用 Python 爬取网页漫画
目录
- 1 相关资料搜集
-
- 参考博客
- 2 实现代码
-
- 2.1 提取单本漫画
- 2.2 把多张图片生成 PDF
- 3 提取单本漫画的过程
-
- 3.1 安装模块
- 3.2 获取网页源码
- 3.3 提取章节名和漫画
1 相关资料搜集
参考博客
(1)Python爬取腾讯动漫全站漫画详细教程(附带源码)
(2)用python爬取漫画,代入感太强了
如果上述链接失效,请查看备份资源:https://pan.quark.cn/s/5e09bf67b260
2 实现代码
2.1 提取单本漫画
以漫画网站 包子漫画 为例,提取漫画《一人之下》的代码如下:
import requests
from lxml import etree
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup
import os
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}
def getPics(url):
# 获取网页源码
browser = webdriver.Chrome()
browser.get(url)
data = browser.page_source
# print(data)
browser.close()
# 提取章节名
page_ming = etree.HTML(data)
page_name = page_ming.xpath('//span[@class="title"]/text()')
print(page_name[0])
# 以章节名命名一个文件夹
if not os.path.exists('D:/code/yiren/test1/' + page_name[0]):
os.makedirs('D:/code/yiren/test1/' + page_name[0])
#提取漫画主体部分
soup = BeautifulSoup(data)
body = soup.find('ul', attrs={'class': 'comic-contain'})
# print(body)
#设置变量i,方便为保存的图片命名
i = 0
#提取出主体部分中的img标签(因为图片地址保存在img标签中)
for items in body.find_all("amp-img"):
#提取图片地址信息
item = items.get("src")
print(item)
basic_path = 'D:/code/yiren/test1/' + page_name[0] + '/'
pic = requests.get(item, headers=headers)
with open(basic_path + str(i + 1) + '.jpg' ,mode = "wb") as f:
f.write(pic.content)
i += 1
url_0 = 'https://cn.czmanga.com/comic/chapter/yirenzhixiafanwaixiutie-dongmantang/0_'
for index in range(0, 45):
url = url_0 + str(index) + '.html'
getPics(url)
2.2 把多张图片生成 PDF
上一步中提取出的图片按章存放在 test1 文件夹中,此处假定 test1 的子文件夹名字为数字,子文件夹中的图片名字也是数字。将 test1 文件夹中所有图片生成一个 PDF 文件的代码如下:
import os
from PIL import Image
from reportlab.lib.pagesizes import portrait
from reportlab.pdfgen import canvas
# 指定图片文件夹路径和输出的 PDF 文件名
image_folder = 'test1'
output_pdf = 'output.pdf'
# 获取所有子文件夹并按数字命名的方式排序
subfolders = sorted([os.path.join(image_folder, f) for f in os.listdir(image_folder)], key=lambda x: int(os.path.basename(x)))
# 创建 PDF 文档
c = canvas.Canvas(output_pdf, pagesize=portrait)
# 遍历子文件夹
for subfolder in subfolders:
# 获取子文件夹中的图片文件列表
image_files = sorted([f for f in os.listdir(subfolder)], key=lambda x: int(os.path.splitext(x)[0]))
# 遍历图片文件并将它们添加到 PDF 中
for image_file in image_files:
# 打开当前的图片文件
with Image.open(os.path.join(subfolder, image_file)) as img:
# 获取图片的宽度和高度(以点为单位)
img_width, img_height = img.size
# 添加一页 PDF 页面,并设置页面尺寸与图片相同
c.setPageSize((img_width, img_height))
# 将图片绘制到当前页面上
c.drawImage(os.path.join(subfolder, image_file), 0, 0, width=img_width, height=img_height)
c.showPage()
# 保存 PDF 文件
c.save()
print(f'PDF 已创建:{output_pdf}')
3 提取单本漫画的过程
3.1 安装模块
先安装代码中需要的包,有点麻烦的是 webdriver,不同浏览器使用不同的webdriver,以 Chrome 浏览器为例(就是说电脑中安装的有 Chrome 浏览器),安装步骤如下:
(1)查看电脑中 Chrome 浏览器的版本
(2)下载对应版本的 ChromeDriver,大部分用的都是最新版的 Chrome,就要从这个链接(https://googlechromelabs.github.io/chrome-for-testing/#stable)中去下载,以版本为 116.0.5845.187 的浏览器为例,下载 win32 的 chromedriver(Windows 系统使用 win32 的没有问题,win64 不确定)
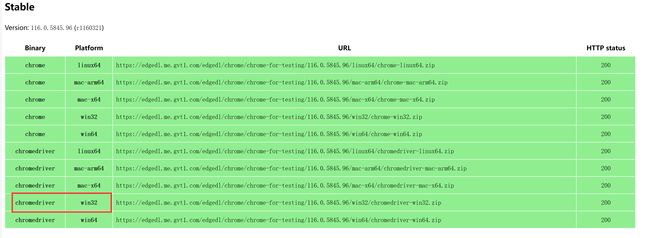
(3)解压之后,将 chromedriver.exe 放入 Python 的安装目录下(如果有安装 anaconda,就放入到 anaconda 的安装目录下,运行代码时使用 anaconda 自带的命令行)
3.2 获取网页源码
使用 webdriver 模拟对浏览器进行操作,获取网页源代码
获取网页源码的详细讲解参考:python爬虫之爬虫第一步:获取网页源代码
browser = webdriver.Chrome()
# 打开网页
browser.get(url)
# 获取网页源码
data = browser.page_source
print(data)
# 关闭网页
browser.close()
3.3 提取章节名和漫画
任意打开一个章节,查看代码特性
(1)章节名位于 class 为 title 的 span中,提取代码如下
page_ming = etree.HTML(data)
page_name = page_ming.xpath('//span[@class="title"]/text()')
print(page_name[0])
(2)漫画的主体部分在 class 为 comic-contain 的 ul 中,提取代码如下
soup = BeautifulSoup(data)
body = soup.find('ul', attrs={'class': 'comic-contain'})
print(body)
(3)图片的地址信息位于主体部分中 amp-img 标签的 src 中,提取代码如下
for items in body.find_all("amp-img"):
item = items.get("src")
print(item)

(4)保存图片到本地
设置 requests.get() 中的 headers 参数,用来模拟浏览器进行访问,代码如下
basic_path = 'D:/code/yiren/test1/' + page_name[0] + '/'
pic = requests.get(item, headers=headers)
with open(basic_path + str(i + 1) + '.jpg' ,mode = "wb") as f:
f.write(pic.content)
i += 1
headers 参数获取方法:以 Chrome 浏览器为例,在网址栏中输入 chrome://version/ ,页面中出现的 User Agent 即为我们需要的
![]()
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}