Python反反爬虫:JavaScript 逆向爬虫(三)浏览器调试技巧:
在做爬虫时,如果遇到前端那些被混淆,加密的代码, 就不得不硬着头皮去想方设法的找出其中隐含的关键逻辑了, 这个过程,就是 JS 逆向
我们先来基于Chrome 浏览器介绍浏览器开发者工具的使用,但由于开发者工具的功能十分复杂, 我们主要学习对 JS逆向有帮助的功能, 学会这些, 在做JS逆向调试的过程中会更加得心应手
在本节中, 我们以一个示例网站 https://spa2.scrape.center/ 来做演示
面板介绍:
接下来,我们可以打开浏览器,输入该网址, 然后在浏览器上 右键 检查 , 即可打开开发者工具
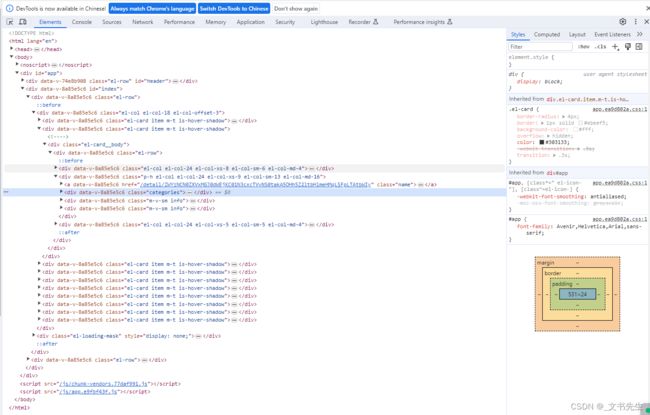
这里可以看到有很多面板标签, 例如: Elements, Console, Sources 等, 这就是开发者工具的一个个面板, 功能丰富且非常强大, 接下来让我们一起了解一下各个面板的功能:
Elements: 元素面板, 用于查看或修改当前网页HTML 节点的属性, Css属性, 监听事件等, Html 和 css 都可以即时修改和即时显示。
Console: 控制台面板, 用于查看调试日志或异常信息,另外, 我们还可以在控制台输入 JS代码,方便调试
Sources: 源代码面板,用于查看页面的HTML文件源代码, JS源代码, css源代码,此外,还可以在此面板对JS代码进行调试, 比如添加和修改JS 断点,观察JS变量变化等
Network: 网络面板, 用于查看页面加载过程中的各个网络请求,包括请求,响应等。
Performance: 性能面板, 用于记录和分析页面在运行时的所有活动, 比如 CPU占用情况,呈现页面的性能分析结果
Memory: 内存面板,用于记录和分析页面占用内存的情况, 如查看内存占用情况,查看 JS对象和 HTML节点的内存分配
Application: 应用面板, 用于记录网站加载的所有资源信息, 如存储, 缓存, 字体, 图片等,同时也可以对一些资源进行修改和删除
Lighthouse: 审核面板, 用于分析网络应用和网页,收集现代性能指标并提供对开发人员最佳时间的意见,
学会这些面板,对我们逆向过程会有很大的帮助
查看节点事件:
我们可以通过Elements 面板审查页面的节点信息, 可以查看当前页面的HTML源码及其在网页中对应的位置, 查看某个条目的标题对应的页面源代码,

