[论文阅读]VoxSet——Voxel Set Transformer
VoxSet
Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds
论文网址:VoxSet
论文代码:VoxSet
简读论文
这篇论文提出了一个称为Voxel Set Transformer(VoxSeT)的3D目标检测模型,主要有以下几个亮点:
-
提出了基于体素的集合自注意力(Voxel Set Attention,VSA)模块。该模块将整个场景划分为非重叠的体素,针对每个体素内的点云特征学习自注意力表示。其通过引入一组潜在代码来解决不同体素包含点数不同的问题,从而避免了其他方法中随机舍弃点或填充虚点的做法。
-
基于VSA模块,构建了端到端的VoxSeT检测器。网络主干采用VSA模块、多层感知机层交错堆叠的结构。并在最后将点云特征编码到BEV表示中,供检测头预测边界框。
-
在Waymo和KITTI两个数据集上进行了评估。结果显示VoxSeT能够获得与当前最先进方法相媲美的性能,表明其可以作为点云建模的一个有竞争力的替代方案。
-
作者通过可视化分析等 ablation 实验验证了VSA模块的有效性,如其可以聚焦于目标区域,不同的潜在代码可以编码目标的不同上下文信息等。
-
与其他基于卷积或点的方法相比,VoxSeT在两个数据集上的表现更为稳定,显示了其泛化能力的优势。
总的来说,这篇论文通过集合自注意力的方式,将点云处理建模为一个集合到集合的转换问题,提供了一个新的基于transformer的检测器框架,值得学习和参考。
摘要
Transformer 在许多 2D 视觉任务中表现出了良好的性能。然而,由于点云是一个长序列并且在3D空间中分布不均匀,因此在大规模点云数据上计算自注意力是很麻烦的。为了解决这个问题,现有的方法通常通过将点分组为相同大小的簇来本地计算自注意力,或者对离散表示执行卷积自注意力。然而,前者会导致随机点丢失,而后者通常具有狭窄的注意力范围。在本文中,我们提出了一种新颖的基于体素的架构,即Voxel Set Transformer(VoxSeT),通过集合到集合的转换来检测点云中的 3D 对象。 VoxSeT 建立在基于体素的集合注意力(VSA)模块之上,该模块通过两个交叉注意力减少每个体素中的自注意力,并对一组潜在代码引起的隐藏空间中的特征进行建模。借助VSA模块,VoxSeT可以管理大范围内任意大小的体素化点簇,并以线性复杂度并行处理它们。所提出的 VoxSeT 将 Transformer 的高性能与基于体素的模型的效率相结合,可以作为卷积和基于点的主干网的良好替代方案。
引言
3D 点云的对象检测已受到广泛关注,因为它为自动驾驶、机器人和虚拟现实等许多应用提供了支持。与 2D 图像不同,3D 点云在连续空间中自然稀疏且分布不均匀,阻碍了 CNN 层的直接应用。为了解决这个问题,一些方法首先将点云转换为离散表示,然后应用CNN模型来提取高维特征。另一类方法对连续空间中的点云进行建模,其中通过交错分组和聚合步骤提取多尺度特征。
除了上述两种方案之外,基于Transformer的模型最近在处理点云数据方面引起了极大的兴趣,因为Transformer中使用的自注意力对于输入组件的排列和基数是不变的,这使得 Transformer 成为点云处理的合适选择。然而,Transformer 模型的主要局限性在于自注意力计算是二次的。每个token都必须使用前一层中的所有其他令牌进行更新,这使得自注意力对于长序列点云来说变得棘手。 Point Transformer 在 PointNet 架构上构建Transformer,该架构将点云数据分层分组到不同的集群中,并计算每个集群中的自注意力。 CT3D 提出了一个两阶段点云检测器,其中提取 3D RoIs 以对第一阶段中的原始点进行分组,并将Transformer应用于第二阶段中的分组点。
![[论文阅读]VoxSet——Voxel Set Transformer_第1张图片](http://img.e-com-net.com/image/info8/8a2f1a07c7ae48a2934f54660b7ad20e.jpg)
然而,由于点云的分布极其不均匀,每个簇中的点数量差异很大。为了使自注意力能够并行运行,当前的方法通过随机丢弃点或填充虚拟点来平衡每个集群中的token数量(见图1(a))。这导致检测结果不稳定和冗余计算。此外,每次将n个点分组到m个簇的操作都会花费O(nm)的复杂度,这是相对密集的。或者,Voxel Transformer 在离散体素网格上执行自注意力,如图 1(b) 所示。它以卷积方式计算自注意力,因此与具有 O(n) 复杂度的稀疏卷积一样高效。然而,由于卷积注意力是逐点操作,为了节省内存,卷积核的注意力域通常很小,从而阻碍了体素Transformer对长程依赖性进行建模。值得一提的是,尽管 Group-free 和 3DETR 通过在一组减少的种子点上计算自注意力,提出了一种很有前途的解决方案,但该解决方案仅适用于点云相对密集的室内场景并集中。考虑到室外场景的点云通常稀疏、大规模(例如> 20k)且分布不均匀,种子点的规模和覆盖范围仍然是一个问题。
