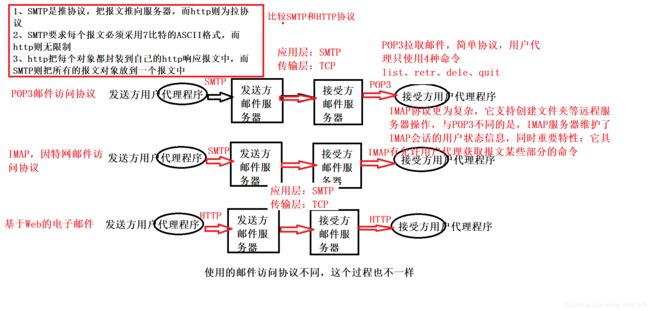
2.2、SMTP协议和HTTP协议
2.3、DNS——域名系统,因特网的目录服务
DNS用于实现主机名到IP地址的转换,这也是因特网的目录服务。比如我们要访问www.baidu.com这个URL,那么它需要先通过DNS服务器获取百度的ip地址:103.235.46.49,然后再向该地址发送http请求报文。
域名系统(Domain Name System,DNS)
DNS是
- 一个由分层的DNS服务器(DNS Server)实现的分布式数据库
- 是一个使得主机能够查询分布式是数据库的应用层协议
DNS服务器通常运行在BIND(Berkeley Internet Domain)软件上的unix机器,DNS协议运行在UDP之上,使用53号端口。它是应用层协议。
DNS提供的功能有:
- 将主机地址转化为IP地址,客户端输入url,会首先向DNS服务器发送url里面的主机名(DNS查询报文),dns服务器根据该主机名返回IP地址(DNS应答报文),之后再由客户端通过HTTP协议…
- 主机别名,一个主机可以有多个主机名,特别是规范主机名比较复杂的时候
- 邮箱服务器别名,同主机名一样。注意,通过DNS记录里面的MX记录,允许一家公司的邮件服务器和web服务器拥有一样的主机别名
- 负载分配
DNS的工作原理:
(1)考虑只有一个DNS服务器


(2)分布式设计
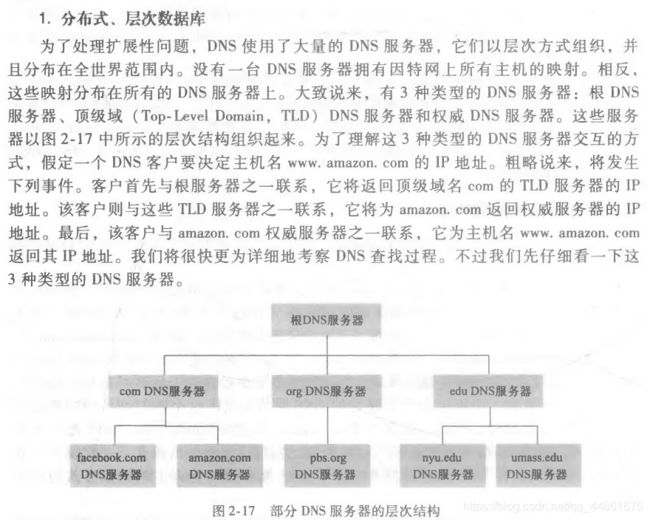

本地DNS服务器:

DNS缓存——减少时延的利器

DNS报文和记录

DNS数据库里面插入记录
2.4、 P2P文件分发
我们知道因特网的体系结构包括:1. 客户端服务器体系;2.P2P体系结构
那么如果我们现在需要将某个更新文件从服务器发送给众多的主机,这个时候采用哪一种方式比较好呢?


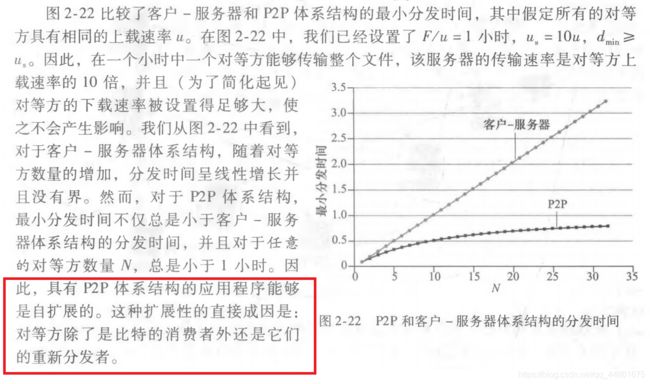
P2P体系,可以使用客户的上传速率来减少分发时间。
Bittorrent:某一个出色的用于文件分发的P2P协议。

2.5、视频流和内容分发网
因特网视频:

HTTP流和DASH

CDN:内容分发商,提高视频的分发速度
2.6、套接字编程实践——UDP\TCP的客户端和服务器端
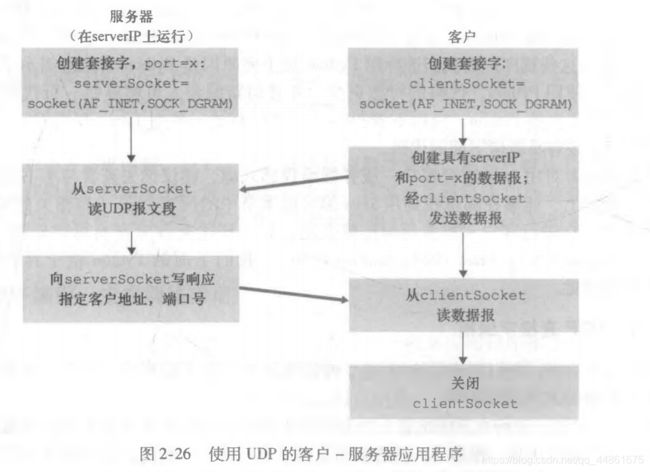
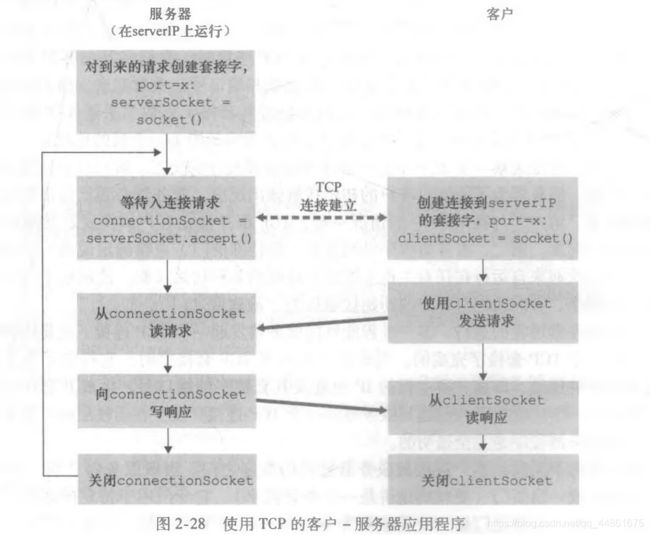
2.7、 复习题和作业题
2.7.1 、复习题
R1:网址——http;电子邮件——SMTP;文件传输——FTP;远程登陆——Telnet;BitTorrent文件共享——BitTorrent协议(一种P2P协议)
R2:网络体系结构是分层结构,应用程序体系是模块化体系结构(答案:网络体系结构是指通信过程组织成多个层次例如五层互联网结构,而应用程序体系结构是由应用程序开发人员设定的,它决定了应用程序的广泛结构,例如客户机-服务器或P2P)
R3:发起通信的进程就是客户端,等待联系的进程是服务器。
R4:不同意,分发文件的是服务器,而接受文件的对等方就是客户端。、
R5:目标进程套接字的端口号和目标主机ip地址
R6:使用UDP,因为它使用不可靠连接,没有三次握手过程。UDP协议可以在一个RTT之内完成。而TCP至少一个RTT建立TCP连接,一个RTT用于客户端接收数据。
R7:答案——例如,使用Google文档进行远程文字处理就是这样一个例子,但是它使用TCP协议,没有提供定时保证。
R8:一个运输协议(UDP/TCP)应该提供的服务有——1,可靠的数据传输;2,定时;3、安全性;4、保证一定的吞吐量

