Java正则表达式从入门到精通
Java正则表达式从入门到精通
-
一、JAVA正则表达式规则
Java中的正则表达式规则,在java.util.regex.Pattern类文档中有详细说明。
-
(一)字符类匹配符(只匹配一个字符)
| 规则字符 |
说明 |
| [abc] |
匹配a,b或c中的任意一个字符 |
| [^abc] |
除a,b或c之外的任意一个字符(取反) |
| [a-zA-Z] |
包含在a到z或A到Z范围内的任意一个字符(范围) |
| [a-d[m-p]] |
a到d,或m到p,等价于[a-dm-p](并集) |
| [a-z&&[def]] |
d,e或f(交集) |
| [a-z&&[^bc]] |
a到z范围中除了b和c,等价于[ad-z](减掉) |
| [a-z&&[^m-p]] |
a到z范围内除去m到p,等价于[a-lq-z] |
例程:
“a”.matches(“[abc]”); //true
“a”.matches(“[^abc]”); //false
“ab”.matches(“[abc]”); //false
“ab”.matches(“[abc][abc]”); //true
“a”.matches(“[a-z]”); //true
// 并集
“a”.matches(“[a-d[m-p]]”); //true
“e”.matches(“[a-z[m-p]]”); //false
// 交集
“a”.matches(“[a-z&&[def]]”); //false
“e”.matches(“[a-z&&[def]]”); //true
// 减去subtraction,a-z与非bc的交集
“a”.matches(“[a-z&&[^bc]]”); //true
“b”.matches(“[a-z]&&[^bc]”); //false
“a”.matches(“[a-z&&[^m-p]]”); //true
“m”.matches(“[a-z]&&[^m-p]”); //false-
(二)预定义的字符类(只匹配一个字符)
| 规则字符 |
说明 |
| . |
任意一个字符 |
| \d |
一个数字[0-9] |
| \D |
一个非数字[^0-9] |
| \h |
水平空白字符,如\t |
| \H |
非水平空白字符 |
| \s |
空白字符,如\t \n等 |
| \S |
非空白字符 |
| \v |
垂直空白字符,如\n |
| \V |
非垂直空白字符 |
| \w |
一个词字符(英文字母、数字及下划线),等价于[a-zA-Z_0-9] |
| \W |
非词字符 |
示例代码:
“a”.matches(“\\d”); //false
“2”.matches(“\\d”); //true
“a”.matches(“\\w”); //true
“2”.matches(“\\w”); //true
“我”.matches(“\\w”); //false
“_”.matches(“\\w”); //true
“我”.matches(“\\W”); //true-
(三)数量限定字符
| 规则字符 |
说明 |
| X? |
X出现0次或1次 |
| X* |
X出现0次或多次 |
| X+ |
X出现1次或多次 |
| X{n} |
X出现n次 |
| X{n,} |
X至少出现n次 |
| X{n,m} |
X出现n次到m次 |
例如:
“abcde12345”.matches(“\\w{6,}”); // true
“abcde”.matches(“\\w{6,}”); // false
“ab34”.matches(“[a-zA-Z0-9]{4}”); // true
“ab_c”.matches(“[a-zA-Z0-9]{4}”); // false
“ab56”.matches(“[\\w&&[^_]]{4}”); // true
“ab_c”.matches(“[\\w&&[^_]]{4}”); // false-
(四)分组
-
1.分组的概念
| 分组符号 |
说明 |
| (X) |
X作为一个分组,以括号括起 |
| \n |
匹配第n组 |
| \k |
按name命名分组 |
代码:
// 邮箱号
String regex1 ="\\w+@[\\w&&[^_]]{2,6}(\\.[a-zA-z]{2,3}){1,2})";
// 简易身份证号码
String regex2 ="[1-9]\\d{16}(\\d|x|x)";
// 24小时时间
String regex3 ="([01]\\d|2[0-3]):[0-5]\\d:[0-5]\\d";
String regex4 ="([01]\\d|2[0-3])(:[0-5]\\d){2}";以上代码包括在括号中的都是分组,每组括号就是一个分组,每组都有一个组号(默认的),也就是序号,编号规则为:
- 规则1:从1开始,连续不间断。
- 规则2:以左括号为基准,最左边的是第一组,其次为第二组,以此类推。
例如:
- (\\d+)(\\w+)(\\s+)
- (\\d+(\\w+))(\\s+)
第一组中(\\d+)、(\\w+)、(\\s+)依次为第1、2、3组。第二组中(\\d+)、(\\w+)、(\\s+)也依次为1、2、3组。因为只以左括号为标准,所以数括号的顺序即可。捕获分组就是把需要的分组数据捕获出来,再用一次。
