SHAP(三):在解释预测模型以寻求因果见解时要小心
SHAP(三):在解释预测模型以寻求因果见解时要小心
与 Microsoft 的 Eleanor Dillon、Jacob LaRiviere、Scott Lundberg、Jonathan Roth 和 Vasilis Syrgkanis 合作撰写的关于因果关系和可解释机器学习的文章。
当与 SHAP 等可解释性工具配合使用时,XGBoost 等预测机器学习模型会变得更加强大。 这些工具确定输入特征和预测结果之间信息最丰富的关系,这对于解释模型的作用、获得利益相关者的支持以及诊断潜在问题非常有用。 人们很容易进一步进行这一分析,并假设解释工具还可以识别决策者如果想要改变未来的结果,应该操纵哪些特征。 然而,在本文中,我们讨论如何使用预测模型来指导此类政策选择往往会产生误导。
原因与“相关性”和“因果性”之间的根本区别有关。 SHAP 使预测 ML 模型拾取的相关性变得透明。 但使相关性透明并不意味着它们就是因果关系! 所有预测模型都隐含地假设每个人在未来都会保持相同的行为方式,因此相关模式将保持不变。 为了了解如果某人开始表现不同会发生什么,我们需要建立因果模型,这需要做出假设并使用因果分析工具。
1.订阅者保留示例
想象一下,我们的任务是构建一个模型来预测客户是否会续订产品订阅。 假设经过一番挖掘,我们设法获得了八个对于预测流失很重要的特征:客户折扣、广告支出、客户每月使用情况、上次升级、客户报告的错误、与客户的互动、与客户的销售电话 和宏观经济活动。 然后,我们使用这些功能来训练基本的 XGBoost 模型,以预测客户是否会在订阅到期时续订:
# This cell defines the functions we use to generate the data in our scenario
import numpy as np
import pandas as pd
import scipy.stats
import sklearn
import xgboost
class FixableDataFrame(pd.DataFrame):
"""Helper class for manipulating generative models."""
def __init__(self, *args, fixed={}, **kwargs):
self.__dict__["__fixed_var_dictionary"] = fixed
super().__init__(*args, **kwargs)
def __setitem__(self, key, value):
out = super().__setitem__(key, value)
if isinstance(key, str) and key in self.__dict__["__fixed_var_dictionary"]:
out = super().__setitem__(key, self.__dict__["__fixed_var_dictionary"][key])
return out
# generate the data
def generator(n, fixed={}, seed=0):
"""The generative model for our subscriber retention example."""
if seed is not None:
np.random.seed(seed)
X = FixableDataFrame(fixed=fixed)
# the number of sales calls made to this customer
X["Sales calls"] = np.random.uniform(0, 4, size=(n,)).round()
# the number of sales calls made to this customer
X["Interactions"] = X["Sales calls"] + np.random.poisson(0.2, size=(n,))
# the health of the regional economy this customer is a part of
X["Economy"] = np.random.uniform(0, 1, size=(n,))
# the time since the last product upgrade when this customer came up for renewal
X["Last upgrade"] = np.random.uniform(0, 20, size=(n,))
# how much the user perceives that they need the product
X["Product need"] = X["Sales calls"] * 0.1 + np.random.normal(0, 1, size=(n,))
# the fractional discount offered to this customer upon renewal
X["Discount"] = (
(1 - scipy.special.expit(X["Product need"])) * 0.5
+ 0.5 * np.random.uniform(0, 1, size=(n,))
) / 2
# What percent of the days in the last period was the user actively using the product
X["Monthly usage"] = scipy.special.expit(
X["Product need"] * 0.3 + np.random.normal(0, 1, size=(n,))
)
# how much ad money we spent per user targeted at this user (or a group this user is in)
X["Ad spend"] = (
X["Monthly usage"] * np.random.uniform(0.99, 0.9, size=(n,))
+ (X["Last upgrade"] < 1)
+ (X["Last upgrade"] < 2)
)
# how many bugs did this user encounter in the since their last renewal
X["Bugs faced"] = np.array([np.random.poisson(v * 2) for v in X["Monthly usage"]])