R9:SSL是用来强化TCP的,它工作在应用层。加密传输的报文、从应用层接受的数据报需要进行SSL加密,然后从传输层发送加密数据,另外一个结点的传输层收到该数据需要进行SSL解密。
![]()
R10:握手协议的作用是告知服务器,和客户端建立TCP连接
![]()
R11:因为他们都需要保证可靠的数据传输,而这一服务只有TCP提供,而UDP不提供。
R12:客户第一次登陆注册该网站,服务器会生成一个cookie ID来标识该客户,该ID通过HTTP响应报文送达客户端并保持到其浏览器的本地cookie文件,之后客户在该网站的足迹可以通过cookie ID来跟踪(客户每次请求报文里面会添加上其cookie ID作为首部行。),通过分析客户的踪迹来建立一个表存储用户的购买记录。
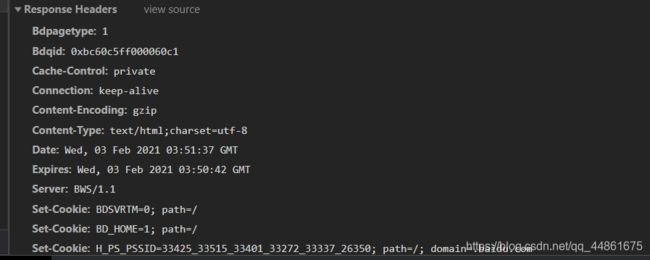
R13:如果Web缓冲器之前缓存过该主机的ip地址则直接返回而不需要经过顶级域服务器或者权威服务器从而减少时延。减少一个用户请求的某些对象时延,因为并不是所有的对象都位于同一IP地址的服务器。
![]()
R14:图:

R15:即时通信应用如:语音通信、微信、FaceBook,这些应用使用与SMS不同的协议。
R16:Alice使用HTTP协议将报文推向其邮件服务器,放到邮件服务器队列,该邮件服务器里的SMTP客户端检索到该报文存在,则和Bob的邮件服务器进行应用层握手,建立TCP连接,然后使用SMTP协议将报文推向Bob的邮件服务器,之后Bob使用自己的代理程序,通过POP3协议,从其邮件服务器里面拉取报文,进行阅读。
R17: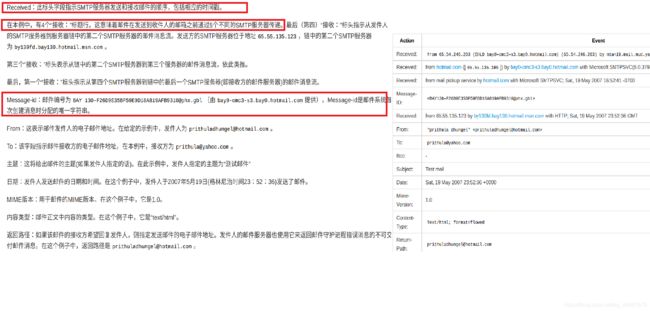
R18:下载删除模式,你只能在一个设备上查阅自己的邮件信息,而下载保留模式则可以多设备进行邮件的查收。
![]()
R19:可以,这是通过发送的DNS报文中的记录type来分类,chame则是主机的别名,而MX则是邮件服务器的别名。
![]()
R20:![]()
R21:不会,因为只有对等子集里面的缺少最多的才会进行上传
![]()
R22:
R25:
2.7.2、 作业题
![]()

P3:需要tcp传输协议和DNS应用层协议
P4:
P5:
P6:
R8:


![]()



