java集合框架(超详细)
文章目录
-
- 1.1、集合框架概述
- 1.2、集合的分类
- 二、List接口
-
- 2.1、ArrayList类
- 2.2、LinkedList类
- 三、泛型
-
- 3.1、什么是泛型
- 3.2、自定义和使用泛型
- 3.3、在集合中使用泛型
- 四、集合遍历
- 4.1、集合元素遍历
-
- 4.2、并发修改异常
- 五、Set接口
-
- 5.1、HashSet类
- 5.2、TreeSet类
- 六、Map接口
-
- 6.1、认识Map
- 6.2、Map常用的API
- 6.3、HashSet
- 6.4、TreeMap
# 一、集合框架体系
思考:既然数组可以存储多个数据,为什么要出现集合?
数组的长度是固定的,集合的长度是可变的。
使用Java类封装出一个个容器类,开发者只需要直接调用即可,不用再手动创建容器类。
1.1、集合框架概述
集合是Java中提供的一种容器,可以用来存储多个数据,根据不同存储方式形成的体系结构,就叫做集合框架体系(掌握)。集合也时常被称为容器。
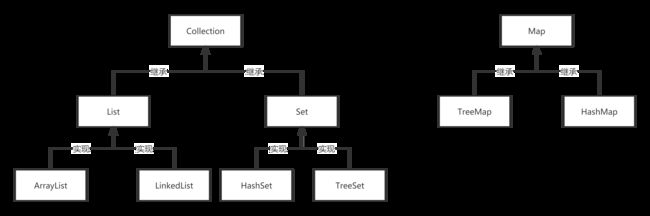
List、Set集合是继承了Colection接口,跟Collection是继承关系
而ArrayList、LinkedList跟List是继承关系,HashSet、TreeSet跟Set也是继承关系,HashMap、TreeMap跟Map也是继承关系
-
Collection接口:泛指广义上集合,主要表示List和Set两种存储方式。
-
List接口:表示列表,规定了允许记录添加顺序,允许元素重复的规范。
-
Set接口:表示狭义上集合,规定了不记录添加顺序,不允许元素重复的规范。
-
Map接口:表示映射关系,规定了两个集合映射关系的规范。
1.2、集合的分类
根据容器的存储特点的不同,可以分成三种情况:

List(列表):允许记录添加顺序,允许元素重复。=> **元素有序且可重复**
Set(数据集):不记录添加顺序,不允许元素重复。=> **元素无序且唯一**
二、List接口
List接口是Collection接口子接口,List接口定义了一种规范,要求该容器允许记录元素的添加顺序,也允许元素重复。那么List接口的实现类都会遵循这一种规范。
List集合存储特点:
-
允许元素重复
-
允许记录元素的添加先后顺序
该接口常用的实现类有:
ArrayList类:数组列表,表示数组结构,底层采用数组实现,开发中使用对多的实现类,重点。
LinkedList类:链表,表示双向列表和双向队列结构,采用链表实现,使用不多。
Stack类:栈,表示栈结构,采用数组实现,使用不多。
Vector类:向量,其实就是古老的ArrayList,采用数组实现,使用不多。
一般来说,集合接口的实现类命名规则:(底层数据结构 + 接口名)例如:ArrayList
2.1、ArrayList类
ArrayList类,基于数组算法的列表,通过查看源代码会发现底层其实就是一个Object数组。
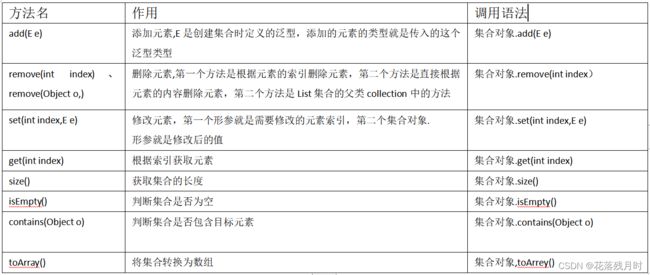
ArrayList常用方法的API:
public class ArrayListDemo1 {
public static void main(String[] args) {
// 创建一个默认长度的列表对象
List list = new ArrayList();
// 打印集合中元素的个数
System.out.println("元素数量:"+list.size());//0
// 添加操作:向列表中添加4个元素
list.add("Will");
list.add(100);
list.add(true);
list.add("Lucy");
// 查询操作:
System.out.println("列表中所有元素:"+list);//输出:[Will, 100, true, Lucy]
System.out.println("元素数量:"+list.size());//4
System.out.println("第一个元素:"+list.get(0));//Will
// 修改操作:把索引为2的元素,替换为wolfcode
list.set(2, "wolfcode");
System.out.println("修改后:"+list);//输出:[Will, 100, wolfcode, Lucy]
// 删除操作:删除索引为1的元素
list.remove(1);
System.out.println("删除后:"+list);//输出:[Will, wolfcode, Lucy]
}
}
2.2、LinkedList类
LinkedList类,底层采用链表算法,实现了链表,队列,栈的数据结构。无论是链表还是队列主要操作的都是头和尾的元素,因此在LinkedList类中除了List接口的方法,还有很多操作头尾的方法。