为了解决上述问题,本文引入了基于体素的集合注意力(VSA)模块。对于每个 VSA,将整个场景划分为不重叠的 3D 体素,并即时高效地计算输入点的体素索引。使用这些体素来确定注意力区域,类似于 SwinTransformer 中的窗口注意力。与图像不同,LiDAR具有不规则的结构,并且产生的注意力组具有不同的长度,这阻碍了模型的并行化。
受induced set Transformer的启发,本文为每个体素分配一组可训练的“潜在代码”。这些潜在代码为点云构建了一个固定长度的瓶颈,通过该瓶颈,来自体素内输入点的信息可以被压缩到静态隐藏空间。该公式基于以下关键观察:自注意力矩阵通常是低秩的,因此可以将密集的完全自注意力分解为两个连续的交叉注意力模块。如图 1© 所示,VSA 首先通过关注输入点的投影特征(即键和值)将用作查询的潜在代码转换为隐藏空间。变换后的隐藏特征对每个体素中输入点的上下文信息进行编码,并通过卷积前馈网络进行丰富,其中跨体素的特征在空间域中交换其信息。之后,隐藏特征与输入仔细融合,产生输入分辨率的输出特征。通过利用潜在代码,可以对所有体素中执行的交叉注意力进行向量化,使 VSA 成为高度并行的模块。给定 n 维输入特征和 k 个潜在代码,VSA 的复杂度为 O(nkd),并且可以用一般的矩阵乘法来实现。
通过 VSA,本文提出了一种voxel set Transformer (VoxSeT),通过在集合到集合的转换过程中学习点云特征来检测 3D 对象。 VoxSeT 由 VSA 模块、MLP 层和用于鸟瞰 (BEV) 特征提取的浅层 CNN 组成。为了验证所提出模型的有效性,本文在两个 3D 检测基准 KITTI 和 Waymo 开放数据集上进行了实验。 VoxSeT 实现了与当前最先进技术竞争的性能。此外,所提出的 VSA 模块可以无缝地采用基于点的检测器,例如 PointRCNN ,并展示了相对于集合抽象模块的优势。
总之,本文首先发明了一种基于体素的集合注意力模块,它可以对任意大小的令牌簇的远程依赖性进行建模,绕过当前基于分组和基于卷积的注意力模块的限制。然后,提出了一个voxel set transformer,通过利用transformer在大规模序列数据上的优势来有效地学习点云特征。本文的工作为 3D 点云数据处理的当前卷积和基于点的主干提供了一种新颖的替代方案。
相关工作
基于点云的3D目标检测
早期的点云 3D 对象检测方法可以分为两类。第一类方法将点云转换为更紧凑的表示,例如鸟瞰(BEV)图像、正面视图范围图像和体积特征。严等人开发了一种稀疏卷积主干,通过将点云编码为 3D 稀疏张量来有效地处理点云。朗等人通过将体素特征堆叠为“支柱”并使用2D CNN进行处理,进一步加快了检测率。另一类方法通过采用 PointNet架构来处理连续空间中的点云。通过交错分组和采样操作分阶段提取多尺度中的逐点特征。施等人和杨等人,建议从 PointNet 输出生成 3D RoIs,并将 RoIs 应用到逐点特征分组以进一步细化。齐等人提出了一种深度投票方法,对物体表面的点进行聚类,以检测点不足的物体。与紧凑表示不同,逐点特征保留了原始点云的更多细节和细粒度结构。基于这一事实,一些方法在点和体素空间中采用混合表示来实现更可靠的检测输出。
本文提出的架构很大程度上是由基于体素的方法推动的。本文将点云划分为体素网格并在本地执行自注意力,赋予模型归纳偏差和计算效率。
点云分析中的transformer
最近,Transformer 在许多计算机视觉任务中展示了其巨大成功,例如图像分类、2D 目标检测和其他密集预测任务 。对于点云分析,Zhao 等人提出了一种基于减法注意力的新型点云分类和分割算子。郭等人研究了在特征和边缘空间中处理点云的双重关注。米斯拉等人和刘等人使用 Transformer 将点云作为顺序数据进行处理,防止模型堆叠分层分组和采样模块。苗等人将自注意力嵌入到稀疏卷积核中。盛等人将transformer构建在两级检测器之上,并对按 RoI 分组的点进行关注。
与上述在固定大小的标记簇上执行自注意力的方法不同,本文提出的voxel set transformer利用induced set transformer的思想将自注意力分解为两个交叉注意力,从而可以执行自注意力注意任意大小的标记簇。
方法
准备工作
由于其二次计算复杂性,直接将自注意力应用于点云数据是禁止的。为了绕过这个问题,[Set transformer]中提出了induced set注意力块,其中集合中的完整自注意力由一组潜在代码诱导的两个减少的交叉注意力来近似。给定大小为 n、维度为 d 的输入集 X ∈ Rn×d 和 k 个潜在代码 L ∈ Rk×d,来自induced set注意力块的输出集 O ∈ Rn×d 可以表示为:
![[论文阅读]VoxSet——Voxel Set Transformer_第2张图片](http://img.e-com-net.com/image/info8/e4c68c4c5ca34718bcff38e4b0ebeb99.jpg)
第一个交叉注意力通过关注输入集将潜在特征 L 转换为隐藏特征 H。此步骤的复杂度为 O(nkd),与 n 成线性关系,因为潜在代码的数量 k 是固定的并且通常非常小。转换后的隐藏特征包含有关输入集 X 的信息,然后通过点前馈网络(FFN)更新它们。这种逐点操作的复杂度为 O(k),并且它从输入集中学习高度语义的特征。第二个交叉注意力关注输入集到生成的隐藏特征,这会花费 O(nkd) 复杂度,产生长度为 n 的输出集。诱导集注意力基于自注意力可以用低秩投影来近似的假设,因此自注意力可以被视为对输入执行 k 聚类,其中潜在代码作为聚类中心。这也类似于聚类注意力 和 Linformer,其中输入集通过线性投影显式减少。