2.8、套接字编程作业
作业一:Web服务器
package 第二章应用层;
import java.io.*;
import java.net.InetAddress;
import java.net.ServerSocket;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
import java.util.Date;
/**
* 第二章,作业1:Web服务器
*
* @author LinSir
* @// TODO: 2021/2/5 使用java实现有个web服务器,能够从浏览器输入一个网址,该服务器能够给予正确的回应
*/
public class Test1_WebServer {
private ServerSocket serverSocket;//服务器套接字
private byte[] header;
private byte[] content;
public Test1_WebServer(int port, String host) throws IOException {
InetAddress ip = InetAddress.getByName(host);//根据主机名获取ip地址
this.serverSocket = new ServerSocket(port, 100, ip);
}
public static void main(String[] args) throws IOException {
new Test1_WebServer(10001, "localhost").service();
}
/**
* 服务
*/
public void service() {
System.out.println("服务器启动....");
while(true){
//监听端口,获取服务器
if (serverSocket == null) {
System.out.println("连接未建立");
System.exit(0);
}
Socket socket;
try {
socket = serverSocket.accept();
//获取客户的连接
System.out.println("客户主机:" + socket.getInetAddress() + new Date(System.currentTimeMillis()).toString());
BufferedInputStream in = getInputStream(socket);//Input
BufferedOutputStream out = getOutputStream(socket);//Output
StringBuffer request=new StringBuffer();
while (true) {
int c=in.read();
if (c=='\r'||c=='\n'||c==-1) {
break;
}
request.append((char)c);
}
if (request.toString().contains("HTTP/")) {
String s = request.toString();
System.out.println(s);
//String s = buffers.toString();//得到的是其hashconde
//System.out.println(s);
//获取请求的主页
String path = s.split(" ")[1];
path = path.substring(1);
System.out.println(path);
File file = new File(path);
if (file.exists()) {
long length = file.length();
BufferedReader bufferedReader = new BufferedReader(new FileReader(file));
//发送响应的http报文的首部行:
//http首部行
String header = "HTTP/1.1 200 OK\r\n" +
"Server: Apache/2.2.3\r\n" +
"Content-Length: " + length + "\r\n" +
"Content-Type: text/html" + "\r\n\r\n";
this.header = header.getBytes(StandardCharsets.US_ASCII);
//必须使用字节流来发送这些头文件,不然的话会导致无法解析。
out.write( this.header);
//接下來发送实体体,请求的文件
StringBuffer textB = new StringBuffer();
String text;
while ((text = bufferedReader.readLine()) != null) {
textB.append(text);
}
//这里使用的编码为UTF-8,因为包含中文。
this.content = textB.toString().getBytes("UTF-8");
out.write(this.content);
out.flush();
System.out.println("服务器完成一次服务");
} else {//发送文件不存在的报文:
out.write("HTTP/1.1 404 NotFound".getBytes(StandardCharsets.US_ASCII));
out.flush();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
private BufferedOutputStream getOutputStream(Socket socket) throws IOException {
OutputStream socketOut = socket.getOutputStream();//获取输出流对象,用于做出响应。
return new BufferedOutputStream(socketOut);//使用装饰类
}
private BufferedInputStream getInputStream(Socket socket) throws IOException {
InputStream socketIn = socket.getInputStream();//获取输入流对象,用于接受请求。
return new BufferedInputStream(socketIn);//使用转换流和装饰类
}
}
测试:
注意事项,使用socke的流时,注意使用字节流,然后对首部行等进行的编码方式是ASCII码,而对于实体体内容,编码方式是UTF-8。
作业二——UDP Ping程序
UDPPinger.java:
package 第二章应用层;
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetAddress;
import java.net.SocketException;
import java.util.Date;
import java.util.Random;
/**
* @author Linsir
* @// TODO: 2021/2/5 套接字作业2
* 在这个编程作业中,你将用java编写一个客户ping程序。该客户将发送一个简单的ping报文,
* 接受一个从服务器返回的pong报文,并确定从该客户发送ping报文到接收到pong报文为止的时延。
* 该时延称为往返时延(RTT)。由该客户和服务器提供的功能类似于在现代操作系统中可用的标准ping程序,
* 然而,标准的ping使用互联网控制报文协议(ICMP)(我们将在第4章中学习ICMP)。
* 此时我们将创建一个非标准(但简单)的基于UDP的ping程序。
*
* 你的ping程序经UDP向目标服务器发送10个ping报文,对于每个报文,
* 当对应的pong报文返回时,你的客户要确定和打印RTT。因为UDP是一个不可靠协议,
* 由客户发送的分组可能会丢失。为此,客户不能无限期地等待对ping报文的回答。
* 客户等待服务器回答的时间至多为1秒;如果没有收到回答,客户假定该分组丢失并相应地打印一条报文。
*
*/
public class Test2_UDPPinger {
private DatagramSocket datagramSocket;//UDP协议的socket
public Test2_UDPPinger(int port) throws SocketException {
this.datagramSocket = new DatagramSocket(port);
}
public static void main(String[] args) throws IOException {
new Test2_UDPPinger(8800).Ping();
}
/**
* 发送Ping报文10个
*/
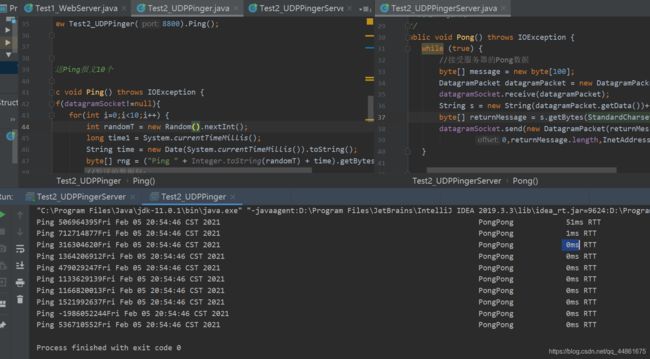
public void Ping() throws IOException {
if(datagramSocket!=null){
for(int i=0;i<10;i++) {
int randomT = new Random().nextInt();
long time1 = System.currentTimeMillis();
String time = new Date(System.currentTimeMillis()).toString();
byte[] rng = ("Ping " + randomT + time).getBytes();
//发送的数据包:
//数据报
DatagramPacket datagramPacket1 = new DatagramPacket(rng, 0, rng.length,
InetAddress.getByName("localhost"), 9990);
datagramSocket.send(datagramPacket1);
//接受服务器的Pong数据
byte[] message = new byte[120];
DatagramPacket datagramPacket = new DatagramPacket(message, message.length);
datagramSocket.receive(datagramPacket);
long time2 = System.currentTimeMillis();
System.out.print(new String(datagramPacket.getData()) + " ");
System.out.println((time2 - time1) + "ms RTT");
}
this.datagramSocket.close();
}
}
}
UDPPingerServer:
package 第二章应用层;
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetAddress;
import java.net.SocketException;
import java.nio.charset.StandardCharsets;
/**
* UDP服务器,将发送过来的数据添加上随机数
*/
public class Test2_UDPPingerServer {
private DatagramSocket datagramSocket;//UDP协议的socket
public Test2_UDPPingerServer(int port) throws SocketException {
this.datagramSocket = new DatagramSocket(port);
}
public static void main(String[] args) throws IOException {
new Test2_UDPPingerServer(9990).Pong();
}
/**
* 发送Pong报文
*/
public void Pong() {
while(true) {
try{
//接受服务器的Pong数据
byte[] message = new byte[100];
DatagramPacket datagramPacket = new DatagramPacket(message, message.length);
datagramSocket.receive(datagramPacket);
String s = new String(datagramPacket.getData())+" PongPong";
byte[] returnMessage = s.getBytes(StandardCharsets.US_ASCII);
datagramSocket.send(new DatagramPacket(returnMessage,
0,returnMessage.length,InetAddress.getByName("localhost"),datagramPacket.getPort()));
}catch (IOException e){
e.printStackTrace();
}
}
}
}
套接字编程作业3:邮件客户端
通过完成本实验,您将更加了解SMTP协议。您还将学到使用Python实现标准协议的经验。
您的任务是开发一个简单的邮件客户端,将邮件发送给任意收件人。您的客户端将需要连接到邮件服务器,使用SMTP协议与邮件服务器进行对话,并向邮件服务器发送电子邮件。 Python提供了一个名为smtplib的模块,它内置了使用SMTP协议发送邮件的方法。但是我们不会在本实验中使用此模块,因为它隐藏了SMTP和套接字编程的细节。
为了限制垃圾邮件,一些邮件服务器不接受来源随意的TCP连接。对于下面所述的实验,您可能需要尝试连接到您的大学邮件服务器和流行的Webmail服务器(如AOL邮件服务器)。您也可以尝试从您的家和您的大学校园进行连接。
可选练习
- 类似Google邮件的服务器(如地址:smtp.gmail.com,端口:587))要求您的客户端在发送MAIL FROM命令之前,需要为了身份验证和安全原因添加传输层安全(TLS)或安全套接字层(SSL)。将TLS / SSL命令添加到现有的命令中,并使用上述地址和端口为Google邮件服务器实现客户端。
- 您当前的SMTP邮件客户端只能在电子邮件正文中发送文本消息。修改您的客户端,使其可以发送包含文本和图像的电子邮件。
实现
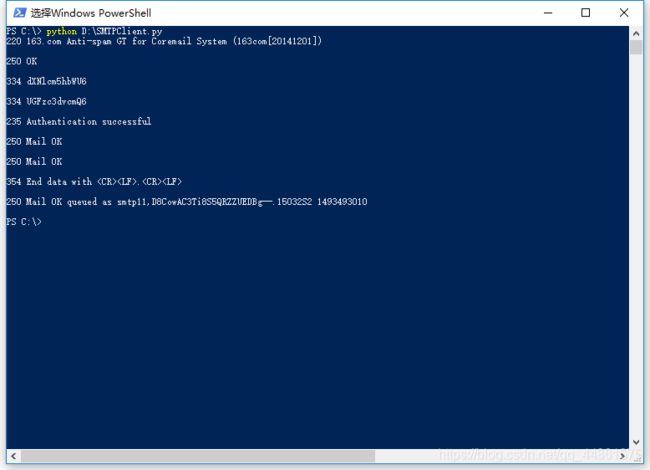
由于众所周知的原因,本文并不采用谷歌邮件服务器实现程序,而是采用网易163邮箱来完成。本文将实现一个SMTP客户端,使用163邮箱作为发件人,向指定的QQ邮箱发送一封邮件。
SMTP协议即简单邮件传输协议,允许用户按照标准发送/接收邮件。
在本文中,SMTP邮件客户端程序的基本流程如下:
- 与163邮件服务器建立TCP连接,域名"smtp.126.com",SMTP默认端口号25。建立连接后服务器将返回状态码220,代表服务就绪(类似HTTP,SMTP也使用状态码通知客户端状态信息)。
- 发送"HELO"命令,开始与服务器的交互,服务器将返回状态码250(请求动作正确完成)。
- 发送"AUTH LOGIN"命令,开始验证身份,服务器将返回状态码334(服务器等待用户输入验证信息)。
- 发送经过base64编码的用户名(本例中是163邮箱的账号),服务器将返回状态码334(服务器等待用户输入验证信息)。
- 发送经过base64编码的密码(本例中是163邮箱的密码),服务器将返回状态码235(用户验证成功)。
- 发送"MAIL FROM"命令,并包含发件人邮箱地址,服务器将返回状态码250(请求动作正确完成)。
- 发送"RCPT TO"命令,并包含收件人邮箱地址,服务器将返回状态码250(请求动作正确完成)。
- 发送"DATA"命令,表示即将发送邮件内容,服务器将返回状态码354(开始邮件输入,以"."结束)。
- 发送邮件内容,服务器将返回状态码250(请求动作正确完成)。
- 发送"QUIT"命令,断开与邮件服务器的连接。
提示
- 有些邮箱默认关闭SMTP服务,比如本文使用的163邮箱。需要在设置中打开SMTP服务。另外,163邮箱在打开SMTP服务后,会设置一个授权码,在程序使用这个授权码作为密码登录,而不是平时使用的密码。
- 代码中带有"****"的内容的是需要自行设置的内容,包含:发件人邮箱,收件人邮箱,登录邮箱的用户名和密码。
代码
from socket import *
# Mail content
subject = "I love computer networks!"
contenttype = "text/plain"
msg = "I love computer networks!"
endmsg = "\r\n.\r\n"
# Choose a mail server (e.g. Google mail server) and call it mailserver
mailserver = "smtp.163.com"
# Sender and reciever
fromaddress = "******@163.com"
toaddress = "******@qq.com"
# Auth information (Encode with base64)
username = "******"
password = "******"
# Create socket called clientSocket and establish a TCP connection with mailserver
clientSocket = socket(AF_INET, SOCK_STREAM)
clientSocket.connect((mailserver, 25))
recv = clientSocket.recv(1024).decode()
print(recv)
if recv[:3] != '220':
print('220 reply not received from server.')
# Send HELO command and print server response.
heloCommand = 'HELO Alice\r\n'
clientSocket.send(heloCommand.encode())
recv1 = clientSocket.recv(1024).decode()
print(recv1)
if recv1[:3] != '250':
print('250 reply not received from server.')
# Auth
clientSocket.sendall('AUTH LOGIN\r\n'.encode())
recv = clientSocket.recv(1024).decode()
print(recv)
if (recv[:3] != '334'):
print('334 reply not received from server')
clientSocket.sendall((username + '\r\n').encode())
recv = clientSocket.recv(1024).decode()
print(recv)
if (recv[:3] != '334'):
print('334 reply not received from server')
clientSocket.sendall((password + '\r\n').encode())
recv = clientSocket.recv(1024).decode()
print(recv)
if (recv[:3] != '235'):
print('235 reply not received from server')
# Send MAIL FROM command and print server response.
clientSocket.sendall(('MAIL FROM: <' + fromaddress + '>\r\n').encode())
recv = clientSocket.recv(1024).decode()
print(recv)
if (recv[:3] != '250'):
print('250 reply not received from server')
# Send RCPT TO command and print server response.
clientSocket.sendall(('RCPT TO: <' + toaddress + '>\r\n').encode())
recv = clientSocket.recv(1024).decode()
print(recv)
if (recv[:3] != '250'):
print('250 reply not received from server')
# Send DATA command and print server response.
clientSocket.send('DATA\r\n'.encode())
recv = clientSocket.recv(1024).decode()
print(recv)
if (recv[:3] != '354'):
print('354 reply not received from server')
# Send message data.
message = 'from:' + fromaddress + '\r\n'
message += 'to:' + toaddress + '\r\n'
message += 'subject:' + subject + '\r\n'
message += 'Content-Type:' + contenttype + '\t\n'
message += '\r\n' + msg
clientSocket.sendall(message.encode())
# Message ends with a single period.
clientSocket.sendall(endmsg.encode())
recv = clientSocket.recv(1024).decode()
print(recv)
if (recv[:3] != '250'):
print('250 reply not received from server')
# Send QUIT command and get server response.
clientSocket.sendall('QUIT\r\n'.encode())
# Close connection
clientSocket.close()
作业4:多线程Web代理服务器
简单一点,使用两个TCP连接(如果文件不存在Web代理服务器的缓存中)。存在则只需用一个TCP连接
2.9、WireShark实验——http
内容:
在介Wireshark实验-入门里,我们已经初步使用了Wireshark包嗅探器,我们现在可以操作Wireshark来查看网络协议。在这个实验中,我们会探索HTTP协议的几个方面:基本的GET/response交互,HTTP消息格式,检索大型HTML文件,检索具有嵌入对象的HTML文件,HTTP认证和安全性。在开始这些实验之前,您可能想查看书中第2.2节。
2.9.1、基本HTTP GET/response交互
我们开始探索HTTP,方法是下载一个非常简单的HTML文件 非常短,并且不包含嵌入的对象。执行以下操作:
- 启动您的浏览器。
- 启动Wireshark数据包嗅探器,如Wireshark实验-入门所述(还没开始数据包捕获)。在display-filter-specification窗口中输入“http”(只是字母,不含引号标记),这样就在稍后的分组列表窗口中只捕获HTTP消息。(我们只对HTTP协议感兴趣,不想看到其他所有的混乱的数据包)。
- 稍等一会儿(我们将会明白为什么不久),然后开始Wireshark数据包捕获。
- 在浏览器中输入以下内容 http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file1.html 您的浏览器应显示非常简单的单行HTML文件。
- 停止Wireshark数据包捕获。