LinkedList常用方法的API:

其余方法:
boolean offerFirst(Object e) 在此列表的开头插入指定的元素。
boolean offerLast(Object e) 在此列表末尾插入指定的元素。
Object peekFirst() 获取但不移除此列表的第一个元素;如果此列表为空,则返回 null。
Object peekLast() 获取但不移除此列表的最后一个元素;如果此列表为空,则返回 null。
Object pollFirst() 获取并移除此列表的第一个元素;如果此列表为空,则返回 null。
Object pollLast() 获取并移除此列表的最后一个元素;如果此列表为空,则返回 null。
void push(Object e) 将元素推入此列表所表示的栈。
Object pop() 从此列表所表示的栈处弹出一个元素。
Object peek() 获取但不移除此列表的头(第一个元素)。
LinkedList之所以有这么多方法,是因为自身实现了多种数据结构,而不同的数据结构的操作方法名称不同,在开发中LinkedList使用不是很多,知道存储特点就可以了。
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList list = new LinkedList();
//添加元素
list.addFirst("A");
list.addFirst("B");
System.out.println(list);
list.addFirst("C");
System.out.println(list);
list.addLast("D");
System.out.println(list);
//获取元素
System.out.println("获取第一个元素:" + list.getFirst());//C
System.out.println("获取最后一个元素:" + list.getLast());//D
//删除元素
list.removeFirst();
System.out.println("删除第一个元素后:" + list);//[B, A, D]
list.removeLast();
System.out.println("删除最后一个元素后:" + list);//[B, A]
}
}
运行结果
[B, A]
[C, B, A]
[C, B, A, D]
获取第一个元素:C
获取最后一个元素:D
删除第一个元素后:[B, A, D]
删除最后一个元素后:[B, A]
三、泛型
3.1、什么是泛型
其实就是一种类型参数,主要用于某个类或接口中数据类型不确定时,可以使用一个标识符来表示未知的数据类型,然后在使用该类或接口时指定该未知类型的真实类型。
泛型可用到的接口、类、方法中,将数据类型作为参数传递,其实更像是一个数据类型模板。
如果不使用泛型,从容器中获取出元素,需要做类型强转,也不能限制容器只能存储相同类型的元素。
List list = new ArrayList();
list.add("A");
list.add("B");
String ele = (String) list.get(0);
3.2、自定义和使用泛型
定义泛型:使用一个标识符,比如T在类中表示一种未知的数据类型。
使用泛型:一般在创建对象时,给未知的类型设置一个具体的类型,当没有指定泛型时,默认类型为Object类型。
需求:定义一个类Point,x和y表示横纵坐标,分别使用String、Integer、Double表示坐标类型。
如果没有泛型需要设计三个类,如下:

定义泛型:
在类上声明使用符号T,表示未知的类型
//在类上声明使用符号T,表示未知的类型
public class Point<T> {
private T x;
private T y;
//省略getter/setter
}
使用泛型:
//没有使用泛型,默认类型是Object
Point p1 = new Point();
Object x1 = p1.getX();
//使用String作为泛型类型
Point<String> p2 = new Point<String>();
String x2 = p2.getX();
//使用Integer作为泛型类型
Point<Integer> p3 = new Point<Integer>();
Integer x3 = p3.getX();
注意:这里仅仅是演示泛型类是怎么回事,并不是要求定义类都要使用泛型。
3.3、在集合中使用泛型
拿List接口和ArrayList类举例。
class ArrayList<E>{
public boolean add(E e){
}
public E get(int index){
}
}