# how many bugs did the user report?
X["Bugs reported"] = (
X["Bugs faced"] * scipy.special.expit(X["Product need"])
).round()
# did the user renew?
X["Did renew"] = scipy.special.expit(
7
* (
0.18 * X["Product need"]
+ 0.08 * X["Monthly usage"]
+ 0.1 * X["Economy"]
+ 0.05 * X["Discount"]
+ 0.05 * np.random.normal(0, 1, size=(n,))
+ 0.05 * (1 - X["Bugs faced"] / 20)
+ 0.005 * X["Sales calls"]
+ 0.015 * X["Interactions"]
+ 0.1 / (X["Last upgrade"] / 4 + 0.25)
+ X["Ad spend"] * 0.0
- 0.45
)
)
# in real life we would make a random draw to get either 0 or 1 for if the
# customer did or did not renew. but here we leave the label as the probability
# so that we can get less noise in our plots. Uncomment this line to get
# noiser causal effect lines but the same basic results
X["Did renew"] = scipy.stats.bernoulli.rvs(X["Did renew"])
return X
def user_retention_dataset():
"""The observed data for model training."""
n = 10000
X_full = generator(n)
y = X_full["Did renew"]
X = X_full.drop(["Did renew", "Product need", "Bugs faced"], axis=1)
return X, y
def fit_xgboost(X, y):
"""Train an XGBoost model with early stopping."""
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y)
dtrain = xgboost.DMatrix(X_train, label=y_train)
dtest = xgboost.DMatrix(X_test, label=y_test)
model = xgboost.train(
{"eta": 0.001, "subsample": 0.5, "max_depth": 2, "objective": "reg:logistic"},
dtrain,
num_boost_round=200000,
evals=((dtest, "test"),),
early_stopping_rounds=20,
verbose_eval=False,
)
return model
X, y = user_retention_dataset()
model = fit_xgboost(X, y)
一旦我们掌握了 XGBoost 客户保留模型,我们就可以开始使用 SHAP 等可解释性工具来探索它学到了什么。 我们首先绘制模型中每个特征的全局重要性:
import shap
explainer = shap.Explainer(model)
shap_values = explainer(X)
clust = shap.utils.hclust(X, y, linkage="single")
shap.plots.bar(shap_values, clustering=clust, clustering_cutoff=1)

该条形图显示,提供的折扣、广告支出和报告的错误数量是推动模型预测客户保留率的三大因素。 这很有趣,乍一看似乎很合理。 条形图还包括我们稍后将使用的特征冗余聚类。
然而,当我们更深入地研究并查看每个特征值的变化如何影响模型的预测时,我们发现了一些不直观的模式。 SHAP 散点图显示了特征值的变化如何影响模型对更新概率的预测。 如果蓝点遵循递增的模式,则意味着特征越大,模型的预测更新概率就越高。
shap.plots.scatter(
shap_values, ylabel="SHAP value\n(higher means more likely to renew)"
)

2.预测任务与因果任务
散点图显示了一些令人惊讶的发现:
- 报告错误越多的用户续订的可能性就越大!
- 折扣较大的用户续订的可能性较小!
我们三次检查我们的代码和数据管道以排除错误,然后与一些提供直观解释的业务合作伙伴交谈:
- 重视产品的高使用率用户更有可能报告错误并续订其订阅。
- 销售人员倾向于向他们认为不太可能对产品感兴趣的客户提供高折扣,而这些客户的流失率较高。
模型中这些起初反直觉的关系是否存在问题? 这取决于我们的目标是什么!
