嵌入式软件
嵌入式软件
一、C语言
1.1、局部变量能否和全局变量重名
能,局部会屏蔽全局
1.2、如何用C编写死循环
while (1){} 或者 for ( ; ; )
1.3、new和malloc
1)、new和delete是C++的关键字,不需要头文件,需要编译器支持;malloc和free是C/C++的库函数,需要带头文件stdlib.h
2)、使用new操作符申请内存分配时,无需制定内存块的大小,编译器会根据类型信息自行计算;而malloc则需要支持本地所分配的大小。
1.4、static的用法(定义和用途)
static限制作用域
在C语言中,关键字static有三个明显的作用:
1)、用static修饰局部变量:使其变为静态存储方式,那么这个局部变量执行完成时不会被释放,继续保留在内存中。
2)、用static修饰全局变量:使其在本文件内部有效,而其他文件不可以被引用或链接该变量。
3)、用static修饰函数:使函数只在本文件内部有效,对其他文件不可见,这样的函数又叫静态函数;使用静态函数的好处,不用担心与其他文件的同名函数产生干扰,也是对函数本身保护的一种机制。
1.5、const的用法(定义与用途)
const主要用来修饰变量、函数形参和类成员函数:
1)、用const修饰常量:定义时就初始化,以后不能修改。
2)、用const修饰形参:func (const int a) {} 该函数在函数内不能改变。
3)、用const修饰成员函数:该函数对成员变量只能进行只读操作,就是不能修改成员变量的数值。
下面声明都是什么意思?
const int a;
int const a;
const int *a;
int *const a;
int const * a const;
第一个和第一个作用是一样的,a是常整型数。
第三个意味着a是一个指向整型数的指针。(整型数不可修改,但指针可以)
第四个意思是a是一个指向整型数的常数的指针。(指针指向的整型数是可以修改的,但指针是不可修改的)
第五个意味着a是一个指向整型数的常指针。(指针指向的整型数是不可修改的,同时指针也是不可修改的)
结论和记忆方法:
(1) const在*前面,就表示const作用于p所指向的量。所以这时候p所指向的是个常量。
(2) const在*后面,表示p本身是常量,但是p指向的不一定是常量。
(3) *在const中间,表示p本身是常量,p指向的也是个常量。
1.6、const常量和#define的区别(编译阶段、安全性、内存占用等)
用#define max 100; 定义的常量没有类型(不进行类型安全检查,可能会出现意想不到的错误),所给出的是一个立即数,编译器只是把所定义的常量值与所在的常量名字联系起来,define所定义的宏变量在预处理阶段的时候进行替换,在程序中使用到该常量的地方都要进行拷贝替换。
用const int max = 255; 定义的常量有类型(编译时会进行类型检查)名字,存储在静态区域中,在编译时确定其值。在程序运行过程中const变量只有一个拷贝,而#define所定义的宏变量却又多个拷贝,所以宏定义在程序运行过程中所消耗的内存比const变量的大很多。
1.7、volatile作用和用法
一个定义为volatile的变量是说这变量可能被意想不到的改变,这样不会假设这个变量的值了。
以下几种情况都会用到volatile:
1)、并行设备的硬件存储器。
2)、一个中断服务子程序会访问到的非自动变量。
3)、多线程应用中被几个任务共享的变量。
1.8、变量的作用域(全局变量和局部变量)
全局变量:
在所有函数体外部定义,程序所在的部分(甚至其他文件中的代码)都可以使用。
全局变量不受作用域的影响(也就是全局变量的生命周期一直到程序的结束)。
局部变量:
出现在一个作用域内,它们是局限于一个函数的。
局部变量经常被称为自动变量,它们进入作用域时自动生成,离开作用域时自动消失。
关键字auto可以显示说明这个问题,但是局部变量默认为auto,所以没有必要声明auto。
局部变量可以和全局变量重名,在局部变量作用域范围内,全局变量失效,采用的是局部变量的值。
1.9、sizeof与strlen(字符串,数组)
1)、如果是数组:
#include 运行结果:
sizeof 数组名=20
sizeof *数组名=4

2)、如果是指针,sizeof只会检测到指针的类型,指针都是占用4字节的空间(32位机器)。
sizeof是什么? 是一个操作符,也是关键字,就不是一个函数,这和strlen()不同,strlen()是一个函数。
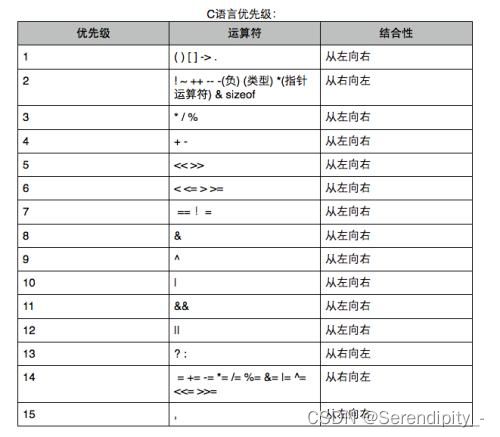
1.10、与或非,异或。运算符优先级
1.11、递归函数与回调函数的区别是什么?
答:回调是一个函数把非当前函数当做参数传递到自身内部来调用;而递归是自己调用自己。
1.12、为什么要用回调函数呢?