此时的E也仅仅是一个占位符,表示元素(Element)的类型,那么当使用容器时给出泛型就表示该容器只能存储某种类型的数据。
//只能存储String类型的集合
List<String> list1 = new ArrayList<String>();
list1.add("A");
list1.add("B");
//只能存储Integer类型的集合
List<Integer> list2 = new ArrayList<Integer>();
list2.add(11);
list2.add(22);
因为前后两个泛型类型相同(也必须相同),泛型类型推断:
List<String> list1 = new ArrayList<String>();
// 可以简写为
List<String> list1 = new ArrayList<>();
通过反编译工具,会发现泛型其实是语法糖,也就是说编译之后,泛型就不存在了。
注意:泛型必须是引用类型,不能是基本数据类型(错误如下):
List<int> list = new ArrayList<int>();//编译错误
泛型不存在继承的关系(错误如下):
List<Object> list = new ArrayList<String>(); //错误的
四、集合遍历
4.1、集合元素遍历
对集合中的每一个元素获取出来。
List<String> list = new ArrayList<>();
list.add("西施");
list.add("王昭君");
list.add("貂蝉");
list.add("杨玉环");
使用for遍历
for (int index = 0; index < list.size(); index++) {
String ele = list.get(index);
System.out.println(ele);
}
使用迭代器遍历
Iterator表示迭代器对象,迭代器中拥有一个指针,默认指向第一个元素之前,
-
boolean hasNext():判断指针后是否存在下一个元素
-
Object next():获取指针位置下一个元素,获取后指针向后移动一位
Iterator<String> it = list.iterator();
while(it.hasNext()) {
String ele = it.next();
System.out.println(ele);
}
在这里插入图片描述
注意: 此时,就不能使用两次迭代器,因为第一个迭代器就已经将指针指向了最后一个元素,这样的话第二个迭代器开始的指针一直都是最后一个
使用for-each遍历(推荐使用)
for (String ele : list) {
System.out.println(ele);
}
通过反编译工具会发现,for-each操作集合时,其实底层依然是Iterator,我们直接使用for-each即可。
4.2、并发修改异常
需求:在迭代集合时删除集合元素,比如删除王昭君。
List<String> list = new ArrayList<>();
list.add("西施");
list.add("王昭君");
list.add("貂蝉");
list.add("杨玉环");
System.out.println(list);
for (String ele : list) {
if("王昭君".equals(ele)) {
list.remove(ele);
}
}
System.out.println(list);
此时报错java.util.ConcurrentModificationException,并发修改异常。
造成该错误的原因是,不允许在迭代过程中改变集合的长度(不能删除和增加)。如果要在迭代过程中删除元素,就不能使用集合的remove方法,只能使用迭代器的remove方法,此时只能使用迭代器来操作,不能使用foreach。
List<String> list = new ArrayList<>();
list.add("西施");
list.add("王昭君");
list.add("貂蝉");
list.add("杨玉环");
System.out.println(list);
//获取迭代器对象
Iterator<String> it = list.iterator();
while(it.hasNext()) {
String ele = it.next();
if("王昭君".equals(ele)) {
it.remove();
}
}
System.out.println(list);
五、Set接口
Set是Collection子接口,Set接口定义了一种规范,也就是该容器不记录元素的添加顺序,也不允许元素重复,那么Set接口的实现类都遵循这一种规范。
Set集合存储特点:
-
不允许元素重复
-
不会记录元素的添加先后顺序