我们对该模型的最初目标是预测客户保留率,这对于估计财务规划的未来收入等项目很有用。 由于报告更多错误的用户实际上更有可能续订,因此在模型中捕获这种关系有助于预测。 只要我们的模型具有良好的样本外拟合,我们就应该能够为财务提供良好的预测,因此不应该担心模型中这种关系的方向。
这是称为 预测任务 的一类任务的示例。 在预测任务中,目标是在给定一组特征X的情况下预测结果Y(例如续订)。 预测练习的一个关键组成部分是,我们只关心预测 模型(X) 在与我们的训练集类似的数据分布中接近Y。 X和Y之间的简单相关性对于这些类型的预测很有帮助。
然而,假设第二个团队采用了我们的预测模型,其新目标是确定我们公司可以采取哪些行动来留住更多客户。 该团队非常关心每个X特征与Y的关系,不仅在我们的训练分布中,而且在世界变化时产生的反事实场景。 在该用例中,仅仅确定变量之间的稳定相关性已经不够了; 该团队想知道操纵特征X是否会导致Y发生变化。 想象一下当你告诉工程主管你希望他引入新的错误以增加客户续订时他的表情!
这是称为因果任务的一类任务的示例。 在因果任务中,我们想知道改变世界 X 的某个方面(例如报告的错误)如何影响结果Y(更新)。 在这种情况下,了解更改X是否会导致Y增加,或者数据中的关系是否仅仅是相关性至关重要。
3.估计因果效应的挑战
理解因果关系的一个有用工具是写下我们感兴趣的数据生成过程的因果图。我们示例的因果图说明了为什么我们的 XGBoost 客户保留模型所选取的稳健预测关系与 想要计划干预措施以提高保留率的团队的兴趣。 该图只是真实数据生成机制(上面定义的)的总结。 实心椭圆代表我们观察到的特征,而虚线椭圆代表我们未测量的隐藏特征。 每个特征都是带有箭头的所有特征的函数,加上一些随机效应。
在我们的示例中,我们知道因果图,因为我们模拟了数据。 在实践中,真正的因果图是未知的,但我们也许能够使用有关世界如何运作的特定上下文领域知识来推断哪些关系可以存在或不可以存在。
import graphviz
names = [
"Bugs reported",
"Monthly usage",
"Sales calls",
"Economy",
"Discount",
"Last upgrade",
"Ad spend",
"Interactions",
]
g = graphviz.Digraph()
for name in names:
g.node(name, fontsize="10")
g.node("Product need", style="dashed", fontsize="10")
g.node("Bugs faced", style="dashed", fontsize="10")
g.node("Did renew", style="filled", fontsize="10")
g.edge("Product need", "Did renew")
g.edge("Product need", "Discount")
g.edge("Product need", "Bugs reported")
g.edge("Product need", "Monthly usage")
g.edge("Discount", "Did renew")
g.edge("Monthly usage", "Bugs faced")
g.edge("Monthly usage", "Did renew")
g.edge("Monthly usage", "Ad spend")
g.edge("Economy", "Did renew")
g.edge("Sales calls", "Did renew")
g.edge("Sales calls", "Product need")
g.edge("Sales calls", "Interactions")
g.edge("Interactions", "Did renew")
g.edge("Bugs faced", "Did renew")
g.edge("Bugs faced", "Bugs reported")
g.edge("Last upgrade", "Did renew")
g.edge("Last upgrade", "Ad spend")
g

该图中有很多关系,但第一个重要的问题是,我们可以测量的一些功能受到未测量的混杂功能的影响,例如产品需求和面临的错误。 例如,报告更多错误的用户会遇到更多错误,因为他们更多地使用该产品,并且他们也更有可能报告这些错误,因为他们更需要该产品。 产品需求对更新有其直接的因果影响。 由于我们无法直接衡量产品需求,因此我们最终在报告的错误和更新之间的预测模型中捕获的相关性结合了所面临的错误的微小负面直接影响和产品需求带来的巨大积极混杂效应。 下图绘制了示例中的 SHAP 值与每个特征的真实因果效应(在我们生成数据后在此示例中已知)。
def marginal_effects(
generative_model, num_samples=100, columns=None, max_points=20, logit=True, seed=0
):
"""Helper function to compute the true marginal causal effects."""