2.捕获分组的练习
捕获分组就是把这一组的数据捕获出来,再用一次。
需求1:判断一个字符串的开始字符和结束字符是否一致?只考虑一个字符
举例: a123a b456b 17891 &abc& a123b
public class RegexGroupRef {
public static void main(String[] args) {
String s1 = "a123a";
String s2 = "b456b";
String s3 = "17891";
String s4 = "&abc&";
String s5 = "a123b";
String regex1 = "(.).+\\1"; //分组引用
s1.matches(regex1); // true
s2.matches(regex1); // true
s3.matches(regex1); // true
s4.matches(regex1); // true
s5.matches(regex1); // false
}
}需求2:判断一个字符串的开始部分和结束部分是否一致?可以有多个字符
举例: abc123abc b456b 123789123 &!@abc&!@ abc123abd
public class RegexGroupRef {
public static void main(String[] args) {
String regex2 = "(.+).+\\1"; //匹配字符串
String s2_1 = "abc123abc";
String s2_2 = "b456b";
String s2_3 = "123789123";
String s2_4 = "&!@abc&!@";
String s2_5 = "abc123abd";
s2_1.matches(regex2); // true
s2_2.matches(regex2); // true
s2_3.matches(regex2); // true
s2_4.matches(regex2); // true
s2_5.matches(regex2); // false
}
}需求3:判断一个字符串的开始部分和结束部分是否一致?开始部分内部每个字符也需要一致
举例: aaa123aaa bbb456bbb 111789111 &&abc&&
public class RegexGroupRef {
public static void main(String[] args) {
String regex3 = "((.)\\2*).+\\1"; // 匹配字符串
String S3_1 = "aaa123aaa";
String S3_2 = "bbb456bbb";
String S3_3 = "111789111";
String S3_4 = "&&abc&&";
String S3_5 = "aaa123aab";
S3_1.matches(regex3); // true
S3_2.matches(regex3); // true
S3_3.matches(regex3); // true
S3_4.matches(regex3); // true
S3_5.matches(regex3); // false
}
}3.捕获分组
捕获分组,也即后续还要继续使用本组的数据。
- 在本条正则内部捕获分组格式(前面已述):\\组号
- 在正则外部捕获分组格式:$组号
需求:口吃式替换
将字符串:我要学学编编编编程程程程程程
替换为:我要学编程
例程:
public class RegexStutter {
public static void main(String[] args) {
// 源字符串
String str ="我要学学编编编编程程程程程程";
// 替换重复的字符模式
String stutterPattern = "(.)\\1+";
// 参数2为$1,以为stutterPattern里的第一组分组
String resultStr = str.replaceAll(stutterPattern, "$1");
System.out.println(resultStr); // 我要学编程
}
}4.非捕获分组
分组之后不需要再用本组数据,仅仅是把数据括起来。
| 符号 |
含义 |
举例 |
| (?:正则) |
获取所有 |
Java(?:8|11|17) |
| (?=正则) |
获取前面部分 |
Java(?=8|11|17) |
| (?!正则) |
获取不是指定内容的前面部分 |
Java(?!8|11|17) |
例程:
public class RegexNonCatchable {
public static void main(String[] args) {
/*
非捕获分组:分组之后不需要再用本组数据,仅仅是把数据括起来。
身份证号码:
41080119930228457x
510801197609022309
15040119810705387X
130133197204039024
430102197606046442
*/
//身份证号码的简易正则表达式
// 非捕获分组:仅仅是把数据括起来
// 特点:不占用组号
// 这里\\1报错原因:(?:)就是非捕获分组,此时是不占用组号的。
// (?:)(?=)(?!)
