python 课后习题汇总(实验8)
1.附件data.csv是一个CSV文件,其中每个数据前后存在空格,请对其进行清洗,要求如下:
①去掉每个数据前后空格,即数据之间仅用逗号(,)分割;
②清洗后打印输出。
该CSV文件的每个数据中不包含空格,因此,可以通过替换空格方式来清洗。如果数据中包含空格,该方法则不适用。
![]()

1, 2, 3, 4, 5
'a', 'b' , 'c' , 'd','e'fo = open("8_1_data.csv")
for line in fo:
line = line.replace(" ", "")
print(line, end="")
注:CSV 是逗号分隔值的意思。CSV 文件是一个存储表格和电子表格信息的纯文本文件,其内容通常是一个文本、数字或日期的表格
2.将整数12345分别写入文本文件test.txt和二进制文件testdat,并比较两个文件的不同之处
data=[1,2,3,4,5]
f=open('1.txt','w')
for i in data:
f.write(str(i)+'\n')
f.close()
3.当前目录下有一个xlsx工作簿,第1列为学生姓名,第2列到第4列分别是学生的课程1、课程2和课程3成绩,如附图8-1所示。编写程序计算每名学生的总分,并输出排名前三的学生姓名。
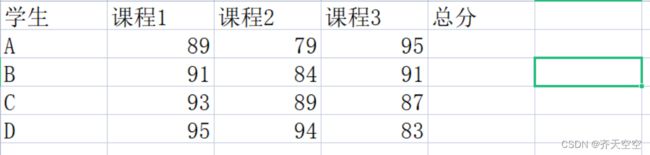
import pandas as pd
df=pd.read_excel(r'成绩.xlsx')
df['总分']=df['课程1']+df['课程2']+df['课程3']
df=df.sort_values(by='总分',ascending=False)
df=df.iloc[0:3]
print(df) 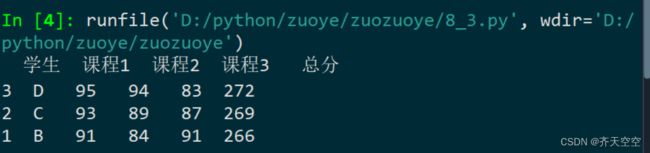
4.当前目录下有一篇英文小说,统计小说中每个单词出现的频次,输出频次最高的10个单词
小说:
In Northwestern China, there is a chain of undulating hills called Colorful Zhangye Danxia. Here you can find the colors of the rainbow.
The terrain is so hostile that even grass struggles to survive. So where did this palette of colors come from?
It's hard to imagine, but this area was once a lake. The multi-colored hills are the result of the long geological evolution of the lakebed.
Changes in temperature and humidity, as well as the existence of various mineral elements, and the different iron content in lake sediments especially, gave rise to the spectrum of colors.
Part of the ancient Silk Road it is said that Marco Polo once visited here over 700 years ago.
However, compared to Marco Polo, today we can have much more fun. 代码:
file = open("8_4_English-novel.txt")
word_appear_time = {}
for line in file:
words = line.strip().split()
for word in words:
if word in word_appear_time:
word_appear_time[word] += 1
else:
word_appear_time[word] = 1
word_list = []
for word, times in word_appear_time.items():
word_list.append((times, word))
word_list.sort(reverse = True)
for times, word in word_list[:10]:
print(word)
file.close()