C语言练习题
C语言练习题
文章目录
- C语言练习题
-
- 题目一
- 题目二
- 题目三
- 题目四
- 题目五
- 题目六
- 题目八
题目一
#include 代码运行结果:>
16
sizeof计算的是联合体的大小,联合体的大小并不是联合体成员中最大的那个,联合体也是有对齐的
在上述代码中,联合体中有两个成员,short s[7],占14字节,对齐数为1,int n,和short s[7],共用空间,对齐数为4,14字节并非联合体中最大对齐数4的整数倍,所以将对齐至16字节
题目二
#include 代码运行结果:>
12
上述问题设计结构体内存对齐
- 结构体第一个成员对齐至偏移量为0的位置
- 其他成员按照取默认对齐数与改成员的大小的较小值对齐,且对齐至整数倍
- 结构体的总大小为最大对齐数的整数倍
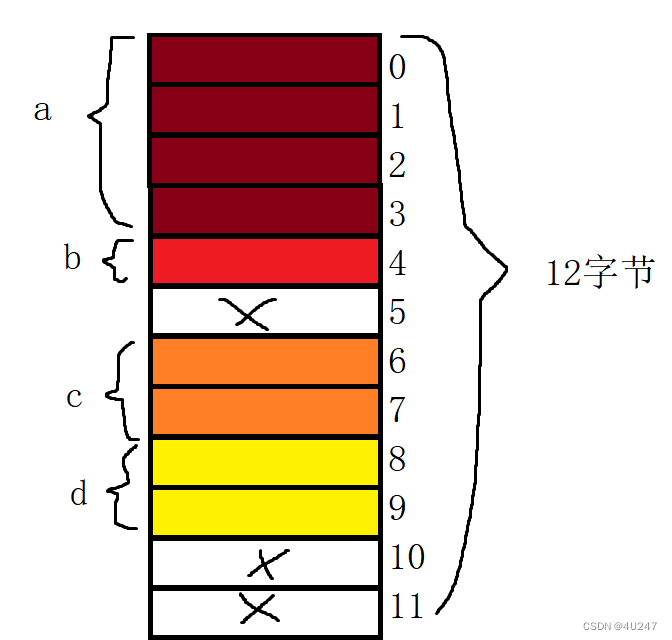
在上述代码中
a 为结构体第一个成员位于偏移量为0的位置,且占4个字节
b 的大小为1字节,默认对齐数为8,取较小值1,取对齐数1的整数倍,也就是偏移量为4的位置,占1个字节
c 的大小为2字节,默认对齐数为8,取较小值2,取对齐数2的整数倍,也就是偏移量为6的位置,占2个字节
d 的大小为2字节,默认对齐数为8,取较小值2,取对齐数2的整数倍,也就是
偏移量为8的位置,占2个字节
总大小为10字节,10字节不是最大对齐数4的倍数,对齐至12字节
题目三
#include 代码运行结果:>
12 12 16
#program是用于修改默认对齐数
#program pack(4) //修改默认对齐数
#program pack( ) //取消设置的对齐数,还原为默认对齐数
stT1

第一个成员a位于偏移量为0的位置
第二个成员b的大小为1字节,默认对齐数为4,取较小值1,对齐至1的整数倍,也就是偏移量为3的位置
第三个成员c的大小为4字节,默认对齐数为4,取较小值4,对齐至4的整数倍,也就是偏移量为4的位置
第四个成员d的大小为4字节,默认对齐数为4,取较小值4,对齐至4的整数倍,也就是偏移量为8的位置
总大小为12字节,为最大对齐数4的整数倍,所以stT1的大小为12字节
stT2

第一个成员a位于偏移量为0的位置
第二个成员b的大小为2字节,默认对齐数为4,取较小值2,对齐至2的整数倍,也就是偏移量为4的位置
第三个成员c的大小为1字节,默认对齐数为4,取较小值1,对齐至1的整数倍,也就是偏移量为6的位置
第四个成员d的大小为4字节,默认对齐数为4,取较小值4,对齐至4的整数倍,也就是偏移量为8的位置
总大小为12字节,为最大对齐数4的整数倍,所以stT2的大小为12字节
stT3

