《西瓜书》-9.聚类
9.聚类
9.1.聚类任务
聚类是一种经典的无监督学习方法,无监督学习的目标是通过对无标记训练样本的学习,发掘和揭示数据集本身潜在的结构与规律,即不依赖于训练数据集的类标记信息。聚类则是试图将数据集的样本划分为若干个互不相交的类簇,从而每个簇对应一个潜在的类别。
聚类直观上来说是将相似的样本聚在一起,从而形成一个类簇(cluster)。那首先的问题是如何来度量相似性(similarity measure)呢?这便是距离度量,在生活中我们说差别小则相似,对应到多维样本,每个样本可以对应于高维空间中的一个数据点,若它们的距离相近,我们便可以称它们相似。那接着如何来评价聚类结果的好坏呢?这便是性能度量,性能度量为评价聚类结果的好坏提供了一系列有效性指标。
9.2.性能度量
聚类性能:评估聚类好坏的指标。
直观的理解:簇内相似度高,簇间相似度低。
一般聚类有两类性能度量指标:外部指标和内部指标。
*外部指标:与某个参考模型比较,如该领域专家给出的划分结果。
*内部指标:不利用外部指标而直接考察聚类结果
外部指标

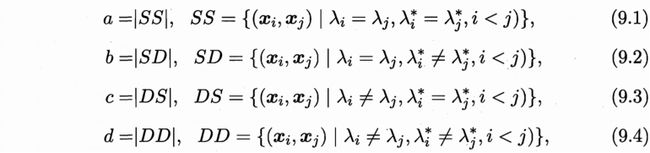
a:在C中同簇,C*中也同簇
b:在C中同簇,C*中不同簇
c:在C中不同簇,C*中同簇
d:在C中不同簇,C*中也不同簇




对于式(9.5)
给定两个集合![]() 和
和![]() ,则Jaccard系数定义为如下公式
,则Jaccard系数定义为如下公式

现在假设集合![]() 中存放着两个样本都同属于聚类结果同一个类的样本对,即
中存放着两个样本都同属于聚类结果同一个类的样本对,即![]() ,集合
,集合![]() 中存放着两个样本都同属于参考模型同一个类的样本对,即
中存放着两个样本都同属于参考模型同一个类的样本对,即![]() ,那么根据Jaccard系数的定义有:
,那么根据Jaccard系数的定义有:

对于式(9.6)
其中![]() 和
和![]() 为两个非对称指标,
为两个非对称指标,![]() 代表两个样本在聚类结果和参考模型中均属于同一类的样本对的个数,
代表两个样本在聚类结果和参考模型中均属于同一类的样本对的个数,![]() 代表两个样本在聚类结果中属于同一类的样本对的个数,
代表两个样本在聚类结果中属于同一类的样本对的个数,![]() 代表两个样本在参考模型中属于同一类的样本对的个数
代表两个样本在参考模型中属于同一类的样本对的个数
这两个非对称指标均可理解为样本对中的两个样本在聚类结果和参考模型中均属于同一类的概率。由于指标的非对称性,这两个概率值往往不一样,这里利用几何平均数将这两个非对称指标转化为一个对称指标,即FMI。
对于式(9.7)
Rand Index定义如下

可以简单理解为聚类结果与参考模型的一致性。
内部指标
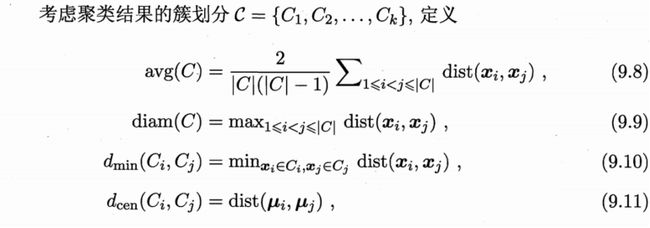



对于式(9.12)
分子表示任意两个簇的簇内平均距离的和,越小越好;分母表示这两个簇的中心点的距离,越大越好,所以整体这个式子越小越好。
对于式(9.13)
分子表示任意两个簇的最近样本间的距离,越大越好;分母表示这两个簇的簇内样本间的最远距离,越小越好,所以整体这个式子越大越好。
9.3.距离计算
谈及距离度量,最熟悉的莫过于欧式距离了,即对应属性之间相减的平方和再开根号。度量距离还有其它的很多经典方法,通常它们需要满足一些基本性质:

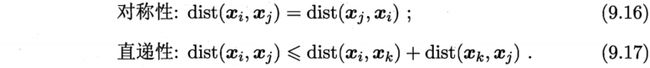

式(9.18)即为![]() 的
的![]() 范数
范数![]()


当![]() 时,则得到切比雪夫距离。
时,则得到切比雪夫距离。
若我们定义的距离计算方法用来度量相似性,例如下面将要讨论的聚类问题,即距离越小,相似性越大,反之距离越大,相似性越小。这时距离的度量方法并不一定需要满足前面所说的四个基本性质,这样的方法称为:非度量距离(non-metric distance)。
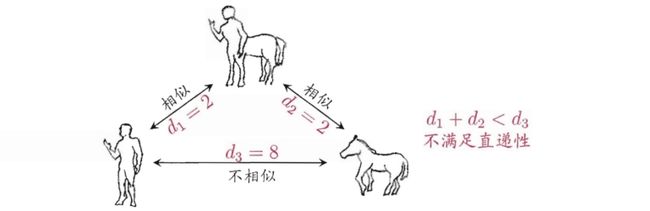
例如有这样的相似度度量:“人”“马”分别与“人马”相似,但“人”与“马”很不相似;要达到这个目的,可以令“人”“马”与“人马”之间的距离都比较小,但“人”与“马”之间的距离很大,如图所示,此时该距离不再满足直递性。
9.4.k-means聚类
原型聚类即“基于原型的聚类”(prototype-based clustering),原型表示模板的意思,也就是样本空间具有代表性的点,通过参考一个模板向量或模板分布的方式来完成聚类的过程。
k均值(k-means)算法的思想十分简单,首先随机指定类中心,根据样本与类中心的远近划分类簇,接着重新计算类中心,迭代直至收敛。

最小化式(9.24)并不容易,找到它的最优解需考察样本集D所有可能的簇划分,这是一个NP难问题。因此,k均值算法采用了贪心策略,通过迭代优化来近似求解式(9.24)
下面以西瓜数据集4.0为例来演示k均值算法的学习过程.为方便叙述,我们将编号为 的样本称为
的样本称为![]() ,这是一个包含“密度”与“含糖率”两个属性值的二维向量。
,这是一个包含“密度”与“含糖率”两个属性值的二维向量。



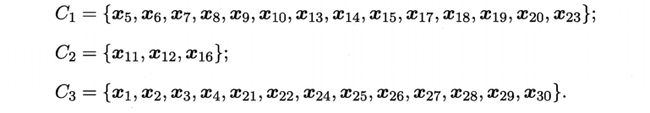

更新当前均值向量后,不断重复上述过程,如下图所示,第五轮迭代产生的结果与第四轮迭代相同,于是算法停止,得到最终的簇划分.
9.5.学习向量量化(LVQ)
学习向量量化(LVQ)也是基于原型的聚类算法,与K-Means不同的是,LVQ使用样本真实类标记辅助聚类。
首先LVQ根据样本的类标记,从各类中分别随机选出一个样本作为该类簇的原型,从而组成了一个原型特征向量组,接着从样本集中随机挑选一个样本,计算其与原型向量组中每个向量的距离,并选取距离最小的原型向量所在的类簇作为它的划分结果,再与真实类标比较。
若划分结果正确,则对应原型向量向这个样本靠近一些,若划分结果不正确,则对应原型向量向这个样本远离一些。
9.6.高斯混合模型(GMM)
现在可以看出K-Means与LVQ都试图以类中心作为原型指导聚类,高斯混合聚类则采用高斯分布来描述原型。
高斯混合模型(GMM)是一个非常基础并且应用很广的模型。对于它的透彻理解非常重要。
现假设每个类簇中的样本都服从一个多维高斯分布,那么空间中的样本可以看作由k个多维高斯分布混合而成。
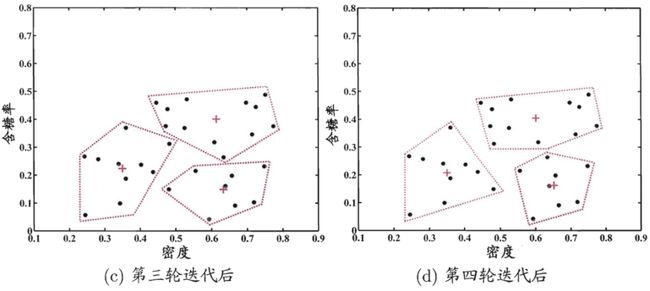
下图a表示所有样本数据,b表示利用高斯混合聚类后的样本分类。