答:我们对回调函数的使用无非是对函数指针的应用,函数指针的概念本身很简单,但是把函数指针应用于回调函数就体现了一种解决问题的策略,一种设计系统的思想。
1.13、系统调用和函数调用的区别
系统调用是最底层的应用,是面向硬件的。而库函数的调用是面向开发的,相当于应用程序的API(即预先定义好的函数)接口。
1.14、段错误发生的原因
段错误:是指访问的内存超过了系统给程序分配的内存空间
原因:
访问不存在的内存空间
访问只读的内存空间
访问系统保护的内存空间
栈溢出
1.15、什么时候会造成内存泄漏
常见的内存泄漏
(1)内存分配未成功,却使用了它
(2)内存分配成功,但尚未初始化就引用它
(3)内存分配成功且初始化,但操作越过了内存的边界
(4)忘记释放内存,造成内存泄漏
(5)释放了内存却继续使用它
1.16、什么是大小端模式
0x123456在内存中的存储方式:
大端模式 低地址—>高地址 0x12 | 0x34 | 0x56
小端模式 低地址—>高地址 0x56 | 0x34 | 0x12
指针方式来判断机器的大小端
#include 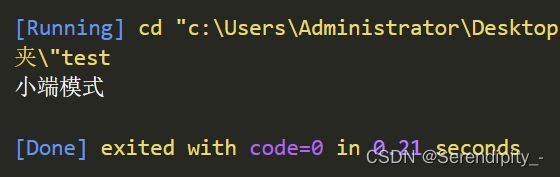
1.17、全局变量可以声明定义在头文件中?
注意头文件中不可以放变量的定义!!!一般情况下头文件中只放变量的声明,因为头文件要被其他文件包含(即#include),如果把定义放到头文件的话,就不能避免多次定义变量,C++不允许多次定义变量,一个程序中对指定变量的定义只有一次,声明可以无数次。
1.18、C语言中各种数据类型与“0”的比较详解
(1)int类型数据和0比较
if (a == 0) 或者 if (a != 0)
(2)float类型与0比较
const float N = 0.0001;
if ((a >= N) && (a <= N))
不建议写成:
if (a == 0) 或者 if (a != 0)
(3)bool类型与0比较
建议写成:if (a) 或者 if (!a)
(4)指针类型与0比较
if (p == NULL) 或者 if (p != NULL)
1.19、C语言中什么是位段
位段(bit-field)是以位为单位来定义结构体(或联合体)中的成员变量所占的空间。含有位段的结构体(联合体)称为位段结构。采用位段结构既能够节省空间,又方便于操作。
1.20、简述什么是地址传递和值传递,并简述两者的区别
值传递只是将变量的内容复制一份而已,函数进行操作的其实是另一个变量,只是另一个变量的值和传递的变量值是相同的。
而地址传递是直接把变量的地址传递给函数,这时函数是直接对原来的变量进行操作的。所以值会变化。
1.21、C语言中调用函数如何返回多个值
通过使用指针,在函数调用时,传递带有地址的参数,并使用指针更改其值;这样,修改后的值就会变成原始参数。
1.22、函数中能否返回一个局部变量地址
一般来说,函数是可以返回局部变量的。局部变量的作用域只在函数内部,在函数返回后,局部变量的内存已经释放了。
1.23、栈的特点是什么
栈的特点是先进后出。栈是一种只能在一端进行插入和删除操作的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据。
1.24、C语言中用了#define,作用范围是从哪到哪
define只在当前文件有效,如果是在头文件中定义的,则引用过头文件的文件都有效
1.25、C语言中定义常量有几种方式
定义常量PI的两种方式:
#define PI 3.1415926f;
const float pi 3.1415926f;
1.26、程序的局部变量存在于哪里,全局变量存在于哪里,动态申请数据存在于哪里。
程序的局部变量存在于栈区;
全局变量存在于静态区;
动态申请数据存在于堆区。
1.27、do……while和while有什么区别?
do……while是先循环再判断,while是先判断再循环。
二、Linux
2.1、Linux内核的组成部分
Linux内核主要由五个子系统组成:进程调度,内存管理,虚拟文件系统,网络接口,进程间通信。
2.2、Linux系统的组成部分
Linux系统一般有4个主要部分:内核、shell、文件系统和应用程序。
2.3、系统调用与普通函数调用的区别
1)、系统调用:
· 使用INT和IRET指令,内核和应用程核态,从而可以使用特权指令操控设备
· 依赖于内核,不保证移植性
· 在用户空间和内核上下文环境间切换
· 是操作系统的一个入口点
2)、普通函数调用:
· 使用CALL和RET指令,调用时没有堆
· 平台移植性好
· 属于过程调用,调用开销较小
· 一个普通功能函数的调用
2.4、内核态,用户态的区别
内核态,操作系统在内核态运行—运行操作系统程序
用户态,应用程序只能再用户态运行—运行用户程序
2.5、BootLoader、内核、根文件的关系
启动顺序:bootloader→linux kernel→rootfile→app
2.6、BootLoader启动的两个阶段
Stage1:汇编语言
Stage2:C语言
2.7、Linux下检查内存状态的命令
查看进程:top
查看内存:free
cat/proc/meminfo
vmstat
2.8、一个程序从开始运行到结束的完整过程(四个过程)
预处理(Pre-Processing)、编译(Compiling)、汇编(Assembling)、链接(Linking)
2.9、什么是堆,栈,内存泄漏和内存溢出?
