学习k8s的介绍(一)
一、kubernetes及Docker相关介绍
1、kubernetes是什么
1-1、简称为k8s或kube,是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。
声明式配置语法: kubectl create/apply/delete -f xxxx.yaml/json
- create:创建资源时,如果不存在该资源则创建,存在则创建失败
- apply:创建资源时,如果不存在该资源则创建,存在则进行更新
1-2、k8s是谷歌推出的业界最受欢迎的容器编排工具之一,由谷歌开源。它提供了广泛的功能,包括自动化部署、自动伸缩、负载均衡、自愈性和强大的配置管理。生态系统庞大,拥有大量的插件和工具,适用于复杂的容器应用场景。
自动化部署: 将容器应用程序部署到容器运行时环境中,无需手动干预。
伸缩性: 根据需求扩展或收缩容器实例,以适应流量和负载的变化。
负载均衡: 在多个容器实例之间分配流量,以确保高可用性和性能。
自愈性: 检测和自动处理容器故障,以确保应用程序的稳定性。
配置管理: 管理容器的配置,包括环境变量、密钥和证书等。
常见的容器编排器有:
- Docker Swarm:是Docker的官方容器编排工具,它专注于简化容器集群的管理,适用于小型和中型应用程序。
- Apache Mesos:是一个通用的集群管理器,可以用于管理容器、虚拟机和其他工作负载。适用于大型分布式系统。
1-3、应用部署的升级过程
- 传统部署时代:各机构是在物理服务器上运行应用程序,由于无法限制物理服务器运行的应用程序资源使用,因此会导致资源分配问题。如:某应用出现占用大部分资源时,而导致其他应用程序的性能下降。若每个应用程序独立一台物理服务器,可能会导致资源利用率不高,维护成本高的情况。
- 虚拟化部署时代:传统部署问题无法解决,因此虚拟化技术被引入。虚拟化技术允许在单个物理服务器的CPU上运行多台虚拟机(VM)。虚拟化能使应用程序在不同的VM之间被隔离,且能提供一定程度的安全性。虚拟化技术更好的利用了物理服务器的资源;并且可轻松添加或更新应用程序,具有更高的可伸缩性,以及降低了硬件成本等好处。
- 容器部署时代:容器类似于VM,但是更宽松的隔离特性,使容器之间可以共享操作系统(OS)。容器比起VM被认为更轻量级的。每个容器都具有自己的文件系统、CPU、内存、进程空间等。由于它们与基础架构分离,因此可以跨云和OS发型版本进行移植。

容器的一些优点:
敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性), 提供可靠且频繁的容器镜像构建和部署。
关注开发与运维的分离:在构建、发布时创建应用程序容器镜像,而不是在部署时, 从而将应用程序与基础架构分离。
可观察性:不仅可以显示 OS 级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
跨开发、测试和生产的环境一致性:在笔记本计算机上也可以和在云中运行一样的应用程序。
跨云和操作系统发行版本的可移植性:可在Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
资源隔离:可预测的应用程序性能。
资源利用:高效率和高密度。
2、什么是Docker
2-1、Docker是一种开源的容器化技术,可以将应用程序及其依赖打包到一个可移植的容器中。然后发布到任何流行的Linux、Windows或虚拟机中。容器是完全使用沙箱机制隔离,相互之前不会有任何接口。
2-2、Docker几个核心概念
- 容器(Container):是Docker的基本部署单元;是一个轻量级的、独立的运行时环境,包含应用程序及其依赖。
- 镜像(Image):是用于创建容器的模板;它是不可变的,它包含了一个完整的文件系统,其中包括应用程序运行所需的文件、依赖和配置信息。通过Docker镜像可创建多个相同的容器实例。
- 镜像仓库(Image Register):是用于存储和分发镜像的地方。常用的公共镜像仓库有官方的、社区共享的。还可以搭建是有的镜像仓库,用于存放自己的镜像。
- Dockerfile:是一种文件,用于定义Docker镜像的构建过程。它包含了一些列的指令,用于指定基础镜像、安装软件、拷贝文件、配置环境等。通过Dockerfile可以自动化地构建镜像,确保镜像的一致性和可重复性。
2-3、Docker运行容器
- 第一步:从镜像仓库中将相应的镜像下载下来。
- 第二步:当镜像下载完成后,可通过docker images来查看本地镜像,在显示的列表中选中想要的镜像。
- 第三步:当选中需要的镜像,通过docker run来运行这个镜像得到想要的容器,可以运行多次得到多个容器,一个镜像相当于一个模版,一个容器相当于一个具体的运行实例。因此镜像就具有了一次构建、到处运行的特点。
2-4、Docker与虚拟机区别与联系
- 传统虚拟机:是虚拟出一套硬件后,在其上运行一套完整的操作系统,在该系统上再运行所需应用进程。
- Docker:Docker容器内的应用程序直接运行于宿主的内核,容器没有自己的内核,也没有进行硬件虚拟化,因此要比传统的虚拟机更为轻便、快捷。
 2-5、docker常用命令
2-5、docker常用命令 - 构建镜像:docker build -t ImageName:TagName dir。
# 选项:
-t - 提到镜像的标签。
ImageName - 这是您要为镜像指定的名称。
TagName - 这是您要为镜像指定的标签。
dir - Dockerfile所在的目录,“.”表示当前目录。
# 示例
docker build -t demo-boot:1.0.0 -f Dockerfile .