// 此正则表达式会报错,因为\\1引用不到分组
String regex = "[1-9]\\d{16}(?:\\d|X|x)\\1";
"41080119930228457x".matches(regex);
}
}5.分组小结
(1)正则表达式中分组有两种:
捕获分组、非捕获分组
(2)捕获分组(默认):
可以获取每组中的内容反复使用。
(3)组号的特点:
从1开始,连续不间断以左括号为基准,最左边的是第一组
(4)非捕获分组:
分组之后不需要再用本组数据,仅仅把数据括起来,不占组号。(?:)(?=)(?!)都是非捕获分组
-
(五)逻辑操作符
| 符号 |
说明 |
| XY |
X后接Y |
| X|Y |
X或Y |
| (X) |
X作为一个捕获分组 |
| (?i) |
忽略后续字符的大小写 |
-
(六)正则表达式编写练习
-
1.验证手机号和座机号
// 验证手机号
String regex1 = “1[3-9]\\d{9}”;
“15612345678”.matches(regex1);
“13987654321”.matches(regex1);
// 验证座机号
String regex2 = “0\\d{2,3}-?[1-9]\\9{4,9}”;
“010-87563214”.matches(regex2);
“0621-10086”.matches(regex2);2.验证电子邮箱地址
String regex3 = “\\w+@[\\w&&[^_]]{2,6}(\\.[a-zA-Z0-9]+){1,2}”;
“[email protected]”.matches(regex3);
“[email protected]”.matches(regex3);
“[email protected]”.matches(regex3);(七)IDEA自动生成正则表达式插件
到Idea的Plugins中搜索any-rule插件安装,在需要生成正则表达式的地方右键点击,在弹出的菜单中选择anyrule,搜索想要的正则表达式。
安装插件:
调出AnyRule对话框:

查找合适的正则表达式:
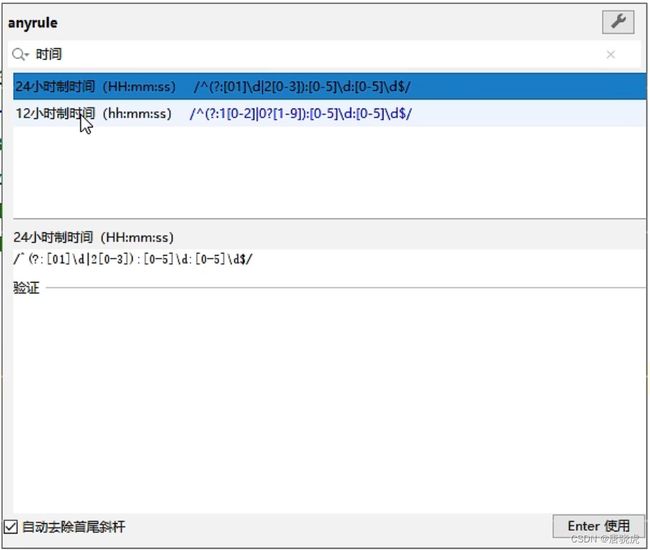
-
二、正则表达式在Java中的应用
-
(一)验证字符串是否符合正则规则
使用String对象的matches(String regex)方法。辨别此字符串是否与给定的正则表达式匹配。调用str.matches(regex)形式的方法,得到与表达式相符的结果。
-
(二)在文本中查找符合条件的子字符串
本节以一个例子开始:
例:有如下文本,请按照要求爬取数据。
Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台
要求:找出里面所有的JavaXX
首先,我们需要引入两个Java类,分别是
- Pattern类:代表正则表达式。
- Matcher类:文本匹配器,作用是按照正则表达式的规则去读取字符串,从头开始读取,在源字符串中寻找符合规则的子串。
以上两个包都位于java.util.regex包中。代码:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexTest1 {
public static void main(String[] args) {
String str = "Java自从95年问世以来,经历了很多版本," +
"目前企业中用的最多的是Java8和Java11," +
"因为这两个是长期支持版本,下一个长期支持版本是Java17," +
"相信在未来不久Java17也会逐渐登上历史舞台";
// 获取正则表达式的对象
Pattern p = Pattern.compile("Java\\d{0,2}");
// 获取文本匹配器的对象,str为源字符串(大串)
Matcher m = p.matcher(str);
// find方法拿着文本匹配器从头开始读取,
// 寻找是否满足规则的子串,
// 如果没有,返回false
// 如果有,返回true
// 在底层记录子串的起始索引和结束索引+1,索引是包左不包右
while (m.find()){
// group方法根据find方法记录的索引值,
// 取出匹配的子串返回
System.out.println(m.group());
}
}
}需求2:爬取指定网页上的身份证号码信息,代码如下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexTest2 {
public static void main(String[] args) throws IOException {
/* 需求:
* 把链接:https://www.thepaper.cn/newsDetail_forward_8981455中所有的身份证号码都爬取出来。
*/
//创建一个URL对象
URL url =new URL("https://www.thepaper.cn/newsDetail_forward_8981455");//连接上这个网址
//细节:保证网络是畅通
URLConnection conn =url.openConnection();
//创建一个对象去读取网络中的数据