假设样本的生成过程由高斯混合分布给出,那么生成过程分为两步:
首先,根据概率![]() 选择第个高斯混合成分;
选择第个高斯混合成分;
然后,根据该混合成分的概率分布![]() 生成样本。
生成样本。
若训练集 中的样本均由某个高斯混合模型生成,而每个样本
中的样本均由某个高斯混合模型生成,而每个样本![]() 是由哪个高斯混合成分生成是未知的,属于一个隐变量,令其为
是由哪个高斯混合成分生成是未知的,属于一个隐变量,令其为![]() 表示生成样本
表示生成样本![]() 的高斯混合成分。结合高斯混合模型生成数据的方式易知
的高斯混合成分。结合高斯混合模型生成数据的方式易知![]() 的分布律为
的分布律为![]() 。
。
对于高斯混合模型,下面用两种方式进行推导,分别为EM算法和极大似然估计法。
(1)利用EM算法进行推导。
E步:确定![]() 函数
函数
![]()
其中![]() 表示观测数据,之前学习EM算法时,这里是
表示观测数据,之前学习EM算法时,这里是![]() ,但是意思是一样的。
,但是意思是一样的。![]() 表示隐变量序列,
表示隐变量序列,![]() 为模型的参数
为模型的参数![]() ,
,![]() 表示迭代到第次的
表示迭代到第次的![]() 。
。
将上式展开得
![]()

由之前EM推导得

再将![]() 展开,即遍历
展开,即遍历![]() 的所有取值,则变为
的所有取值,则变为
 (1)
(1)
接下来,对式中的两项分别讨论
首先对于![]() ,先不考虑
,先不考虑![]() ,由贝叶斯公式得
,由贝叶斯公式得

其中分母![]() 表示生成
表示生成![]() 的概率,即式9.29高斯混合分布的表达式
的概率,即式9.29高斯混合分布的表达式
分子中![]() 表示选择第个混合成分来生成样本的概率,根据生成数据的方式得
表示选择第个混合成分来生成样本的概率,根据生成数据的方式得![]() ,
,![]() 表示已经选定第个混合成分,然后通过该成分生成样本
表示已经选定第个混合成分,然后通过该成分生成样本![]() 的概率,即式9.28。
的概率,即式9.28。
所以,上式可以变为
 (2)
(2)
上式即为西瓜书的式(9.30)。当考虑![]() 时,也即第次迭代后的参数,也即这些参数均为已知,上式变为
时,也即第次迭代后的参数,也即这些参数均为已知,上式变为

将其记为![]() ,因为上式的所有量均为已知,所以
,因为上式的所有量均为已知,所以![]() 也是已知量。
也是已知量。
接着对于![]() 函数的第二项
函数的第二项![]() ,可以写为
,可以写为
![]()
右边的两项在求解式(9.30)时均已介绍,所以
![]() (3)
(3)
这里的参数均未知,也即我们需要极大化的参数。
将式(2)与(3)代入(1)得







接下来,进行M步,极大化![]() 函数,即求使得
函数,即求使得![]() 函数极大化的
函数极大化的![]() ,令其为
,令其为![]() ,即求参数
,即求参数![]()
从上式可以看出,只有左边第一项包含![]() ,后面项包含
,后面项包含![]() 和
和![]() ,所以极大化
,所以极大化![]() 函数可以分别极大化左右两边的项。
函数可以分别极大化左右两边的项。
求![]() ,对
,对![]() 函数关于
函数关于![]() 求偏导,对于求和符号
求偏导,对于求和符号![]() ,由于求某个特定的
,由于求某个特定的![]() 时与其他的项无关,所以这个求和符号可以省略,即
时与其他的项无关,所以这个求和符号可以省略,即


去掉不含![]() 的项得
的项得

由于![]() 和
和![]() 均为标量(转置为本身),
均为标量(转置为本身),![]() 为对称矩阵,则
为对称矩阵,则
![]()
代入上式得


根据矩阵微分公式 ,
, 得
得


令上式等于0得

由于![]() 不受求和符号的约束,则可以将其提出
不受求和符号的约束,则可以将其提出

等式左右两边分别乘以![]() 得
得

计算得

![]()