X = generative_model(num_samples)
if columns is None:
columns = X.columns
ys = [[] for _ in columns]
xs = [X[c].values for c in columns]
xs = np.sort(xs, axis=1)
xs = [xs[i] for i in range(len(xs))]
for i, c in enumerate(columns):
xs[i] = np.unique(
[
np.nanpercentile(xs[i], v, method="nearest")
for v in np.linspace(0, 100, max_points)
]
)
for x in xs[i]:
Xnew = generative_model(num_samples, fixed={c: x}, seed=seed)
val = Xnew["Did renew"].mean()
if logit:
val = scipy.special.logit(val)
ys[i].append(val)
ys[i] = np.array(ys[i])
ys = [ys[i] - ys[i].mean() for i in range(len(ys))]
return list(zip(xs, ys))
shap.plots.scatter(
shap_values,
ylabel="SHAP value\n(higher means more likely to renew)",
overlay={"True causal effects": marginal_effects(generator, 10000, X.columns)},
)

预测模型捕获了报告的错误对保留率的总体积极影响(如 SHAP 所示),即使报告错误的因果影响为零,并且遇到错误的影响是负面的。
我们在折扣上也看到了类似的问题,折扣也是由未观察到的客户对产品的需求驱动的。 我们的预测模型发现折扣和保留之间存在负相关关系,这是由与未观察到的特征“产品需求”的相关性驱动的,尽管折扣实际上对续订有很小的正因果影响! 换句话说,如果两个客户具有相同的产品需求并且在其他方面相似,那么折扣较大的客户更有可能续订。
当我们开始将预测模型解释为因果关系时,该图还揭示了第二个更隐蔽的问题。 请注意,广告支出也有类似的问题 - 它对保留率没有因果影响(黑线是平的),但预测模型正在产生积极的影响!
在这种情况下,广告支出仅由上次升级和每月使用情况驱动,因此我们没有未观察到的混杂问题,而是观察到混杂问题。 广告支出和影响广告支出的功能之间存在统计冗余。 当我们通过多个特征捕获相同的信息时,预测模型可以使用这些特征中的任何一个进行预测,即使它们并不都是因果关系。 虽然广告支出对续订本身没有因果影响,但它与确实推动续订的几个功能密切相关。 我们的正则化模型将广告支出视为有用的预测因子,因为它总结了多个因果驱动因素(因此导致模型更稀疏),但如果我们开始将其解释为因果效应,就会产生严重误导。
现在,我们将依次处理示例的每个部分,以说明预测模型何时可以准确测量因果效应,何时不能。 我们还将介绍一些因果工具,有时可以在预测模型失败的情况下估计因果效应。
4.预测模型何时可以回答因果问题
让我们从示例中的成功开始。 请注意,我们的预测模型很好地捕捉了经济特征的真正因果效应(更好的经济对保留有积极影响)。 那么我们什么时候才能期望预测模型能够捕捉到真正的因果效应呢?
让 XGBoost 获得良好的经济因果效应估计的重要因素是该特征强大的独立成分(在此模拟中); 它对保留的预测能力与任何其他测量的特征或任何未测量的混杂因素并不强烈冗余。 因此,它不会受到未测量的混杂因素或特征冗余带来的偏差的影响。