第一个成员a位于偏移量为0的位置
第二个成员b的大小为4字节,默认对齐数为4,取较小值4,对齐至4的整数倍,也就是偏移量为4的位置
第三个成员c的大小为1字节,默认对齐数为4,取较小值1,对齐至1的整数倍,也就是偏移量为8的位置
第四个成员d的大小为4字节,默认对齐数为4,取较小值4,对齐至4的整数倍,也就是偏移量为12的位置
总大小为16字节,为最大对齐数4的整数倍,所以stT2的大小为16字节
结论
相同大小的结构体成员位于不同位置,结构体的总大小不一样,建议让占⽤空间⼩的成员尽量集中在⼀起
题目四
//VS2022 X64
#define MAX_SIZE A+B
struct _Record_Struct
{
unsigned char Env_Alarm_ID : 4;
unsigned char Para1 : 2;
unsigned char state;
unsigned char avail : 1;
}*Env_Alarm_Record;
struct _Record_Struct *pointer = (struct _Record_Struct*)malloc(sizeof(struct _Record_Struct) * MAX_SIZE);
当A=2, B=3时,pointer分配( 9 )个字节的空间
解释:
#define是在C和C++中使用的预处理器指令,用于创建宏。编译器在执行代码时,会将define定义的标识符全都替换成相应的值
先计算位段的大小

冒号后的数字表示bit位,在VS2022中,位段的内存分配是从右到左的,其次遇到不够的时候,直接舍去
Env_Alarm_ID 占4个bit位,Para1 占2个bit位,第一个字节剩1个bit位不够下一个成员,舍去这一个bit位
state 占8个bit位,第二个字节分配给state使用
avail 占1个bit位,第三个字节中的一个bit位给avail 使用
总共占3个字节
sizeof(struct _Record_Struct)计算结果为8
题目给出A = 2 B = 3
sizeof(struct _Record_Struct) * MAX_SIZE 其中的 MAX_SIZE 会被替换为A + B
也就是 3 * 2 +3 ,计算结果为9
malloc为动态内存开辟,如果开辟成功则返回一个指针,开辟失败则返回一个NULL,返回的类型为void*
struct _Record_Struct *pointer = (struct _Record_Struct*)malloc(sizeof(struct _Record_Struct) * MAX_SIZE);
整句代码的意思为给pointer初始化赋值一个指针,指针指向的内容为开辟好的9字节的内存空间
题目五
在X86下,小端字节序存储
#include代码运行结果:>
3839
解释:

short 和 char i [2] 共用空间,打印的是16进制的a.k,也就是打印两个字节的内容
由于是小端存储,在低地址存放的是低位字节,高地址存放高位字节的内容,也就是倒着存放的,举例:0x11223344在内存中是 44 33 22 11
所以打印的结果为3839
题目六
enum ENUM_A
{
X1,
Y1,
Z1 = 255,
A1,
B1,
};
enum ENUM_A enumA = Y1;
enum ENUM_A enumB = B1;
printf("%d %d\n", enumA, enumB);
代码运行结果:>
1 257
枚举成员变量默认为从0开始,依次递增1
也就是说
X1 = 0
Y1 = 2
Z1 = 255
A1 = 256
B1 = 257
所以打印结果为1 257
题目八
#include 代码运行结果:>
02 29 00 00
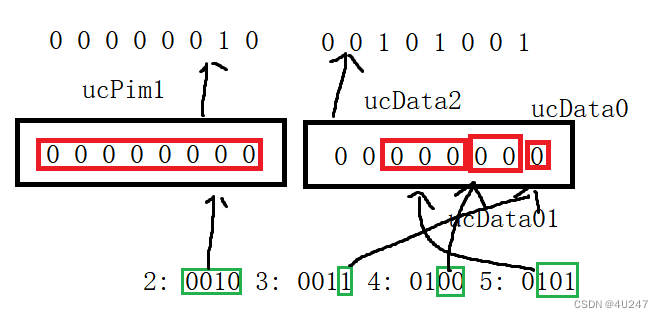
位段总共占2个字节的空间,其中ucPim1占了1个字节,ucData0 占了1个bit位,ucData1 占了2个bit位,ucData2 占了3个bit位
2 的二进制为 0010 可以全部存入 ucPim1
3 的二进制为 0011 只能存1bit位到 ucData0
4 的二进制为 0100 只能存2bit位到 ucData1
5 的二进制为 0101 只能存3bit位到 ucData2
将值存入puc数组中,且数组默认元素为0
所以
第一个字节中的内容为 0000 0010 转为16进制为 0x02
第二个字节中的内容为 0010 1001 转为16进制为 0x29
第三个字节没被修改为0
第四个字节没被修改为0
%02x打印16进制,如果小于宽度2则补0
所以打印结果为 02 29 00 00