点击右侧的Styles选项卡, 可以看到对应节点的CSS 样式, 我们可以自行在这里增删样式,实时预览效果, 这对网页开发十分有帮助
在Computed选项卡中, 可以看到当前节点的盒子模型, 比如外边距, 内边距等, 还可以看到当前节点最终计算出的CSS样式
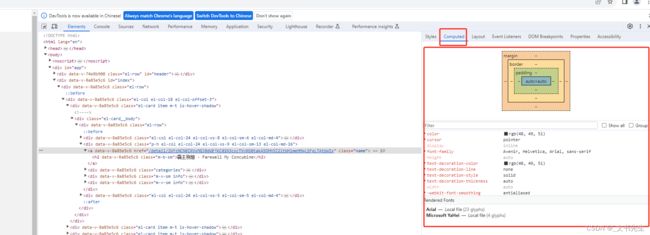
接下来, 切换到右侧的Event Listeners 选项卡, 这里可以查看各个节点当前已经绑定的事件, 都是JS原生支持的, 下面简单列举几个事件:
change: HTML元素改变时会触发的事件
click: 用户点击HTML元素时会触发的事件
mouseover: 用户在一个HTML元素上移动鼠标时会触发的事件
mouseout: 用户从一个HTML元素已开鼠标时会触发的事件
keydown: 用户按下键盘按键时会触发的事件
load: 浏览器完成页面加载时会触发的事件
通常, 我们会给按钮绑定一个点击事件, 它的处理逻辑一般是由JS 定义的, 这样在我们点击按钮的时候, 对应的JS代码便会执行:
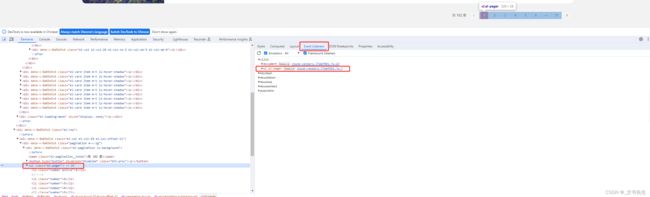
如图所示, 这里有对应事件的代码位置, 内容为一个JS文件名称:chunk- ......
然后紧跟着一个冒号, 接着跟了一个数字 7, 所以对应的事件处理函数是定义在 chunk-vendors.77daf991.js 这个文件的第7行, 点击这个代码的位置, 便会自动跳转到 Sources面板, 打开对应的 chunk-vendors.77daf991.js 文件并跳转到对应的代码位置:
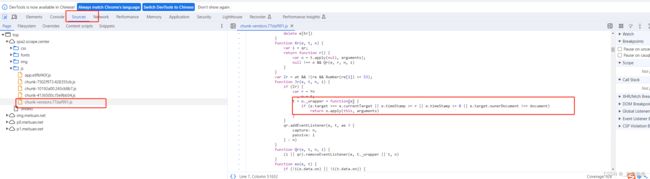
所以, 利用好Event Listeners, 我们可以轻松找到各个节点绑定事件的处理方法所在位置,帮我们在JS 逆向过程中找到一些突破口
代码美化:
刚才我们通过 Event Listeners 找到了对应的事件处理方法所在的位置,并成功的跳转到了代码所在位置, 但是这部分代码似乎被压缩过了, 可读性很差, 根本没法阅读,该怎么办呢? Sources面板提供了一个便捷好用的代码美化功能:
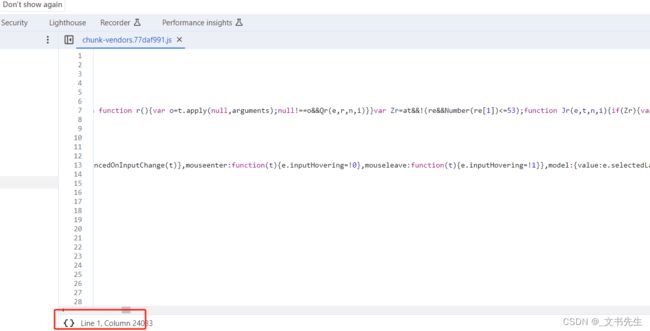
点击此按钮,即可将别压缩过的代码格式化, 以人性化的方式展示
断点调试:
接下来,我们介绍一个非常重要的功能, 断点调试, 在调试代码的时候, 我们可以在需要的位置上打上断点, 当对应的事件触发时, 浏览器就会自动停在断点的位置等待调试,此时我们可以选择单步调试, 在面板中观察 调用栈, 变量值, 以更好的追踪对应位置的执行逻辑:
我们在要调试的代码前面用鼠标点击一下, 即可添加一个断点
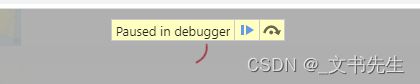
我们知道这个断点就是用来翻页按钮的点击事件, 所以可以在网页里面点击按钮试试, 例如,点击第二页的按钮, 这时候会发现断点就出发了:

这时候在页面中会看到有一个叫 Paused in debugger 的提示, 这说明浏览器执行到刚才我们设置断点的位置处就不在继续执行了, 等待我们发号施令执行调试
此时可以看到, 回调参数 e 就是对应的点击事件 MouseEvent , 在右侧的Scope 面板处, 可以观察到各个变量的值, 比如在 Local域下有当前方法的局部变量, 我们可以在这里看到就MouseEvent 的各个属性:

另外,我们关注到有一个方法 o, 他在 Jr 方法下面, 所以切换到 Closure(Jr) 域, 可以查看它的定义及其接受的参数:
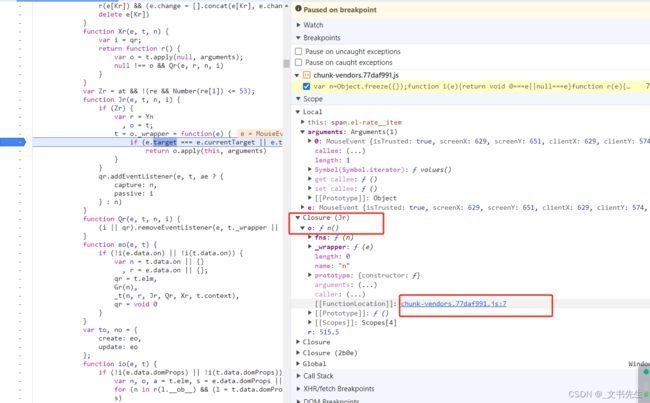
可以看到, FunctionLocation 又指向了方法 O, 点击之后又可以跳到指定位置, 用同样的方法进行断点调试即可,
通过Scope面板, 我们可以看到当前执行环境下变量的值和方法的定义, 知道当前代码究竟执行了怎样的逻辑
接下来, 切换到 Watch面板, 在这里可以自行添加想要查看的变量和方法, 点击右上角 + 按钮, 我们可以任意添加想要监听的对象:
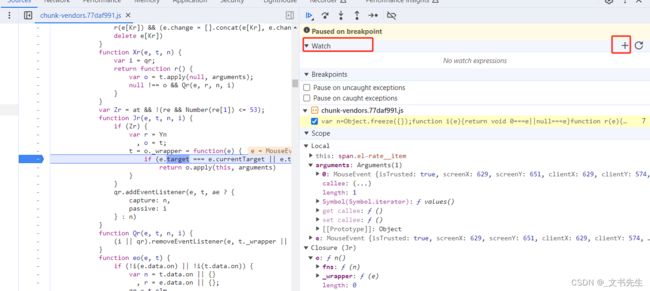
还有Console面板, 如果我们在debugger调试过程中, 想看那个对象,以及变量的值是什么, 可以直接在Console 中输入, 然后打印出来, 非常的方便
调试过程中, 有三个很重要的按钮也需要学习一下:

Step Over Next Function Call : 逐语句执行
Step Into Next Function Call : 进入方法内部执行
Step out of Current Function : 跳出当前方法
用得较多的是第一个, 相当于逐行调试
观察调用栈:
在调试的过程中, 我们可能会跳到一个新的位置,比如点击几下 Step Over Next Function Call 按钮, 可能会跳到一个叫做 ct 的方法中, 这时候我们也不知道发生了什么

究竟怎么调过来的呢, 我们观察一下右侧的Call Stack 面板, 就可以看到全部的调用过程了, 比如它的上一步是 ot 方法, 再上一步是 pt 方法, 点击对应的位置也可以跳转到对应的代码位置:
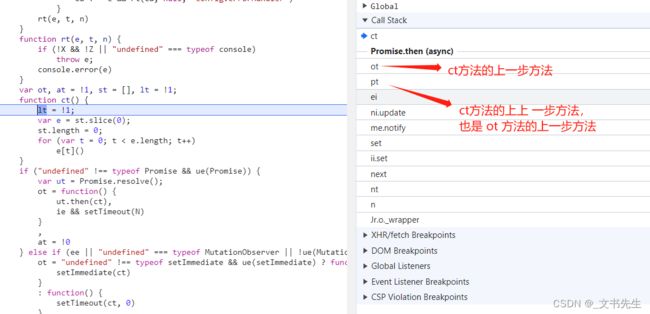
有时候调用栈是非常有用的, 利用它我们可以追溯某个逻辑的执行流程,从而快速找到突破口
恢复JS执行:
在调试过程中, 如果想快速跳到下一个断点或者让Js 代码运行下去, 可以点击 Resume script execution 按钮:

如果有 打上其它的断点, 点击此按钮后会跳到下一个断点, 如果没有其它断点了,那么JS会完全执行完毕
Ajax 断点:
上面我们介绍了一些DOM 节点的监听器, 通过监听器我们可以手动设置断点并进行调试, 但其实针对这个例子, 通过翻页的点击事件监听器是不太容易找到突破口的。
接下来我们在街上一个方法, Ajax 断点, 它可以在发生Ajax请求的时候触发断点, 对于这个例子, 我们的目标其实就是找到Ajax请求的那一部分逻辑, 找出加密参数是怎么构造的, 可以想到, 通过Ajax断点, 使页面在获取数据的时候停下来, 我们就可以顺着找到构造Ajax请求的逻辑了。
我们把之前的断点全部取消掉, 切换到Sources 面板下, 然后展开 XHR/fetch Breakpoints, 这里就可以设置Ajax断点了: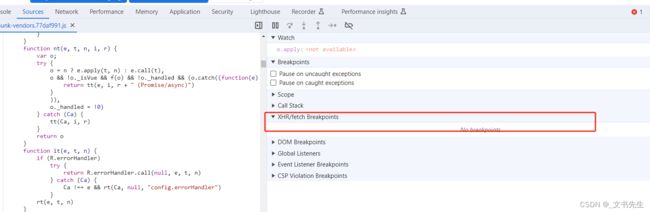
要设置断点,就要先观察Ajax请求, 和之前一样, 我们点击翻页按钮, 在Network面板里面观察 Ajax请求是怎样的:
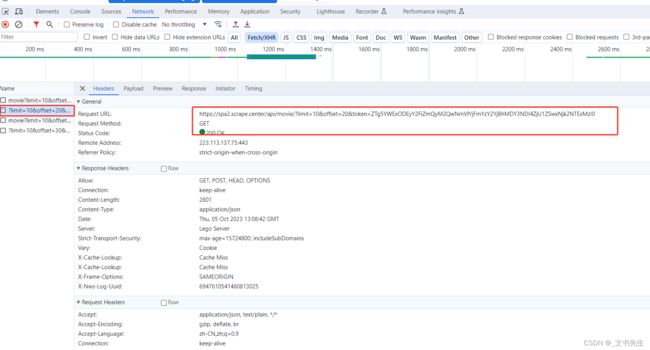
可以看到, URL里面包含 /api/movie这样的内容, 我们可以 在刚才的XHR/fetch Breakpoints 面板中添加拦截规则, 点击 + 按钮, 可以看到一行 Break when URL contains: 的提示, 意思就是 当Ajax请求的URL包含填写的内容时,就会进入断点停止, 这里可以填写 /api/movie

这时候如果我们再点击翻页, 触发下一页的请求, 会发现点击后之后页面走到断点停下来了

我们将代码格式化一下, 发现它听到了 Ajax 最后发送的那个时候, 即底层的XMLHttpRequest的send 方法,, 可是似乎还是找不到Ajax请求是怎么构造的, 前面我们讲过 Call Stack, 通过它可以顺着找到前序调用逻辑, 所以顺着它一层层找, 也可以找到构造Ajax请求的逻辑, 最后会找到一个叫作 onFetchData 的方法 :

切换到onFetchData方法并将代码格式化, 可以看到此时就是一个Ajax:
可以发现, 这里可能使用了axios库发送了一个Ajax请求, 还有 limit, offset, token 这3个参数, 基本就能确定了, 顺利找到了突破口
因此在某些情况下, 我们可以比较容易的通过Ajax断点找到分析的突破口, 这是一个常见的寻找JS 逆向突破口的方法
要取消断点也很简单, 只需要在 XHR/fetch Breakpoints 面板取消勾选即可
改写 JavaScript 文件:
我们知道, 一个网页里面的JS 是从对应服务器上下载下来并在浏览器执行的, 有时候, 我们可能想要在调试的过程中对JS 做一些更改, 比如有以下需求:
发现Js 文件中包含很多阻扰调试的代码或者无效代码, 干扰代码,想要将其删除
调试到某处,想要加一行console.log 输出一些内容, 以便观察某个变量或方法在页面加载过程中的调用情况, 在某些情况下, 这种方法比打断点调试更方便
调试过程遇到某个局部变量或方法, 想要把它赋值给window对象以便全局可以访问或调用
在调试的时候, 得到的某个变量中可能包含一些关键的结果, 想要加一些逻辑将这些结果转发到对应目标服务器,
这时候我们可以试着在Sources 面板中对 JS 进行更改, 但是这种更改并不能长久生效, 一旦刷新页面, 更改就全都没有了
在浏览器中,,有一个ReRes 插件, 我们可以添加自定义Js 文件, 并配置URL映射规则, 这样浏览器在加载某个在线 JS 文件的时候就可以将内容替换成自定义的JS 文件了, 另外,还有一些代理服务器也可以实现, 比如 Charles, Fiddler , 借助它们可以在加载 Js 文件时修改对应 URL 的响应内容, 以实现对 Js 文件的修改
其实浏览器的开发者工具已经原生支持这个功能了, 即浏览器的 Overrides 功能, 它在 Sources 面板左侧,
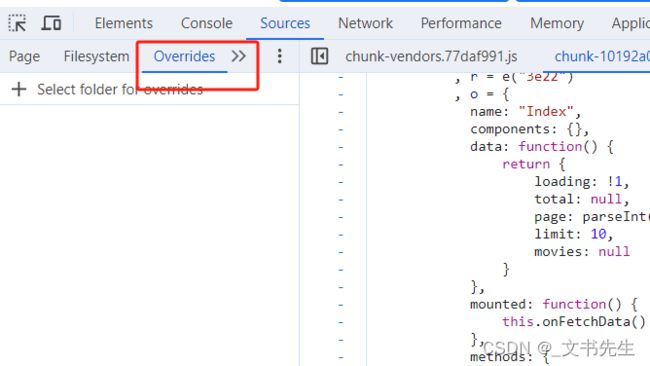
我们可以在 Overrides 面板选定一个本地的文件夹, 用于保持需要更改的JS 文件, 下面让我们来实操练习一下:
首先,根据前面设置Ajax断点的方法,找到对应的构造Ajax请求的位置, 根据一些网页开发知识, 我们可以大体判断出 then 后面的回调方法接受的参数a 中就包含了Ajax请求的结果:

我们打算在Ajax请求成功获得响应的时候, 在控制台输出响应的结果, 也就是通过console.log输出变量a
在切回 Overrides面板, 点击 + 按钮, 这时候浏览器会提示我们选择一个本地文件夹,用于存储要替换的JS文件, 这里我们选定了一个新建的文件夹 ChromeOverrides 注意如果这时候遇到弹窗, 确认没问题,点击允许即可
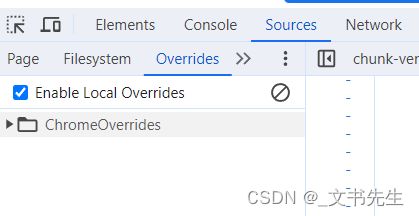
这时, Overrides面板下就多了 ChromeOverrides 文件夹, 用于存储所有我们想要更改的 JS文件
选择要修改的JS文件, 然后右键 选择 override content 选项,即可将要修改的文件添加到Overrides 中创建的文件夹里, (注意:这里由于浏览器版本不同的缘故, 有可能操作不一致, 自行摸索一下即可)

此时我们取消所有断点, 刷新页面, 就可以在控制台看到输出的响应结果了,
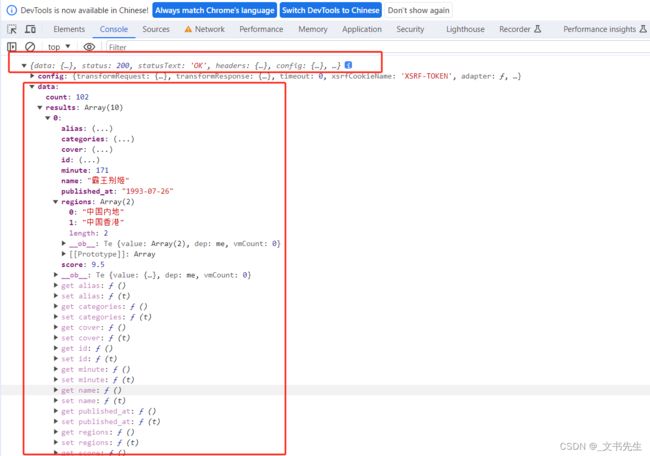
正如我们所料, 成功的将变量 a输出, 其中的data 字段就是 Ajax的响应结果, 证明改写 JS 成功, 而且刷新页面也不会丢失,重新加载JS文件了,因为用的是我们覆盖的本地JS文件
我们还可以增加一些JS 逻辑, 例如直接将变量a 的结果通过 API 发送到远程服务器, 并通过服务器将数据保存下来, 也就完成了直接拦截Ajax 请求并保存数据的过程了
修改 JS 文件有很多用途, 此方案可以为我们进行 JS 逆向带来极大的便利