# Economy is independent of other measured features.
shap.plots.bar(shap_values, clustering=clust, clustering_cutoff=1)

由于我们已将聚类添加到 SHAP 条形图的右侧,因此我们可以将数据的冗余结构视为树状图。 当特征在树状图的底部(左侧)合并在一起时,这意味着这些特征包含的有关结果(更新)的信息非常冗余,并且模型可以使用任一特征。 当特征在树状图的顶部(右侧)合并在一起时,意味着它们包含的有关结果的信息是彼此独立的。
我们可以看到经济独立于所有其他测量的特征,注意到经济直到聚类树状图的最顶部才与任何其他特征合并。 这告诉我们,经济不会受到观察到的混杂因素的影响。 但为了相信经济效应是因果关系,我们还需要检查未观察到的混杂因素。 检查未测量的混杂因素更加困难,需要使用领域知识(由上面示例中的业务合作伙伴提供)。
对于要提供因果结果的经典预测 ML 模型,这些特征不仅需要独立于模型中的其他特征,而且还需要独立于未观察到的混杂因素。 自然地表现出这种独立性水平的兴趣驱动因素的例子并不常见,但当我们的数据包含一些实验时,我们经常可以找到独立特征的例子。
5.当预测模型无法回答因果问题但因果推理方法可以提供帮助时
在大多数现实世界的数据集中,特征并不是独立且无混杂的,因此标准预测模型将无法学习真正的因果效应。 因此,用 SHAP 解释它们不会揭示因果效应。 但一切并没有丢失,有时我们可以使用观察因果推理工具来解决或至少最小化这个问题。
5.1 观察到的混杂
因果推理可以提供帮助的第一个场景是观察到的混淆。 当存在另一个特征同时影响原始特征和我们预测的结果时,一个特征被“混淆”。 如果我们可以测量其他特征,则它被称为“观察到的混杂因素”。
# Ad spend is very redundant with Monthly usage and Last upgrade.
shap.plots.bar(shap_values, clustering=clust, clustering_cutoff=1)
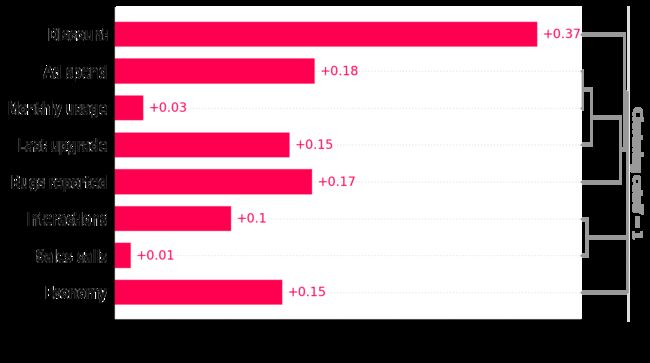
在我们的场景中,广告支出功能就是一个例子。 尽管广告支出对保留率没有直接因果影响,但它与上次升级和每月使用功能相关,这确实会提高保留率。 我们的预测模型将广告支出视为保留的最佳单一预测因素之一,因为它通过相关性捕获了许多真正的因果驱动因素。 XGBoost 强加了正则化,这是一种奇特的说法,它试图选择仍然可以很好预测的最简单的模型。 如果它可以使用一个特征而不是三个特征进行同样好的预测,那么它往往会这样做以避免过度拟合。 但这意味着,如果广告支出与上次升级和每月使用情况高度相关,XGBoost 可能会使用广告支出而不是因果特征! XGBoost(或任何其他具有正则化的机器学习模型)的这一属性对于生成未来保留的稳健预测非常有用,但不利于理解如果我们想增加保留,我们应该操纵哪些特征。
这凸显了为每个问题匹配正确的建模工具的重要性。 与错误报告示例不同,增加广告支出可以提高保留率的结论从直觉上看并没有什么错误。 如果没有适当关注我们的预测模型是什么,什么不是测量,我们可以很容易地继续这一发现,但只有在增加广告支出并且没有得到我们预期的更新结果后才认识到我们的错误。
5.2 观察因果推断
对于广告支出来说,好消息是我们可以衡量所有可能混淆它的特征(在上面的因果图中带有指向广告支出的箭头的特征)。 因此,这是一个观察到的混杂的例子,我们应该能够仅使用我们已经收集的数据来理清相关模式; 我们只需要使用来自观察因果推理的正确工具。 这些工具使我们能够指定哪些功能可能会混淆广告支出,然后针对这些功能进行调整,以获得广告支出对产品更新的因果影响的无混淆估计。
一种特别灵活的观察因果推理工具是双重/去偏差机器学习。 它使用您想要首先解构感兴趣的特征(即广告支出)的任何机器学习模型,然后估计更改该特征的平均因果效应(即因果效应的平均斜率)。
双机器学习的工作原理如下:
- 训练模型以使用一组可能的混杂因素(即不是由广告支出引起的任何特征)来预测感兴趣的特征(即广告支出)。
- 使用同一组可能的混杂因素训练模型来预测结果(即是否更新)。
- 训练一个模型,使用感兴趣的因果特征的残差变化来预测结果的残差变化(减去我们的预测后剩下的变化)。
直觉是,如果广告支出导致更新,那么广告支出中无法通过其他混杂特征预测的部分应该与无法通过其他混杂特征预测的更新部分相关。 换句话说,双重机器学习假设存在一个独立的(未观察到的)噪声特征会影响广告支出(因为广告支出并不完全由其他特征决定),因此我们可以估算这个独立噪声特征的值,然后训练一个 基于这个独立特征的模型来预测输出。
虽然我们可以手动完成所有双重 ML 步骤,但使用 econML 或 CausalML 等因果推理包会更容易。 这里我们使用econML的LinearDML模型。 这将返回该处理是否具有非零因果效应的 P 值,并且在我们的场景中效果良好,正确识别没有证据表明广告支出对续订有因果效应(P 值 = 0.85):
import matplotlib.pyplot as plt
from econml.dml import LinearDML
from sklearn.base import BaseEstimator, clone
class RegressionWrapper(BaseEstimator):
"""Turns a classifier into a 'regressor'.
We use the regression formulation of double ML, so we need to approximate the classifer
as a regression model. This treats the probabilities as just quantitative value targets
for least squares regression, but it turns out to be a reasonable approximation.
"""
def __init__(self, clf):
self.clf = clf
def fit(self, X, y, **kwargs):
self.clf_ = clone(self.clf)
self.clf_.fit(X, y, **kwargs)
return self
def predict(self, X):
return self.clf_.predict_proba(X)[:, 1]
# Run Double ML, controlling for all the other features
def double_ml(y, causal_feature, control_features):
"""Use doubleML from econML to estimate the slope of the causal effect of a feature."""
xgb_model = xgboost.XGBClassifier(objective="binary:logistic", random_state=42)
est = LinearDML(model_y=RegressionWrapper(xgb_model))
est.fit(y, causal_feature, W=control_features)
return est.effect_inference()
def plot_effect(effect, xs, true_ys, ylim=None):
"""Plot a double ML effect estimate from econML as a line.
Note that the effect estimate from double ML is an average effect *slope* not a full
function. So we arbitrarily draw the slope of the line as passing through the origin.
