Redis队列详解(springboot实战)
前言
MQ应用有很多,比如ActiveMQ,RabbitMQ,Kafka等,但是也可以基于redis来实现,可以降低系统的维护成本和实现复杂度,本篇介绍redis中实现消息队列的几种方案,并通过springboot实战使其更易懂。
1. 基于List的 LPUSH+BRPOP 的实现
2. 基于Sorted-Set的实现
3. PUB/SUB,订阅/发布模式
4. 基于Stream类型的实现
1. 基于List的 LPUSH+BRPOP 的实现
描述
使用rpush和lpush操作入队列,lpop和rpop操作出队列。
List支持多个生产者和消费者并发进出消息,每个消费者拿到都是不同的列表元素。
优点
一旦数据到来则立刻醒过来,消息延迟几乎为零。
缺点
不能重复消费,一旦消费就会被删除
不能做广播模式 , 不支持分组消费
lpop和rpop会一直空轮训,消耗资源 ,但可以 引入阻塞读blpop和brpop 同时也有新的问题 如果线程一直阻塞在那里,Redis客户端的连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用,这个时候blpop和brpop或抛出异常
实战
代码
@Slf4j
@Service
public class ListRedisQueue {
//队列名
public static final String KEY = "listQueue";
@Resource
private RedisTemplate redisTemplate;
public void produce(String message) {
redisTemplate.opsForList().rightPush(KEY, message);
}
public void consume() {
while (true) {
String msg = (String) redisTemplate.opsForList().leftPop(KEY);
log.info("疯狂获取消息:" + msg);
}
}
public void blockingConsume() {
while (true) {
List测试
lPop/rPop消费数据
@Autowired
private ListRedisQueue listRedisQueue;
@Test
public void produce() {
for (int i = 0; i < 5; i++) {
listRedisQueue.produce("第"+i + "个数据");
}
}
@Test
public void consume() {
produce();
logger.info("生产消息完毕");
listRedisQueue.consume();
}输出

blpop / brpop 消费数据
@Test
public void blockingConsume() {
produce();
logger.info("生产消息完毕");
listRedisQueue.blockingConsume();
}输出

2. 基于Sorted-Set的实现延时队列
描述
其实zset就是sorted set。为了避免sorted set简写sset导致命令冲突,所以改为zset。同理例如class-->clazz
sorted set从字面意思上,很容易就可以理解,是个有序且不可重复的数据集合。类似set和hash的混合体,但是相比于set,zset内部由score进行排序.
优点
可以自定义消息ID,在消息ID有意义时,比较重要。
缺点
缺点也明显,不允许重复消息(因为是集合),同时消息ID确定有错误会导致消息的顺序出错。
实战
代码
@Slf4j
@Service
public class SortedSetRedisQueue {
//队列名
public static final String KEY = "sortedSet_queue";
@Autowired
private RedisTemplate redisTemplate;
public void produce(String msg, Double score) {
// 创建Sorted Set实例
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
// 添加数据
zSetOperations.add(KEY, msg, score);
}
public void consumer() throws InterruptedException {
// 创建SortedSet实例
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
while (true) {
// 拿取数据 (rangeByScore返回有序集合中指定分数区间的成员列表。有序集成员按分数值递增(从小到大)次序排列)
Set order = zSetOperations.rangeByScore(KEY, 0, System.currentTimeMillis(), 0, 1);
if (ObjectUtils.isEmpty(order)) {
log.info("当前没有数据 当前线程睡眠3秒");
TimeUnit.SECONDS.sleep(3);
// 跳过本次循环 重新循环拿取数据
continue;
}
// 利用迭代器拿取Set中的数据
String massage = order.iterator().next();
// 过河拆迁,拿到就删除消息
if (zSetOperations.remove(KEY, massage) > 0) {
//做些业务处理
log.info("我拿到的消息:" + massage);
}
}
}
} 测试
@Autowired
private SortedSetRedisQueue sortedSetRedisQueue;
@Test
public void sortedSetProduce() throws InterruptedException {
for (int i = 0; i < 5; i++) {
TimeUnit.SECONDS.sleep(1);
// 生成分数
double score = System.currentTimeMillis();
sortedSetRedisQueue.produce("第"+i + "个数据",score);
}
}
@Test
public void sortedSetConsumer() throws InterruptedException {
sortedSetProduce();
logger.info("生产消息完毕");
sortedSetRedisQueue.consumer();
}
}输出

3.PUB/SUB,订阅/发布模式
描述
SUBSCRIBE,用于订阅信道
PUBLISH,向信道发送消息
UNSUBSCRIBE,取消订阅
此模式允许生产者只生产一次消息,由中间件负责将消息复制到多个消息队列,每个消息队列由对应的消费组消费。
优点
一个消息可以发布到多个消费者
消费者可以同时订阅多个信道,因此可以接收多种消息(处理时先根据信道判断)
消息即时发送,消费者会自动接收到信道发布的消息
缺点
消息发布时,如果客户端不在线,则消息丢失
消费者处理消息时出现了大量消息积压,则可能会断开通道,导致消息丢失
消费者接收消息的时间不一定是一致的,可能会有差异(业务处理需要判重)
实战
监听器
@Slf4j
@Component
public class RedisMessageListenerListener implements MessageListener {
@Autowired
private RedisTemplate redisTemplate;
/**
* 消息处理
*
* @param message
* @param pattern
*/
@Override
public void onMessage(Message message, byte[] pattern) {
String channel = new String(pattern);
log.info("onMessage --> 消息通道是:{}", channel);
RedisSerializer valueSerializer = redisTemplate.getValueSerializer();
Object deserialize = valueSerializer.deserialize(message.getBody());
log.info("反序列化的结果:{}", deserialize);
if (deserialize == null) return;
String md5DigestAsHex = DigestUtils.md5DigestAsHex(deserialize.toString().getBytes(StandardCharsets.UTF_8));
log.info("计算得到的key: {}", md5DigestAsHex);
Boolean result = redisTemplate.opsForValue().setIfAbsent(md5DigestAsHex, "1", 20, TimeUnit.SECONDS);
if (Boolean.TRUE.equals(result)) {
// redis消息进行处理
log.info("接收的结果:{}", deserialize.toString());
} else {
log.info("其他服务处理中");
}
}
} 实现MessageListener 接口,就可以通过onMessage()方法接收到消息了,该方法有两个参数:
参数 message 的 getBody() 方法以二进制形式获取消息体, getChannel() 以二进制形式获取消息通道
参数 pattern 二进制形式的消息通道(实际和 message.getChannel() 返回值相同)
绑定监听器
@Configuration
public class RedisMessageListenerConfig {
@Bean
public RedisMessageListenerContainer getRedisMessageListenerContainer(RedisConnectionFactory redisConnectionFactory,
RedisMessageListenerListener redisMessageListenerListener) {
RedisMessageListenerContainer redisMessageListenerContainer = new RedisMessageListenerContainer();
redisMessageListenerContainer.setConnectionFactory(redisConnectionFactory);
redisMessageListenerContainer.addMessageListener(redisMessageListenerListener, new ChannelTopic(PubSubRedisQueue.KEY));
return redisMessageListenerContainer;
}
}RedisMessageListenerContainer 是为Redis消息侦听器 MessageListener 提供异步行为的容器。处理侦听、转换和消息分派的低级别详细信息。
本文使用的是主题订阅:ChannelTopic,你也可以使用模式匹配:PatternTopic,从而匹配多个信道。
生产者
@Service
public class PubSubRedisQueue {
//队列名
public static final String KEY = "pub_sub_queue";
@Autowired
private RedisTemplate redisTemplate;
public void produce(String message) {
redisTemplate.convertAndSend(KEY, message);
}
} 测试
@Slf4j
@RestController
@RequestMapping(value = "/queue")
public class RedisMQController {
@Autowired
private PubSubRedisQueue pubSubRedisQueue;
@RequestMapping(value = "/pubsub/produce", method = RequestMethod.GET)
public void pubsubProduce(@RequestParam(name = "msg") String msg) {
pubSubRedisQueue.produce(msg);
}随便找个浏览器请求生产者接口:
所以每插入一条消息,监听者则立即进去消费

4. 基于Stream类型的实现(Redis Version5.0)
描述
Stream为redis 5.0后新增的数据结构。支持多播的可持久化消息队列,实现借鉴了Kafka设计。
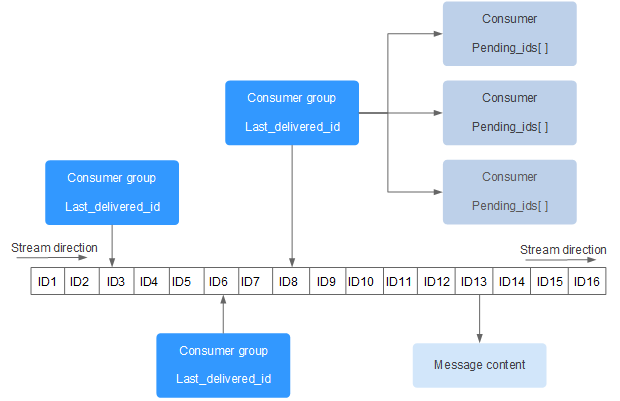
Redis Stream的结构如上图所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的ID和对应的内容。消息是持久化的,Redis重启后,内容还在。
每个Stream都有唯一的名称,它就是Redis的key,在我们首次使用xadd指令追加消息时自动创建。
每个Stream都可以挂多个消费组,每个消费组会有个游标last_delivered_id在Stream数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费组都有一个Stream内唯一的名称,消费组不会自动创建,它需要单独的指令xgroup create进行创建,需要指定从Stream的某个消息ID开始消费,这个ID用来初始化last_delivered_id变量。
每个消费组(Consumer Group)的状态都是独立的,相互不受影响。也就是说同一份Stream内部的消息会被每个消费组都消费到。
同一个消费组(Consumer Group)可以挂接多个消费者(Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id往前移动。每个消费者者有一个组内唯一名称。
消费者(Consumer)内部会有个状态变量pending_ids,它记录了当前已经被客户端读取的消息,但是还没有ack。如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack,它就开始减少。这个pending_ids变量在Redis官方被称之为PEL,也就是Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
优点
高性能:可以在非常短的时间内处理大量的消息。
持久化:支持数据持久化,即使Redis服务器宕机,也可以恢复之前的消息。
顺序性:保证消息的顺序性,即使是并发的消息也会按照发送顺序排列。
灵活性:可以方便地扩展和分布式部署,可以满足不同场景下的需求。
缺点
功能相对简单:Redis Stream相对于其他的消息队列,功能相对简单,无法满足一些复杂的需求。
不支持消息回溯:即消费者无法获取之前已经消费过的消息。
不支持多消费者分组:无法实现多个消费者并发消费消息的功能。
实战
自动ack消费者
@Slf4j
@Component
public class AutoAckStreamConsumeListener implements StreamListener> {
//分组名
public static final String GROUP = "autoack_stream";
@Autowired
private RedisTemplate redisTemplate;
@Override
public void onMessage(MapRecord message) {
String stream = message.getStream();
RecordId id = message.getId();
Map map = message.getValue();
log.info("[自动ACK]接收到一个消息 stream:[{}],id:[{}],value:[{}]", stream, id, map);
redisTemplate.opsForStream().delete(GROUP, id.getValue());
}
} 手动ack消费者
@Slf4j
@Component
public class BasicAckStreamConsumeListener implements StreamListener> {
//分组名
public static final String GROUP = "basicack_stream";
@Autowired
private RedisTemplate redisTemplate;
@Override
public void onMessage(MapRecord message) {
String stream = message.getStream();
RecordId id = message.getId();
Map map = message.getValue();
log.info("[手动ACK]接收到一个消息 stream:[{}],id:[{}],value:[{}]", stream, id, map);
redisTemplate.opsForStream().acknowledge(stream, GROUP, id.getValue());
//消费完毕删除该条消息
redisTemplate.opsForStream().delete(GROUP, id.getValue());
}
} 绑定关系
@Slf4j
@Configuration
public class RedisStreamConfiguration {
@Autowired
private RedisConnectionFactory redisConnectionFactory;
@Autowired
private AutoAckStreamConsumeListener autoAckStreamConsumeListener;
@Autowired
private BasicAckStreamConsumeListener basicAckStreamConsumeListener;
@Autowired
private RedisTemplate redisTemplate;
@Bean(initMethod = "start", destroyMethod = "stop")
public StreamMessageListenerContainer> streamMessageListenerContainer() {
AtomicInteger index = new AtomicInteger(1);
int processors = Runtime.getRuntime().availableProcessors();
ThreadPoolExecutor executor = new ThreadPoolExecutor(processors, processors, 0, TimeUnit.SECONDS,
new LinkedBlockingDeque<>(), r -> {
Thread thread = new Thread(r);
thread.setName("async-stream-consumer-" + index.getAndIncrement());
thread.setDaemon(true);
return thread;
});
StreamMessageListenerContainer.StreamMessageListenerContainerOptions> options =
StreamMessageListenerContainer.StreamMessageListenerContainerOptions
.builder()
// 一次最多获取多少条消息
.batchSize(3)
// 运行 Stream 的 poll task
.executor(executor)
// Stream 中没有消息时,阻塞多长时间,需要比 `spring.redis.timeout` 的时间小
.pollTimeout(Duration.ofSeconds(3))
// 获取消息的过程或获取到消息给具体的消息者处理的过程中,发生了异常的处理
.errorHandler(new ErrorHandler() {
@Override
public void handleError(Throwable t) {
log.info("出现异常就来这里了" + t);
}
})
.build();
StreamMessageListenerContainer> streamMessageListenerContainer =
StreamMessageListenerContainer.create(redisConnectionFactory, options);
// 独立消费
// 消费组A,自动ack
// 从消费组中没有分配给消费者的消息开始消费
if (!isStreamGroupExists(StreamRedisQueue.KEY,AutoAckStreamConsumeListener.GROUP)){
redisTemplate.opsForStream().createGroup(StreamRedisQueue.KEY,AutoAckStreamConsumeListener.GROUP);
}
streamMessageListenerContainer.receiveAutoAck(Consumer.from(AutoAckStreamConsumeListener.GROUP, "AutoAckConsumer"),
StreamOffset.create(StreamRedisQueue.KEY, ReadOffset.lastConsumed()), autoAckStreamConsumeListener);
// 消费组B,不自动ack
if (!isStreamGroupExists(StreamRedisQueue.KEY,BasicAckStreamConsumeListener.GROUP)){
redisTemplate.opsForStream().createGroup(StreamRedisQueue.KEY,BasicAckStreamConsumeListener.GROUP);
}
streamMessageListenerContainer.receive(Consumer.from(BasicAckStreamConsumeListener.GROUP, "BasicAckConsumer"),
StreamOffset.create(StreamRedisQueue.KEY, ReadOffset.lastConsumed()), basicAckStreamConsumeListener);
return streamMessageListenerContainer;
}
/**
* 判断该消费组是否存在
* @param streamKey
* @param groupName
* @return
*/
public boolean isStreamGroupExists(String streamKey, String groupName) {
RedisStreamCommands commands = redisConnectionFactory.getConnection().streamCommands();
//首先检查Stream Key是否存在,否则下面代码可能会因为尝试检查不存在的Stream Key而导致异常
if (!redisTemplate.hasKey(streamKey)){
return false;
}
//获取streamKey下的所有groups
StreamInfo.XInfoGroups xInfoGroups = commands.xInfoGroups(streamKey.getBytes());
AtomicBoolean exists= new AtomicBoolean(false);
xInfoGroups.forEach(xInfoGroup -> {
if (xInfoGroup.groupName().equals(groupName)){
exists.set(true);
}
});
return exists.get();
}
}
生产工具
@Slf4j
@Service
public class StreamRedisQueue {
//队列名
public static final String KEY = "stream_queue";
@Autowired
private RedisTemplate redisTemplate;
public String produce(Map value) {
return redisTemplate.opsForStream().add(KEY, value).getValue();
}
public void createGroup(String key, String group){
redisTemplate.opsForStream().createGroup(key, group);
}
} 测试
生产消息
@Slf4j
@RestController
@RequestMapping(value = "/queue")
public class RedisMQController {
@Autowired
private StreamRedisQueue streamRedisQueue;
@RequestMapping(value = "/stream/produce", method = RequestMethod.GET)
public void streamProduce() {
Map map = new HashMap<>();
map.put("刘德华", "大家好我是刘德华");
map.put("周杰伦", "周杰伦");
map.put("time", DateUtil.now());
String result = streamRedisQueue.produce(map);
log.info("返回结果:{}", result);
}
} 只要有消息,消费者就会消费
