RabbitMQ学习一
RabbitMQ学习
- RabbitMQ相关概念
- Virtual host数据隔离
- SpringAMQP
-
- 第一种 基本消息模型
- 第二种 WorkQueues模型
- 第三种 发布订阅模型(fanout交换机)
-
- fanout交换机实例
- 第四种 Direct交换机
-
- direct交换机实例
- 基于注解的方式声明——direct交换机
- 第五种Topic交换机
-
- 基于注解的方式声明——Topic交换机
- 消息转换器
- 配置JSON转换器
RabbitMQ相关概念

其中包含几个概念:
1. publisher:生产者,也就是发送消息的一方
2. consumer:消费者,也就是消费消息的一方
3. queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理
4. exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。
5. virtual host:虚拟主机,起到数据隔离的作用(相当于独立的数据库)。每个虚拟主机相互独立,有各自的exchange、queue
Virtual host数据隔离
这里的用户都是RabbitMQ的管理或运维人员。目前只有安装RabbitMQ时添加的itheima这个用户。仔细观察用户表格中的字段,如下:
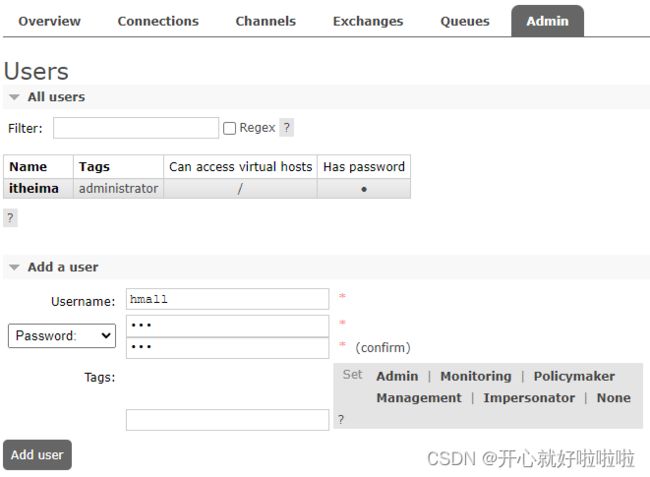
- Name:itheima,也就是用户名
- Tags:administrator,说明itheima用户是超级管理员,拥有所有权限
- Can access virtual host: /,可以访问的virtual host,这里的/是默认的virtual host
对于小型企业而言,出于成本考虑,我们通常只会搭建一套MQ集群,公司内的多个不同项目同时使用。这个时候为了避免互相干扰, 我们会利用virtual host的隔离特性,将不同项目隔离。一般会做两件事情:
- 给每个项目创建独立的运维账号,将管理权限分离。
- 给每个项目创建不同的virtual host,将每个项目的数据隔离。
创建用户hmall 并分配administrator权限
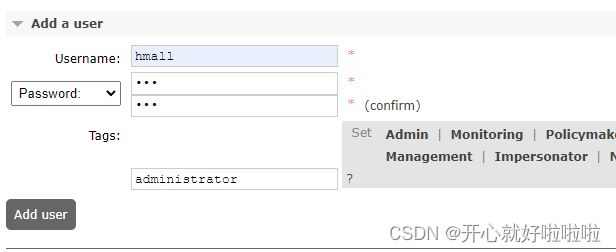
此时hmall用户是没有任何virtual host的访问权限

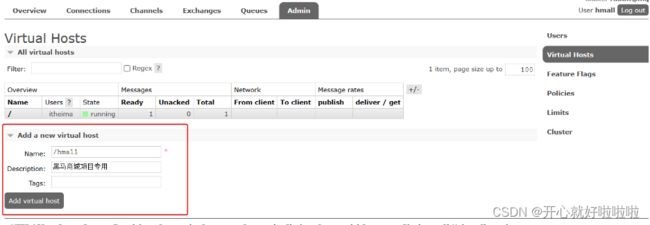
然后切切换用户hmall进行登录,并给项目创建一个单独的virtual host,进行项目之间的隔离
由于我们是登录hmall账户后创建的virtual host,因此回到users菜单,你会发现当前用户已经具备了对/hmall这个virtual host的访问权限了:
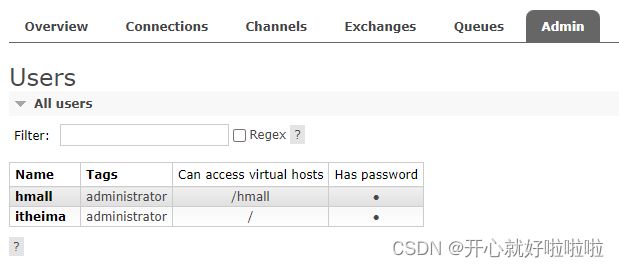
之前在virual host为/下创建的队列、交换机就看不到了。
SpringAMQP
RabbitMQ官方提供的Java客户端编码相对复杂,一般生产环境下我们更多会结合Spring来使用。而Spring的官方刚好基于RabbitMQ提供了这样一套消息收发的模板工具:SpringAMQP
- RabbitMQ提供了6中消息模型,但是第6种RPC,并不属于MQ,
- 其实3、4、5都属于订阅模型,只不过路由的方式不同。

