python爬虫--requests简介
一:requests的概念
简单来说,爬虫由获取网页和解析网页获取数据组成,reqiuests模块就是用来获取网页的,当然requests模块时第三方模块,需要下载导入(win+r--->pip install requests),另外 使用urlib也是一种获取网页的方式,不过使用urlib的效率比requests效率和兼容较低,故我们重点了解掌握requests模块即可!
二:requests基本使用(常用方法)
例1:获取百度首页
# 导入 requests 包
import requests
# 发送请求
x = requests.get('https://www.baidu.com')
# 返回网页内容
print(x.text)例2:破解百度翻译(控制台输入要翻译的单词,导出json文件的解释在文件目录中)
import requests
import json
# 1.指定url
post_url="https://fanyi.baidu.com/sug"
# 2.进行UA伪装
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36"
}
kw=input("请输入你要翻译的字符:")
# 3.请求参数处理
data={
"kw":kw
}
# 4.请求发送
response=requests.post(url=post_url,data=data,headers=headers)
# 5,获取响应数据
dic_obj=response.json()
# 6.持久化存储
fp=open(kw+".json","w",encoding="utf-8")
json.dump(dic_obj,fp=fp,ensure_ascii=False)
print("over")如何知道是改用get()还是post(),可以右键检查(F12),抓包工具可以看到require method(需要方法),以及如何知道获取的数据是text文本内容格式还是json格式,也是早抓包查看network--->Headers
| 1.request() |
构造请求,支撑以下的基础方法 |
| 2.get() |
获取HTML页面的主要方法,对应于http的get(常用) |
| 3.head() |
获取HTML页面的头部信息的主要方法,对应于http的head |
| 4.post() |
向HTML提交post请求的方法,对应于http的post(常用) |
| - |
|
| - |
|
| 5.put() |
向HTML提交put请求的方法,对应于http的put |
| 6.patch() |
向HTML提交局部修改的请求,对应于http的patch |
| 7.delete() |
向HTML提交删除请求,对应于http的delete |
| 8.json() | 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) |
每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息。
响应信息如下:
| status_code |
HTTP请求的返回状态码,200表示成功,400表示失败 |
| text |
HTTP响应内容的字符串形式,即URL对应的页面内容 |
| encoding |
从HTTPheader中猜测的响应内容编码方式 |
| - |
|
| apparent_encoding |
从内容中分析出的响应内容编码方式(备选编码方式) |
| - |
|
| content |
HTTP响应内容的二进制形式 |
现在再来看一个例子:
import requests
#构造一个向服务器请求资源的Response对象
r = requests.get(url="http://www.baidu.com")
print(r.status_code) #打印请求状态码
#200
print(type(r)) #打印请求对象类型
#
print(r.headers) #打印请求对象的头部信息
#{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sat, 27 Jun 2020 09:03:41 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:32 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
print(r.text) # 页面源代码(html)
print(r.encoding) #ISO-8859-1
print(r.apparent_encoding) #备用编码utf-8
r.encoding = "utf-8"
print(r.text) 三:请求异常捕获
为了获取网页请求超时或者组织是给出回应而不是报错强制退出,同样使爬虫程序更完善,便引入了异常捕获的方面内容:
爬虫程序的通过用异常捕获代码:
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常!"作用:r.raise_for_status()函数判断当前请求返回状态码,当返回状态码不为200时,产生异常并能够被except捕获
import requests
# (定义方法)封装函数
def getHTMLText(url):
try:
r = requests.get(url,timeout=30) # 超时30s发出异常
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "代码错误,产生异常!"
if __name__ =="__main__":
url = "http://www.baidu.com"
print(getHTMLText(url)) #正常显示爬取的页面信息
if __name__ =="__main__":
url = "www.baidu.com" #缺失了
print(getHTMLText(url)) #代码错误,产生异常!
requests常见异常:
| requests.ConnectionError |
网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError |
HTTP错误异常 |
| requests.URLRequired |
URL缺失异常 |
| requests.TooManyRedirects |
超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout |
连接远程服务器超时异常 |
|
requests.Timeout |
请求URL超时,产生超时异常 |
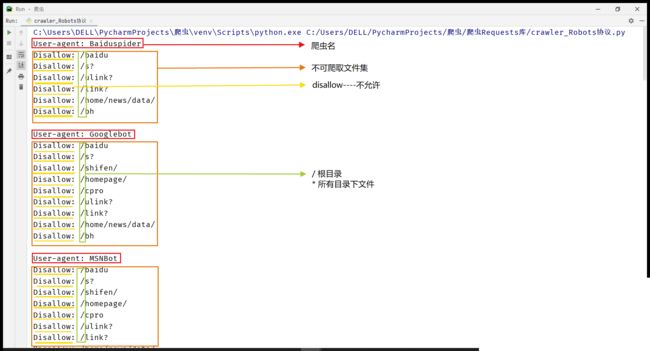
Robots协议展示
import requests
# (定义方法)封装函数
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "代码错误,产生异常!"
if __name__ =="__main__":
url = "http://www.baidu.com/robots.txt"
print(getHTMLText(url)) #正常显示爬取的页面信息,显示出robots协议对于不同类型爬虫的限制
接下来展示几个案例来做巩固:
1:搜狗搜索实现(在控制台输入要搜索的信息条即可搜索,并把搜索结果以文件形式进行保存)
import requests
import json
# 1.指定url
post_url="https://fanyi.baidu.com/sug"
# 2.进行UA伪装
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36"
}
kw=input("请输入你要翻译的字符:")
# 3.请求参数处理
data={
"kw":kw
}
# 4.请求发送
response=requests.post(url=post_url,data=data,headers=headers)
# 5,获取响应数据
dic_obj=response.json()
# 6.持久化存储
fp=open(kw+".json","w",encoding="utf-8")
json.dump(dic_obj,fp=fp,ensure_ascii=False)
print("over")2:获取豆瓣top榜信息(电影名称,导演,评分,时间等等)
import requests
import json
url="https://movie.douban.com/j/chart/top_list"
param={
"type": "24",
"interval_id":'100:90',
"action":"",
"start": "0",
"limit":"20"
}
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36"
}
response=requests.get(url=url,params=param,headers=headers)
list_data=response.json()
fp=open("./douban.json","w",encoding="utf-8")
# json对文件进行操作
# json.dump(json格式化,文件,ensure_ascii=False)
json.dump(list_data,fp=fp,ensure_ascii=False)
print("豆瓣电影爬取完毕!!!")3: 获取北京肯德基的地理位置:
import requests
import json
url="http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname"
data={
"cname": "北京",
"pid":"",
"pageIndex": "1",
"pageSize": "2"
}
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36"
}
response=requests.post(url=url,data=data,headers=headers)
page_text=response.json()
fp=open("./f_kfc.json","w",encoding="utf-8")
json.dump(page_text,fp=fp,ensure_ascii=False)
print("beijing kfc area 查询完毕!!!")4:获取网上图片保存
import requests
import os
url = "http://image.ngchina.com.cn/2019/0523/20190523103156143.jpg"
root = "F:/图片/" #根目录
path = root + url.split('/')[-1] #以最后一个/后的文字命名
try:
if not os.path.exists(root): #如果不存在根目录文件,则创建根目录文件夹
os.mkdir(root) #该方法只能创建一级目录,如要创建多层,可以遍历循环创建
if not os.path.exists(path):
r = requests.get(url)
with open(path,'wb') as f:
f.write(r.content) #r.content返回的是2进制编码,将其写入
f.close()
print("文件已成功保存!")
else:
print("文件已存在~")
except:
print("爬取失败!!!") 