7.C转python
1.对字典的各种操作都是对键来进行的
2.关于字典的遍历操作
例:
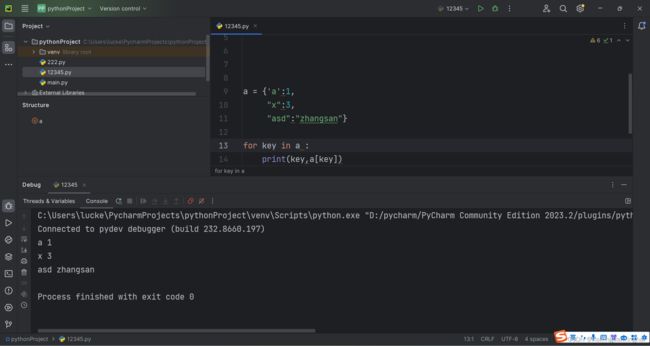
还可以这样遍历
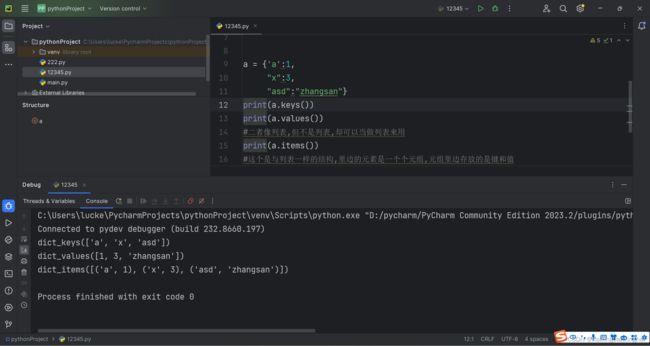
所以生成了一个固定模版来遍历字典:
例:
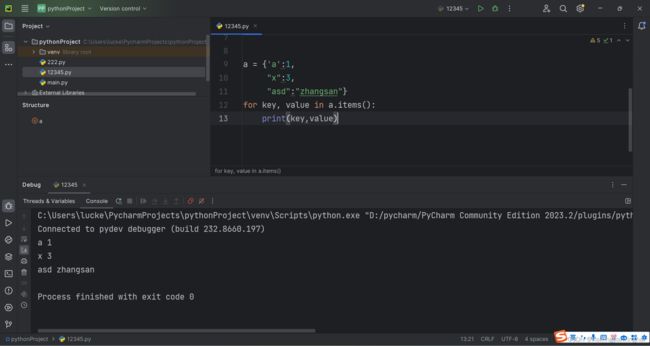
那两个名字可以换
例:
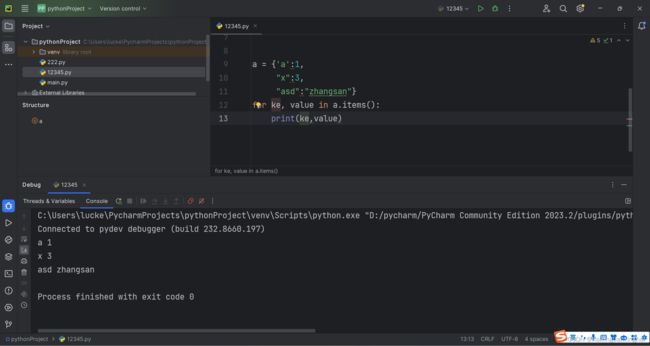
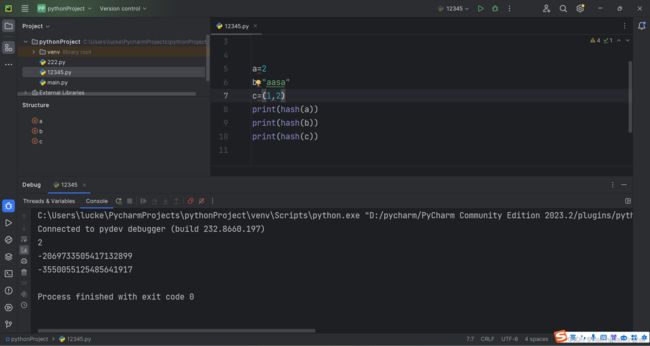
3.合法key的类型:
要求可哈希
在python中,专门提供了一个hash()函数来计算哈希值
例:

有的类型是不能计算哈希的,如:列表,字典
一般来说:不可变的对象可哈希,可变的对象不可哈希,但是
例:
4.电影 mp4
歌曲 mp3
图片 jpg
文本 txt
表格 xlsx
它们的数据都是保存在硬盘上的
变量存储在内存中
文件存储在硬盘中
硬盘里边的内容都是以文件的形式来组织的