你的Wireshark窗口应该类似于图1所示的窗口。如果你无法连接网络并运行Wireshark,您可以根据后面的步骤下载已捕获的数据包:
下载zip文件 http://gaia.cs.umass.edu/wireshark-labs/wireshark-traces.zip
解压缩文件 http-ethereal-trace-1。这个zip文件中的数据是由本书作者之一使用Wireshark在作者电脑上收集的,并且是按照Wireshark实验中的步骤做的。 如果你下载了数据文件,你可以将其加载到Wireshark中,并使用文件菜单选择打开并查看数据,然后选择http-ethereal-trace-1文件。 结果显示应与图1类似。(在不同的操作系统上,或不同的Wireshark版本上,Wireshark的界面会不同)。
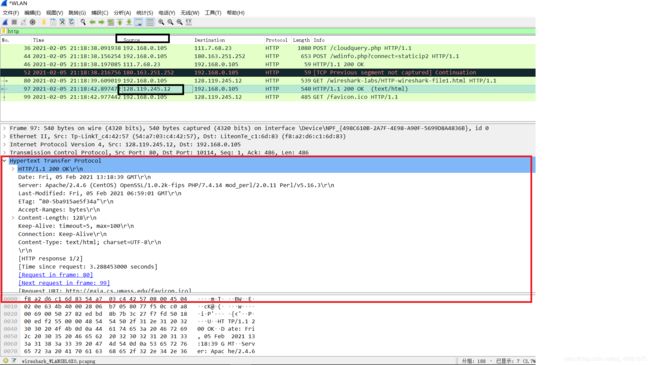
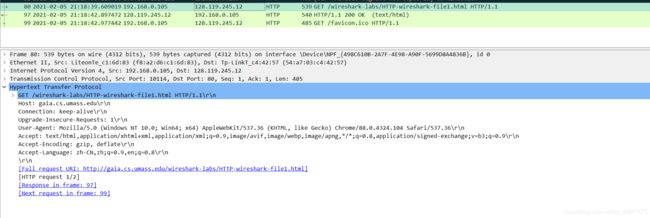
图1中的示例在分组列表窗口中显示了两个被捕获的HTTP消息:GET消息(从您的浏览器发送到gaia.cs.umass.edu 的web服务器)和从服务器到浏览器的响应消息。分组内容窗口显示所选消息的详细信息(在这种情况下为HTTP OK消息,其在分组列表窗口中高亮显示)。回想一下,因为HTTP消息被装载在TCP报文段内,该报文段是在IP分组封装吗,进而在以太网帧,和帧中封装,所以界面中显示了帧,以太网,IP,TCP分组信息以及HTTP报文信息。我们想最小化非HTTP数据的显示(我们这里只对HTTP感兴趣,这些其他协议将在以后的实验中研究),所以确保帧,以太网,IP和TCP行的信息被隐藏,注意左边有一个加号或一个向右的三角形(这意味着有信息被隐藏),而HTTP行具有减号或向下三角形(表示显示有关HTTP消息的所有信息)。
(注意:您应该忽略与favicon.ico相关的任何HTTP GET和response。 如果你看到一个关于这个文件的引用,这是你的浏览器自动询问服务器是否有一个图标文件应显示在浏览器的URL旁边。 我们会忽略这个引起麻烦的引用。)
通过查看HTTP GET和响应消息中的信息,回答以下问题。 在回答以下问题时,您应该打印出GET和响应消息(请参阅Wireshark-入门实验以获取信息),并指出您在消息中的哪个具体位置找到了回答以下问题的信息。 当您上交作业时,请注明输出,显示您在哪些地方表示了您的答案(例如,对于我们的课程,我们要求学生用笔标记纸质副本,或用彩色字体在电子副本的中注释文本)。
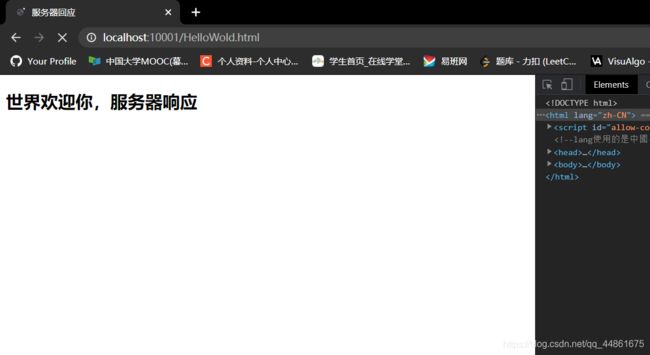
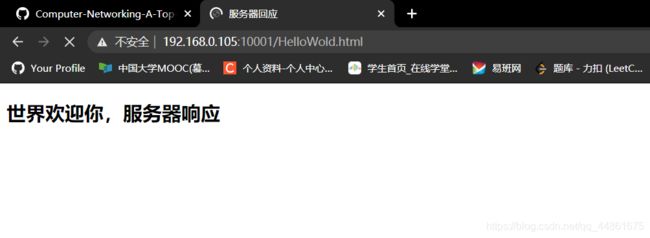
- 您的浏览器是否运行HTTP版本1.0或1.1?服务器运行什么版本的HTTP?——1.1
- 您的浏览器会从接服务器接受哪种语言(如果有的话)?仅支持简体中文,权置0.9
- 您的计算机的IP地址是什么? gaia.cs.umass.edu服务器地址呢?192.168.0.105;128.119.245.12
- 服务器返回到浏览器的状态代码是什么?200
- 服务器上HTML文件的最近一次修改是什么时候?
- 服务器返回多少字节的内容到您的浏览器?128字节
- 通过检查数据包内容窗口中的原始数据,你是否看到有协议头在数据包列表窗口中未显示? 如果是,请举一个例子。
在您对上述问题5的回答中,您可能会惊讶地发现您刚才检索的文档在下载文档之前最近一次修改是一分钟前。 那是因为(对于这个特定文件),gaia.cs.umass.edu服务器将文件的最后修改时间设置为当前时间,并且每分钟执行一次。 因此,如果您在两次访问之间等待一分钟,则该文件看起来已被修改,因此您的浏览器将下载文档的“新”副本。
2.9.2、HTTP条件Get/response交互
回顾书的第2.2.5节,大多数Web浏览器使用对象缓存,从而在检索HTTP对象时执行条件GET。执行以下步骤之前,请确保浏览器的缓存为空。(要在Firefox下执行此操作,请选择“工具” - > “清除最近历史记录”,然后检查缓存框,对于Internet Explorer,选择“工具” - >“Internet选项” - >“删除文件”;这些操作将从浏览器缓存中删除缓存文件。 现在按下列步骤操作:
- 启动您的浏览器,并确保您的浏览器的缓存被清除,如上所述。
- 启动Wireshark数据包嗅探器。
- 在浏览器中输入以下URL http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file2.html 您的浏览器应显示一个非常简单的五行HTML文件。
- 再次快速地将相同的URL输入到浏览器中(或者只需在浏览器中点击刷新按钮)。
- 停止Wireshark数据包捕获,并在display-filter-specification窗口中输入“http”,以便只捕获HTTP消息,并在数据包列表窗口中显示。
- (注意:如果无法连接网络并运行Wireshark,则可以使用http-ethereal-trace-2数据包跟踪来回答以下问题;请参见上文注释。)
回答下列问题:
-
检查第一个从您浏览器到服务器的HTTP GET请求的内容。您在HTTP GET中看到了“IF-MODIFIED-SINCE”行吗?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4VrSefhI-1612671681873)(C:\Users\86158\AppData\Roaming\Typora\typora-user-images\image-20210205213014446.png)]
-
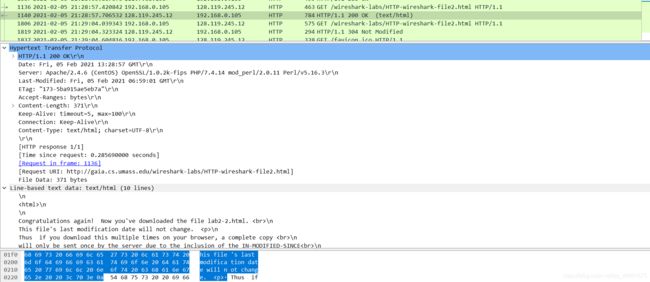
检查服务器响应的内容。服务器是否显式返回文件的内容? 你是怎么知道的?
是显式返回了,看下面的实体体部分:
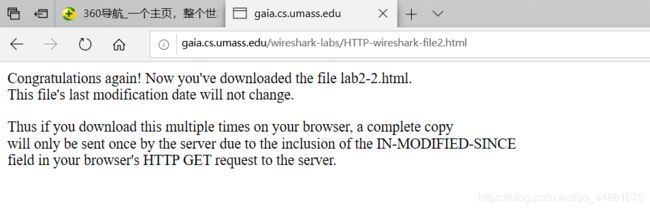
- 现在,检查第二个HTTP GET请求的内容。 您在HTTP GET中看到了“IF-MODIFIED-SINCE:”行吗? 如果是,“IF-MODIFIED-SINCE:”头后面包含哪些信息?
-
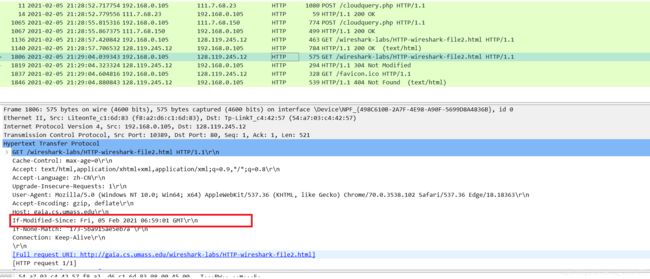
针对第二个HTTP GET,从服务器响应的HTTP状态码和短语是什么?服务器是否明确地返回文件的内容?请解释。
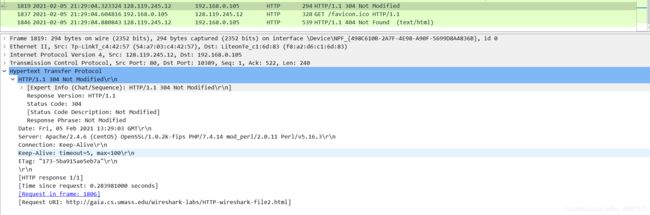
第二个GET的HTTP响应状态码为304 Not Modified。
服务器没有明显的返回文件的内容。下面是空行
2.9.3、检索长文件
在我们到目前为止的例子中,检索的文档是简短的HTML文件。 接下来我们来看看当我们下载一个长的HTML文件时会发生什么。 按以下步骤操作:
-
启动您的浏览器,并确保您的浏览器缓存被清除,如上所述。
-
启动Wireshark数据包嗅探器
-
在您的浏览器中输入以下URL http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file3.html 您的浏览器应显示相当冗长的美国权利法案。
-
停止Wireshark数据包捕获,并在display-filter-specification窗口中输入“http”,以便只显示捕获的HTTP消息。
-
(注意:如果无法连接网络并运行Wireshark,则可以使用http-ethereal-trace-3数据包跟踪来回答以下问题;请参见上文注释。)
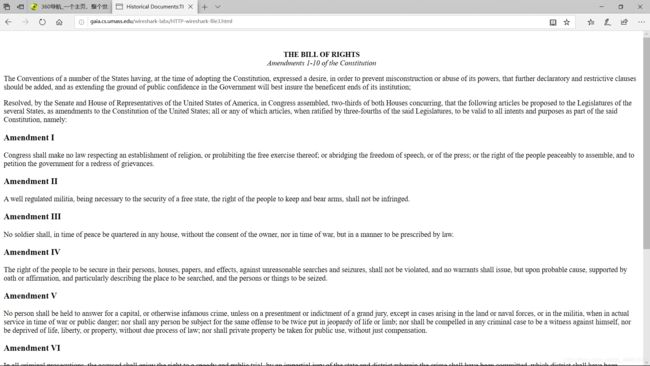
在分组列表窗口中,您应该看到您的HTTP GET消息,然后是对您的HTTP GET请求的多个分组的TCP响应。这个多分组响应值得进行一点解释。回顾第2.2节(见文中的图2.9),HTTP响应消息由状态行组成,后跟标题行,后跟一个空行,后跟实体主体。在我们的HTTP GET这种情况下,响应中的实体主体是整个请求的HTML文件。在我们的例子中,HTML文件相当长,4500字节太大,一个TCP数据包不能容纳。因此,单个HTTP响应消息由TCP分成几个部分,每个部分包含在单独的TCP报文段中(参见书中的图1.24)。在Wireshark的最新版本中,Wireshark将每个TCP报文段指定为独立的数据包,并且单个HTTP响应在多个TCP数据包之间分段的事实由Wireshark显示的Info列中的“重组PDU的TCP段”指示。 Wireshark的早期版本使用“继续”短语表示HTTP消息的整个内容被多个TCP段打断。我们在这里强调,HTTP中没有“继续”消息!
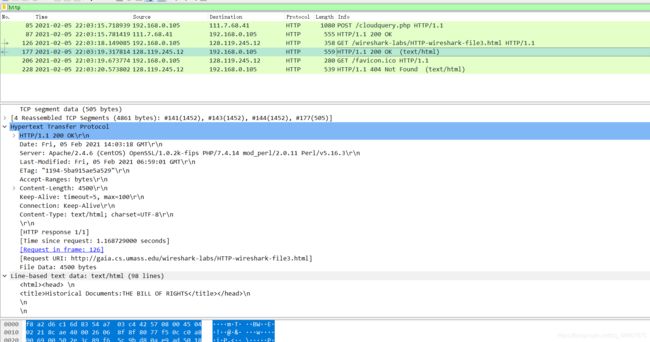
从图中观察, 这里的TCP报分为10个段,每个段的长度为409字节
回答下列问题:
-
您的浏览器发送多少HTTP GET请求消息?哪个数据包包含了美国权利法案的消息?
一个GET请求,177号包

