基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(四)
目录
- 前言
- 总体设计
-
- 系统整体结构图
- 系统流程图
- 运行环境
-
- 爬虫
- 模型训练
- 实际应用
- 模块实现
-
- 1. 数据准备
-
- 1)爬虫下载原始图片
- 2)手动筛选图片
- 2. 数据处理
- 3. 模型训练及保存
- 4. 模型测试
-
- 1)前端
- 2)后端
- 系统测试
-
- 1. 测试效果
- 2. 模型应用
-
- 1)启动服务器端
- 2)浏览器访问网页
- 3)测试结果
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目通过爬虫技术获取图片,利用OpenCV库对图像进行处理,识别并切割出人物脸部,形成了一个用于训练的数据集。通过ImageAI进行训练,最终实现了对动漫人物的识别模型。同时,本项目还开发了一个线上Web应用,使得用户可以方便地体验和使用该模型。
首先,项目使用爬虫技术从网络上获取图片。这些图片包含各种动漫人物,其中我们只对人物脸部进行训练,所以我们会对图像进行处理,并最终将这些图像将作为训练数据的来源。
其次,利用OpenCV库对这些图像进行处理,包括人脸检测、图像增强等步骤,以便准确识别并切割出人物脸部。这一步是为了构建一个清晰而准确的数据集,用于模型的训练。
接下来,通过ImageAI进行训练。ImageAI是一个简化图像识别任务的库,它可以方便地用于训练模型,这里用于训练动漫人物的识别模型。
最终,通过项目开发的线上Web应用,用户可以上传动漫图像,系统将使用训练好的模型识别图像中的动漫人物,并返回相应的结果。
总的来说,本项目结合了爬虫、图像处理、深度学习和Web开发技术,旨在提供一个便捷的动漫人物识别服务。这对于动漫爱好者、社交媒体平台等有着广泛的应用前景。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。