但是文件里边存储的数据内容/格式,差距也可以很大
5.写代码中表示文件路径时,一般都是使用的/(即正斜杠)
6.python中的open内置函数功能就是打开一个文件
例:
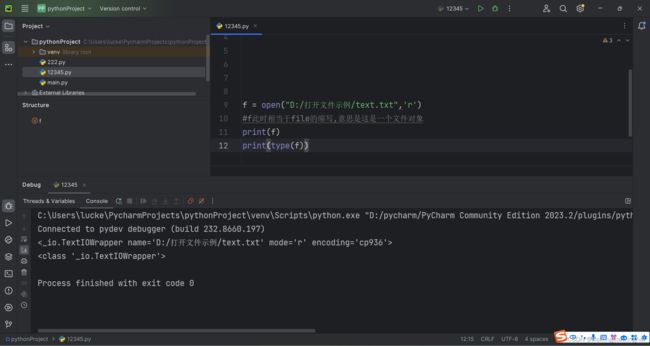
第一个参数是打开哪个文件,第二个参数是打开方式('r'表示read,即按照读的方式打开;'w'即write,按照写的方式打开;'a'表示append,也是按照写的方式打开,但是它会把内容写到原有文件内容的末尾)
7.另外,可以多去看看python的官方网站,上边有很多知识可以学习
8.可以用close函数来关闭文件
例:

文件在打开使用完后一定要关闭,因为我们在打开文件的的同时申请了一定的系统资源
如果一直不释放系统资源,则在打开别的文件的时候就可能没有系统资源可申请了
9.每个程序在启动的时候,都会默认打开3个文件
(1).标准输入
(2).标准输出
(3).标准错误
其实这个点考试应该不考
10.写文件(用'r'方式打开则不能写)
例:
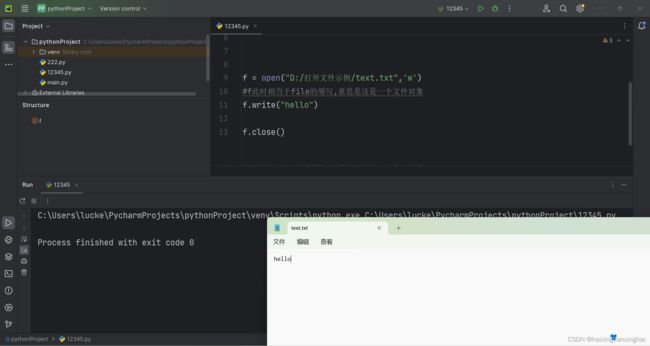