"""
plt.figure(figsize=(5, 3))
pred_xs = [xs.min(), xs.max()]
mid = (xs.min() + xs.max()) / 2
[effect.pred[0] * (xs.min() - mid), effect.pred[0] * (xs.max() - mid)]
plt.plot(
xs, true_ys - true_ys[0], label="True causal effect", color="black", linewidth=3
)
point_pred = effect.point_estimate * pred_xs
pred_stderr = effect.stderr * np.abs(pred_xs)
plt.plot(
pred_xs,
point_pred - point_pred[0],
label="Double ML slope",
color=shap.plots.colors.blue_rgb,
linewidth=3,
)
# 99.9% CI
plt.fill_between(
pred_xs,
point_pred - point_pred[0] - 3.291 * pred_stderr,
point_pred - point_pred[0] + 3.291 * pred_stderr,
alpha=0.2,
color=shap.plots.colors.blue_rgb,
)
plt.legend()
plt.xlabel("Ad spend", fontsize=13)
plt.ylabel("Zero centered effect")
if ylim is not None:
plt.ylim(*ylim)
plt.gca().xaxis.set_ticks_position("bottom")
plt.gca().yaxis.set_ticks_position("left")
plt.gca().spines["right"].set_visible(False)
plt.gca().spines["top"].set_visible(False)
plt.show()
# estimate the causal effect of Ad spend controlling for all the other features
causal_feature = "Ad spend"
control_features = [
"Sales calls",
"Interactions",
"Economy",
"Last upgrade",
"Discount",
"Monthly usage",
"Bugs reported",
]
effect = double_ml(y, X[causal_feature], X.loc[:, control_features])
# plot the estimated slope against the true effect
xs, true_ys = marginal_effects(generator, 10000, X[["Ad spend"]], logit=False)[0]
plot_effect(effect, xs, true_ys, ylim=(-0.2, 0.2))

请记住,只有当您可以测量和识别要估计因果效应的特征的所有可能的混杂因素时,双重机器学习(或任何其他观察性因果推理方法)才有效。 在这里,我们知道因果图,并且可以看到每月使用情况和上次升级是我们需要控制的两个直接混杂因素。 但是,如果我们不知道因果图,我们仍然可以查看 SHAP 条形图中的冗余,并发现每月使用情况和上次升级是最冗余的功能,因此是很好的控制候选功能(折扣和报告的错误也是如此) )。
5.3 非混杂冗余
因果推理可以提供帮助的第二种情况是非混杂冗余。 当我们想要因果驱动的特征或由模型中包含的另一个特征驱动的特征,但该其他特征不是我们感兴趣的特征的混杂因素时,就会发生这种情况。
# Interactions and sales calls are very redundant with one another.
shap.plots.bar(shap_values, clustering=clust, clustering_cutoff=1)

销售电话功能就是一个例子。 销售拜访直接影响留存率,但也通过互动对留存率产生间接影响。 当我们在模型中同时包含交互和销售电话功能时,这两个功能共享的因果效应将被迫在它们之间传播。 我们可以在上面的 SHAP 散点图中看到这一点,它显示了 XGBoost 如何低估销售电话的真正因果效应,因为大部分效应都被放到了交互功能上。
原则上可以通过从模型中删除冗余变量来修复非混杂冗余(见下文)。 例如,如果我们从模型中删除交互,那么我们将捕获销售电话对续订概率的全部影响。 这种删除对于双重机器学习也很重要,因为如果您控制由感兴趣的特征引起的下游特征,双重机器学习将无法捕获间接因果效应。 在这种情况下,双重 ML 将仅测量不通过其他特征的“直接”效果。 然而,双 ML 对于控制上游非混杂冗余(其中冗余特征导致感兴趣的特征)具有鲁棒性,尽管这会降低您检测真实效果的统计能力。
不幸的是,我们通常不知道真正的因果图,因此很难知道另一个特征何时与我们感兴趣的特征冗余,因为观察到混杂冗余与非混杂冗余。 如果是因为混杂,那么我们应该使用双机器学习等方法来控制该特征,而如果它是下游结果,那么如果我们想要完整的因果效应而不仅仅是直接效应,那么我们应该从模型中删除该特征。 控制我们不应该控制的特征往往会隐藏或分裂因果效应,而未能控制我们应该控制的特征往往会推断出不存在的因果效应。 当您不确定时,这通常会使控制某个功能成为更安全的选择。
# Fit, explain, and plot a univariate model with just Sales calls
# Note how this model does not have to split of credit between Sales calls and
# Interactions, so we get a better agreement with the true causal effect.
sales_calls_model = fit_xgboost(X[["Sales calls"]], y)
sales_calls_shap_values = shap.Explainer(sales_calls_model)(X[["Sales calls"]])
shap.plots.scatter(
sales_calls_shap_values,
overlay={
"True causal effects": marginal_effects(generator, 10000, ["Sales calls"])
},
)

6.当预测模型和非混杂方法都无法回答因果问题时
只有当您可以测量和识别要估计因果效应的特征的所有可能的混杂因素时,双重机器学习(或任何其他假设无混杂性的因果推理方法)才有效。 如果您无法衡量所有混杂因素,那么您就处于最困难的情况:未观察到的混杂因素。