- 查看镜像:docker images
- 删除镜像:docker rmi 镜像ID
- 列出容器:docker ps [options]
option 作用
-a, --all 显示全部容器(默认只显示运行中的容器)
-f, --filter filter 根据提供的 filter 过滤输出
-n, --last int 列出最近创建的 n 个容器(默认-1,代表全部)
-l, --latest 显示最近创建的容器(包括所有状态的容器)
-s, --size 显示总的文件大小
--no-trunc 显示完整的镜像 ID
-q, --quiet 静默模式,只显示容器 ID
- 删除容器:docker rm 容器ID
- 运行容器:docker run [OPTIONS] IMAGE [COMMAND] [ARG…]。
option 作用
-d 守护进程,后台运行该容器
-v 目录映射,容器目录挂载到宿主机目录,格式: <host目录>:<容器目录>
-p 指定端口映射,格式:主机(宿主)端口:容器端口
--name “nginx-lb” 容器名字
-
运行示例:docker run -d -p 8001:80 --name demo-boot demo-boot:1.0.0
镜像:demo-boot:1.0.0(demo-boot镜像名,1.0.0版本号)
8001:80:将容器的 80 端口映射到主机的8001端口
容器名字: demo-boot(docker ps -a 可以看到创建后的运行容器名) -
进入镜像: sudo docker exec -it 容器ID /bin/bash
-
查看容器IP:docker inspect
| grep IPAddress | cut -d ‘"’ -f 4
2-6、Docker的那些端口含义
- 程序端口:即应用程序的端口,也跟容器端口是同一个端口。启动容器后,本机或同网络其他容器可通过【容器IP + 程序端口】访问该容器的服务。外网访问需要映射主机端口。
- 容器端口:也称为内部端口,它是指Docker容器内部暴露出来供其他进程连接访问的端口号。通常情况下,在Dockerfile文件中会使用EXPOSE命令声明容器需要监听的端口。但实际端口由程序的端口决定。
- 主机端口:也成为外部端口,它是指主机映射到容器内部的端口号。通常情况下,需要将Docker容器暴露出来的端口映射带主机上,以便外界可以访问该应用程序。
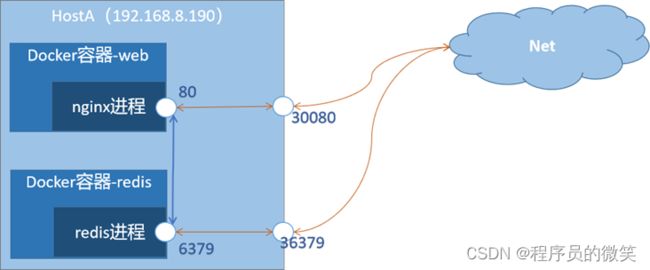
- 访问示例
(1)nginx程序端口为80,映射主机端口30001
本机或同网络访问:curl 容器IP:80
外部访问:curl 主机IP:30001 或 curl 域名:30001
(2)redis程序端口为6379,映射主机端口为36379
访问方式同上
3、k8s和docker的区别与联系
3-1、k8s是一种开源的容器集群管理系统,而docker是一种开源的应用容器引擎。
3-2、k8s是一套自动化部署工具,可以管理docker容器是容器编排层面的;docker是容器化技术,是容器层面的。 所以说Docker解决了应用程序的容器化问题,而k8s则负责容器容器的自动化管理和编排。这两者相辅相成。
3-3、k8s+docker+Jenkins自动化部署,如下图(引用掘金平台的图片)

4、什么是容器、容器引擎、容器编排
4-1、容器:是一个视图隔离、资源可限制、独立文件系统的进程集合。所谓“视图隔离”就是能够看到部分进程以及具有独立的主机名等;控制资源使用率则是可以对于内存大小以及CPU使用个数等进行限制。容器就是一个进程集合,他将系统的其他资源隔离开来,具有自己的独立资源视图。
4-2、容器引擎:是一种虚拟化技术,利用操作系统内核来实现对应用程序的隔离和打包,使得应用程序可以在不同的环境中运行,而不需要修改代码。
4-3、容器编排:是指自动化容器应用的部署、管理、扩展和联网的一些列管控操作、能够控制和自动化许多任务、包括调度和部署容器、在容器之间分配资源、扩缩容器应用规模、在主机不可用或资源不足时将容器从一台主机迁移到其他主机、负载均衡以及监视容器和主机运行状况等。
5、k8s中service的各端口含义
注:参考nginx-svc.yaml配置,如下
apiVersion: v1
kind: Service
metadata:
name: nginx-svc ## svc名称,对应 kubectl get svc的name