Voxel-based Set Attention (VSA)
class MLP(nn.Module):
""" Very simple multi-layer perceptron (also called FFN)"""
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
return x
class VoxSeT(VFETemplate):
def __init__(self, model_cfg, num_point_features, voxel_size, point_cloud_range, grid_size, **kwargs):
super().__init__(model_cfg=model_cfg)
self.num_latents = self.model_cfg.NUM_LATENTS
self.input_dim = self.model_cfg.INPUT_DIM
self.output_dim = self.model_cfg.OUTPUT_DIM
self.input_embed = MLP(num_point_features, 16, self.input_dim, 2)
self.pe0 = PositionalEncodingFourier(64, self.input_dim)
self.pe1 = PositionalEncodingFourier(64, self.input_dim * 2)
self.pe2 = PositionalEncodingFourier(64, self.input_dim * 4)
self.pe3 = PositionalEncodingFourier(64, self.input_dim * 8)
self.mlp_vsa_layer_0 = MLP_VSA_Layer(self.input_dim * 1, self.num_latents[0])
self.mlp_vsa_layer_1 = MLP_VSA_Layer(self.input_dim * 2, self.num_latents[1])
self.mlp_vsa_layer_2 = MLP_VSA_Layer(self.input_dim * 4, self.num_latents[2])
self.mlp_vsa_layer_3 = MLP_VSA_Layer(self.input_dim * 8, self.num_latents[3])
self.post_mlp = nn.Sequential(
nn.Linear(self.input_dim * 16, self.output_dim),
nn.BatchNorm1d(self.output_dim, eps=1e-3, momentum=0.01),
nn.ReLU(),
nn.Linear(self.output_dim, self.output_dim),
nn.BatchNorm1d(self.output_dim, eps=1e-3, momentum=0.01),
nn.ReLU(),
nn.Linear(self.output_dim, self.output_dim),
nn.BatchNorm1d(self.output_dim, eps=1e-3, momentum=0.01)
)
self.register_buffer('point_cloud_range', torch.FloatTensor(point_cloud_range).view(1, -1))
self.register_buffer('voxel_size', torch.FloatTensor(voxel_size).view(1, -1))
self.grid_size = grid_size.tolist()
a, b, c = voxel_size
self.register_buffer('voxel_size_02x', torch.FloatTensor([a * 2, b * 2, c]).view(1, -1))
self.register_buffer('voxel_size_04x', torch.FloatTensor([a * 4, b * 4, c]).view(1, -1))
self.register_buffer('voxel_size_08x', torch.FloatTensor([a * 8, b * 8, c]).view(1, -1))
a, b, c = grid_size
self.grid_size_02x = [a // 2, b // 2, c]
self.grid_size_04x = [a // 4, b // 4, c]
self.grid_size_08x = [a // 8, b // 8, c]
def get_output_feature_dim(self):