# Discount and Bugs reported seem are fairly independent of the other features we can
# measure, but they are not independent of Product need, which is an unobserved confounder.
shap.plots.bar(shap_values, clustering=clust, clustering_cutoff=1)

折扣和错误报告功能都受到未观察到的混淆的影响,因为并非所有重要变量(例如,产品需求和面临的错误)都在数据中进行测量。 尽管这两个功能相对独立于模型中的所有其他功能,但仍有一些重要的驱动因素无法衡量。 在这种情况下,需要观察混杂因素的预测模型和因果模型(例如双重机器学习)都会失败。 这就是为什么即使在控制所有其他观察到的特征时,双重机器学习也会估计折扣特征的巨大负面因果效应:
# estimate the causal effect of Ad spend controlling for all the other features
causal_feature = "Discount"
control_features = [
"Sales calls",
"Interactions",
"Economy",
"Last upgrade",
"Monthly usage",
"Ad spend",
"Bugs reported",
]
effect = double_ml(y, X[causal_feature], X.loc[:, control_features])
# plot the estimated slope against the true effect
xs, true_ys = marginal_effects(generator, 10000, X[[causal_feature]], logit=False)[0]
plot_effect(effect, xs, true_ys, ylim=(-0.5, 0.2))

除非能够测量以前未测量的特征(或与其相关的特征),否则很难在存在未观察到的混杂因素的情况下找到因果效应。 在这些情况下,识别可以为政策提供信息的因果效应的唯一方法是创建或利用一些随机化,打破感兴趣的特征和无法测量的混杂因素之间的相关性。 在这种情况下,随机实验仍然是寻找因果效应的黄金标准。
基于工具变量、双重差异或回归不连续性原理的专门因果工具有时可以利用部分随机化,即使在不可能进行完整实验的情况下也是如此。 例如,工具变量技术可用于在我们无法随机分配治疗的情况下识别因果效应,但我们可以随机推动一些客户进行治疗,例如发送电子邮件鼓励他们探索新的产品功能。 当新疗法在各组间错开引入时,双重差分方法可能会有所帮助。 最后,当治疗模式表现出明显的界限时(例如,基于特定的、可测量的特征(例如每月收入超过 5,000 美元)的治疗资格),断点回归方法是一个不错的选择。
7.概括
XGBoost 或 LightGBM 等灵活的预测模型是解决预测问题的强大工具。 然而,它们本质上并不是因果模型,因此用 SHAP 解释它们将无法准确回答许多常见情况下的因果问题。 除非模型中的特征是实验变异的结果,否则将 SHAP 应用于预测模型而不考虑混杂因素通常不是衡量用于为政策提供信息的因果影响的合适工具。 SHAP 和其他可解释性工具可用于因果推理,并且 SHAP 已集成到许多因果推理包中,但这些用例本质上是明确因果关系的。 为此,使用我们为预测问题收集的相同数据,并使用专门用于返回因果效应的双机器学习等因果推理方法,通常是为政策提供信息的好方法。 在其他情况下,只有实验或其他随机来源才能真正回答假设问题。 因果推理总是要求我们做出重要的假设。 本文的要点是,我们通过将正常预测模型解释为因果关系而做出的假设通常是不现实的。
情况下也是如此。 例如,工具变量技术可用于在我们无法随机分配治疗的情况下识别因果效应,但我们可以随机推动一些客户进行治疗,例如发送电子邮件鼓励他们探索新的产品功能。 当新疗法在各组间错开引入时,双重差分方法可能会有所帮助。 最后,当治疗模式表现出明显的界限时(例如,基于特定的、可测量的特征(例如每月收入超过 5,000 美元)的治疗资格),断点回归方法是一个不错的选择。