-
哪个数据包包含响应HTTP GET请求的状态码和短语?
177号包

-
响应中的状态码和短语是什么?200,OK
-
需要多少包含数据的TCP段来执行单个HTTP响应和权利法案文本?
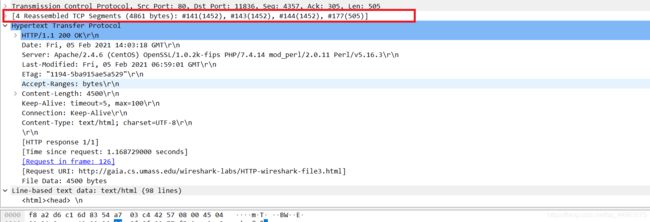
4个。
2.9.4、具有嵌入对象的HTML文档
现在我们已经看到Wireshark如何显示捕获的大型HTML文件的数据包流量,我们可以看看当浏览器使用嵌入的对象下载文件时,会发生什么,即包含其他对象的文件(在下面的例子中是图像文件) 的服务器。 执行以下操作:
- 启动您的浏览器。
- 启动Wireshark数据包嗅探器。
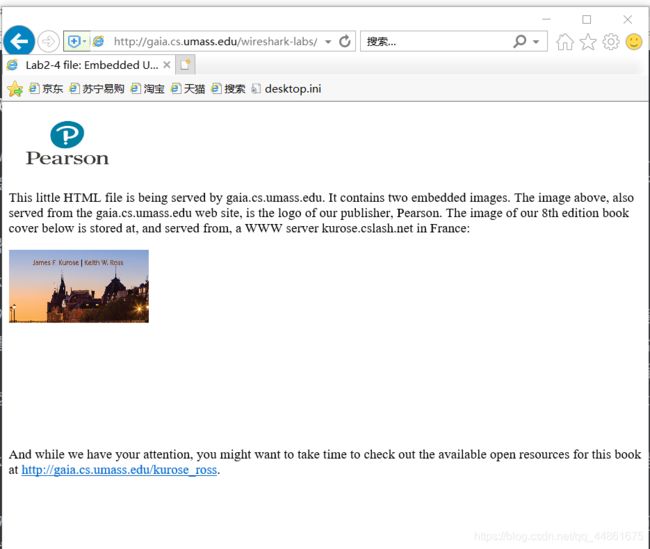
- 在浏览器中输入以下URL http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file4.html 您的浏览器应显示包含两个图像的短HTML文件。这两个图像在基本HTML文件中被引用。也就是说,图像本身不包含在HTML文件中;相反,图像的URL包含在已下载的HTML文件中。如书中所述,您的浏览器将不得不从指定的网站中检索这些图标。我们的出版社的图标是从 www.aw-bc.com 网站检索的。而我们第5版(我们最喜欢的封面之一)的封面图像存储在manic.cs.umass.edu服务器。
- 停止Wireshark数据包捕获,并在display-filter-specification窗口中输入“http”,以便只显示捕获的HTTP消息。
- (注意:如果无法连接网络并运行Wireshark,则可以使用http-ethereal-trace-4数据包跟踪来回答以下问题;请参见上文注释。)
回答下列问题:
-
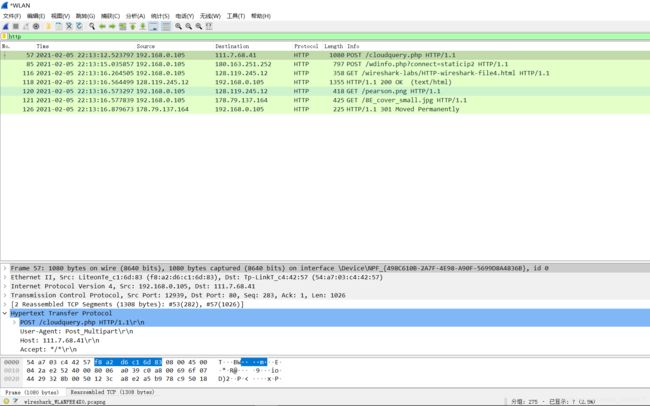
您的浏览器发送了几个HTTP GET请求消息? 这些GET请求发送到哪个IP地址?
三个,分别发送到128.119.245.12和178.79.0.105