注:如果是使用'w'的方式打开,则会把原来文件的内容清空掉
但是使用'a'方式打开则会继续追加内容(可以使用\n符号来完成换行)
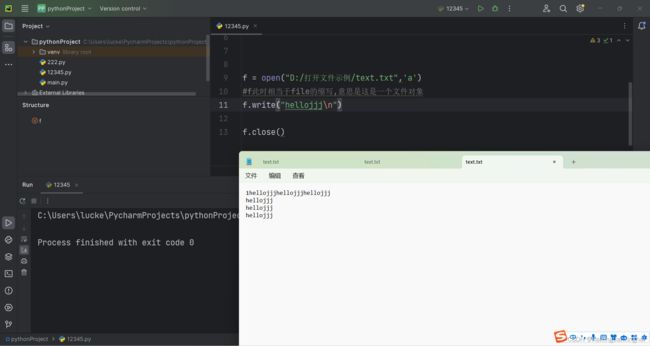
特例:
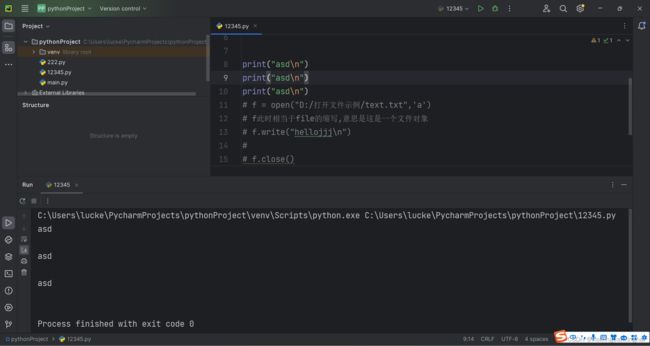
11.如果文件对象已经被关闭,则不能再对其进行写 等 操作
12.读文件:
中文和英文都是用"数字"来表示字符的,但哪个数字对应哪个字符有很多个版本,所以要保证文件内容的编码方式和代码中操作文件的编码方式匹配,否则会出错,所以要对不同编码方式的文件转换为相同编码方式的文件
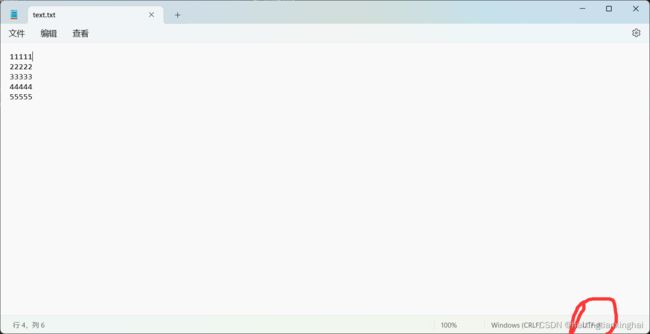
编译器是gbk编码方式
例:(其中的encoding那个是关键字参数)(一个汉字也是一个字符在python)
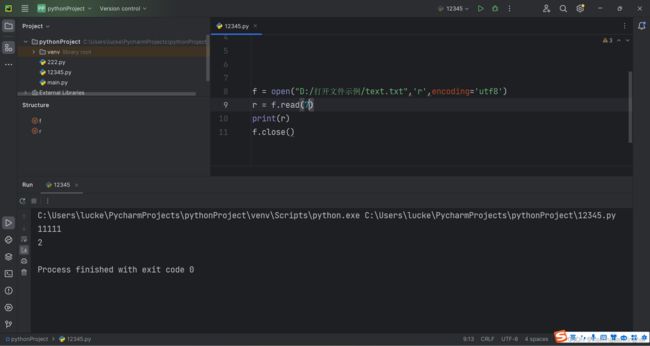
可以这样按行来读取
例(用for循环):

又多一个空行是因为:
本来读到的文件内容末尾带有\n,
用print()又会自动加一个\n
还可以这样读文件