return self.output_dim
def forward(self, batch_dict, **kwargs):
points = batch_dict['points']
points_offsets = points[:, 1:4] - self.point_cloud_range[:, :3]
coords01x = points[:, :4].clone()
coords01x[:, 1:4] = points_offsets // self.voxel_size
pe_raw = (points_offsets - coords01x[:, 1:4] * self.voxel_size ) / self.voxel_size
coords01x, inverse01x = torch.unique(coords01x, return_inverse=True, dim=0)
coords02x = points[:, :4].clone()
coords02x[:, 1:4] = points_offsets // self.voxel_size_02x
coords02x, inverse02x = torch.unique(coords02x, return_inverse=True, dim=0)
coords04x = points[:, :4].clone()
coords04x[:, 1:4] = points_offsets // self.voxel_size_04x
coords04x, inverse04x = torch.unique(coords04x, return_inverse=True, dim=0)
coords08x = points[:, :4].clone()
coords08x[:, 1:4] = points_offsets // self.voxel_size_08x
coords08x, inverse08x = torch.unique(coords08x, return_inverse=True, dim=0)
src = self.input_embed(points[:, 1:])
src = src + self.pe0(pe_raw)
src = self.mlp_vsa_layer_0(src, inverse01x, coords01x, self.grid_size)
src = src + self.pe1(pe_raw)
src = self.mlp_vsa_layer_1(src, inverse02x, coords02x, self.grid_size_02x)
src = src + self.pe2(pe_raw)
src = self.mlp_vsa_layer_2(src, inverse04x, coords04x, self.grid_size_04x)
src = src + self.pe3(pe_raw)
src = self.mlp_vsa_layer_3(src, inverse08x, coords08x, self.grid_size_08x)
src = self.post_mlp(src)
batch_dict['point_features'] = F.relu(src)
batch_dict['point_coords'] = points[:, :4]
batch_dict['pillar_features'] = F.relu(torch_scatter.scatter_max(src, inverse01x, dim=0)[0])
batch_dict['voxel_coords'] = coords01x[:, [0, 3, 2, 1]]
return batch_dict
class MLP_VSA_Layer(nn.Module):
def __init__(self, dim, n_latents=8):
super(MLP_VSA_Layer, self).__init__()
self.dim = dim
self.k = n_latents
self.pre_mlp = nn.Sequential(
nn.Linear(dim, dim),
nn.BatchNorm1d(dim,eps=1e-3, momentum=0.01),
nn.ReLU(),
nn.Linear(dim, dim),
nn.BatchNorm1d(dim,eps=1e-3, momentum=0.01),
nn.ReLU(),
nn.Linear(dim, dim),
nn.BatchNorm1d(dim,eps=1e-3, momentum=0.01),
)
# the learnable latent codes can be obsorbed by the linear projection
self.score = nn.Linear(dim, n_latents)
conv_dim = dim * self.k
self.conv_dim = conv_dim
# conv ffn
self.conv_ffn = nn.Sequential(
nn.Conv2d(conv_dim, conv_dim, 3, 1, 1, groups=conv_dim, bias=False),