-
浏览器从两个网站串行还是并行下载了两张图片?请说明。
从上面的发送世界上看,差了大概300ms,可以知道不是并行下载。
2.9.5、HTTP认证
最后,我们尝试访问受密码保护的网站,并检查网站的HTTP消息交换的序列。URL http://gaia.cs.umass.edu/wireshark-labs/protected_pages/HTTP-wireshark-file5.html 是受密码保护的。用户名是“wireshark-students”(不包含引号),密码是“network”(再次不包含引号)。所以让我们访问这个“安全的”受密码保护的网站。执行以下操作:
- 请确保浏览器的缓存被清除,如上所述,然后关闭你的浏览器,再然后启动浏览器
- 启动Wireshark数据包嗅探器。
- 在浏览器中输入以下URL http://gaia.cs.umass.edu/wireshark-labs/protected_pages/HTTP-wiresharkfile5.html 在弹出框中键入所请求的用户名和密码。
- 停止Wireshark数据包捕获,并在display-filter-specification窗口中输入“http”,以便只显示捕获的HTTP消息。
- (注意:如果无法连接网络并运行Wireshark,则可以使用http-ethereal-trace-5数据包跟踪来回答以下问题;请参见上文注释。)
现在来看看Wireshark输出。 您可能需要首先阅读HTTP身份验证相关信息,方法是在 http://frontier.userland.com/stories/storyReader$2159 上查看“HTTP Access Authentication Framework ”上的易读材料。
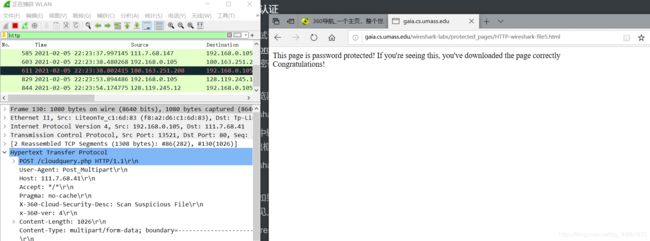
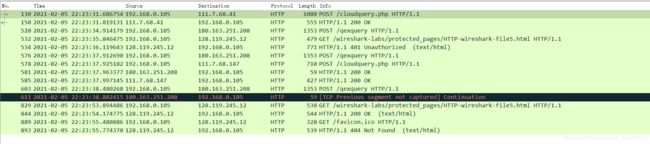
回答下列问题:
-
对于您的浏览器的初始HTTP GET消息,服务器响应(状态码和短语)是什么响应?
401 Unauthorized

-
当您的浏览器第二次发送HTTP GET消息时,HTTP GET消息中包含哪些新字段?
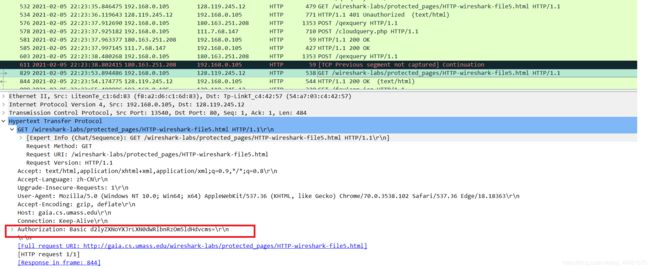
您输入的用户名(wireshark-students)和密码(network)按照客户端HTTP GET消息中请求头的“Authorization: Basic ”的字符串(d2lyZXNoYXJrLXN0dWRlbnRzOm5ldHdvcms=)编码。虽然您的用户名和密码可能加密,但它们只是以一种称为Base64格式的格式进行编码。用户名和密码并没有加密!要确认这些,请访问 http://www.motobit.com/util/base64-decoder-encoder.asp 并输入base64编码的字符串d2lyZXNoYXJrLXN0dWRlbnRz 并进行解码。瞧!您已从Base64编码转换为ASCII编码,因此应该看到您的用户名!要查看密码,请输入字符串Om5ldHdvcms=的剩余部分,然后按解码。因为任何人都可以下载像Wireshark这样的工具,而且可以通过网络适配器嗅探数据包(不仅仅是自己的),任何人都可以从Base64转换为ASCII(你刚刚就这么做了!),所以你应该很清楚,WWW网站上的简单密码并不安全,除非采取其他措施。
新版本的WireShark自带加密和解密base64:

不要害怕! 正如我们将在第8章中看到的,有一些方法可以使WWW访问更加安全。然而,我们显然需要一些超出基本HTTP认证框架的知识!
2.10、WireShark实验——DNS
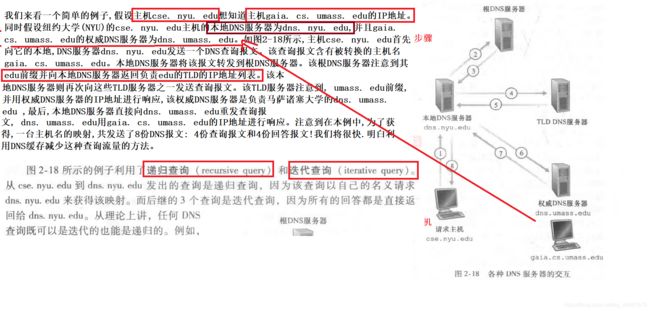
如书中第2.5节所述,域名系统(DNS)将主机名转换为IP地址,在互联网基础架构中发挥关键作用。在本实验中,我们将仔细查看DNS在客户端的细节。回想一下,客户端在DNS中的角色相对简单——客户端向其本地DNS服务器发送请求,并接收一个响应。如书中的图2.21和2.22所示,由于DNS分层服务器之间相互通信,可以递归地或迭代地解析客户端的DNS查询请求,而大多数操作是不可见的。然而,从DNS客户端的角度来看,协议非常简 ——将查询指向为本地DNS服务器,并从该服务器接收到响应。
在开始本实验之前,您可能需要阅读书中的第2.5节来了解DNS。另外,您可能需要查看关于本地DNS服务器,DNS缓存,DNS记录和消息,以及DNS记录中的TYPE字段的资料。
2.10.1、nslookup
在本实验中,我们将大量使用nslookup工具,这个工具在现在的大多数Linux/Unix和Microsoft平台中都有。要在Linux/Unix中运行nslookup,您只需在命令行中键入nslookup命令即可。要在Windows中运行,请打开命令提示符并在命令行上运行nslookup。
在这是最基本的操作,nslookup工具允许主机查询任何指定的DNS服务器的DNS记录。DNS服务器可以是根DNS服务器,顶级域DNS服务器,权威DNS服务器或中间DNS服务器(有关这些术语的定义,请参阅书本)。要完成此任务,nslookup将DNS查询发送到指定的DNS服务器,然后接收DNS回复,并显示结果。