栈由系统操作,程序员不可以操作。
所以内存泄漏是指堆内存的泄漏。
堆内存是指程序从堆中分配的,大小任意的,使用完后必须显示释放的内存。应用程序一般使用malloc,new等函数从堆中分配到一块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块,否则,这块内存就不能被再次使用。
内存溢出:你要求分配的内存超出了系统能给你的,系统不能满足需求,于是产生溢出。
内存越界:向系统申请了一块内存,而在使用内存时,超出了申请的范围(常见的有使用定大小数组时发生内存越界)
内存溢出问题是C语言或者C++语言所固有的缺陷,它们既不检查数组边界,又不检查类型可靠性(type-safety)。
2.10、死锁的原因、条件
产生死锁的原因主要是:
1)、因为系统资源不足
2)、进程运行推进的顺序不合适
3)、资源分配不当等
2.11、硬链接与软链接
1)、硬链接
硬链接只能引用同一文件系统中的文件。它引用的是文件在文件系统中的物理索引(也称为inode)。当你移动或删除原始文件时,硬链接不会被破坏,因为它所引用的是文件的物理数据而不是文件在文件结构中的位置。
硬链接的文件不需要用户有访问原始文件的权限,也不会显示原始文件的位置,这样有助于文件的安全。如果你删除的文件有相应的硬链接,那么这个文件依然会保留,直到所有对它的引用都被删除。
2)、软链接
软链接,其实就是新建立的一个文件,这个文件就是专门用来指向别的文件的(那就和Windows下的快捷方式的那个文件有很接近的意味)
软链接产生的是一个新的文件,但这个文件的作用就是专门指向某个文件的,删除了这个软链接文件,那就等于不需要这个链接,和原来的存在的实体原文没有任何关系,但删除原来的文件,则相应的软链接不可用。
2.12、中断和异常的区别
内中断:同步中断(异常)是由CPU内部的电信号产生的中断,其特点为当前执行的指令结束后才转而产生中断,由于有CPU主动产生,其执行点必然是可控的。
外中断:异步中断是由CPU的外设产生的电信号引起的中断,其发生的时间点不可预期。
2.13、中断怎么发生,中断处理流程
请求中断→响应中断→关闭中断→保留断点→中断源识别→保护现场→中断服务子程序→恢复现场→中断返回。
2.14、Linux下编译优化选项
加: -o
2.15、Linux命令
1)、改变文件属性的命令:chmod
2)、查找文件中匹配字符串的命令: grep
3)、查找当前目录:pwd
4)、删除目录:rm -rf 目录名
5)、删除文件:rm 文件名
6)、创建目录(文件夹):mkdir
7)、创建文件:touch
8)、vi和vim文件名 也可以直接创建
9)、解压:tar -xzvf 压缩包
10)、打包:tar -cvzf 目录(文件夹)
11)、查看进程对应的端口号
1、先查看进程pid
ps -ef | grep 进程名
2、通过pid查看占用端口
netstat -nap | grep 进程pid
2.16、硬实时系统和软实时系统
软实时系统:
Windows、Linux系统通常为软实时,当然有补丁可以将内核做成硬实时的系统的。
硬实时系统:
对时间要求很高,限定时间内不管做没做完必须返回
VxWorks,uCOS,FreeRTOS,WinCE,RT-thread等实时系统。
三、数据结构
3.1、十大排序
1、冒泡排序; 2、选择排序; 3、插入排序; 4、希尔排序; 5、归并排序; 6、快速排序; 7、堆排序; 8、计数排序; 9、桶排序; 10、基数排序
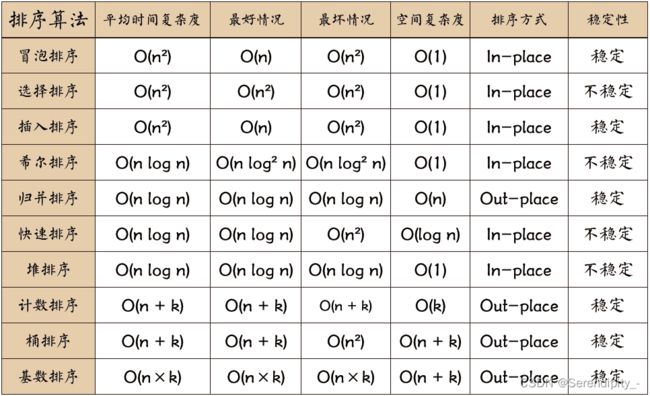
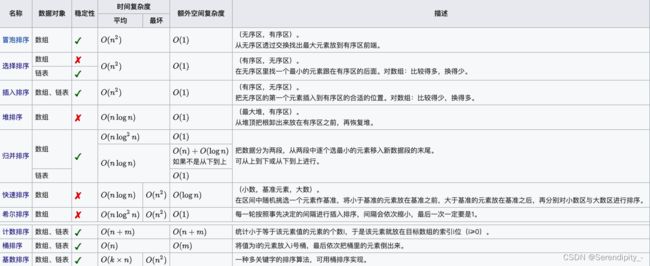
对于这十大排序的考察主要有两点:
1、考察时间复杂度、空间复杂度、稳定与否
2、手写某种排序
第一点:对于时间复杂度的考察,可能会考察插入排序的平均复杂度是多少?最坏和最好复杂度又是多少?有时候也会从别的角度来对你进行考察,直接会问你了解到的排序中哪些排序是稳定的?哪些不是稳定的?