namespace: ns-test ## 命名空间,没有可以删除,默认是default
spec:
selector:
app: nginx ## 关联容器标签
ports:
- port: 8000 ## 集群间接口:集群内部服务之间访问service的入口
targetPort: 80 ## 程序端口:容器内部端口号
nodePort: 30001 ## nodeport映射为30001端口,便于外部主机访问
type: NodePort ## svc类型为nodeport
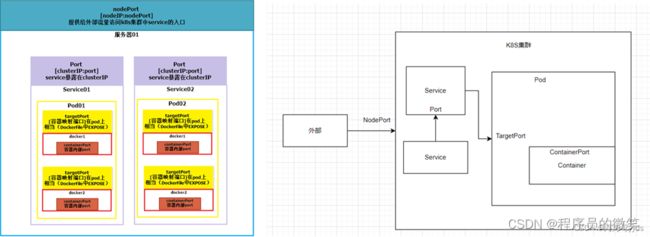
5-1、nodePort
- nodePort提供了集群外部客户端访问service的端口,即nodeIP:nodePort提供了外部流量访问k8s集群中service的入口。比如外部用户要访问k8s集群中的Web应用,那么可以配置对应service的type=NodePort,nodePort=30001.其他用户就可以通过浏览器http://node:30001访问到该web服务。
5-2、port
- port是暴露在cluster ip上的端口,port提供了集群内部客户端访问service的入口,即clusterIP:port。集群内其他容器可通过8000端口访问web服务。
5-3、targetPort
- targetPort是pod上的端口,从port/nodePort上来的数据,经过kube-proxy流入到后端pod的targetPort上,最后进入容器。targetPort与制作容器时暴露的端口一致,如官方的nginx暴露80端口。
5-4、containerPort
- containerPort是在pod控制器中定义的、pod中的容器需要暴露的端口,targetPort映射到containerPort。该端口只起到规范作用,哪怕不在yaml定义,也可以通过nodePort->targetPort的流向(外部)或者port->targetPort的流向(内部)进行访问。
5-5、总结
-
总的来说,port和nodePort都是service的端口,前者暴露给k8s集群内部服务访问,后者暴露给k8s集群外部流量访问。从这两个端口到来的数据都需要经过反向代理kube-proxy,流入后端pod的targetPort上,最后到达pod内容器的containerPort。
-
需要注意的,nodePort的使用只是实验性质,如果在生产环境上通过通过nginx等反向代理工具去管理nodePort绝对是灾难性的。更多是需要通过外部LoadBalancer或者ingress去做管理。
6、k8s的yaml主要配置说明
# Deployment.yaml的配置
apiVersion: apps/v1 #指定api版本标签
kind: Deployment #定义资源的类型/角色,deployment为副本控制器,此处资源类型可以是Deployment、Ingress、Service等
metadata: #定义资源的元数据信息,比如资源的名称、namespace、标签等信息
name: nginx-deployment #定义资源的名称,在同一个namespace空间中必须是唯一的
labels: #定义Deployment资源标签
app: nginx
spec: #定义deployment资源需要的参数属性,诸如是否在容器失败时重新启动容器的属性
replicas: 3 #定义副本数量
selector: #定义标签选择器
matchLabels: #定义匹配标签
app: nginx #需与 .spec.template.metadata.labels 定义的标签保持一致
template: #定义业务模板,如果有多个副本,所有副本的属性会按照模板的相关配置进行匹配
metadata:
labels: #定义Pod副本将使用的标签,需与 .spec.selector.matchLabels 定义的标签保持一致
app: nginx
spec:
containers: #定义容器属性
- name: nginx #定义一个容器名,一个 - name: 定义一个容器
image: nginx:1.20 #定义容器使用的镜像以及版本
ports:
- containerPort: 80 #定义容器的对外的端口
# Service.yaml的配置
apiVersion: v1
kind: Service
metadata: #元数据
name: string #Service名称