上式即为西瓜书式(9.34)
求![]() ,对
,对![]() 函数关于
函数关于![]() 求偏导,同样可以省去求和符号,得
求偏导,同样可以省去求和符号,得


根据矩阵微分公式 ,
,  得
得

因为![]() 为对称矩阵,得
为对称矩阵,得

令其等于0得

等式两边都在右侧乘以![]() 得
得

将求和符号分配并移项得

同样![]() 不受求和符号的约束,则可以将其提出
不受求和符号的约束,则可以将其提出

所以 
即 
![]()

上式即为西瓜书式(9.35)
最后,求![]() ,由于
,由于![]() 存在约束
存在约束 ,所以使用拉格朗日乘子法,得拉格朗日函数为
,所以使用拉格朗日乘子法,得拉格朗日函数为

代入![]() 函数得
函数得

对拉格朗日函数关于![]() 求偏导,同样可以去掉的求和符号,得
求偏导,同样可以去掉的求和符号,得


令上式等于0得



由于,则对上式两边关于求和得



又因为

所以


这里,还需要满足![]() ,由于
,由于![]() ,所以
,所以

![]()

因此![]() 是有效解,可以作为下一次迭代的初始参数,即
是有效解,可以作为下一次迭代的初始参数,即
![]()

上式即为西瓜书式(9.38)
利用上述算法进行迭代,直至收敛(或达到迭代轮数),即为EM算法的过程。
由上述推导即可获得高斯混合模型的EM算法:在每步迭代中,先根据当前参数来计算每个样本属于每个高斯成分的后验概率![]() (E步),再根据式(9.34)、(9.35)和(9.38)更新模型参数
(E步),再根据式(9.34)、(9.35)和(9.38)更新模型参数![]() (M步),直至收敛(或达到迭代轮数)。
(M步),直至收敛(或达到迭代轮数)。
(2)利用极大似然法推导
首先,引入公式
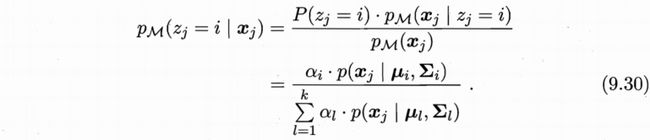
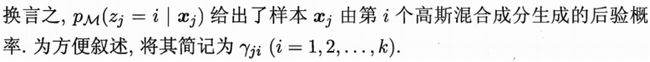


对于上式(9.33)进行推导:
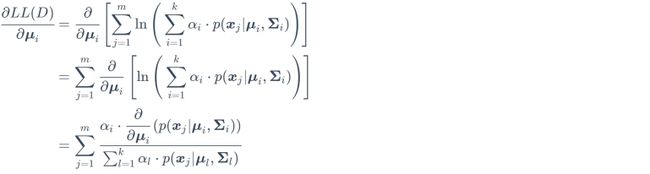
将式(9.28)代入得
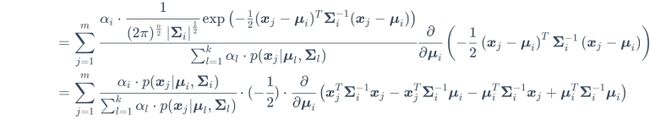

![]()
![]()
所以上式可化为
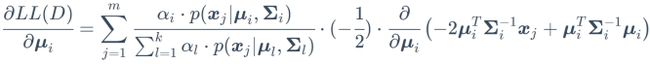
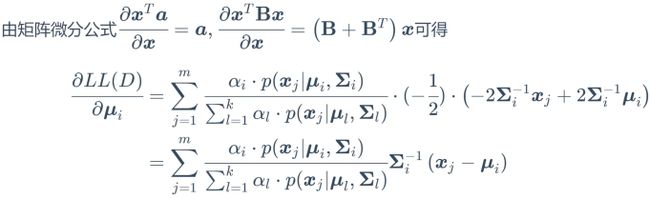
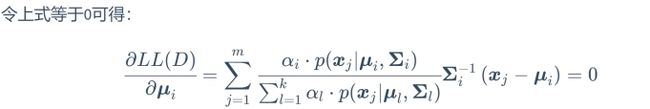
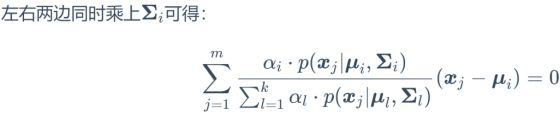
上式即为式(9.33)
![]()
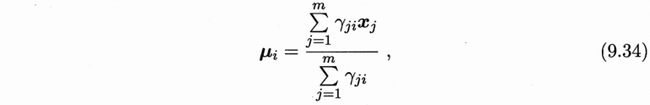