第二点:快速排序手写次数绝对占据第一名,因为现在企业招聘基本都是有代码要求的,有时候面试官可能也拿不准让你写什么算法题,“算了,写个快排吧”,快排的频率就是这样被拉高的; 第二高频率的应该就是归并排序了。
归并是刚好比快排难度大一点,但也不是那种特别难的排序方法。让手写的还可能有堆排序。
十大排序中考察最多的就是冒泡排序、快速排序、归并排序、堆排序以及可能会出现的桶排序和基数排序了,其余排序出现的概率稍小一点。
1.0 十大经典排序算法 | 菜鸟教程 (runoob.com)
3.2、算法
嵌入式考察算法大多都是双向链表、二叉树、字符串翻转和复制这些普通题目。刷题可以在LeetCode、牛客网、杭电OJ等。
十种常见排序算法可以分为两大类:
非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn), 因此称为非线性时间比较类排序。
线性时间非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。
3.3、队列和栈的区别有什么?
栈:栈(stack)又名堆栈,线性表。仅允许在表的一端进行插入和删除运算。一端为栈顶,另一端为栈底,先进后出。
队列:队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
3.4、顺序表和链表它们的特点?
线性表存储数据,需要预先申请一块内存空间,然后将数据按照次序逐一存储,数据之间紧密贴合,不留一丝空隙。
链表的存储方式与顺序表截然相反,什么时候存储数据,什么时候才申请存储空间,数据之间的逻辑关系依靠每个数据元素携带的指针维持。
3.5、什么是完全二叉树
如果二叉树中除去最后一层节点为满二叉树,且最后一层的节点依次从左到右分布,则此二叉树被称为完全二叉树。
3.6、什么是二叉树
树有很多种,每个节点最多只能有两个子节点的叫二叉树
二叉树的子节点分为左节点和右节点
3.7、七大查找算法
顺序查找; 二分查找; 插值查找; 斐波那契查找; 树表查找; 分块查找; 哈希查找。
3.8、十大排序算法
1、冒泡排序; 2、选择排序; 3、插入排序; 4、希尔排序; 5、归并排序; 6、快速排序; 7、堆排序; 8、计数排序; 9、桶排序; 10、基数排序
3.9、怎样判断一个算法的优劣?
时间复杂度;空间复杂度
3.10、“算法”的基本特征有哪些?
一个算法应该具有以下五个重要的特征:
1、有穷性(Finiteness)
2、确切性(Definiteness)
3、输入项(Input)
4、输出项(Output)
5、可行性(Effectiveness)
3.11、什么是哈希表
根据关键码值而直接进行访问的数据结构
3.12、如何判断单链表是否存在环
方法一、穷举遍历
方法二、哈希表缓存
方法三、快慢指针
方法四、Set集合大小变化
3.13、删除链表中倒数第n个节点
要删除倒数第n个节点,我们就要找到其前面一个节点,也就是倒数第n+1个节点,找到这个节点就可以进行删除;
定义两个指针,p和cur,cur指针向前走,走了n+1步之后,p指针开始走,当cur指针走到链表结尾的时候,p指针刚好走到倒数第n+1个节点处。
3.14、循环队列有什么用
为充分利用向量空间,克服“假溢出”现象的方法是:将向量空间想象为一个首尾相接的圆环,并称这种向量为循环向量。
四、进程与线程
4.1、什么是进程、线程,它们有什么区别
进程是资源(CPU、内存等)分配的基本单位,线程是CPU调度和分配的基本单位(程序执行的最小单位)。
同一时间,如果CPU是单核,只有一个进程在执行,所谓的并发执行,也是顺序执行,只不过由于切换太快,误以为这些进程同步执行。多核CPU可以同一时间点多个进程在执行。
4.2、多进程与多线程的优缺点
1)、一个进程死了不影响其他进程,一个线程崩溃很可能影响到其他线程
2)、创建多进程的系统花销大于创建多线程。
3)、多进程通讯因为需要跨越进程边界,不适合大量的数据传送,适合小数据或者密集的数据传送。多线程无需跨越进程边界,适合各线程间的大量传送。并且多线程跨越共享同一进程的共享内存和变量。
4.3、什么时候使用进程,什么时候用线程
进程间通讯:
(1)、有名管道、无名管道; (2)、信号灯集; (3)、共享内存; (4)、消息队列; (5)、信号量; (6)socket
线程通讯(锁):
(1)、信号量; (2)、读写锁; (3)、条件变量; (4)、互斥锁; (5)、自旋锁
4.4、父进程、子进程
父进程调用fork()以后,克隆出一个子进程,子进程和父进程拥有相同内容的代码段、数据段和用户堆栈。
父进程和子进程谁先执行不一定,看CPU。所以我们一般会设置父进程等待子进程执行完毕。
4.5、fork的作用是什么
在Linux下产生新的进程的系统调用就是fork函数
4.6、fork和vfork的区别
· fork(): 子进程拷贝父进程的数据段,代码段
vfork(): 子进程与父进程共享数据段
· fork() 父子进程的执行次序不确定
vfork() 保证子进程先运行,在调用exec或exit之前与父进程数据是共享的,在它调用exec或exit之后父进程才可能被调度运行。
4.7、进程的开销比线程大在了哪里?