namespace: string #命名空间,不指定时默认为default命名空间
labels: #自定义标签属性列表
- name: string
spec: #详细描述
selector: [] #这里选择器一定要选择容器的标签,也就是pod的标签
type: string #service的类型,指定service的访问方式,默认ClusterIP
clusterIP: string #虚拟服务IP地址,当type=ClusterIP时,如不指定系统会自动分配,也可手动指定。当type=loadBalancer,需要指定
sessionAffinity: string #是否支持session,可选值为ClietIP,默认值为空
#ClientIP表示将同一个客户端(根据客户端IP地址决定)的访问请求都转发到同一个后端Pod
ports: #service需要暴露的端口列表
- name: string #端口名称
protocol: string #端口协议,支持TCP或UDP,默认TCP
port: int #服务监听的端口号
targetPort: int #需要转发到后端的端口号(要于containerPort对应)
nodePort: int #当type=NodePort时,指定映射到物理机的端口号
status: #当type=LoadBalancer时,设置外部负载均衡的地址,用于公有云环境
loadBalancer: #外部负载均衡器
ingress: #外部负载均衡器
ip: string #外部负载均衡器的IP地址
hostname: string #外部负载均衡器的机主机
6-1、apiVersion: v1或apps/v1
- apps是指所属组,v1是默认版本
6-2、kind:Pod、Deployment、Service、ReplicaSet、ReplicationController等
- Pod:是k8s中最小资源管理组件,一个Pod相当于docker中的一个容器。
- Deployment:是Pod的控制器,维持Pod的数量。部署容器一般就用它。即:kind:Deployment
- Service:当Pod重新生成时,其容器IP等状态信息可能会变动,而Service会根据Pod的Label标签对这些状态信息进行监控和变更,保证上下游服务不受Pod的变动而影响。
- ReplicaSet:目的是维护一组在任何时候都处于运行状态的 Pod 副本的稳定集合。 因此,它通常用来保证给定数量的、完全相同的Pod 的可用性。
- ReplicationController: 确保在任何时候都有特定数量的 Pod 副本处于运行状态。 即:确保一个 Pod 或一组同类的Pod 总是可用的。(推荐使用配置 ReplicaSet 的 Deployment 来建立副本管理机制)。
6-3、 - name 或- port等,表明是一组集合中的一个实例配置
- port: 443
targetPort: 8443
- port: 442
targetPort: 8442
7、什么是Pod
-
Pod是 Kubernetes 集群中能够被创建和管理的最小部署单元,它是虚拟存在的。Pod 是一组容器的集合,并且部署在同一个Pod里面的容器是亲密性很强的一组容器,Pod 里面的容器,共享网络和存储空间。
-
Pod属于生命周期比较短暂的组件,比如,当Pod所在节点发生故障时,那么该节点上的Pod会被调度到其他节点,但需要注意的是,被重新调度的Pod是一个全新的Pod,跟之前的Pod没有任何关系。
-
每一个Pod都有一个特殊的被称为“根容器”的Pause容器。Pause容器对应镜像属于k8s平台的一部分,除了Pause容器,每个Pod还包含一个或多个紧密相关的用户业务容器。
-

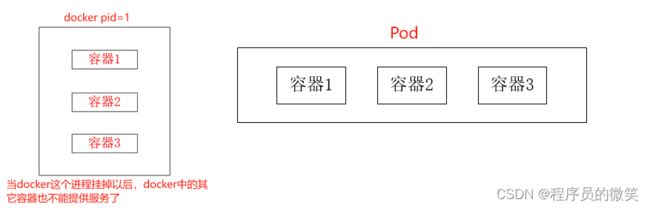
8、Pod与Docker创建容器对比
-
创建容器使用docker,1个docker对应一个容器,一个容器对应1个进程,一个容器运行一个程序。一个docker也可以创建多个容器,但是不好管理,因为docker是单进程的。
-
Pod是多进程设计,可以运行多个应用程序(容器),一个Pod中可以有多个容器,一个容器中运行一个应用程序。
-
Pod创建容器的优点:① 两个应用之间进行交互更加方便;② 网络之间调用可以直接通过127.0.0.1,不需要通过ip调用;③ 两个应用之间需要频繁调用。
9、Pod实现机制