BufferedReader br =new BufferedReader(new InputStreamReader(conn.getInputStream()));
// line用于暂存单行信息
String line;
//获取正则表达式的对象pattern
String regex ="[1-9]\\d{5}(?:18|19|20)\\d{2}(?:0[1-9]|10|11|12)(?:0[1-9]|[1-2]\\d|30|31)\\d{3}[\\dXx]";
Pattern pattern = Pattern.compile(regex);
//在读取的时候每次读一整行
while((line =br.readLine())!=null) {
//拿着文本匹配器的对象matcher
// 按照pattern的规则去读取当前的这一行信息
Matcher matcher = pattern.matcher(line);
while (matcher.find()) { // 判断是否有符合的子串
System.out.println(matcher.group()); // 打印获取的身份中号
}
}
br.close(); // 关闭资源
}
}需求3:匹配多种信息
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexTest3 {
public static void main(String[] args) {
/*
需求:把下面文本中的座机电话,邮箱,手机号,热线都爬取出来。
来XXX程序员培训机构学习Java,手机号:18512516758,18512508907或者联系邮箱:[email protected],
座机电话:01036517895,010-98951256 邮箱:[email protected],
热线电话:400-618-9090,400-618-4000,4006184000,4006189090
手机号的正则表达式:1[3-9]\d{9}
邮箱的正则表达式:\w+@[\w&&[^_]]{2,6}(\.[a-zA-z]{2,3}){1,2}
座机电话的正则表达式:0\d{2,3}-?[1-9]\d{4,9}
热线电话的正则表达式:400-?[1-9]\\d{2}-?[1-9]\\d{3}
*/
// 源字符串
String s = "来XXX程序员培训机构学习Java,手机号:18512516758,18512508907" +
"或者联系邮箱:[email protected]," +
" 座机电话:01036517895,010-98951256 邮箱:[email protected]," +
" 热线电话:400-618-9090,400-618-4000,4006184000,4006189090";
// 匹配字符串,四个条件用|或操作符隔开
String pattern = "(1[3-9]\\d{9})|(\\w+@[\\w&&[^_]]{2,6}(\\.[a-zA-z]{2,3}){1,2})|(0\\d{2,3}-?[1-9]\\d{4,9})|(400-?[1-9]\\d{2}-?[1-9]\\d{3})";
// 获取正则表达式对象
Pattern p = Pattern.compile(pattern);
// 获取文本匹配器
Matcher m = p.matcher(s);
// 循环获取匹配子串
while (m.find()){
System.out.println(m.group()); // 输出匹配的子串
}
}
}-
(三)有条件的匹配子串
有条件匹配
有如下文本,请按照要求爬取数据。
Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台
需求1:爬取版本号为8,11,17的Java文本,但是只要Java,不显示版本号。
需求2:爬取版本号为8,11,17的Java文本。正确爬取结果为:Java8Java11 Java17 Java17
需求3:爬取除了版本号为8,11,17的Java文本
代码如下:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexTest4 {
public static void main(String[] args) {
/* 有如下文本,请按照要求爬取数据。
* Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,
* 因为这两个是长期支持版本,下一个长期支持版本是Java17,
* 相信在未来不久Java17也会逐渐登上历史舞台。
*
* 需求1:爬取版本号为8,11,17的Java文本,但是只要Java,不显示版本号。
* 需求2:爬取版本号为8,11,17的Java文本。正确爬取结果为:Java8Java11 Java17 Java17
* 需求3:爬取除了版本号为8,11,17的Java文本,
*/
// 1.定义正则表达式
// ?可以理解为前面的数据Java
// =表示在Java后面要跟随的数据
// 但是在获取的时候,只获取前半部分
String s = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是JaVa8和JAva11," +