第一种 基本消息模型
其实就是生产者将消息发送到队列,消费者从队列中获取消息,队列是存储消息的缓冲区。(可以直接向队列发送消息,跳过交换机)——这种模式比较简单,很少在生产中使用。

第二种 WorkQueues模型
Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息,主要处理消息堆积,可以使用work 模型,多个消费者共同处理消息,消息处理的速度就能大大提高了。
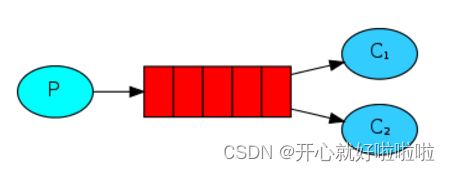
- 但WorkQueues 是平均分配给每个消费者,并没有考虑到消费者的处理能力。导致1个消费者空闲,另一个消费者忙的不可开交。没有充分利用每一个消费者的能力
- 可以在spring中简单的配置,可以解决这个问题,我们修改consumer服务的application.yml文件,添加配置:
spring:
rabbitmq:
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息
第三种 发布订阅模型(fanout交换机)
发布订阅模型,添加两个队列,分别各用一个消费者监听,设置一个交换机,类型为广播(fanout),生产者将消息发送给交换机,而交换机将消息投递给所有与本交换机绑定(routingKey)的队列中。
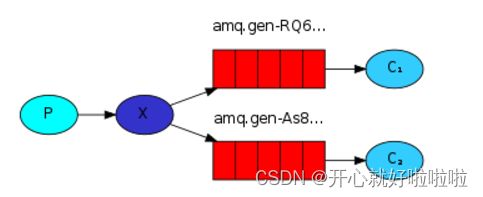
交换机只能转发消息,不能存储消息,有队列绑定就转发到队列里,没有队列时候,交换机里的消息会立马丢失。
- 1) 可以有多个队列
- 2) 每个队列都要绑定到Exchange(交换机)
- 3) 生产者发送的消息,只能发送到交换机
- 4) 交换机把消息发送给绑定过的所有队列
- 5) 订阅队列的消费者都能拿到消息
fanout交换机实例
//发布订阅模式的配置,包括两个队列和对应的订阅者,发布者的交换机类型使用fanout(子网广播),两根网线binding用来绑定队列到交换机
@Configuration
public class FanoutExchangeConfig {
@Bean
public Queue myQueue1() {
Queue queue=new Queue("queue1");
return queue;
}
@Bean
public Queue myQueue2() {
Queue queue=new Queue("queue2");
return queue;
}
/**
* 声明交换机
*/
@Bean
public FanoutExchange fanoutExchange(){
FanoutExchange fanoutExchange=new FanoutExchange("fanout");
return fanoutExchange;
}
/**
* 绑定队列到交换机上
*/
@Bean
public Binding binding1(){
Binding binding=BindingBuilder.bind(myQueue1()).to(fanoutExchange());
return binding;
}
/**
* 绑定队列2到交换机上
*/
@Bean
public Binding binding2(){
Binding binding=BindingBuilder.bind(myQueue2()).to(fanoutExchange());
return binding;
}
}
查看交换机