创建进程需要为进程划分出一块完整的内存空间,有大量的初始化操作,比如要把内存分段(堆栈,正文区等)。
创建线程则简单得多,只需要确定PC指针和寄存器的值,并且给线程分配一个栈用于执行程序,同一个进程的多个线程间可以复用堆栈。
因此,创建进程比创建线程慢,而且进程的内存开销更大。
4.8、什么是阻塞,什么是非阻塞
阻塞调用是指调用结果返回之前,当前线程就会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
4.9、同步和互斥
互斥:是指散布在不同任务之间的若干程序片段,当某个任务运行其中一个程序片段时,其他任务就不能运行它们之中的任一程序片段,只能等到该任务运行完这个程序片段后才可以运行。
同步:是指散布在不同任务之间的若干程序片段,它们的运行必须严格按照规定的某种先后次序来运行,这种先后次序依赖于要完成的特定的任务。
4.10、申请互斥锁的过程
// 头文件
#include 1)初始化互斥锁
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr);
2)上锁
int pthread_mutex_lock(pthread_mutex_t *mutex);
3)解锁
int pthread_mutex_unlock(pthread_mutex_t * mutex);
4)销毁互斥锁
int pthread_mutex_destroy(pthread_mutex_t *mutex);
4.11、创建守护进程的步骤
(1)创建子进程,父进程退出
(2)子进程下创建新的会话
(3)设置当前目录为根目录
(4)设置文件权限掩码
(5)退出文件描述符
4.12、指出静态库和共享库的区别
静态库编译时程序较大,可以独立运行。
动态库编译时程序较小,不可独立运行。
4.13、什么是IO多路复用
I/O通常指网络I/O,多路指多个Socket连接,复用指操作系统进程运算调度的最小单位线程。整体意思也就是多个网络I/O复用一个或少量的线程来处理Socket。
I/O多路复用有多种实现模式:select、poll、epoll、kqueue
4.14、进线程的区别
线程依赖于进程,同一进程的多个线程共享这一进程的资源。所以进程间的切换会比线程更加耗时。
4.15、一个程序中最多创建多少个线程
一个线程的栈要预留1M的内存空间,而一个进程中可用的内存空间只有2G,所以理论上一个进程中最多可以开2048个线程,但是内存当然不可能完全拿来作线程的栈,所以实际数目要比这个值要小。
4.16、文件IO中的文件描述符
对于Linux而言,所有对设备或文件的操作都是通过文件描述符进行的。
4.17、线程中的同步应该怎么实现
当使用多个线程来访问同一个数据时,非常容易出现线程安全问题(比如多个线程都在操作同一数据导致数据不一致),所以我们用同步机制来解决这些问题。
4.18、进程间通信消息队列的机制
消息队列与命名管道有许多类似之处,但少了在打开和关闭管道时的复杂性。但使用消息队列并未解决我们在使用命名管道时遇到的问题,比如管道满时的阻塞问题。
与命名管道相比,消息队列的优势在于,它独立于发送和接收进程而存在,这消除了再同步命名管道的打开和关闭时可能产生的一些困难。
4.19、什么是进程池
进程池的作用是在多个客户端并发请求时提高服务器的处理效率。
4.20、进程之间通信的途径有哪些?
进程间通讯方式有:管道,信号灯集,信号量,消息队列,共享内存,套接字共六种。
4.21、产生死锁的原因是什么?
系统资源有限。
进程推进顺序不合理。
4.22、进程和线程有什么区别?
进程是资源分配的最小单位。
线程是程序执行的最小单位。
五、网络编程
5.1、TCP、UDP的区别
TCP→传输控制协议,提供面向对象连接、可靠的字节流服务。当客户端和服务器交换数据前,必须在双方之间建立一个TCP连接,之后才能传输数据。
UDP→用户数据报协议,是一个简单的面向数据报的运算层协议。UDP不提供可靠性,它是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。
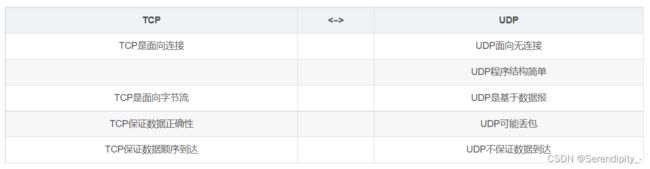
5.2、TCP、UDP的优缺点
TCP优点:可靠稳定
TCP的可靠体现在TCP在传输数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、阻塞控制机制,在数据传完之后,还会断开连接用来节约系统资源。
TCP缺点:慢、效率低、占用系统资源高、容易被攻击
在传递数据之前要建立连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、阻塞机制等会消耗大量时间,而且每台设备上维护所有的传递连接。