例:
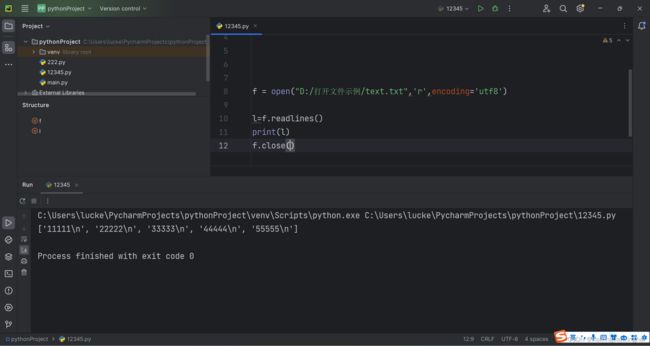
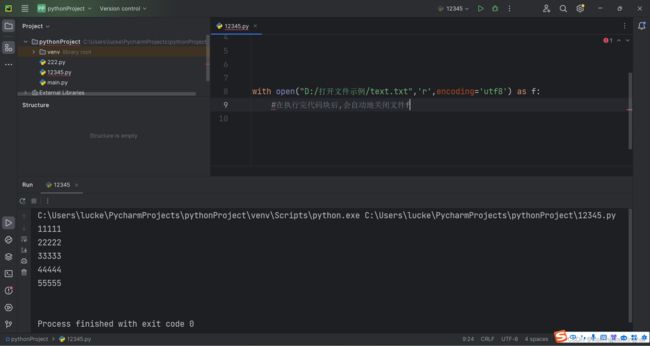
13.上下文管理器:
当with对应的代码块执行结束,就会自动执行f的close
例:
14.标准库的相关网站:https://docs.python.org/3.10/library/index.html(有中文版本哇)
有个离线版搜
15.例:
日期计算器:(datetime()中的参数默认顺序为年月日)
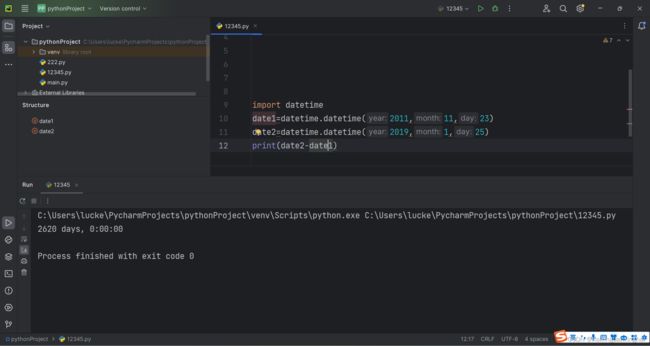
可以这样写:
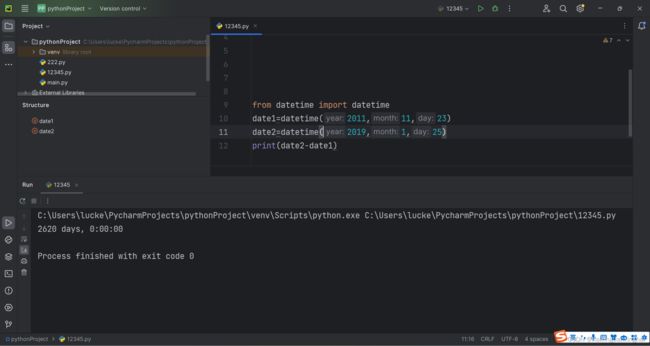
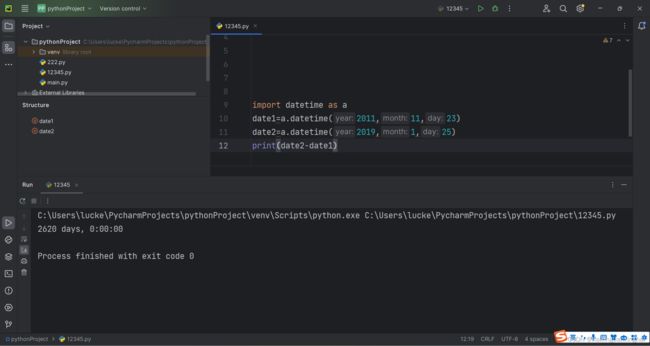
还有一种方式:
16.把剑指offer刷两遍
17.例题:
字符串的逆序:
不会写
字符串的逆序解:搜
18.例题:
判断字符串能否旋转:搜
19.例题:
aaasssddd搜
20.查找全部的某文件:
用到os.walk函数
查找全部的某文件搜