nn.BatchNorm2d(conv_dim),
nn.ReLU(),
nn.Conv2d(conv_dim, conv_dim, 3, 1, 1, groups=conv_dim, bias=False),
nn.BatchNorm2d(conv_dim),
nn.ReLU(),
# nn.Conv2d(conv_dim, conv_dim, 3, 1, dilation=2, padding=2, groups=conv_dim, bias=False),
# nn.BatchNorm2d(conv_dim),
# nn.ReLU(),
nn.Conv2d(conv_dim, conv_dim, 1, 1, bias=False),
)
# decoder
self.norm = nn.BatchNorm1d(dim,eps=1e-3, momentum=0.01)
self.mhsa = nn.MultiheadAttention(dim, num_heads=1, batch_first=True)
def forward(self, inp, inverse, coords, bev_shape):
x = self.pre_mlp(inp)
# encoder
attn = torch_scatter.scatter_softmax(self.score(x), inverse, dim=0)
dot = (attn[:, :, None] * x.view(-1, 1, self.dim)).view(-1, self.dim*self.k)
x_ = torch_scatter.scatter_sum(dot, inverse, dim=0)
# conv ffn
batch_size = int(coords[:, 0].max() + 1)
h = spconv.SparseConvTensor(F.relu(x_), coords.int(), bev_shape, batch_size).dense().squeeze(-1)
h = self.conv_ffn(h).permute(0,2,3,1).contiguous().view(-1, self.conv_dim)
flatten_indices = coords[:, 0] * bev_shape[0] * bev_shape[1] + coords[:, 1] * bev_shape[1] + coords[:, 2]
h = h[flatten_indices.long(), :]
h = h[inverse, :]
# decoder
hs = self.norm(h.view(-1, self.dim)).view(-1, self.k, self.dim)
hs = self.mhsa(x.view(-1, 1, self.dim), hs, hs)[0]
hs = hs.view(-1, self.dim)
# skip connection
return torch.cat([inp, hs], dim=-1)
class PositionalEncodingFourier(nn.Module):
"""
Positional encoding relying on a fourier kernel matching the one used in the
"Attention is all of Need" paper. The implementation builds on DeTR code
https://github.com/facebookresearch/detr/blob/master/models/position_encoding.py
"""
def __init__(self, hidden_dim=64, dim=128, temperature=10000):
super().__init__()
self.token_projection = nn.Linear(hidden_dim * 3, dim)
self.scale = 2 * math.pi
self.temperature = temperature
self.hidden_dim = hidden_dim
def forward(self, pos_embed, max_len=(1, 1, 1)):
z_embed, y_embed, x_embed = pos_embed.chunk(3, 1)
z_max, y_max, x_max = max_len
eps = 1e-6
z_embed = z_embed / (z_max + eps) * self.scale
y_embed = y_embed / (y_max + eps) * self.scale
x_embed = x_embed / (x_max + eps) * self.scale
dim_t = torch.arange(self.hidden_dim, dtype=torch.float32, device=pos_embed.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.hidden_dim)