UDP优点:快,比TCP稍安全
UDP没有TCP拥有各种机制,是一种无状态的传输协议,所以传输数据非常快,没有TCP整型机制,被攻击的机会就会少一些,但是也是无法避免被攻击。
UDP缺点:不可靠、不稳定
因为没有TCP的这些机制,UDP在传输数据时,如果网络质量不好,就会容易丢包,造成数据的缺失。
5.3、TCP、UDP适用场景
TCP:传输一些对信号完整性,信号质量有要求的信息。
UDP:对网络通信质量要求不高时,要求网络通信速度要快的场景。
5.4、TCP为什么是可靠连接
因为TCP传输的数据满足3大条件,不丢失,不重复,按顺序到达。
5.5、OSI典型网络模型


5.6、三次握手、四次挥手
1)、三次握手过程
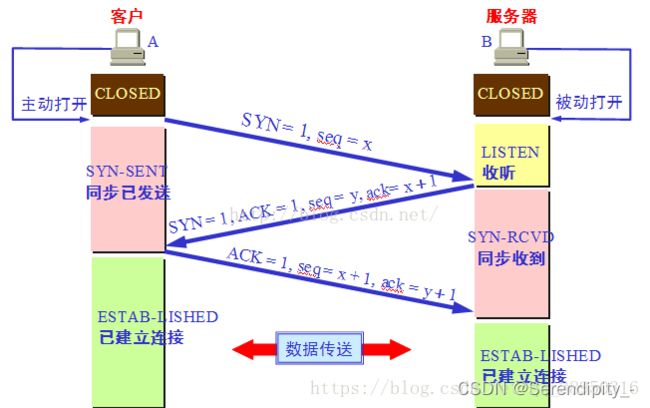
· 第一次握手:建立连接时,客户端发送syn包(syn=x)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)
· 第二次握手:服务器收到SYN包,必须确认客户端的SYN(ack=x+1),同时自己也发送一个SYN包(syn=y),即SYN+ACK包,此时服务器进入SYN_RECV状态;
· 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
TCP/IP建立连接时三次握手过程:
第一次:建立连接时,客户端向服务器发送连接请求,进入SYN_END状态,并等待服务器确认。
第二次:服务器收到客户端连接请求,并向客户端发送允许连接应答,进入SYN_RECV状态。
第三次:客户端收到服务器允许连接应答,并向服务器发送确认连接,此时客户端和服务器进入通信状态,三次握手完成。
2)、四次挥手过程
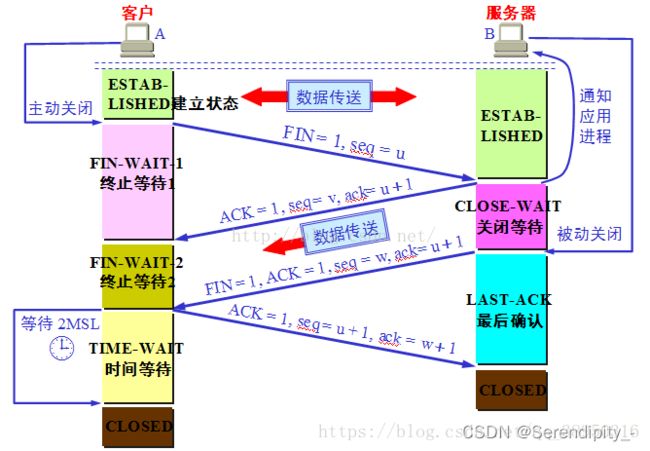
第一次:客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
第二次:服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
第三次:客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
第四次:服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次挥手?
答:
三次握手时,服务器同时把ACK和SYN放在一起发送到了客户端那里。
四次挥手时,当收到对方的 FIN 报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方是否现在关闭发送数据通道,需要上层应用来决定,因此,己方 ACK 和 FIN 一般都会分开发送
【问题2】为什么客户端最后还要等待2MSL?
答:客户端需要保证最后一次发送的ACK报文到服务器,如果服务器未收到,可以请求客户端重发,这样客户端还有时间再发,重启2MSL计时。
【问题3】为什么不能用两次握手进行连接?
答:三次握手完成两个重要的功能,既要双方做好发送数据的准备工作(双方都知道彼此已准备好),也要允许双方就初始序列号进行协商,这个序列号在握手过程中被发送和确认。
【问题4】如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
5.7、常见网络协议
TCP/IP协议
NetBEUI
IPX/SPX协议
5.8、处理粘包问题
解决粘包问题:就是转换成发送数据和接收数据的格式
发送数据:发送数据,先发送数据的长度,然后再发送真是数据的字节数
接收数据:接收真实数据的长度,然后再按字节长度接收数据;
5.9、ip地址分了多少类
A类:0~127.255.255.255
B类:128 ~ 191.255.255.255
C类:192 ~ 223.255.255.255
D类:224 ~ 239.255.255.255
E类:240 ~ 255.255.255.255
六、C++
最喜欢问的莫过于strlen与sizeof的区别、explicit关键字、mutable关键字、指针和引用、public、protected、private三者在继承情况下的一些访问权限、菱形继承、友元函数等。
6.1、构造和析构的作用
构造函数只是起初始化值的作用,但实例化一个对象的时候,可以通过实例去传递参数,从主函数传递到其他的函数里面,这样就使其他的函数里面有值了。
析构函数与构造函数的作用相反,用于撤销对象的一些特殊任务处理,可以是释放对象分配的内存空间。
特点:析构函数与构造函数同名,但该函数前面加~。 析构函数没有参数,也没有返回值,而且不能重载
6.2、继承是做什么的?
继承是指一个对象直接使用另一对象的属性和方法
6.3、多态是什么?