Set只包含从Collection继承的方法,不过Set无法记住添加的顺序,不允许包含重复的元素。当试图添加两个相同元素进Set集合,添加操作失败,add()方法返回false。
加粗样式Set接口定义了一种规范,也就是该容器不记录元素的添加顺序,也不允许元素重复。
Set接口常用的实现类有:
-
HashSet类:底层采用哈希表实现,开发中使用对多的实现类,重点。
-
TreeSet类:底层采用红黑树实现,可以对集合中元素排序,使用不多。
HashSet和TreeSet的API都是一样的:
5.1、HashSet类
HashSet 是Set接口的实现类,底层数据结构是哈希表,集合容器不记录元素的添加顺序,也不允许元素重复。通常我们也说HashSet中的元素是无序的、唯一的。
public class HashSetDemo {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
//添加操作:向列表中添加4个元素
set.add("Will");
set.add("wolf");
set.add("code");
set.add("Lucy");
//查询操作:
System.out.println("集合中所有元素:" + set);//[code, wolf, Will, Lucy]
System.out.println("元素数量:" + set.size());//4
System.out.println("是否存在某个元素:" + set.contains("code"));//true
System.out.println("是否存在某个元素:" + set.contains("code2"));//false
//删除操作:删除code元素
set.remove("code");
System.out.println("删除后:" + set);//[wolf, Will, Lucy]
//使用for-each遍历
for (String ele : set) {
System.out.println(ele);
}
//使用迭代器遍历
Iterator<String> it = set.iterator();
while (it.hasNext()) {
Object ele = it.next();
System.out.println(ele);
}
}
}
哈希表工作原理:

HashSet底层采用哈希表实现,元素对象的hashCode值决定了在哈希表中的存储位置。
向HashSet添加元素时,经过以下过程:
step 1 : 首先计算要添加元素e的hashCode值,根据 y = k( hashCode ) 计算出元素在哈希表的存储位置,一般计算位置的函数会选择 y = hashcode % 9, 这个函数称为散列函数,可见,散列的位置和添加的位置不一致。
step 2:根据散列出来的位置查看哈希表该位置是否有无元素,如果没有元素,直接添加该元素即可。如果有元素,查看e元素和此位置所有元素的是否相等,如果相等,则不添加,如果不相同,在该位置连接e元素即可。
在哈希表中元素对象的hashCode和equals方法的很重要。
每一个存储到哈希表中的对象,都得覆盖hashCode和equals方法用来判断是否是同一个对象,一般的,根据对象的字段数据比较来判断,通常情况下equals为true的时候hashCode也应该相等。
5.2、TreeSet类
TreeSet类底层才有红黑树算法,会对存储的元素对象默认使用自然排序(从小到大)。
注意:必须保证TreeSet集合中的元素对象是相同的数据类型,否则报错。
public class TreeSetDemo{
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("wolf");
set.add("will");
set.add("sfef");
set.add("allen");
System.out.println(set);// [allen, sfef, will, wolf]
}
}
六、Map接口
6.1、认识Map
Map,翻译为映射,在数学中的解释为:
设A、B是两个非空集合,如果存在一个法则f,使得A中的每个元素a,按法则f,在B中有唯一确定的元素b与之对应,则称f为从A到B的映射,记作f:A→B。
也就是说映射表示两个集合之间各自元素的一种“对应”的关系,在面向对象中我们使用Map来封装和表示这种关系。
从定义和结构图上,可以看出Map并不是集合,而表示两个集合之间的一种关系,故Map没有实现Collection接口。
在Map中,要求A集合中的每一个元素都可以在B集合中找到唯一的一个值与之对应。这句话可以解读为一个A集合元素只能对应一个B集合元素,也就说A集合中的元素是不允许重复的,B集合中的元素可以重复,也可不重复。那么不难推断出A集合应该是一个Set集合,B集合应该是List集合。
我们把A集合中的元素称之为key,把B集合中的元素称之为value。
其实能看出一个Map其实就有多个key-value(键值对)组成的,每一个键值对我们使用Entry表示。
不难发现,一个Map结构也可以理解为是Entry的集合,即Set。
一般的,我们依然习惯把Map称之为集合,不过要区分下,Set和List是单元素集合,Map是双元素集合。
单元素集合:每次只能存储一个元素,比如Set和List。
双元素集合:每次需要存储两个元素(一个key和一个value),比如Map。
注意:
Map接口并没有继承于Collection接口也没有继承于Iterable接口,所以不能直接对Map使用for-each操作。
如果不能理解Map的结构,就直接记住Map每次需要存储两个值,一个是key,一个是value,其中value表示存储的数据,而key就是这一个value的名字。
6.2、Map常用的API
添加操作
boolean put(Object key,Object value):存储一个键值对到Map中
boolean putAll(Map m):把m中的所有键值对添加到当前Map中
删除操作
Object remove(Object key):从Map中删除指定key的键值对,并返回被删除key对应的value
修改操作
无专门的方法,可以调用put方法,存储相同key,不同value的键值对,可以覆盖原来的。
查询操作
int size():返回当前Map中键值对个数
boolean isEmpty():判断当前Map中键值对个数是否为0.
Object get(Object key):返回Map中指定key对应的value值,如果不存在该key,返回null
boolean containsKey(Object key):判断Map中是否包含指定key
boolean containsValue(Object value):判断Map中是否包含指定value
Set keySet():返回Map中所有key所组成的Set集合
Collection values():返回Map中所有value所组成的Collection集合
Set entrySet():返回Map中所有键值对所组成的Set集合
6.3、HashSet
HashMap底层基于哈希表算法,Map中存储的key对象的hashCode值决定了在哈希表中的存储位置,因为Map中的key是Set,所以不能保证添加的先后顺序,也不允许重复。
HashMap key的底层数据结构是哈希表
案例: 统计一个字符串中每个字符出现次数
public class HashMapDemo2{
public static void main(String[] args) {
String str = "ABCDEFABCDEABCDABCABA";
//把字符串转换为char数组
char[] charArray = str.toCharArray();
//Map的key存储字符,value存储出现的次数
Map<Character, Integer> map = new HashMap<>();
//迭代每一个字符
for (char ch : charArray) {
//判断Map中是否已经存储该字符
if (map.containsKey(ch)) {
Integer count = map.get(ch);
//如果已经存储该字符,则把出现次数加上1
map.put(ch, count+1);
}else {
//如果没有存储该字符,则把设置次数为1
map.put(ch, 1);
}
}
System.out.println(map);
}
}
6.4、TreeMap
TreeMap key底层基于红黑树算法,因为Map中的key是Set,所以不能保证添加的先后顺序,也不允许重复,但是Map中存储的key会默认使用自然排序(从小到大),和TreeSet一样,除了可以使用自然排序也可以自定义排序。
需求:测试HashMap和TreeMap中key的顺序
public class App {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("girl4", "杨玉环");
map.put("girl2", "王昭君");
map.put("key1", "西施");
map.put("key3", "貂蝉");
System.out.println(map);
//-------------------------------------------
map = new TreeMap<>(map);
System.out.println(map);
}
}
输出结果:
{key1=西施, girl4=杨玉环, key3=貂蝉, girl2=王昭君}
{girl2=王昭君, girl4=杨玉环, key1=西施, key3=貂蝉}