"因为这两个是长期支持版本,下一个长期支持版本是JavA17," +
" 相信在未来不久JAVA17也会逐渐登上历史舞台。";
// 需求1:
String regex1 = "((?i)Java)(?=8|11|17)";
// 需求2:获取JavaXX,XX为数字
String regex2 = "((?i)Java)(8|11|17)";
String regex3 = "((?i)Java)(?:8|11|17)";
// 需求3:去除Java开头后接8、11或17的字符串
String regex4 = "((?i)Java)(?!8|11|17)";
Pattern p = Pattern.compile(regex3);
Matcher m = p.matcher(s);
while (m.find()){ //这里匹配的是JaVa8、JAva11、Java17和JAVA17中的Java
System.out.println(m.group());
}
}
}-
(四)贪婪爬取和非贪婪爬取
有如下文本,请按照要求爬取数据。
Java自从95年问世以来,abbbbbbbbbbbbaaaaaaaaaaaaaaaaaa
经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台
需求1:按照ab+的方式爬取ab,b尽可能多获取
需求2:按照ab+的方式爬取ab,b尽可能少获取
- 贪婪爬取:在爬取数据的时候尽可能的多获取数据
- 非贪婪爬取:在爬取数据的时候尽可能的少获取数据
Java中默认的是贪婪爬取,如果我们在数量次+ *的后面加上问号,那么此时就是非贪婪爬取。
- +? 非贪婪匹配
- *? 非贪婪匹配
代码如下:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexGreedy {
public static void main(String[] args) {
String s = "Java自从95年问世以来,abbbbbbbbbbbbaaaaaaaaaaaaaaaaaa" +
"经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本," +
"下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
String regex1 = "ab+"; // 贪婪模式:输出结果为abbbbbbbbbbbb
String regex2 = "ab+?"; // 非贪婪模式:输出结果为ab
Pattern p = Pattern.compile(regex2);
Matcher m = p.matcher(s);
while (m.find()){
System.out.println(m.group());
}
}
}-
(五)字符串类中的正则表达式方法
| 方法 |
说明 |
| public String[] matches(String regex) |
判断字符串是否满足正则表达式的规则 |
| public String replaceAll(String regex, String newStr) |
按照正则表达式的规则进行替换 |
| public String[] split(String regex) |
按照正则表达式的规则切割字符串 |
需求:有一段字符串:小诗诗dqwefqwfqwfwq12312小丹丹dqwefqwfqwfwq12312小惠惠
要求1:把字符串中三个姓名之间的字母替换为vs
要求2:把字符串中的三个姓名切割出来
代码如下:
public class RegexTest5 {
public static void main(String[] args) {
// 小诗诗dqwefqwfqwfwq12312小丹丹dqwefqwfqwfwq12312小惠惠
String s = "小诗诗dqwefqwfqwfwq12312小丹丹dqwefqwfqwfwq12312小惠惠";
// 正则表达式
String pattern = "\\w+";
// 需求1:
// 用规则pattern去匹配,然后替换为VS
String result = s.replaceAll(pattern, "VS");
System.out.println(result);
// 需求2:
// 分割字符串
String[] ss = s.split(pattern);
for (String str:ss) {
System.out.println(str);
}
}
}https://docs.oracle.com/javase/tutorial/essential/regex/
https://docs.oracle.com/javase/8/docs/api/java/util/regex/Matcher.html
https://docs.oracle.com/javase/8/docs/api/java/util/regex/Pattern.html
https://docs.oracle.com/javase/8/docs/api/java/lang/String.html