多态首先是建立在继承的基础上的,先有继承才有多态。多态是指不同的子类在继承父类后分别都重写覆盖了父类的方法,即父类同一方法,在继承的子类中表现出不同的形式。
6.4、面向对象中的对象指的是什么?
就是实例化了的类。类是属性和方法的封装。对象是这个类的具体实现。
6.5、类和对象的关系是什么?
对象是类实例化出来的,对象中含有类的属性,类是对象的抽象。
6.6、类的关键词用什么
class
6.7、如果想要在类的外部访问类
C public的类成员
可以作为虚函数的是普通函数,析构函数
6.8、友元有哪些呢?
友元函数就是以friend开头的一种破坏类的封装性的一种用法
友元类的私有和保护成员在类外不可以使用
6.9、继承的作用是什么?
继承是指在已存在的类的基础上扩展产生新的类。
意义:继承是面向对象程序设计的三大特征(封装、继承和多态)之一
6.10、组合和继承的区别是什么?
组合和继承是面向对象中两种代码复用的方式。组合是指在新类中创建原有类的对象,重复利用已有类的功能。继承是面向对象的主要特性之一,它允许设计人员根据其他类的实现来定义一个类的实现。
6.11、多态是指的什么?
多态首先是建立在继承的基础上的,先有继承才能有多态。多态是指不同的子类在继承父类后分别都重写覆盖了父类的方法,即父类同一个方法,在继承的子类中表现出不同的形式。多态成立的另一个条件是在创建子类时候必须使用父类new子类的方式。
6.12、什么是抽象类,抽象类怎么使用?
抽象类是特殊的类,只是不能被实例化;除此以外,具有类的其他特性;重要的是抽象类可以包括抽象方法,这是普通类所不能的。
如果预计要创建组件的多个版本,则创建抽象类。抽象类提供简单的方法来控制组件版本。
如果创建的功能将在大范围的全异对象间使用,则使用接口。如果要设计小而简练的功能块,则使用接口。
如果要设计大的功能单元,则使用抽象类.如果要在组件的所有实现间提供通用的已实现功能,则使用抽象类。
抽象类主要用于关系密切的对象;而接口适合为不相关的类提供通用功能。
6.13、malloc和new的区别?
malloc/free是标准库函数,new/delete是C++运算符
malloc失败返回空,new失败抛异常
new/delete会调用构造、析构函数,malloc/free不会,所以他们无法满足动态对象的要求。
new返回有类型的指针,malloc返回无类型的指针
6.14、深拷贝和浅拷贝的区别是什么?
浅拷贝(shallowCopy)只是增加了一个指针指向已存在的内存地址,
深拷贝(deepCopy)是增加了一个指针并且申请了一个新的内存,使这个增加的指针指向这个新的内存,使用深拷贝的情况下,释放内存的时候不会因为出现浅拷贝时释放同一个内存的错误。
七、Qt
八、ARM体系结构
8.1、讲一讲冯诺依曼和哈佛体系的区别
冯诺依曼结构:
程序和数据都放在内存中,且不彼此分离 的结构称为冯诺依曼结构。譬如Intel的 CPU均采用冯诺依曼结构。
哈佛结构:
程序和数据分开独立放在不同的内存块中, 彼此完全分离的结构称为哈佛结构。譬如 大部分的单(MCS51、 ARM9等)均采用哈佛结构。
8.2、什么是ARM体系架构
ARM体系结构包含有:
(1)结构
• 不同ARM体系采用不同指令集;
• 哈佛结构是将数据与指令分开存储并行;
• 冯诺依曼结构是混合存储的
(2)ARM工作模式
User 、FIQ、IRQ、System、Supervisor、Abort、Undef
(3)寄存器
ARM有37个寄存器
(4)ARM指令机器码
8.3、什么是异常
正常工作之外的流程都叫异常
九、系统移植
9.1、什么是设备树
设备树:用树型结构描述设备节点
十、驱动
10.1、什么是驱动?