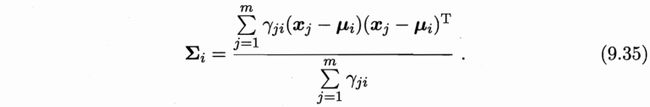
对于上式(9.35)进行推导:
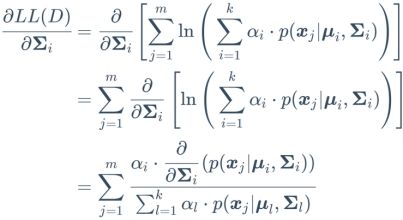
由式(9.28)可得
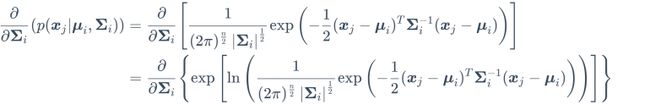

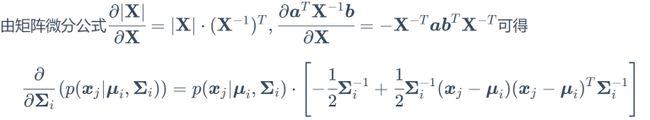

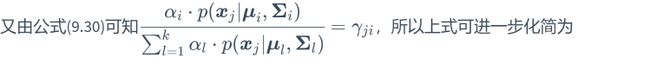
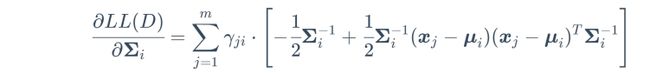
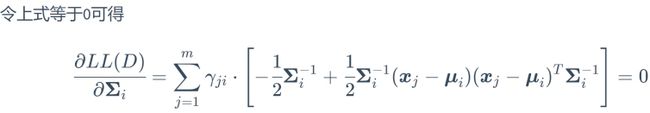
移项推导有:
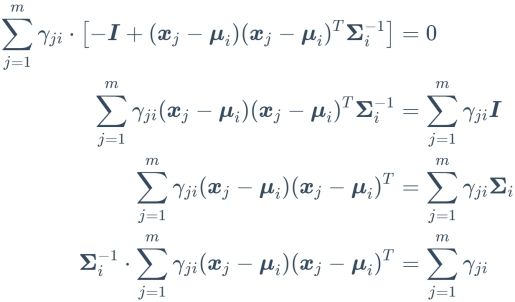
所以

上式即为式(9.35)
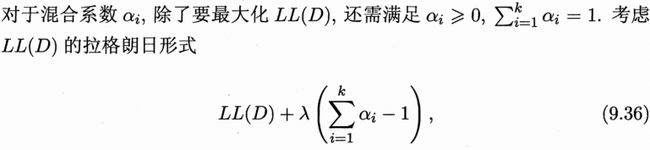
![]()
![]()

对于上式(9.38)进行推导:
对公式(9.37)两边同时乘以![]() 可得
可得
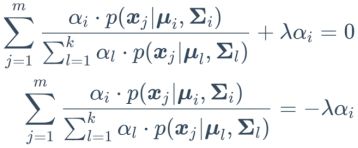
两边对所有混合成分求和可得
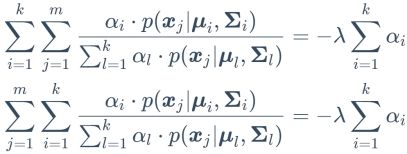
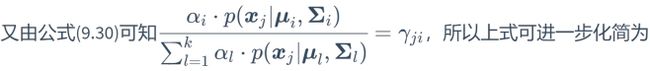