9-1、共享网络
实现原理:创建Pod时,首先会在Pod中创建一个pause根容器,也成为info容器,然后创建其它业务容器,每创建一个业务容器,都会加入到根容器中,让所有的业务容器在同一个namespace下,只要在同一个namespace下那么所有容器共享ip、port。

9-2、共享存储
Volume是容器中的一种存储方式,可以被认为是容器内的一个目录。Volume可以在容器内部被挂载并用于存储数据,包括应用程序的数据、配置文件、日志等。k8s支持多种类型的Volume,每种类型的用途和特点如下:
① EmptyDir:在容器中创建空目录,用于临时存储数据,当Pod被删除时,数据也会被删除。
② HostPath:使用节点上的文件系统作为Volume,在容器中挂载节点上的目录或文件,可以实现数据持久化存储。
③ ConfigMap:将配置文件作为Volume挂载到容器中,可以通过ConfigMap管理容器的配置信息
④ Secret:将敏感数据(如密码、证书等)作为Volume挂载到容器中,可以通过Secret管理容器的敏感数据

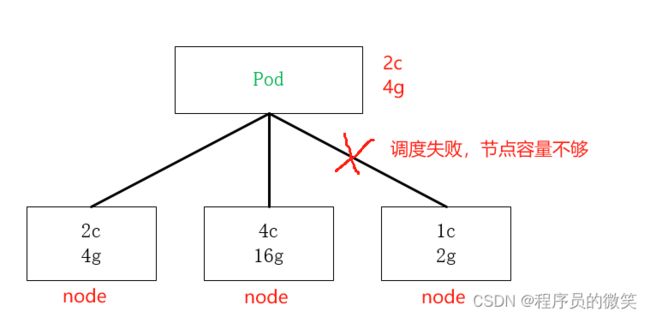
9-3、资源限制
Pod在进行资源调度时,可以对调度的资源大小进行限制,例如:我们限制Pod调度是使用的资源大小为:2C4G(即:2核CPU、4G内存),那么调度对应的node节点时,只会占用对应的资源,对于不满足资源的节点,将不会进行调度。
10、k8s常用命令
-
10-1、查看命名空间:kubectl get ns [ns名称] [-o 格式参数]
ns名称:不指定命名空间,表示查询所有。
格式参数:wide默认、json、yaml。 -
10-2、命令空间/创建/删除
kubectl create/delete ns ns名称
-
10-3、查看pod信息:kubectl get pod [-n 命名空间][-A等]
-n 命名空间:指定命名空间,不指定就会使用默认空间。
-A:表示查询所有命名空间的pod信息。 -
10-4、创建、运行、删除pod
# 运行pod
# 模板:kubectl run 控制器名称 --image=镜像名称:版本 --port=端口 --namespace ns名称
kubectl run mynginx --image=nginx:1.20 --port=80 --namespace ns_test
# 创建pod
kubectl apply/create -f pod-*.yaml
# 删除pod
kubectl delete -f pod-*.yaml
- 10-5、去除点污点,设为可调度
kubectl taint nodes --all node-role.kubernetes.io/master-
注:node-role.kubernetes.io/master-:表示去除所有名为“node-role.kubernetes.io/master”的污点。
-
10-6、设置污点,设为不可调度
kubectl taint nodes master node-role.kubernetes.io/master=:NoSchedule
污点可选参数:
NoSchedule: 一定不能被调度
PreferNoSchedule: 尽量不要调度
NoExecute: 不仅不会调度, 还会驱逐Node上已有的Pod -
10-7、检查组件运行状态
# 1. 检查组件运行状态
kubectl get cs
----------------------------------------------------------------------------
NAME STATUS MESSAGE ERROR
scheduler Healthy ok -- 调度服务 作用是将pod调度到node
controller-manager Healthy ok -- 自动化修复服务 作用:Node宕机后自动修复
etcd-0 Healthy {"health":"true"} -- 服务注册与发现
----------------------------------------------------------------------------
# 2. 查看节点状态
kubectl get nodes
# 3. 使用Pod的ip+pod里面运行容器的端口
# 集群中的任意一个机器以及任意的应用都能通过Pod分配的ip来访问这个Pod
curl 192.168.26.6