Python爬虫实例——保存热搜至指定txt文件(含注释)
一、程序目的
爬取实时热搜并保存至名称为“目标榜单 截止时间”的txt文件。
二、注意事项
1、cookies文中并未给出
2、目标网站代码可能随时间而变动
3、输出的颜色字体提供两种:coloema库和ANSI转义码,根据需求自行选择
三、第三方库安装
需在cmd中运行以下代码
pip install requests
pip install bs4
pip install colorama四、全局变量
# 存放微博数据
weibo = []
# 返回一个 datetime 对象,表示当前的日期和时间 strftime用于格式化日期和时间的方法
time = datetime.datetime.now()
# 格式化处理 用于内容时间
formatted_time = time.strftime("%Y-%m-%d %H:%M:%S")
# 格式化处理 用于文件名时间
formatted_time_1 = time.strftime("%Y-%m-%d %H-%M-%S")五、获取HTML
1、获取cookies
具体方法:游览器(谷歌/Edge) -> F12 -> 选择应用程序 -> cookie

2、代码实现
def GetHTMLText(url):
try:
cookies = {
#cookies自行填入
}
r = requests.get(url, timeout=30, cookies=cookies)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""四、处理文本
包括普通文本、置顶内容、广告、特殊榜单
def fillData(soup):
tr = soup.find_all('tr', class_="")
n = 1
for data in tr:
# 查找当前 tr 标签下的a、span标签
a = data.find('a')
span = data.find('span')
# 处理置顶内容
i_1 = data.find('i', class_="icon-top")
if i_1 is not None:
# print("TOP %s" % a.string)
# print("\033[32mTop %s \033[0m" % a.string)
print(Fore.GREEN + "TOP %s" % a.string)
# 保存置顶数据至列表weibo
temp = ["TOP ", a.string]
weibo.append(temp)
continue
# 广告处理
ad = data.find('td', class_="td-01 ranktop")
if ad is not None and ad.string == '•':
continue
if span is not None:
# print("%2d、%s %s" % (n, a.string, span.string))
# print("\033[33m%2d\\033[0m\033[36m%s\033[0m \033[37m%s\033[0m" % (n, a.string, span.string))
print(Fore.YELLOW + "%02d、" % n, end='')
print(Fore.CYAN + "%s " % a.string, end='')
print(Fore.RESET + "%s" % span.string)
# 保存榜单数据至列表weibo
temp = ["%02d" % n, '、', a.string, ' |', span.string]
weibo.append(temp)
else: # 特殊榜单处理
# print("%d、%s" % (n, a.string))
# print("\033[33m%2d、\033[0m\033[36m%s\033[0m" % (n, a.string))
print(Fore.YELLOW + "%2d、" % n, end='')
print(Fore.CYAN + "%s" % a.string, )
# 保存数据至列表weibo
temp = ["%02d" % n, '、', a.string]
weibo.append(temp)
n = n + 1五、发起HTTP请求获取页面内容
def main():
url = web_choice()
html = GetHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
fillData(soup)六、处理所选榜单选择
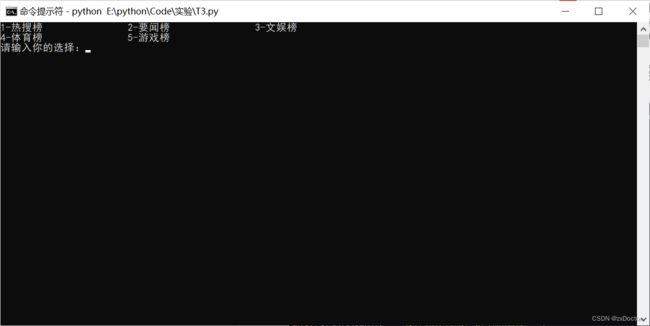
def web_choice():
os.system('cls') # 清屏
print("1-热搜榜\t\t2-要闻榜\t\t3-文娱榜\n4-体育榜\t\t5-游戏榜")
choice = input("请输入你的选择:")
web = {
'1': {
'add': 'summary',
'name': '热搜榜'
},
'2': {
'add': 'summary?cate=socialevent',
'name': '要闻榜'
},
'3': {
'add': 'summary?cate=entrank',
'name': '文娱榜'
},
'4': {
'add': 'summary?cate=sport',
'name': '体育榜'
},
'5': {
'add': 'summary?cate=game',
'name': '游戏榜'
},
}
html = 'https://s.weibo.com/top/' + web[choice]['add']
os.system('cls')
# print("\033[34m\t微博搜索-热搜榜\033"+'\033[34m %s\033' % (web[choice]['name']))
print(Fore.LIGHTMAGENTA_EX + "\t微博搜索-" + '%s' % (web[choice]['name']))
# 保存榜单名称至列表weibo
weibo.append("微博搜索-" + web[choice]['name'])
# 时间
print(Style.RESET_ALL, end='') # 重置所有样式
print('截止于:', formatted_time)
weibo.append('截止于:' + formatted_time)
return html
七、生成名字为“目标榜单 截止时间”的文件 内容为榜单热搜
with open(str(weibo[0]) + ' ' + str(formatted_time_1) + '.txt', 'w+', encoding='utf-8') as file:
for data1 in weibo:
for data2 in data1:
file.write(data2)
file.write('\n')
# 检测文件状态
fileName = str(weibo[0]) + ' ' + str(formatted_time_1) + '.txt'
if os.path.isfile(fileName):
filePath = os.path.abspath(fileName)
# print("\033[36m文件已保存,路径为:+%s\033[0m" % file_path) # 青色
print(Fore.LIGHTYELLOW_EX + "文件已保存,路径为:%s" % filePath)
else:
# print("\033[35m文件保存失败,请重新运行!\033[0m")
print(Fore.MAGENTA + "文件保存失败,请重新运行!")
print(Style.RESET_ALL, end='') # 重置所有样式八、页面展示
1、主菜单
2、榜单(以游戏榜为例)