pos_x = x_embed / dim_t
pos_y = y_embed / dim_t
pos_z = z_embed / dim_t
pos_x = torch.stack((pos_x[:, 0::2].sin(),
pos_x[:, 1::2].cos()), dim=2).flatten(1)
pos_y = torch.stack((pos_y[:, 0::2].sin(),
pos_y[:, 1::2].cos()), dim=2).flatten(1)
pos_z = torch.stack((pos_z[:, 0::2].sin(),
pos_z[:, 1::2].cos()), dim=2).flatten(1)
pos = torch.cat((pos_z, pos_y, pos_x), dim=1)
pos = self.token_projection(pos)
return pos
与图像不同,点云分布广泛,在场景层面语义关联较弱,而在局部区域具有较强的结构细节。本文不是将所有输入点压缩到隐藏空间中,而是修改上述indeuced set注意力以在本地执行。具体来说,将场景划分为体素网格,并为每个体素分配一组潜在代码。将该模块称为基于体素集合的注意力(VSA)。
Scatter kernel function. : 如前所述,VSA 是一个高度并行的模块,其中跨体素的操作可以矢量化。这种矢量化可以通过 scatter function 来实现,它是一个 cuda 内核库,可以在矩阵的不同段上执行对称约简,例如求和、最大值和平均值。在本文的例子中,将输入集视为单个矩阵,其中的每一行对应于一个逐点特征,并且其所属的体素可以通过体素坐标表来索引。
设 {pi = (xi, yi, zi) : i = 1, …n} 表示点云的坐标,[dx, dy, dz] 为三维像素大小。体素坐标 V 可以通过以下公式计算: V = {Vi = (⌊xi/dx⌋, ⌊yi/dy⌋, ⌊zi/dz⌋) : i = 1, …, n},其中⌊ . ⌋ 是下取整函数。因此,给定逐点输入特征 {Xi : 1 = 1, …n},在对称函数 F(·) 之后它们的简化体素形式 {Yj : j = 1, …,m} 可以是表示为:

其中 m 是非空体素的数量。利用散点函数Fscatter,上式可以写成向量化的形式,即
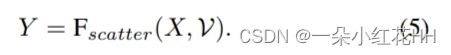
通过部署 VSA,不需要随机删除或填充每个体素中的点,并且模型的复杂度是线性的。
在图 2 中,为了便于理解,本文以矩阵乘法的形式说明了 VSA。可以看出,该模块类似于编码器-解码器架构,其中输入集被编码到隐藏空间,然后通过 ConvFFN 细化隐藏特征,最后解码以产生输出集。
![[论文阅读]VoxSet——Voxel Set Transformer_第3张图片](http://img.e-com-net.com/image/info8/8b93653c9e744f69bbf52b5f5de13407.jpg)
Encoder. : 在编码器中,首先使用线性投影将前一个模块的输入特征分别投影到键 K ∈ Rn×d 和值 V ∈ Rn×d。接下来,在key和潜在代码(查询)L ∈ Rk×d 之间执行交叉注意力,产生注意力矩阵 A ∈ Rn×k×d。然后对注意力矩阵 A 进行体素归一化以获得 A~ ,并与该value相乘,产生隐藏特征 H~ 。 H~的计算可以表示为:
![[论文阅读]VoxSet——Voxel Set Transformer_第4张图片](http://img.e-com-net.com/image/info8/6347a64832b542e99f04b89713013d37.jpg)
之后,根据体素索引 V 对隐藏特征进行体素缩减:
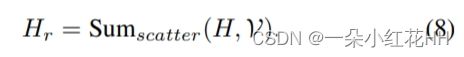
编码器中的总体计算包括两个 GEMM 和两个分散操作。编码器的整体复杂度为 O(2n(k + 1)d)。
值得一提的是,基于交叉注意力的编码方案可以被视为[pointpillars,second,voxelnet]中使用的体素特征编码(VFE)的扩展。不同之处在于,VFE 将体素内的点编码为单个特征向量,而本文的方案则基于由潜在特征组成的码本对点进行编码。由于VSA的高表达能力,可以使用相对较大的体素尺寸来捕获大范围的特征。
Convolutional feed-forward network. : VSA 的核心思想是使用潜在代码将区域特征编码到隐藏空间中。隐藏特征作为瓶颈,通过它本文应用ConvFFN来实现更灵活和复杂的信息更新。与仅执行逐点标记更新的传统 FFN 不同,ConvFFN 能够实现跨体素的信息交换,这对于密集预测尤其重要。为了自适应地将体素特征与全局依赖性相结合,根据体素坐标 Cr 将减少的隐藏特征分散到 3D 稀疏张量中,然后对它们进行两个深度卷积(DwConv)以强制空间域中的特征交互。给定卷积权重 W1 和 W2,来自 ConvFFN 的丰富隐藏特征 Hˆ r ∈ Rm×k×d 可以写为:

其中 σ 表示非线性激活,T 表示稀疏张量的公式,DwConv 中的组数等于潜在特征的组数。此操作的复杂度为 O(HWDkd/dxdydz ),其中 H、W、D 分别指三个方向的点云范围,[dx, dy, dz] 指定体素大小。 ConvFFN 在 VSA 中发挥着重要作用,因为它为模块引入了理想的归纳偏差和全局上下文。
Decoder. : 解码器根据丰富的隐藏特征 Hˆ r 重建输出集。具体来说,首先基于体素索引 V 广播隐藏特征,产生与输入集长度相同的 Hˆ ∈ Rn×k×d。然后,使用线性投影分别从输入集和隐藏特征生成查询、键值对。给定查询 Q ∈ Rn×d、键 K ∈ Rn×k×d 和值 V ∈ Rn×k×d 的矩阵,解码器输出 O 可以计算为:
![[论文阅读]VoxSet——Voxel Set Transformer_第5张图片](http://img.e-com-net.com/image/info8/a74e1131330843a2b90b48fe04923d2a.jpg)
解码器的整体计算复杂度为O(2nkd)。由于交叉注意力机制的灵活性,VSA 将点云处理表述为一个 set-set 转换问题。
Relative position embedding. : 保留点云的局部结构对于输入特征和输出特征提高性能至关重要。因此,本文引入了位置嵌入(PE)模块,将体素内点云的局部坐标编码为高维特征,并将它们注入到每个 VSA 模块中。具体来说,PE 模块应用傅里叶参数化来取值 [sin(fkπx), cos(fkπ, x)],给定归一化局部坐标 x ∈ [0, 1] 和带宽为 L 的第 k 个频率 fk。得到的傅里叶embedding 的维度为 3L,通过可学习的线性层进一步映射到第一个 MLP 模块的输入维度。
Voxel Set Transformer (VoxSeT)
VoxSeT 的整体架构如图 3 所示。遵循传统的 Transformer 范例,VoxSeT 主干由互连的多层感知 (MLP) 和 VSA 模块组成。使用批量归一化作为归一化层,并将每个 VSA 模块包装到残差块中以获得最佳梯度流。
![[论文阅读]VoxSet——Voxel Set Transformer_第6张图片](http://img.e-com-net.com/image/info8/eb977423fa2d43a987d8fbf2f9bdedc2.jpg)
与基于分组的方法逐步下采样和聚合逐点特征以进行上下文提取不同,本文的骨干网将点云特征提取为集合到集合的转换过程。特征的语义级别由 VSA 模块中体素的大小控制。本文凭经验发现,应用大体素可以学习更丰富的上下文信息,并更好地理解具有稀疏点的对象,特别是行人和骑自行车的人实例。
Birds-eye-view feature encoding. : 在点云检测中,一个常见的现象是使用密集鸟瞰(BEV)特征的模型通常比使用稀疏逐点特征的模型获得更高的召回率。在这方面,本文将主干网的逐点特征编码为 BEV 表示,并应用浅层 CNN 来增加特征密度。 CNN 只有两个跨步,每个跨步涉及三个卷积。两个步幅的卷积特征最终被连接并传递到检测头进行边界框预测。为了生成 BEV 特征,将逐点特征聚合在尺寸为 0.36m×0.36m 的柱子内,并应用“软池化”操作来生成 BEV 特征。给定第 j 个支柱中的逐点输出特征 Xj ∈ Rk×d,池化 Fj 后的支柱特征可以表示为:
![[论文阅读]VoxSet——Voxel Set Transformer_第7张图片](http://img.e-com-net.com/image/info8/82536373176b40bba0fd90c165ad5a30.jpg)
Detection head and training objectives. : 为了增强 VoxSeT 主干的表现力,本文遵循 PointRCNN 将前景分割损失 Lseg 应用于输出特征。这迫使 VoxSeT 捕获上下文信息以生成准确的边界框。检测头遵循传统的基于锚的设计。最终的损失就变成:

其中Np是与anchor的IoU在[σ1,σ2]之间的正样本的数量。 Lcls 是边界框分类的焦点损失,Lreg 是边界框偏移回归的 Smooth-Ll 损失。 Ldir 是用于边界框方向预测的二元熵损失。
Two-stage model. : 值得注意的是,VoxSeT 可以扩展到两级检测器,其中采用 LiDAR-RCNN 中的高效 RoI 头作为本文的第二级模块。
结论
本文提出了 VoxSeT,这是一种基于 Transformer 的新颖框架,用于从 LiDAR 点云进行 3D 对象检测。与之前使用稀疏 CNN 和 PointNet 主干网络来学习点云特征的 3D LiDAR 检测器相比,首次尝试将点云处理建模为集合到集合的转换,从而在每次处理时都保留原始点云的完整分辨率。特征提取步骤,本文提出了一种基于体素的集合注意力模块,该模块对任意大小的体素簇执行自注意力,并使用来自大感受野的更具辨别力的上下文信息对点特征进行编码。 Waymo 和 KITTI 数据集上的实验结果表明, VoxSeT 可以实现具有竞争力的性能,使其成为点云建模的良好替代方案。
应该指出的是,在 VoxSeT 中,本文只探索了一种基于诱导潜在代码的线性注意力的可能表述。这限制了 VoxSeT 表示不同点云结构及其相关性的表达能力。通过使用更强的注意力机制,VoxSeT的性能可以进一步提高。