知识蒸馏测试(使用ImageNet中的1000类dog数据,Resnet101和Resnet18分别做教师模型和学生模型)

当教师网络为resnet101,学生网络为resnet18时:
使用蒸馏方法训练的resnet18训练准确率都小于单独训练resnet18,使用蒸馏方法反而导致了下降。
当hard_loss的alpha为0.7时,下降了1.1
当hard_loss的alpha为0.6时,下降了1.7
说明当学生网络和教师网络训练准确率相差不多时,要给hard_loss权重大一点。
VanillaKD:Revisit the Power of Vanilla KnowledgeDistillation from Small Scale to Large Scale
摘要:采用更强的数据增强技术和使用更大的数据集可以直接缩小Vanilla KD与其他精心设计的KD变体之间的差距
Vanilla是基本的,普通的意思。
也就是说: 采用更强的数据增强技术和使用更大的数据集可以缩小普通的知识蒸馏(KD)算法 和知识蒸馏(KD)算法变体之间的差距。
介绍: 大部分现有的知识蒸馏(KD)方法都是针对小规模基准(例如CIFAR[19])和小型师生对(例如Res34-Res18[2]和WRN40-WRN16[10])上比较有效。
仅仅在小规模数据集上探索知识蒸馏(KD)方法可能无法在实际场景中提供全面的理解。
基于logits的一些改进KD方法:
Geoffrey E.Hinton,Oriol Vinyals,and Jeffrey Dean.Distilling the knowledge in a neural network.arXivpreprint arXiv:1503.02531,2015.1,2,3,4,5,6,7,9
Tao Huang,Shan You,Fei Wang,Chen Qian,and Chang Xu.Knowledge distillation from a strongerteacher.In Advances in Neural Information Processing Systems,2022.
Borui Zhao,Quan Cui,Renjie Song,Yiyu Qiu,and Jiajun Liang.Decoupled knowledge distillation.InIEEE/CVF Conference on Computer Vision and Pattern Recognition,2022
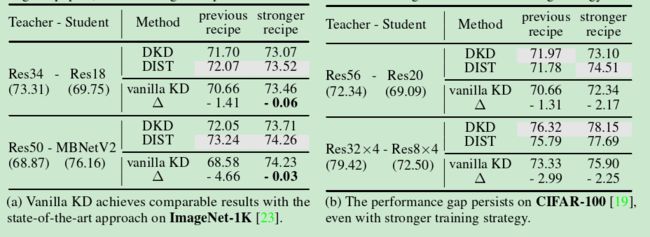
当前最先进的方法: DKD,DIST
vanilla KD
Geoffrey E.Hinton,Oriol Vinyals,and Jeffrey Dean.Distilling the knowledge in a neural network.arXivpreprint arXiv:1503.02531,2015.1,2,3,4,5,6,7,9
DKD
Borui Zhao,Quan Cui,Renjie Song,Yiyu Qiu,and Jiajun Liang.Decoupled knowledge distillation.InIEEE/CVF Conference on Computer Vision and Pattern Recognition,2022.1,2,3,4,5,6,7,9,14
知识蒸馏方法汇总
原始的蒸馏方法
kd_loss_fn = KLDiv(temperature=args.temperature).cuda()
DIST
参数采用A2:
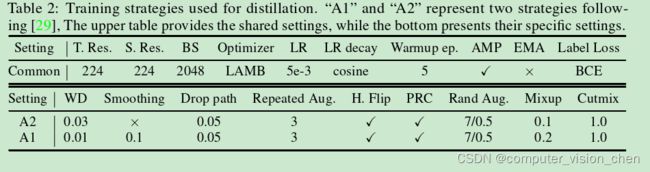
参数设置:
python -m torch.distributed.launch --nproc_per_node=8 train-kd.py /path/to/imagenet --model resnet50 --teacher beitv2_base_patch16_224 --teacher-pretrained /path/to/teacher_checkpoint --kd-loss dist --amp --epochs 300 --batch-size 256 --lr 5e-3 --opt lamb --sched cosine --weight-decay 0.02 --warmup-epochs 5 --warmup-lr 1e-6 --smoothing 0.0 --drop 0 --drop-path 0.05 --aug-repeats 3 --aa rand-m7-mstd0.5 --mixup 0.1 --cutmix 1.0 --color-jitter 0 --crop-pct 0.95 --bce-loss 1
import torch.nn as nn
def cosine_similarity(a, b, eps=1e-8):
return (a * b).sum(1) / (a.norm(dim=1) * b.norm(dim=1) + eps)
def pearson_correlation(a, b, eps=1e-8):
return cosine_similarity(a - a.mean(1).unsqueeze(1),
b - b.mean(1).unsqueeze(1), eps)
def inter_class_relation(y_s, y_t):
return 1 - pearson_correlation(y_s, y_t).mean()
def intra_class_relation(y_s, y_t):
return inter_class_relation(y_s.transpose(0, 1), y_t.transpose(0, 1))
class DIST(nn.Module):
def __init__(self, beta=1.0, gamma=1.0, tau=1.0):
super(DIST, self).__init__()
self.beta = beta
self.gamma = gamma
self.tau = tau
def forward(self, z_s, z_t, **kwargs):
y_s = (z_s / self.tau).softmax(dim=1)
y_t = (z_t / self.tau).softmax(dim=1)
inter_loss = self.tau ** 2 * inter_class_relation(y_s, y_t)
intra_loss = self.tau ** 2 * intra_class_relation(y_s, y_t)
kd_loss = self.beta * inter_loss + self.gamma * intra_loss
return kd_loss
# 调用
kd_loss_fn = DIST(beta=args.dist_beta, gamma=args.dist_gamma, tau=args.temperature).cuda()
论文:
Tao Huang,Shan You,Fei Wang,Chen Qian,and Chang Xu.Knowledge distillation from a strongerteacher.In Advances in Neural Information Processing Systems,2022.1,2,3,4,5,6,9,14
论文解读:
【知识蒸馏】 Knowledge Distillation from A Stronger Teacher
https://blog.csdn.net/AaaA00000001/article/details/129144417
代码
https://github.com/hunto/DIST_KD
待更新