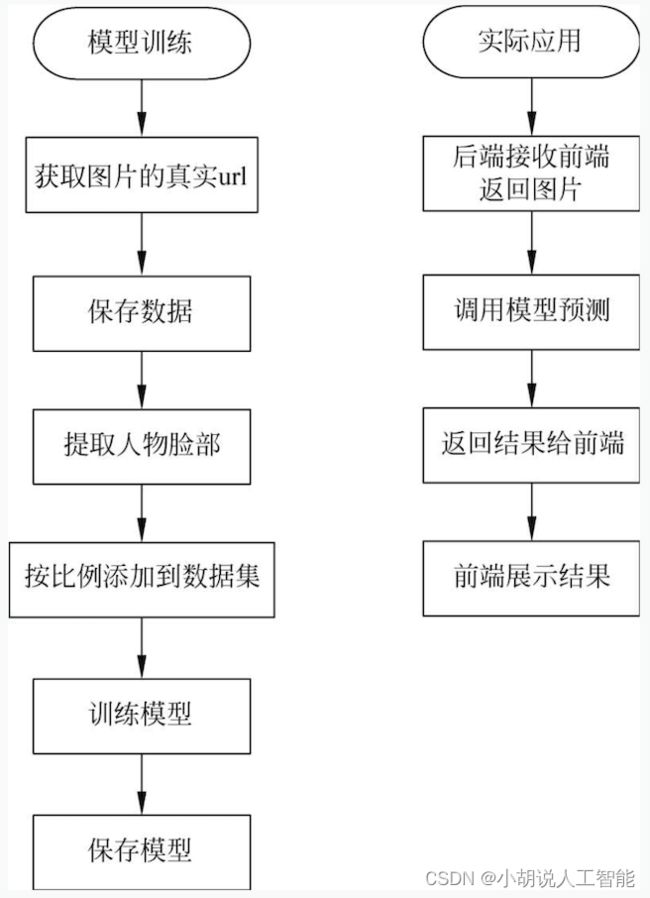
系统流程图
系统流程如图所示。
运行环境
本部分包括爬虫、模型训练及实际应用运行环境。
爬虫
安装Python3.6以上及Selenium3.0.2版本。
详见博客。
模型训练
本部分包括安装依赖、安装ImageAI。
详见博客。
实际应用
实际应用包括前端开发环境和后端环境的搭建。
详见博客。
模块实现
本项目包括4个模块:数据准备、数据处理、模型训练及保存、模型测试,下面分别介绍各模块的功能及相关代码。
1. 数据准备
本项目的数据来自于百度图片,通过爬虫获取。
1)爬虫下载原始图片
详见博客。
2)手动筛选图片
部分人物的名称、现实事物或人物有重名现象,加上一些图片质量不佳,需要人为剔除,手动筛选。
详见博客。
2. 数据处理
将图片中的人脸裁剪进行模型训练,切割人脸部分由OpenCV通过训练好的动漫人物脸部识别模型lbpcascade_animeface截取人物脸部。GitHub下载地址为https://github.com/nagadomi/lbpcascade_animeface。
详见博客。
3. 模型训练及保存
本部分包括设置基本参数、模型保存和模块预测。
详见博客。
4. 模型测试
模型测试分为前端和后端两部分。
1)前端
把用户选择的图片上传至服务器端,接收后端返回的预测结果并展示给用户,使用jQuery的Ajax收发数据:
$.ajax({
type: "POST", //发送选择POST方法
url: '/', //设定人物
dataType: "json", //接收结果类型为json
data: formData, //用户上传的图片
cache: false,
contentType: false,
processData: false,
error: function (XMLResponse) {
console.log("error")
},
success: function (data) { //服务器成功返回结果
document.getElementById('loading').style.display = "none";
let template1 = document.getElementById('template1').innerHTML;
document.getElementById('name').innerHTML = template(template1, {data: data.result}) //渲染展示结果模板
document.getElementById('name').style.display = "block";
}
});} else { document.getElementById('name').innerText = "请选择一张图片"; }
//前端页面框架
<body>
<div class="wrapper">
<nav class="header navbar">
<span class="navbar-brand mb-0 h1">动漫人物识别</span>
</nav>
<div class="content-wrapper">
<div class="input-wrapper card">
<img class="rounded img card-img-top" src="static/images/banner.jpg" id="preview">
<div class="card-body" style="text-align: center">
<button class="btn btn-secondary form-control"id="up">选择图片</button>
<input class="file" type="file" name="file" id="upload_input" value="选择一张图片">
<button class="btn btn-primary form-control" onclick='confirm_up()'>点击上传</button>
<div class="form-control" id="loading" style="display: none">
<img class="card-img-top"src="static/images/loading.gif" alt=""
style="height: 20px;width: 20px; display: inline-block">
uploading...
</div>
</div>
</div>
<div class="predict-result card">
<p class="card-header">预测结果: </p>
<div class="card-body predict" id="name"></div>
</div>
</div>
</div>
<script src="static/js/preview.js" type="text/javascript"></script>
</body>
//添加用户预览
let preview = document.querySelector('#preview');
let eleFile = document.getElementById('upload_input');
eleFile.addEventListener('change', function () {
let file = this.files[0];
console.log("Input change")
//确认选择的文件是图片
if (file.type.indexOf("image") == 0) {
let reader = new FileReader();
reader.readAsDataURL(file);
reader.onload = function (e) {
//图片转为base64
let newUrl = this.result;
preview.src = newUrl;
};
}
document.getElementById('name').style.display = "none";
});
$(document).ready(function(){
$('#up').click(function(){
$('#upload_input').click();
});
});
2)后端
后端使用Flask框架。
UPLOAD_FOLDER = 'uploader' #路径设置
ALLOWED_EXTENSIONS = {'png', 'jpg', 'jpeg', 'gif', 'jif'} #图片类型
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
app.config['JSON_AS_ASCII'] = False
@app.route('/test')
def hello():
return "hello world"
#检查文件类型
def allowed_file(filename):
return '.' in filename and \
filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
#检查请求命令是否有文件
if 'file' not in request.files:
#flash('No file part')
return redirect(request.url)
file = request.files['file']
#如果用户没有选择文件,浏览器提交一个没有文件名的空文件
if file.filename == '':
# flash('No selected file')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file_path = file_path.replace('\\', '/') #解决路径问题
if not os.path.exists(UPLOAD_FOLDER):
os.mkdir(UPLOAD_FOLDER)
file.save(file_path)
print(file_path)
result = predict.predict(file_path)
return jsonify({'signal': 1, 'result': result, 'img_path': file_path})
else:
return render_template('index.html')
@app.route('/uploader/' )
def uploaded_file(filename):
return send_from_directory(app.config['UPLOAD_FOLDER'],
filename)
系统测试
本部分包括测试效果和模型应用。
1. 测试效果
对3个动漫人物夏目贵志、初音未来(miku)和御坂美琴进行测试。模型预测输出两个结果,分别是可能的人物名称及对应概率。
测试一:夏目贵志(见图3和图4)。


测试二:初音未来(miku)(见图5和图6)。


测试三:御坂美琴(见图7和图8)。


2. 模型应用
本部分包括启动服务器端、浏览器访问网页和测试结果。
1)启动服务器端
配置环境后启动服务器端,结果如图所示。

2)浏览器访问网页
在浏览器输入地址并访问页面,如图所示。

3)测试结果
选择一张图片,单击【点击上传】按钮,页面左侧将展示所选择的图片,右侧展示预测的3个结果,并按可能性生从高到低排列,如图所示。由结果可以看出,选择了一张初音的图片,右侧返回的测试结果显示有49.06%的可能性为初音。

相关其它博客
基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(一)
基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(二)
基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(三)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。