又因为

且得![]() ,所以
,所以
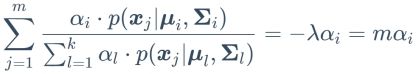
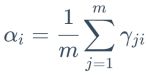
上面即为通过极大似然估计得出的结果。
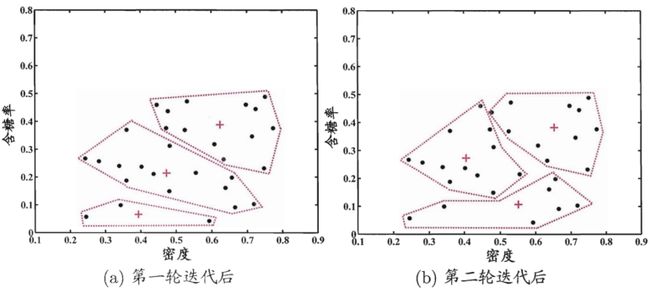
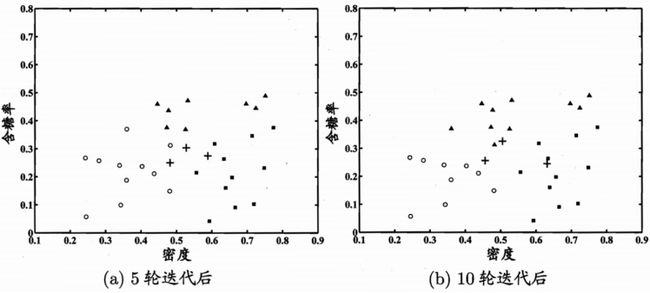
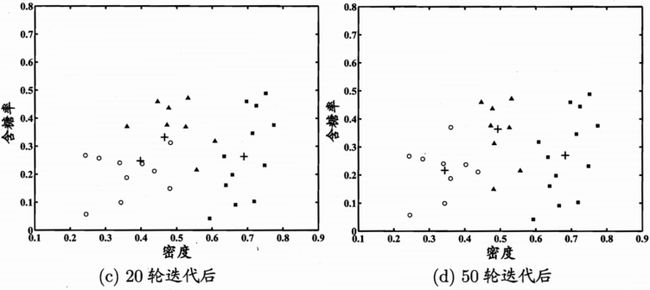
以西瓜数据集4.0为例,利用高斯混合聚类,经过不同轮数迭代后的结果如图所示

