Scrapy框架内置管道之图片视频和文件(一篇文章齐全)
1、Scrapy框架初识(点击前往查阅)
2、Scrapy框架持久化存储(点击前往查阅)
3、Scrapy框架内置管道
4、Scrapy框架中间件(点击前往查阅)
5、Scrapy框架全站、分布式、增量式爬虫

Scrapy 是一个开源的、基于Python的爬虫框架,它提供了强大而灵活的工具,用于快速、高效地提取信息。Scrapy包含了自动处理请求、处理Cookies、自动跟踪链接、下载中间件等功能
Scrapy框架的架构图(先学会再来看,就能看懂了!) 
一、内置管道(图片视频)
1:sttings设置
# 用于在指定目录下创建一个保存图片的文件夹。
IMAGES_STORE = "./imgs"其他的设置不理解的可以参考: Scrapy框架初识

2:数据分析
详细见图片中注视哦~
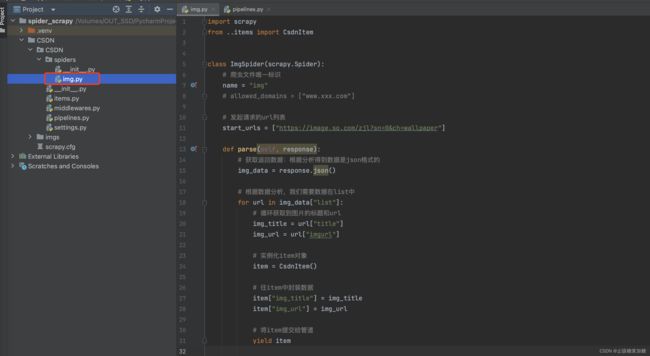
代码:
import scrapy
from ..items import CsdnItem
class ImgSpider(scrapy.Spider):
# 爬虫文件唯一标识
name = "img"
# allowed_domains = ["www.xxx.com"]
# 发起请求的url列表
start_urls = ["https://image.so.com/zjl?sn=0&ch=wallpaper"]
def parse(self, response):
# 获取返回数据:根据分析得到数据是json格式的
img_data = response.json()
# 根据数据分析,我们需要数据在list中
for url in img_data["list"]:
# 循环获取到图片的标题和url
img_title = url["title"]
img_url = url["imgurl"]
# 实例化item对象
item = CsdnItem()
# 往item中封装数据
item["img_title"] = img_title
item["img_url"] = img_url
# 将item提交给管道
yield item3:创建item对象
详细见图片中注视哦~

代码:
import scrapy
class CsdnItem(scrapy.Item):
# define the fields for your item here like:
# 变量随便命名,scrapy.Field() 是固定写法
img_title = scrapy.Field()
img_url = scrapy.Field()4:提交管道,持久化存储
4.1:模块安装
pip install pillow
4.2:代码分析
配合下方图片:
- 1、首先导入 ImagesPipeline 模块,然后class类继承。
- 2、重新构建三个固定函数用于图片的批量下载和保存的操作。
- get_media_requests函数:负责对图片进行请求发送获取图片二进制的数据。
- itme获取爬虫数据传过来的数据这个,不懂理解看这个:item相关知识
- yield发起请求这个是固定写法,参数意思可以看图中注释。
- file_path函数:负责指定保存图片的名字。
- 利用requests来获取上面传过来的数据。
- return返回的值就是图片的名字和后缀
- item_completed函数:用于将item对象传递给下一个管道。
- get_media_requests函数:负责对图片进行请求发送获取图片二进制的数据。

代码:
import scrapy
from scrapy.pipelines.images import ImagesPipeline # 导入模块
class CsdnPipeline(ImagesPipeline): # (ImagesPipeline)括号内加入这个 是面向对象继承,属于面向对象知识。
# 重新构建三个固定函数用于图片的批量下载和保存的操作。
def get_media_requests(self, item, info): # 该函数是负责对图片进行请求发送获取图片二进制的数据
# 可以通过item参数接收爬虫文件提交过来的item对象
img_title = item["img_title"]
img_url = item["img_url"]
# 对图片地址发起请求,(参数1,参数2) 参数1:url 参数2:请求传参,可以将数据传给 file_path 下面这个函数
yield scrapy.Request(img_url, meta={"img_title": img_title})
def file_path(self, request, response=None, info=None, *, item=None): # 负责指定保存图片的名字
# 接收 get_media_requests 函数中通过meta发送过来的数据。
img_title = request.meta["img_title"]
# 给图片名字带上后缀
img_title = img_title + ".jpg"
# 然后返回图片名字
return img_title
def item_completed(self, results, item, info): # 用于将item对象传递给下一个管道
return item
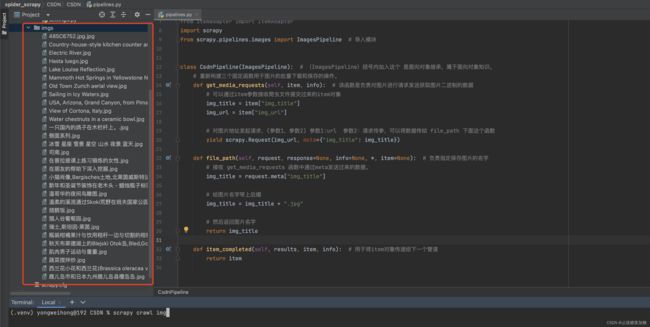
5:结果展示与总结
为什么会在这个文件夹中呢?因为刚开始的 settings 中,我们创建并指定了这个文件夹!!!
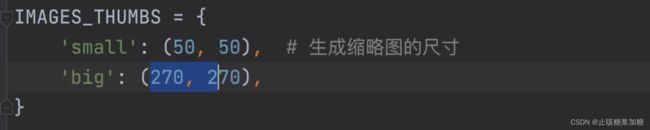
补充:在设置 settings 中,还可以设置图片的缩略图尺寸。
代码流程:
1.在爬虫文件中进行图片/视频的链接提取
2.将提取到的链接封装到items对象中,提交给管道
3.在管道文件中自定义一个父类为ImagesPipeline的管道类,且重写三个方法即可:
def get_media_requests(self, item, info):接收爬虫文件提交过来的item对象,然后对图片地址发起网路请求,返回图片的二进制数据 def file_path(self, request, response=None, info=None, *, item=None):指定保存图片的名称 def item_completed(self, results, item, info):返回item对象给下一个管道类
二、内置管道(文件)
1:sttings设置
# 用于在指定目录下创建一个保存文件的文件夹。
FILES_STORE = "./file"其他的设置不理解的可以参考: Scrapy框架初识
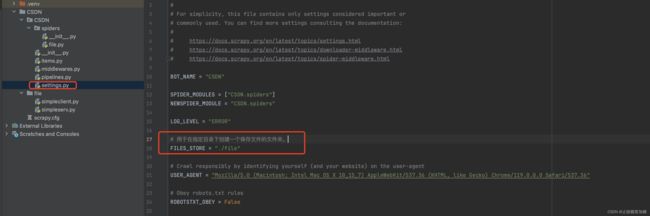
2:数据分析
详细见图片中注视哦,比较简单,不做过多分析了~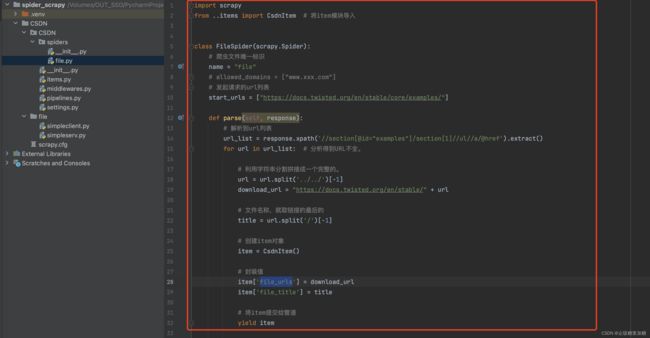
代码:
import scrapy
from ..items import CsdnItem # 将item模块导入
class FileSpider(scrapy.Spider):
# 爬虫文件唯一标识
name = "file"
# allowed_domains = ["www.xxx.com"]
# 发起请求的url列表
start_urls = ["https://docs.twisted.org/en/stable/core/examples/"]
def parse(self, response):
# 解析到url列表
url_list = response.xpath('//section[@id="examples"]/section[1]//ul//a/@href').extract()
for url in url_list: # 分析得到URL不全。
# 利用字符串分割拼接成一个完整的。
url = url.split('../../')[-1]
download_url = "https://docs.twisted.org/en/stable/" + url
# 文件名称,就取链接的最后的
title = url.split('/')[-1]
# 创建item对象
item = CsdnItem()
# 封装值
item['file_urls'] = download_url
item['file_title'] = title
# 将item提交给管道
yield item3:创建item对象
详细见图片中注视哦,与前面不同的是有2个字段是必须存在的。
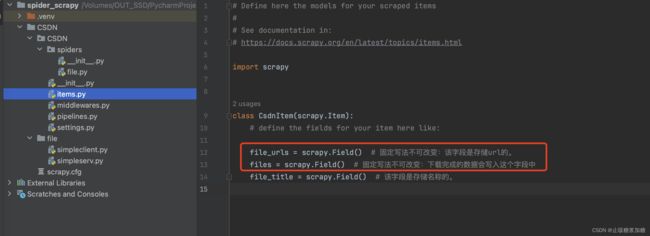
4:提交管道,持久化存储
4.1:模块安装
pip install pillow
4.2:代码分析
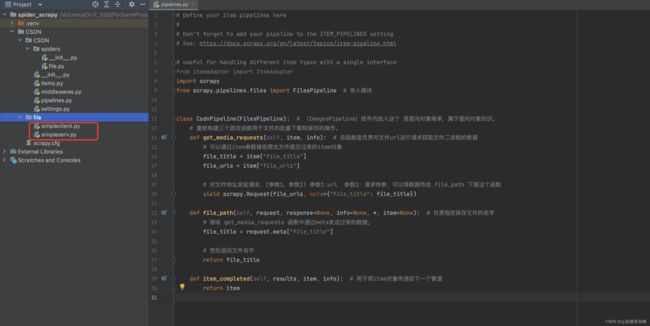
配合下方图片:
- 1、首先导入FilesPipeline 模块,然后class类继承。
- 2、重新构建三个固定函数用于文件的批量下载和保存的操作。
- get_media_requests函数:负责对文件进行请求,获取图片二进制的数据。
- itme获取爬虫数据传过来的数据这个,不懂理解看这个:item相关知识
- yield发起请求这个是固定写法,参数意思可以看图中注释。
- file_path函数:负责指定保存文件的名字。
- 利用requests来获取上面传过来的数据。
- return返回的值就是文件的名字
- item_completed函数:用于将item对象传递给下一个管道。
- get_media_requests函数:负责对文件进行请求,获取图片二进制的数据。

代码:
import scrapy
from scrapy.pipelines.files import FilesPipeline # 导入模块
class CsdnPipeline(FilesPipeline): # (ImagesPipeline)括号内加入这个 是面向对象继承,属于面向对象知识。
# 重新构建三个固定函数用于文件的批量下载和保存的操作。
def get_media_requests(self, item, info): # 该函数是负责对文件url进行请求获取文件二进制的数据
# 可以通过item参数接收爬虫文件提交过来的item对象
file_title = item["file_title"]
file_urls = item["file_urls"]
# 对文件地址发起请求,(参数1,参数2) 参数1:url 参数2:请求传参,可以将数据传给 file_path 下面这个函数
yield scrapy.Request(file_urls, meta={"file_title": file_title})
def file_path(self, request, response=None, info=None, *, item=None): # 负责指定保存文件的名字
# 接收 get_media_requests 函数中通过meta发送过来的数据。
file_title = request.meta["file_title"]
# 然后返回文件名字
return file_title
def item_completed(self, results, item, info): # 用于将item对象传递给下一个管道
return item5:结果展示与总结
代码流程:
在
spider中爬取要下载的文件链接,将其放置于item中的file_urls字段中存储spider提交item给FilesPipeline管道
当
FilesPipeline处理时,它会检测是否有file_urls字段,如果有的话,则会对其进行文件下载下载完成之后,会将结果写入item的另一字段
files
Item要包含file_urls和files两个字段