绑定到交换机下的队列

第四种 Direct交换机
在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。

在Direct模型下:
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key)
- 消息的发送方在 向 Exchange发送消息时,也必须指定消息的 RoutingKey。
- Exchange不再把消息交给每一个绑定的队列,而是根据消息的Routing Key进行判断,只有队列的Routingkey与消息的 Routing key完全一致,才会接收到消息
direct交换机实例
direct模式由于要绑定多个KEY,会非常麻烦,每一个Key都要编写一个binding:
//direct直连模式的交换机配置,包括一个direct交换机,两个队列,4根网线binding
@Configuration
public class DirectExchangeConfig {
@Bean
public DirectExchange directExchange(){
DirectExchange directExchange=new DirectExchange("direct");
return directExchange;
}
@Bean
public Queue directQueue1() {
Queue queue=new Queue("directqueue1");
return queue;
}
@Bean
public Queue directQueue2() {
Queue queue=new Queue("directqueue2");
return queue;
}
//4个binding将交换机和相应队列连起来
@Bean
public Binding bindingblack2(){
Binding binding=BindingBuilder.bind(directQueue1()).to(directExchange()).with("black");
return binding;
}
@Bean
public Binding bindingorange(){
Binding binding=BindingBuilder.bind(directQueue1()).to(directExchange()).with("orange");
return binding;
}
@Bean
public Binding bindingblack(){
Binding binding=BindingBuilder.bind(directQueue2()).to(directExchange()).with("black");
return binding;
}
@Bean
public Binding bindinggreen(){
Binding binding=BindingBuilder.bind(directQueue2()).to(directExchange()).with("green");
return binding;
}
}
基于注解的方式声明——direct交换机
基于@Bean的方式声明队列和交换机比较麻烦,Spring还提供了基于注解方式来声明。
例如,我们同样声明Direct模式的交换机和队列:
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"),
exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT),
key = {"red", "blue"}
))
public void listenDirectQueue1(String msg){
System.out.println("消费者1接收到direct.queue1的消息:【" + msg + "】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue2"),
exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT),
key = {"red", "yellow"}
))
public void listenDirectQueue2(String msg){
System.out.println("消费者2接收到direct.queue2的消息:【" + msg + "】");
}
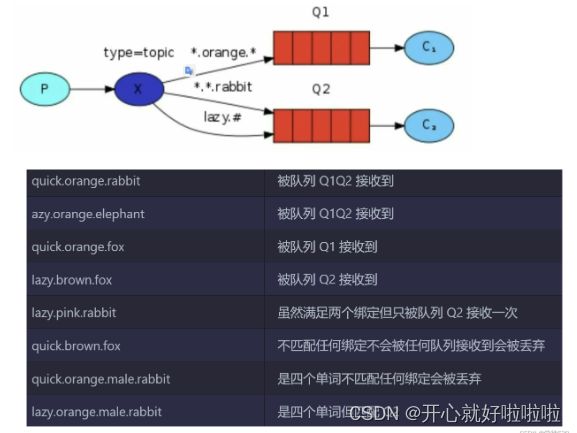
第五种Topic交换机
Topic类型Exchange可以让队列在绑定BindingKey 的时候使用通配符!
BindingKey 一般都是有一个或多个单词组成,多个单词之间以“ .”分割,例如: item.insert
通配符规则:
- #:匹配一个或多个词
- *:匹配不多不少恰好1个词
举例:
item.#:能够匹配item.spu.insert 或者 item.spu
item.*:只能匹配item.spu
基于注解的方式声明——Topic交换机
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue1"),
exchange = @Exchange(name = "hmall.topic", type = ExchangeTypes.TOPIC),
key = "china.#"
))
public void listenTopicQueue1(String msg){
System.out.println("消费者1接收到topic.queue1的消息:【" + msg + "】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue2"),
exchange = @Exchange(name = "hmall.topic", type = ExchangeTypes.TOPIC),
key = "#.news"
))
public void listenTopicQueue2(String msg){
System.out.println("消费者2接收到topic.queue2的消息:【" + msg + "】");
}
消息转换器
在数据传输时,它会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象。 只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题:
- 数据体积过大
- 有安全漏洞
- 可读性差
配置JSON转换器
显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。
在publisher和consumer两个服务中都引入依赖:
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
<version>2.9.10</version>
</dependency>
@Bean
public MessageConverter messageConverter(){
// 1.定义消息转换器
Jackson2JsonMessageConverter jackson2JsonMessageConverter = new Jackson2JsonMessageConverter();
// 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息
jackson2JsonMessageConverter.setCreateMessageIds(true);
return jackson2JsonMessageConverter;
}
消息转换器中添加的messageId可以便于我们将来做幂等性判断。
在consumer服务中定义一个新的消费者,publisher是用什么类型发送,那么消费者也一定要用什么类型接收,格式如下:
@RabbitListener(queues = "object.queue")
public void listenSimpleQueueMessage(Map<String, Object> msg) throws InterruptedException {
System.out.println("消费者接收到object.queue消息:【" + msg + "】");
}