Python反反爬虫:JavaScript 逆向爬虫(四)JS Hook的使用:
在JS逆向的时候, 我们经常需要追踪某些方法的堆栈调用情况, 但是很多情况下, 一些JS变量或者方法名经过混淆之后是非常难以捕捉的, 我们学习了断点的调试, 调用栈查看等技巧, 但仅仅凭借这些技巧还不足以应对多数的 JS 逆向
Hook技术:
Hook技术又叫钩子技术, 指在程序运行的过程中, 对其中的某个方法进行重写, 在原先的方法前后加入我们自定义的代码, 相当于在系统没有调用该函数之前,钩子程序就先捕获 该消息, 得到控制权, 这时钩子函数既可以加工处理(改变)该函数的执行行为, 也可以强制结束消息的传递。
要对 JS代码进行Hook 操作, 就需要额外在页面中执行一些有关 Hook 逻辑的自定义代码, 那么问题来了。怎么才能在浏览器中方便地执行我们所期望执行的 JS 代码呢? 这里推荐一个插件, 叫 Tampermonkey, 这个插件的功能非常强大, 利用它我们几乎可以在网页中执行任何 JS 代码,实现我们想要的功能
Tampermonkey:
Tampermonkey, 中文也叫 油猴 , 它是一款浏览器插件, 支持Chrome, 利用它, 我们可以在浏览器加载页面时自动执行某些 JS 脚本, 由于执行的是 JS, 所以我们几乎可以在网页中完成任何我们想实现的效果, 例如 自动爬虫, 自动修改页面, 自动响应事件等
其实油猴 的用途远远不止这些, 只要我们想要的功能能用 JS 实现, Tampermonkey 就可以帮我们做到, 比如, 我们可以将 Tampermonkey 应用到 JS 逆向分析中, 去帮助我们更方便的分析一些JS 加密和混淆的代码
安装 Tampermonkey:
首先我们需要安装 油猴 插件, 我们使用的浏览器是 Chrome, 直接在 Chrome 应用商店或者 Tampermonkey 官网上下载并安装即可, 安装完成之后呢, 浏览器右上角会出现 油猴 插件图标, 这样就表示安装成功了:

获取脚本:
Tampermonkey 运行的是 JS 脚本, 每个网站都能有对应的脚本运行, 不同的脚本能完成不同的功能, 我们既可以自定义脚本, 也可以用已经写好的很多脚本, 毕竟有些轮子有了, 我们就不需要再造了
脚本编写:
除了使用别人已经写好的脚本外, 我们也可以自己编写脚本来实习想要的功能, 编写脚本其实就是写 JS代码, 只需要懂一些 JS 语法就好了, 另外,我们需要遵循脚本的一些写作规范, 其中就包括一些参数的设置
下面我们就简单实现一个小脚本, 首先, 点击Tempermonkey 插件图标, 再点击 管理面板 项, 打开脚本管理页面:
这里显示已经有了一个 油猴 脚本, 当然, 我们可以自己创建, 也可以从第三方网站下载和安装, 另外这里也停工了编辑,调试,删除等管理内容
解下来让我们创建一个新脚本, 点击左侧 + 按钮:
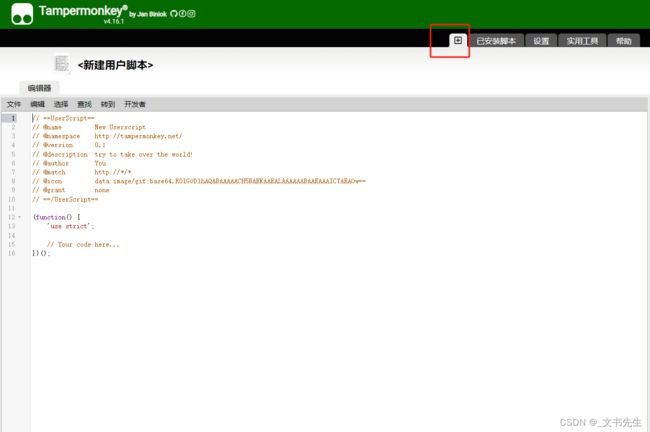
初始化代码如下:
// ==UserScript==
// @name New Userscript
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author You
// @match http://*/*
// @icon data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==
// @grant none
// ==/UserScript==
(function() {
'use strict';
// Your code here...
})();在上面这段代码中, 最前面的是一些注释, 它们非常有用, 这部分内容叫作:UserScript Header
我们可以在里面配置一些脚本信息, 如:名称,版本, 描述, 生效站点等。
下面简单介绍一下 UserScript Header 的一些参数意义:
@name: 脚本的名称, 就是在控制面板显示的脚步名称
@namespace: 脚本的命名空间
@version:脚本的版本, 主要做版本更新时用
@author: 作者
@description:脚本描述
@homepage, @homepageURL, @website, @source: 作者主页,用于在Tampermonkey 选项页面上从脚本名称点击跳转, 请注意, 如果 @namespace 标记以 http:// 开头, 此处也一样
@icon, @iconURL, @defaulticon: 降低分辨率图标
@icon64, @icon64URL: 64 x 64 高分变绿图标
@updateURL: 检查更新的网址,需要定义 @version
@downloadURL: 更新下载脚本的网址,如果定义成none, 就不会检查更新
@supportURL: 报告问题的网址
@include: 生效页面, 可以配置多个, 但注意这里并不支持 URL Hash
例如:
// @include http://www.tampermonkey.net/*
// @include http://*
// @include https://*
// @include *
@match: 约等于@include 标签, 可以配置多个,
@exclude: 不生效页面, 可配置多个,优先级高于 @include 和 @match
@require: 附加脚本网址, 相当于引入外部的脚步, 这些脚步会在自定义脚本执行之前执行,比如引入一些必需的库, 如 jquery等, 这里可以支持配置多个@require参数
例如:
// @require https://code.jquery.com/jquery-2.1.4.min.js
@resource:预加载资源, 可通过GM_getResourceUrl 和 GM_getResourceText 读取。
@connect: 允许被GM_xmlhttpRequest 访问的域名, 每行1个
@run-at: 脚本注入的时刻, 如页面刚加载时, 某个事件发生后等
document-start: 尽可能早执行此脚本
document-body: DOM的body出现时执行
document-end: DOMContentLoaded 事件发生时或发生后执行
document-idle: DOMContentLoaded 事件发生后执行, 即DOM 加载完成之后执行, 这是默认选项
document-menu: 如果浏览器上下文菜单(仅限桌面Chrome浏览器)中点击该脚本, 则会注入该脚本, 注意如果使用此值, 则忽略所有 @include 和 @exclude 语句
@grant:用于添加GM函数到白名单,相当于授权某些GM函数的使用权限
例如:
// @grant GM_setValue
// @grant GM_getValue
如果没有定义过 @grant 选项, 油猴 会猜测所需要的函数使用情况
@noframes: 此标记使脚本在主页面运行,但不会在ifame上云行
@nocompat: 由于部分代码可能是为专门的浏览器所写, 通过此标记, 油猴会知道脚本可以运行的浏览器, 例如: // @nocompat Chrome. 这样就制定了脚本只在Chrome浏览器运行
除此之外, Tampermonkey 还定义了一些API, 使得我们可以方便的完成某个操作
GM_log: 将日志输出到控制台
GM_setValue: 将参数内容保存到浏览器存储中
GM_addValueChangeListener: 为某个变量添加监听, 当这个变量的值改变时, 就会触发回调
GM_xmlhttpRequest: 发起Ajax请求
GM_download: 下载某个文件到磁盘
GM_setClipboard: 将某个内容保存到粘贴板
此外还有很多其它API, 大家感兴趣可以到:
https://www.tampermonkey.net/documentation.php 查看
在UserScript Header 下发, 使 JS 函数和调用的代码, 其中, 'use strict' 标明代码使用JS 的严格模式, 在严格模式下, 可以消除JS语法的一些不合理, 不严谨之处, 减少一些怪异行为, 如不能直接使用过未声明的变量, 这样可以保证代码运行安全,同时提高编译器的效率, 提高运行速度,
在下方 // Your code here 。。。 处就可以编写自己的代码了
实战分析:
下面我们通过一个简单的 JS逆向案例来演示如何实现 JS 的 hook 操作, 轻松找到某个方法执行的位置, 从而快速定位 逆向入口,
接下来, 我们来看一个简单的网站:https://login1.scrape.center/ 这个网站的结构非常简单,只有 用户名, 密码 文本框, 和登录按钮, 但是不同的是, 点击登录按钮的时候, 表单提交post的内容并不是单词的用户名和密码, 而是一个加密后的 token
我们不需要关心响应的结果和状态 , 主要看请求的内容就好,
可以看到, 点击登录后, 发起了一个POST请求, 内容为 Ajax数据,
确实没有像 username password 的内容, 怎么模拟登录呢?
模拟登录的前提就是找到当前 token生成的逻辑, 这个token和用户名, 密码是什么关系呢?
这里我们就可能思考了, 本身输入的是用户名和密码, 但是提交的时候却变成了一个 token, 经过观察并结合一些经验可以看出, token的内容非常像 Base64编码, 这就代表, 网站可能首先将 用户名和密码混为一个新的字符串, 然后经过了一次base64编码, 最后将其赋值为 token 来提交了
那我们就来验证一下吧, 探索一下网站的JS 代码里面是如何实现的,
首先我们看一下网站的源代码, 打开 Sources 面板, 看起来都是 webpack 打包之后的内容经过了一些混淆:

这么多混淆代码, 总不能一点点扒着看吧, 解决方法其实有两种, 一种就是前面所学的Ajax断点, 另外一种就是 hook
Ajax断点:
由于这个请求正好是Ajax请求,所以我们可以添加一个XHR断点来监听, 把POST的网址加到断点上面, 在Sources面板右侧添加一个XHR 断点, 匹配内容就填当前域名:
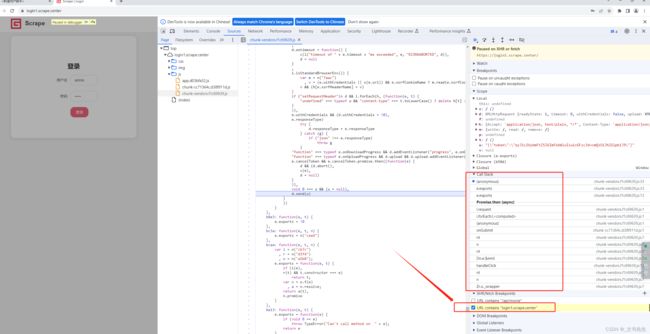
此时如果我们再点击登录 按钮, 发起一次Ajax请求, 就可以进入断点了, 然后再观察堆栈信息, 就可以一步步找到编码的入口了,
一步一步找, 最后可以找到入口其实在 onSubmit方法 这里, 但实际上我们观察到, 这里断点的栈顶还包括了一些 Promise 相关的内容, 而我们真正想找的是 用户名和密码 经过处理, 再进行 Base64 编码的地方, 这些请求的调用实际上和我们找寻入口没有很大的关系
另外, 如果我们想找的入口位置并不伴随这一次Ajax 请求, 这个方法就没法用了
Hook:
第二种可以快速定位入口的方法,就是使用 Tampermonkey 自定义 JS, 实现某个JS 方法的hook, hook哪里呢? 很明显, hook base64编码的位置就好了
在JS 中, base64的实现方法就是 btoa 方法, 在 JS中该方法用于将字符串编码成 Base64 字符串, 因此我们来 hook btoa 方法就好了
新建一个 Tampermonkey 脚本,其内容如下:
// ==UserScript==
// @name HookBase64
// @namespace https://login1.scrape.center/
// @version 0.1
// @description Hook Base64 encode function
// @author Evan
// @match https://login1.scrape.center/
// @grant none
// ==/UserScript==
(function() {
'use strict';
// Your code here...
function hook(object, attr){
var func = object[attr]
object[attr] = function () {
console.log('hooked', object, attr)
var ret = func.apply(object, arguments)
debugger
return ret
}
}
hook(window, 'btoa')
})();首先, 我们定义了一些UserScript Header, 包括@name, @match等, 这里比较重要的就是 @name, 表示脚本的名字, 另外一个就是 @match, 它代表脚本生效的网址
接着, 我们定义了hook 方法, 这里给其传入 object 和attr 参数, 意思就是 Hook object 对象的 attr 参数, 例如,如果我们想要 Hook alert 方法,那就把object 设置为 window, 把attr 设置为字符串 alert, 这里我们想要 Hook Base64 编码方法, 而在 JS中, base64 方法就是用 btoa方法实现的, 所以这里只需要 Hook window 对象的 btoa 方法即可
那么, Hook是怎么实现的呢? 我们来看一下, var func = object[attr] 相当于我们先把它赋值为一个变量, 即我们调用 func 方法就可以实现和原来相同的功能, 接着, 我们直接改写这个方法的定义, 将 object[attr] 改写成一个新的方法, 在新的方法中, 通过 func.apply 方法又重新调用了原来的方法, 这样我们就可以保证前后方法的执行效果不受影响, 之前这个方法该干啥还干啥
但是和之前不同的是, 现在我们自定义方法之后, 可以在 func方法执行前后加入自己的代码, 如通过 console.log 将信息输出到控制台, 通过 debugger进入断点等, 在这个过程中, 我们先临时保存下来 func方法, 然后定义一个新的方法, 接管程序控制权, 在其中自定义我们想要的实现,同时在新的方法里面重新调回 func方法, 保证前后结果不受影响, 所以,我们达到了在不影响原有方法效果的前提下, 实现在方法前后自定义的功能, 这就是Hook的过程。
最后, 我们调用 hook 方法, 传入 window对象和 btoa 字符串, 保存
接下来刷新页面, 这是 我们可以看到这个脚本在当前页面就生效了, Tempermonkey 插件面板提示已经启用, 同时,在 Sources 面板下的Page 选项卡中, 可以观察到我们定义的 JS 脚本被执行了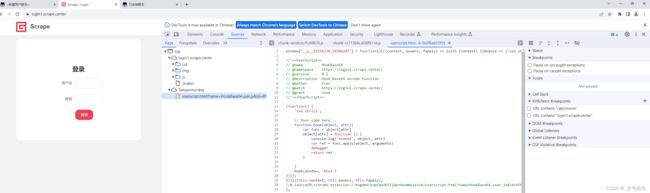
输入用户名和密码, 然后点击登录按钮, 成果进入断点模式并停了下来, 代码就卡在我们自定义的 debugger这行代码的位置:

成功 Hook住了, 这说明 JS代码在执行过程中,调用了 btoa方法,
这时看一下控制台, 输出流 window对象和 btoa方法, 
这样我们就顺利找到了 Base64编码操作这个入口, 然后看一下堆栈信息, 已经不会出现 Promise 相关的信息了, 其中清晰地呈现 了 btoa方法逐层调用过程:
另外再观察下 Local 面板, 看看arguments 变量是怎样的:

可以说是一目了然, arguments 就是指传给 btoa方法的参数, ret 就是 btoa方法返回的结果, 可以看到, arguments 就是 username 和 password 通过 JSON 序列化之后的字符串, 经过 Base64 编码之后得到的值恰好就是Ajax请求参数 token的值
结果几乎也明了了, 我们还可以通过调用栈 找到 onSunbmit 方法的处理源码:
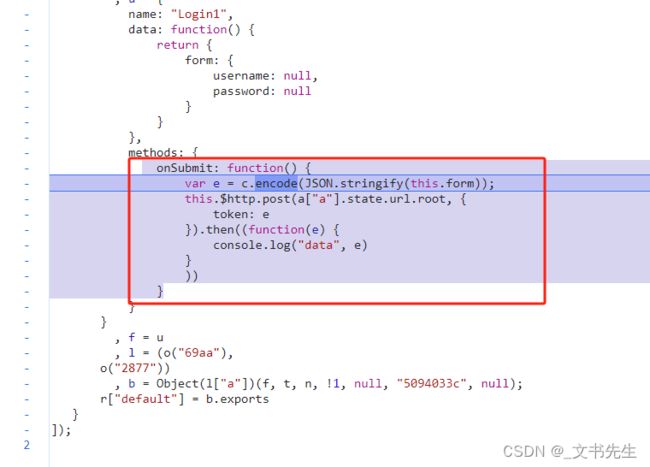
仔细看看, encode方法其实就是调用了 btoa 方法, 这就是一个Base64 编码的过程, 我们还可以进一步添加断点验证, 比如在调用 encode方法的那行添加断点:

我们在编码这行逻辑上添加一个断点,然后将debugger放开, 重新登录, 可以发现, 程序会停留在我们打断点的这行位置
这时候, 如果我们在 Watch 面板下输入 this.form 验证此处是否为在表单中输入的用户名和密码:
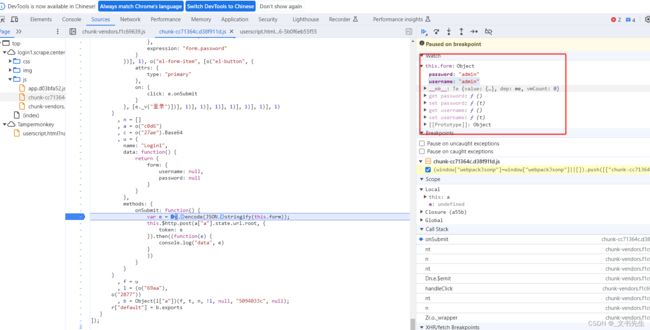
没问题, 然后逐步调试, 可以观察到, 下一步就跳到了我们 Hook 的位置, 这说明调用了 btoa方法, 可以看到,返回等结果就是 token:
 、整体逻辑就是对登录表单的用户名和密码进行 JSON 序列号, 然后调用 encode(也就是 btoa 方法), 并把encode 方法的结果赋值给token 发起登录的Ajax请求,
、整体逻辑就是对登录表单的用户名和密码进行 JSON 序列号, 然后调用 encode(也就是 btoa 方法), 并把encode 方法的结果赋值给token 发起登录的Ajax请求,
以后如果观察出一些门到, 可以使用这种方式来尝试, 如: Hook encode 方法, decode 方法, stringify 方法, log 方法, aler 方法等, 简单又高效