现在我们提供了总览nslookup,现在是你自己驾驭它的时候了。执行以下操作(并记下结果):
- 运行nslookup以获取一个亚洲的Web服务器的IP地址。该服务器的IP地址是什么?
- 运行nslookup来确定一个欧洲的大学的权威DNS服务器。
- 运行nslookup,使用问题2中一个已获得的DNS服务器,来查询Yahoo!邮箱的邮件服务器。它的IP地址是什么?
2.10.2、Ipconfig
ipconfig(对于Windows)和ifconfig(对于Linux / Unix)是主机中最实用的程序,尤其是用于调试网络问题时。这里我们只讨论ipconfig,尽管Linux / Unix的ifconfig与其非常相似。 ipconfig可用于显示您当前的TCP/IP信息,包括您的地址,DNS服务器地址,适配器类型等。例如,您只需进入命令提示符,输入
ipconfig /all
所有关于您的主机信息都类似如下面的屏幕截图所显示。

ipconfig对于管理主机中存储的DNS信息也非常有用。在第2.5节中,我们了解到主机可以缓存最近获得的DNS记录。要查看这些缓存记录,在 C:> 提示符后输入以下命令:
ipconfig /displaydns
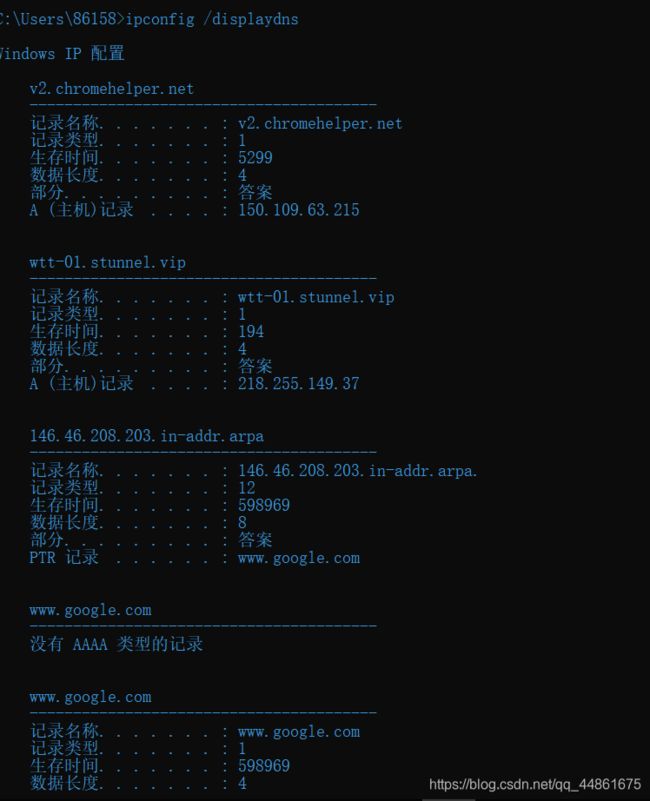
每个条目显示剩余的生存时间(TTL)(秒)。要清除缓存,请输入
ipconfig /flushdns
清除了所有条目并从hosts文件重新加载条目。

2.10.3、使用Wireshark追踪DNS
现在,我们熟悉nslookup和ipconfig,我们准备好了一些正经的事情。首先让我们捕获一些由常规上网活动生成的DNS数据包。
- 使用ipconfig清空主机中的DNS缓存。
-
打开浏览器并清空浏览器缓存。 (若使用Internet Explorer,转到工具菜单并选择Internet选项;然后在常规选项卡中选择删除文件。)
-
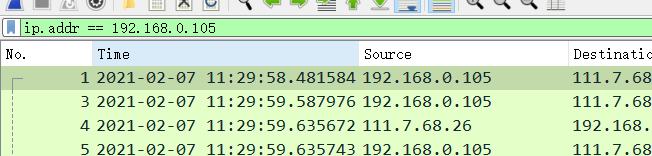
打开Wireshark,然后在过滤器中输入“ip.addr==your_IP_address”,您可以先使用ipconfig获取你的IP地址。此过滤器将删除既从你主机不发出也不发往你主机的所有数据包。
-
在Wireshark中启动数据包捕获。
-
使用浏览器访问网页: http://www.ietf.org
-
停止数据包捕获。
如果您无法在你的网络连接上运行Wireshark,则可以下载一个捕获了数据包的文件,这个文件是本书作者在自己计算机上 按照上述步骤捕获的(原文注:Download the zip file http://gaia.cs.umass.edu/wireshark-labs/wireshark-traces.zip and extract the file dnsethereal-trace-1. The traces in this zip file were collected by Wireshark running on one of the author’s computers, while performing the steps indicated in the Wireshark lab. Once you have downloaded the trace, you can load it into Wireshark and view the trace using the File pull down menu, choosing Open, and then selecting the dns-ethereal-trace-1 trace file. )。回答下列问题。您应该在解答中尽可能展示你使用了哪些你捕获到的数据包,并注释出来(原文注:What do we mean by “annotate”? If you hand in a paper copy, please highlight where in the printout you’ve found the answer and add some text (preferably with a colored pen) noting what you found in what you ‘ve highlight. If you hand in an electronic copy, it would be great if you could also highlight and annotate. )。若要打印数据包,请使用文件->打印,只勾选仅选中分组,和概要行,并选中你所需要用于解答问题的数据包。
-
找到DNS查询和响应消息。它们是否通过UDP或TCP发送?
通过UDP协议——User Datagram Protocol
-
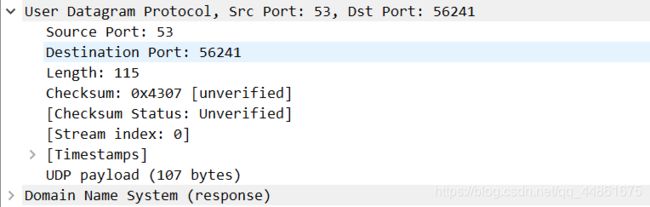
DNS查询消息的目标端口是什么? DNS响应消息的源端口是什么?
DNS查询消息的目标端口是53号
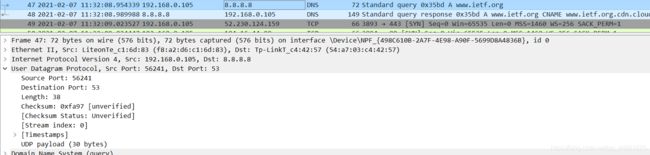
DNS响应源端口为53号
-
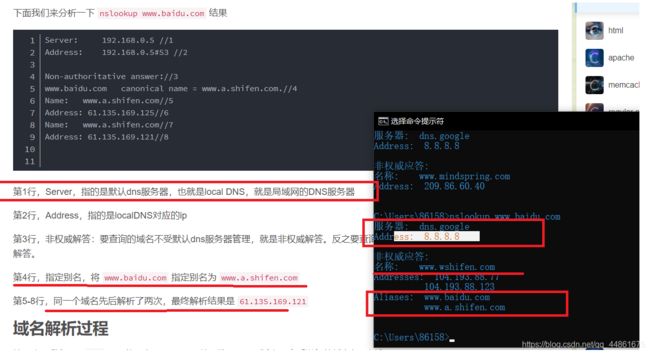
DNS查询消息发送到哪个IP地址?使用ipconfig来确定本地DNS服务器的IP地址。这两个IP地址是否相同?
8.8.8.8,谷歌DNS。
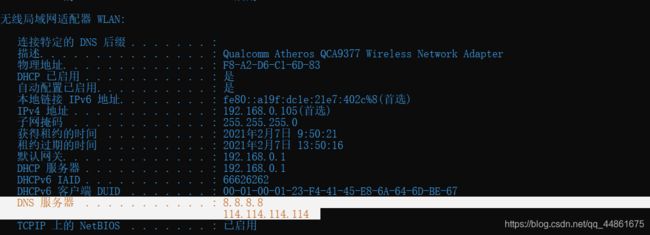
-
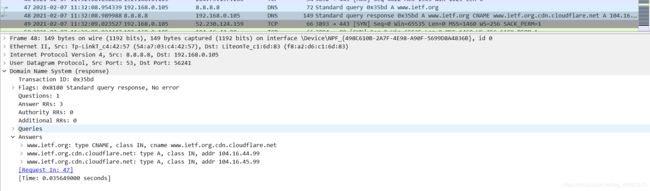
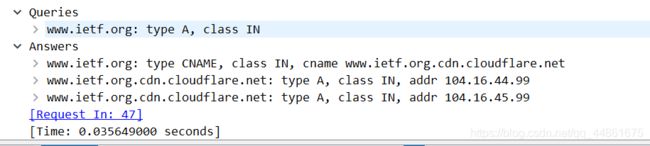
检查DNS查询消息。DNS查询是什么"Type"的?查询消息是否包含任何"answers"?
DNS查询是A类型,查询信息不包含任何“answers”。下面是DNS响应消息:
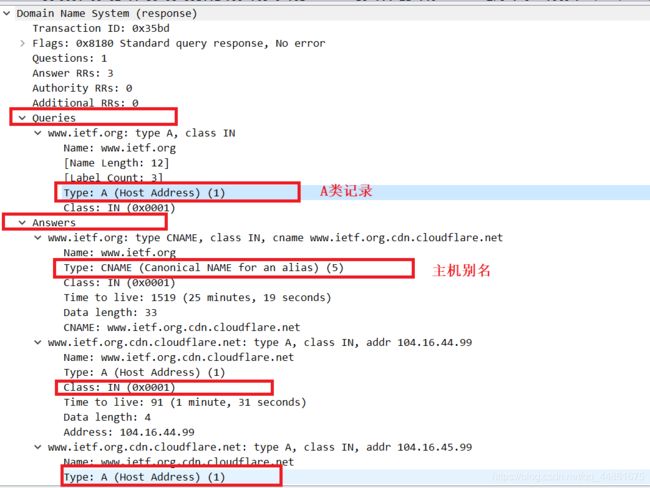
-
检查DNS响应消息。提供了多少个"answers"?这些答案具体包含什么?
从上图可以看到,有3个answers,第一个是查询到的主机别名,第二个是主机的ip,第三个是主机的ip
-
考虑从您主机发送的后续TCP SYN数据包。 SYN数据包的目的IP地址是否与DNS响应消息中提供的任何IP地址相对应?
是相对应的。