控制硬件的软件
驱动是专门为系统编写的配置文件,没有驱动电脑便无法正常运行,简单来说,驱动是连接电脑和其他硬件的必备程序。
十一、Python
十二、单片机
12.1、IO口工作方式
上拉输入、下拉输入、推挽输出、开漏输出。
12.2、请说明总线接口USRT、I2C、USB的异同点
串/并、速度、全/半双工、总线拓扑等
12.3、IIC协议时序图
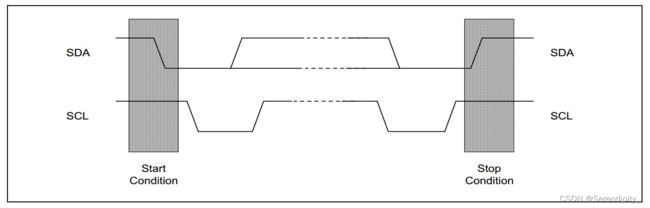
12.4、单片机的SP指针始终指向
栈顶
12.5、IIC总线在传送数据过程中共有三种类型的信号
它们分别是:开始信号、结束信号和应答信号。
12.6、FIQ中断向量入口地址
FIQ和IRQ是两种不同类型的中断,ARM为了支持这两种不同的中断,提供了对应的叫做FIQ和IRQ处理器模式(ARM有7种处理模式)。
FIQ的中断向量地址在0x0000001C,而IRQ的在0x00000018。
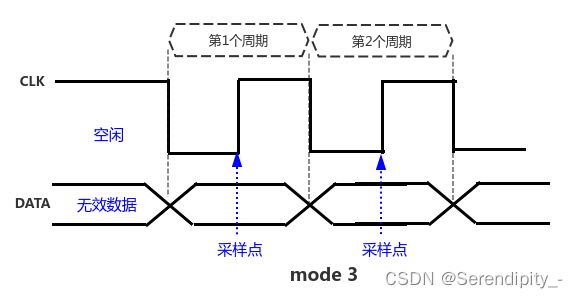
12.7、SPI四种模式,简述四种模式,并画出时序图
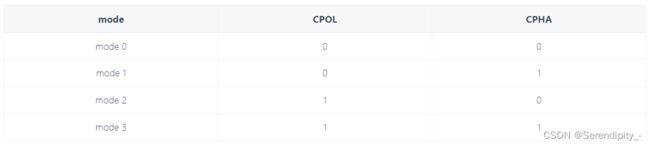
spi四种模式SPI的相位(CPHA)和极性(CPOL)分别可以为0或1,对应的4种组合构成了SPI的4种模式(mode)
Mode 0 CPOL=0, CPHA=0
Mode 1 CPOL=0, CPHA=1
Mode 2 CPOL=1, CPHA=0
Mode 3 CPOL=1, CPHA=1
SPI总线传输的4种模式
原文地址:SPI总线传输的4种模式 - 广漠飘羽 - 博客园 (cnblogs.com)
一、概述
在芯片的资料上,有两个非常特殊的寄存器配置位,分别是 CPOL (Clock POlarity)和 CPHA (Clock PHAse)。
CPOL配置SPI总线的极性
CPHA配置SPI总线的相位
极性和相位,这么专业的名词,非常难理解。我们不妨从时序图入手,了解极性和相位的效果。
二、SPI总线的极性
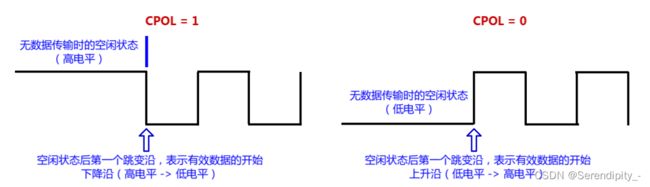
极性,会直接影响SPI总线空闲时的时钟信号是高电平还是低电平。
CPOL = 1:表示空闲时是高电平
CPOL = 0:表示空闲时是低电平
由于数据传输往往是从跳变沿开始的,也就表示开始传输数据的时候,是下降沿还是上升沿。
如下图:
三、SPI总线的相位
一个时钟周期会有2个跳变沿。而相位,直接决定SPI总线从那个跳变沿开始采样数据。
CPHA = 0:表示从第一个跳变沿开始采样
CPHA = 1:表示从第二个跳变沿开始采样

至于跳变沿究竟是上升沿还是下降沿,这取决于 CPOL。记住, CPHA 只决定是哪个跳变沿采样。
四、4种模式
CPOL 和 CPHA 的不同组合,形成了SPI总线的不同模式。
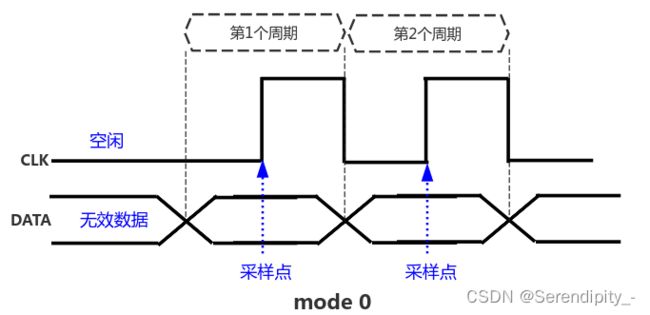
模式0 (CPOL=0; CPHA=0)
特性:
CPOL = 0:空闲时是低电平,第1个跳变沿是上升沿,第2个跳变沿是下降沿
CPHA = 0:数据在第1个跳变沿(上升沿)采样
效果图:
模式1 (CPOL=0; CPHA=1)
特性:
CPOL = 0:空闲时是低电平,第1个跳变沿是上升沿,第2个跳变沿是下降沿
CPHA = 1:数据在第2个跳变沿(下降沿)采样
效果图:
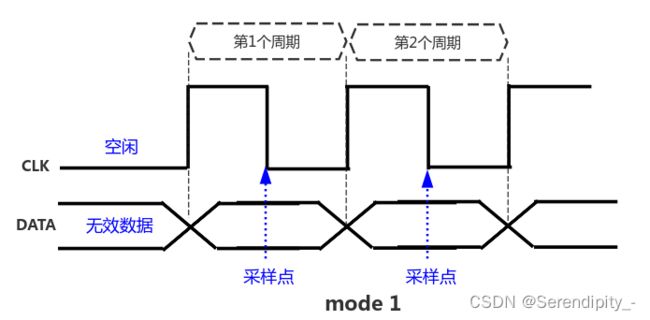
模式2 (CPOL=1; CPHA=0)
特性:
CPOL = 1:空闲时是高电平,第1个跳变沿是下降沿,第2个跳变沿是上升沿
CPHA = 1:数据在第2个跳变沿(上升沿)采样
效果图: