【Python从入门到进阶】42、使用requests的Cookie登录古诗文网站
接上篇《41、有关requests代理的使用》
上一篇我们介绍了requests代理的基本使用,本篇我们来学习如何利用requests的Cookie登录古诗文网。
一、登录网站及目的介绍
我们需要Cookie模拟登录的网站为:https://www.gushiwen.cn/(古诗文网)
这是一个专门分享和品鉴古诗文、名句、作者和古籍的网站。
点击“我的”菜单,可以进入登录页面: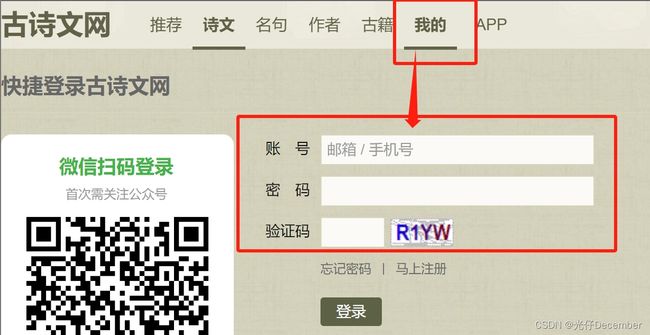
可以看到,是需要输入账号以及密码还有验证码进行登录。
登录成功之后,会跳转到真正的“我的”后台页面: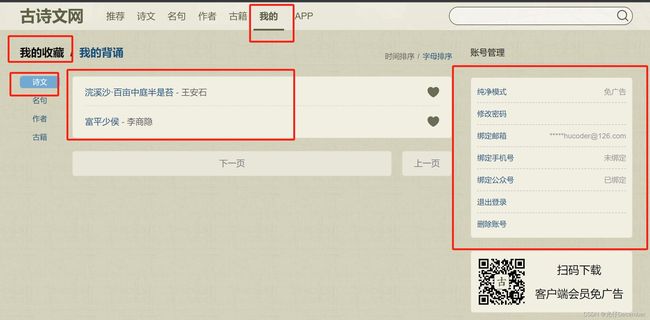
我们本次要实现的目的就是:使用Python脚本实现自动登录,进入到主页面。
二、登录接口分析
1、登录接口API查看
我们先进入登录页面,故意输入一个错误的账号密码,触发错误提示(如果输入正确的账号密码,登录成功后会跳转新的页面,这样我们就无法拿到接口信息了),此时我们F12打开浏览器开发者选项,在network里面找到包含“login”字样的网络请求:
可以看到,接口的大致信息是这样的:
请求URL:
https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx
请求方法:POST
请求参数:
__VIEWSTATE: LE5vdTvJMVsOaxkvBCE16Ls8zz7btwPW6mhhhDq+UtmXrcMxidC6Wa1xm0GFX/1CX4OmxMeVz+hd5lWiq8oPkkAd1bVtoGsgiS/BHXqghOntsFCYfkdmSJwzteX/Itiv81PAIcgZrQTgMH3jRer1MF/1krk=
__VIEWSTATEGENERATOR: C93BE1AE
from: http://so.gushiwen.cn/user/collect.aspx
email: [email protected]
pwd: 23423423423
code: XQ97
denglu: 登录
通过观察到的参数,可以看到__VIEWSTATE、__VIEWSTATEGENERATOR和code是变量,其他的都是不变量。所以我们实现最终目标需要搞定三个难点,即:
(1)分析出“__VIEWSTATE”参数是什么,在哪里获取。
(2)分析出“__VIEWSTATEGENERATOR”参数是什么,在哪里获取。
(3)解析验证码图片,获取相应字符设置在code参数上。
我们下面一个个的解决。
2、__VIEWSTATE等动态参数获取
一般我们看不到的数据,大概率都是隐藏在页面的源代码中。我们查看网页源码,可以看到这两个参数在当前页面中都有,而且是隐藏的(type="hidden"):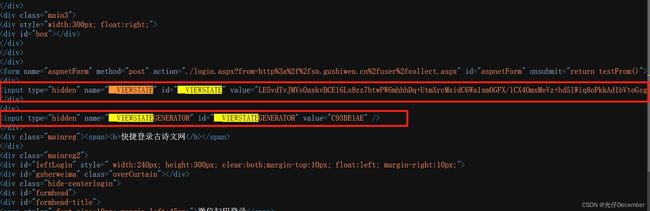
那么获取这两个值就比较简单了,我们只要一开始访问到登录页面,然后通过登录页面的源代码拿到这两个值去访问登录接口即可。
这里我们需要访问的登录页面地址为:https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx我们来编写一些获取__VIEWSTATE和__VIEWSTATEGENERATOR的代码:
import requests
# 古诗文网登录页面的URL地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
# 获取网络源代码
response = requests.get(url=url, headers=headers)
content = response.text
# 使用BeautifulSoup来解析网页源码,获取__VIEWSTATE和__VIEWSTATEGENERATOR参数
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, 'lxml')
# 获取__VIEWSTATE
VIEWSTATE = soup.select('#__VIEWSTATE')[0].attrs.get('value')
print('VIEWSTATE: ', VIEWSTATE)
# 获取__VIEWSTATEGENERATOR
VIEWSTATEGENERATOR = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
print('VIEWSTATEGENERATOR: ', VIEWSTATEGENERATOR)效果: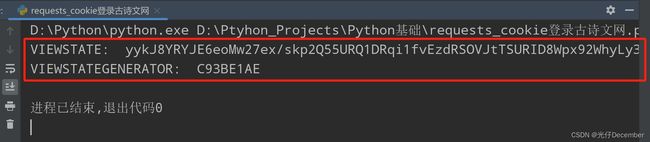
可以看到我们成功获取到了想要的这两个参数的值,可以在下一步调用登录接口的时候设置这两个参数。
3、验证码获取
我们还是进入登录页面,邮件检查验证码图片,可以看到获取验证码的地址: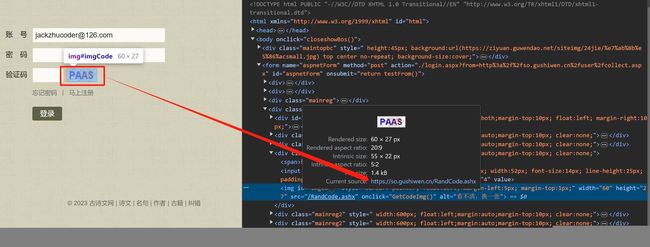
通过src可以看到验证码地址为https://so.gushiwen.cn/RandCode.ashx。
而我们获取到这个验证码的src的地方,是id为imgCode的img元素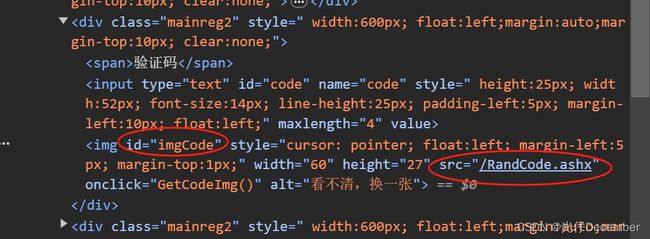
我们仍可以通过bs4获取到该src,并将其下载下来存储至本地:
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
import urllib.request
urllib.request.urlretrieve(url=code_url,filename='code.jpg')
# 获取验证码图片后,下载到本地,观察本地验证码,在控制台输入code
code_name = input('请输入登录验证码:')效果: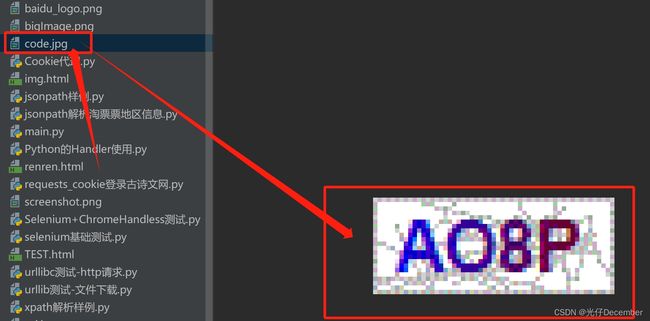
这里要注意,我们如果直接通过上面的方式获取,实际上拿到的是一个全新的验证码图片,而不是我们在登录页面上首次获取的那个,原因是因为我们没有带着之前的Cookie记录去访问这个图片路径,后台会把我们当成一个全新的请求给我们返回数据,所以我们这里一定要带着会话细腻系去访问,才能拿到原始页面的图片验证码。具体做法就是,通过requests的session()方法,获取一个带有之前页面Cookie值的请求对象,利用这个请求对象再去获取图片验证码,拿到的就是原始页面的验证码了:
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
#import urllib.request
#urllib.request.urlretrieve(url=code_url,filename='code.jpg')
session = requests.session()
# 验证码url的内容
response_code = session.get(code_url)
# 图片下载要使用二进制数据
content_code = response_code.content
# wb模式就是将二进制数据写入文件
with open('code.jpg','wb') as fp:
fp.write(content_code)
# 获取验证码图片后,下载到本地,观察本地验证码,在控制台输入code
code_name = input('请输入登录验证码:')此时我们可以在本地看到该验证码,可以进行手工输入(自动识别我们在下一章讲解)。此时我们就可以带着所有参数去执行登录了。
三、进行登录操作
根据上面我们两个步骤的操作,最终获取到登录需要的所有参数,我们来完成最后的登录代码:
# _*_ coding : utf-8 _*_
# @Time : 2023-11-19 15:59
# @Author : 光仔December
# @File : requests_cookie登录古诗文网
# @Project : Python基础
import requests
# 古诗文网登录页面的URL地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
# 获取网络源代码
response = requests.get(url=url, headers=headers)
content = response.text
# 使用BeautifulSoup来解析网页源码,获取__VIEWSTATE和__VIEWSTATEGENERATOR参数
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, 'lxml')
# 获取__VIEWSTATE
VIEWSTATE = soup.select('#__VIEWSTATE')[0].attrs.get('value')
print('VIEWSTATE: ', VIEWSTATE)
# 获取__VIEWSTATEGENERATOR
VIEWSTATEGENERATOR = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
print('VIEWSTATEGENERATOR: ', VIEWSTATEGENERATOR)
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
#import urllib.request
#urllib.request.urlretrieve(url=code_url,filename='code.jpg')
session = requests.session()
# 验证码url的内容
response_code = session.get(code_url)
# 图片下载要使用二进制数据
content_code = response_code.content
# wb模式就是将二进制数据写入文件
with open('code.jpg','wb') as fp:
fp.write(content_code)
# 获取验证码图片后,下载到本地,观察本地验证码,在控制台输入code
code_name = input('请输入登录验证码:')
# 点击登录
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {
'__VIEWSTATE': VIEWSTATE,
'__VIEWSTATEGENERATOR': VIEWSTATEGENERATOR,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '[email protected]',
'pwd': '123456',
'code': code_name,
'denglu': '登录'
}
# 获取网络源代码(这里能用requests对象,要用验证码的session对象,保持一个Cookie环境)
response_post = session.post(url=url_post, headers=headers, data=data_post)
content_post = response_post.text
print(content_post)这里我们要注意,为了校验验证码成功,登录接口要带着图片验证码的Cookie一起过去,在编码上的体现形式就是使用session对象做post请求。
效果:
可以看到我们成功登录,并进入了后台,看到我们收藏的诗文信息。
至此,我们使用requests的Cookie登录古诗文网站的全部内容讲解完毕。下一篇我们讲解如何使用第三方库来自动识别登录验证码。
参考:尚硅谷Python爬虫教程小白零基础速通
转载请注明出处:https://guangzai.blog.csdn.net/article/details/134492436