-
这个网页包含一些图片。在获取每个图片前,您的主机是否都发出了新的DNS查询?
并不是。只是部分重新发出新的DNS查询。
现在让我们玩玩nslookup(原文注:If you are unable to run Wireshark and capture a trace file, use the trace file dns-ethereal-trace-2 in the zip file http://gaia.cs.umass.edu/wireshark-labs/wireshark-traces.zip )。
- 启动数据包捕获。
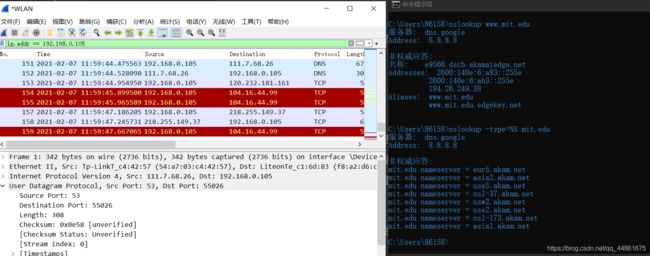
- 使用nslookup查询 www.mit.edu
- 停止数据包捕获。
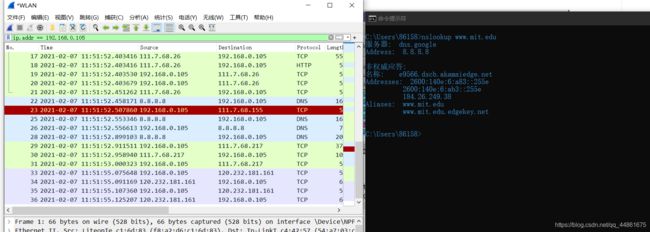
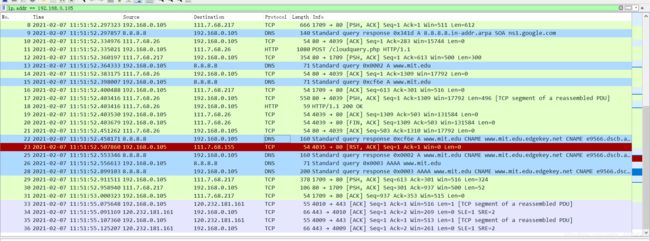
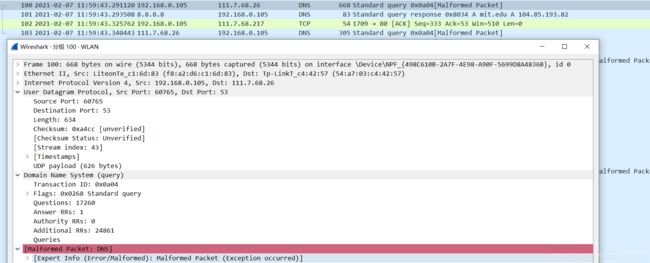
我们从上面的屏幕截图看到,nslookup实际上发送了三个DNS查询,并收到了三个DNS响应。只考虑本次实验相关结果,在回答以下问题时,请忽略前两组查询/响应,因为nslookup的一些特殊性,这些查询通常不是由标准网络应用程序生成的。您应该专注于最后一个查询和响应消息。
-
DNS查询消息的目标端口是什么? DNS响应消息的源端口是什么?
DNS查询消息的目标端口为53号:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DuISRfSc-1612671681894)(C:\Users\86158\AppData\Roaming\Typora\typora-user-images\image-20210207115417375.png)]
DNS响应消息的源端口是53:

-
DNS查询消息的目标IP地址是什么?这是你的默认本地DNS服务器的IP地址吗?
8.8.8.8,是。
-
检查DNS查询消息。DNS查询是什么"Type"的?查询消息是否包含任何"answers"?

查询消息不包含任何的answers。
-
检查DNS响应消息。提供了多少个"answers"?这些答案包含什么?
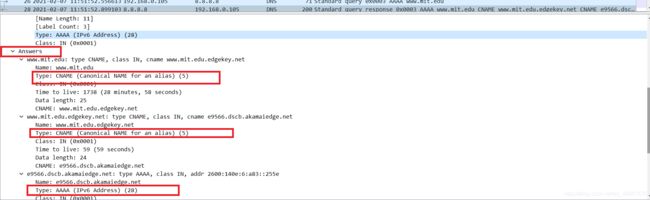
如图,提供了3个answers,第一个是www.mit.edu主机别名的记录,第二个还是www.mit.edu.edgekey.net主机别名的记录,第三个是IPV6类的IP地址 -
提供屏幕截图。
现在重复上一个实验,但换成以下命令:
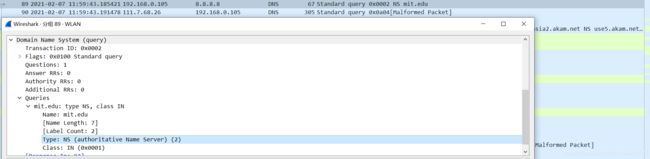
nslookup -type=NS mit.edu
回答下列问题:
-
DNS查询消息发送到的IP地址是什么?这是您的默认本地DNS服务器的IP地址吗?
是本地DNS服务器IP地址
-
检查DNS查询消息。DNS查询是什么"Type"的?查询消息是否包含任何"answers"?
NS类型
-
检查DNS响应消息。响应消息提供的MIT域名服务器是什么?此响应消息还提供了MIT域名服务器的IP地址吗?

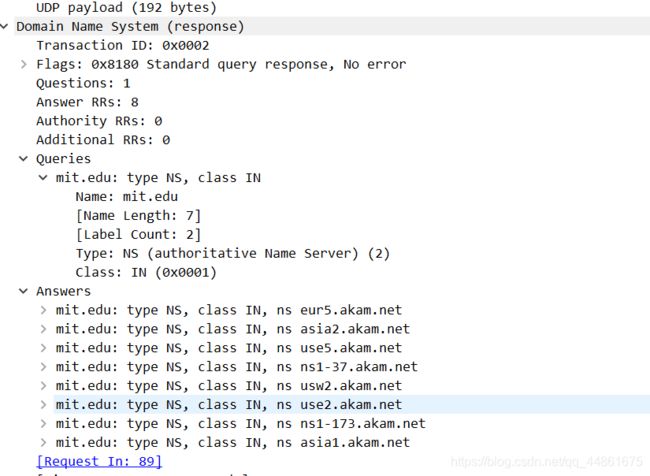
域名服务器是eur5.akam.net。
- 提供屏幕截图。
现在重复上一个实验,但换成以下命令:
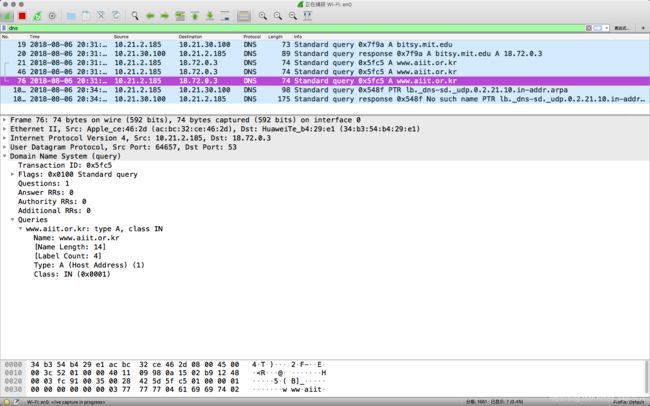
nslookup www.aiit.or.kr bitsy.mit.edu
回答下列问题:
-
DNS查询消息发送到的IP地址是什么?这是您的默认本地DNS服务器的IP地址吗?如果不是,这个IP地址是什么?
DNS第一次查询消息发送的IP地址是默认的本地域名服务器,查询到bitsy.mit.edu的IP地址:18.72.0.3,之后向这个IP地址发送查询消息,但失败了,因为MIT的这个DNS服务器已停用
-
检查DNS查询消息。DNS查询是什么"Type"的?查询消息是否包含任何"answers"?
Type A, 不包含任何"answer"
-
检查DNS响应消息。提供了多少个"answers"?这些答案包含什么?
因为查询失败,提供了0个“answer”
-
提供屏幕截图。