9.7.密度聚类
密度聚类则是基于密度的聚类,它从样本分布的角度来考察样本之间的可连接性,并基于可连接性(密度可达)不断拓展疆域(类簇)。其中最著名的便是DBSCAN算法。
简单来理解DBSCAN便是:找出一个核心对象所有密度可达的样本集合形成簇。即该簇内,任意两点为密度相连。且能密度可达的点都包含进来了。
首先从数据集中任选一个核心对象A,找出所有A密度可达的样本集合,将这些样本形成一个密度相连的类簇,然后从剩余数据中再找一个核心对象,直到所有的核心对象都遍历完。
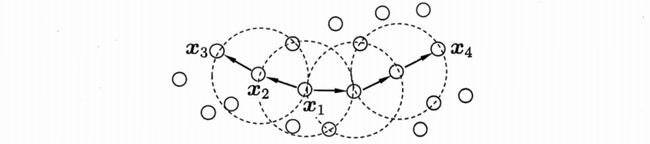
如上图,虚线表示邻域。令MinPts=3(核心对象邻域至少包含MinPts个样本),![]() 是核心对象,
是核心对象,![]() 由
由![]() 密度直达,
密度直达,![]() 由
由![]() 密度可达,
密度可达,![]() 与
与![]() 密度相连。
密度相连。
以西瓜数据集4.0为例的密度聚类过程如图所示
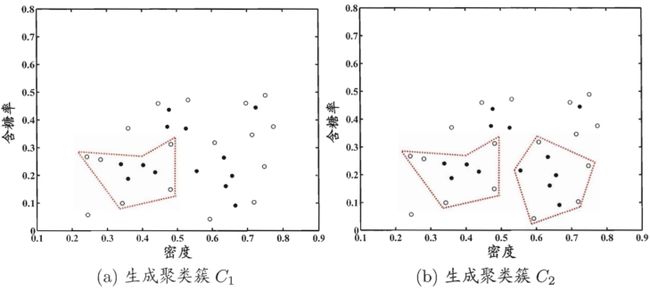
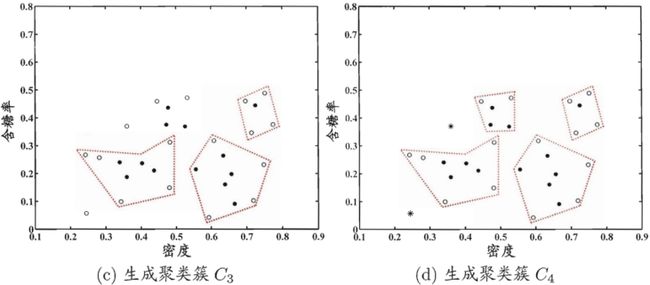
![]()
9.8.层次聚类
层次聚类是一种基于树形结构的聚类方法,常用的是自底向上的结合策略(AGNES算法)。
假设有N个待聚类的样本,其基本步骤是:
1.初始化:把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度;
2.寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个);
3.重新计算新生成的这个类与各个旧类之间的相似度;
4.重复2和3直到所有样本点都归为预设的聚类簇数,结束。
可以看出其中最关键的一步就是计算两个类簇的相似度,这里有多种度量方法:
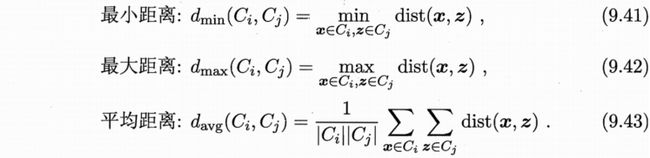
显然,最小距离由两个簇的最近样本决定,最大距离由两个簇的最远样本决定,而平均距离则为两个簇的所有样本的平均距离。
三种距离下,AGNES分别称为单链接,全链接,均链接算法。
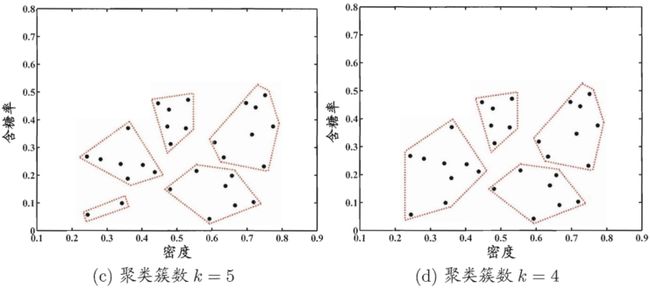
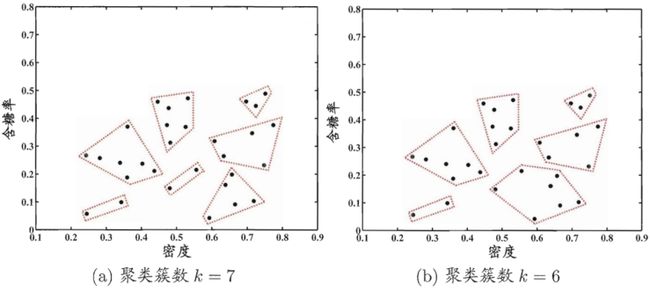
下面,以西瓜数据集4.0为例,令AGNES算法(采用![]() )一直执行到所有样本出现在同一个簇中,即k=1,则可得到如图所示的“树状图”。
)一直执行到所有样本出现在同一个簇中,即k=1,则可得到如图所示的“树状图”。
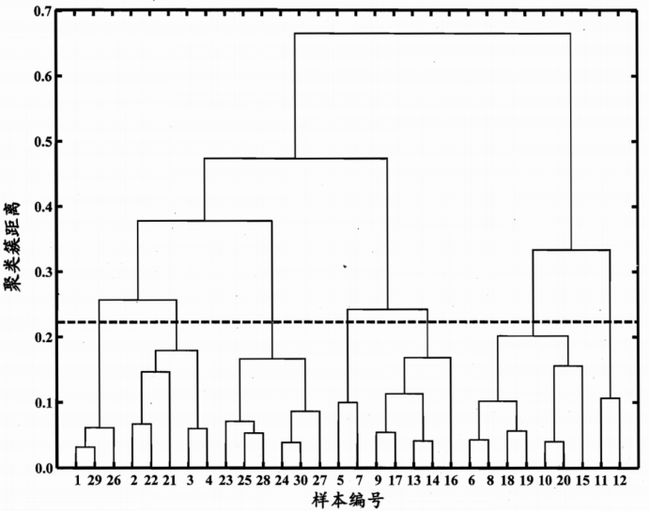
以图中所示虚线分割树状图,将得到包含7个聚类簇的结果。
将分割层逐步提升,则可得到聚类簇逐渐减少的聚类结果。例如下图为产生7至4个聚类簇的划分结果。