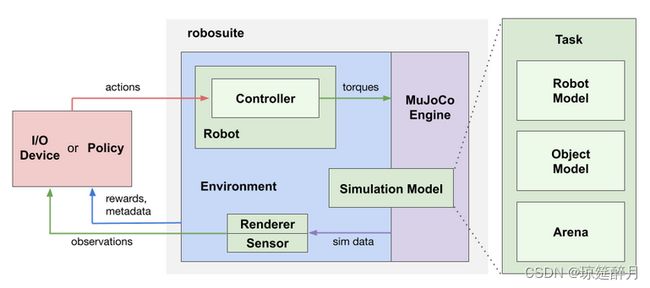
MimicGen
MimicGen
- 介绍
- 环境搭建
- 代码运行
-
- 1. 生成任务:
- 2. 训练数据:
- 3. 生成数据:
- 4. 可视化数据
- Q&A
- Appendix
-
- 1. 数据解析
-
- 数据对比
- 数据解析
-
-
- 重点数据示例:
- PT文件解析
-
- ckpt数据
-
- 场景修改
-
- 阶段一:能实现在现有简单场景中,添加标准几何物体
- 阶段二:可修改现有场景中的配置文件xml
- 阶段三:搭建新的场景
介绍
MimicGen 的作用是用来解决数据不足的问题,可用通过简单的示教少数轨迹或人物,就可以合成大量的测试数据
环境搭建
代码运行
1. 生成任务:
python generate_training_configs.py
python generate_training_configs.py --config_dir /tmp/configs --dataset_dir /tmp/datasets --output_dir /tmp/experiment_results
会生成一堆配置文件
2. 训练数据:
python /path/to/robomimic/scripts/train.py --config /path/to/mimicgen_envs/exps/paper/core/coffee_d0/image/bc_rnn.json
会生成一组pt文件,择优选择最好的即可;
3. 生成数据:
python run_trained_agent.py --agent /path/to/model.pth --n_rollouts 50 --horizon 400 --seed 0 --dataset_path /path/to/output.hdf5 --dataset_obs
生成后缀为 hdf5 的数据集
4. 可视化数据
python playback_dataset.py --dataset ./mug_cleanup_o1.hdf5 --use-actions --render_image_names agentview --video_path ./vis_object_cleanup_o1.mp4
实现将 hdf5 文件中的轨迹可视化
Q&A
- 如何实现少量数据生成大量数据的–尚未找到相关代码;
- 利用
robomimic中的train的目的是什么; - 如何将自己特定的场景作为输入;
Appendix
1. 数据解析
利用 robomimic 中的 get_dataset_info.py 分析下官方给定数据集的详细信息,首先看下 source 里面的数据,这个数据也是后期我们需要提供的原始数据:
#source/coffee,hdf5
total transitions: 2082
total trajectories: 10
traj length mean: 208.2
traj length std: 12.75774274705365
traj length min: 193
traj length max: 232
action min: -1.0
action max: 1.0
==== Filter Keys ====
filter key first_10 with 10 demos
==== Env Meta ====
{
"env_name": "Coffee_D0",
"env_version": "1.4.1",
"type": 1,
"env_kwargs": {
"has_renderer": false,
"has_offscreen_renderer": true,
"ignore_done": true,
"use_object_obs": true,
"use_camera_obs": true,
"control_freq": 20,
"controller_configs": {
"type": "OSC_POSE",
"input_max": 1,
"input_min": -1,
"output_max": [
0.05,
0.05,
0.05,
0.5,
0.5,
0.5
],
"output_min": [
-0.05,
-0.05,
-0.05,
-0.5,
-0.5,
-0.5
],
"kp": 150,
"damping": 1,
"impedance_mode": "fixed",
"kp_limits": [
0,
300
],
"damping_limits": [
0,
10
],
"position_limits": null,
"orientation_limits": null,
"uncouple_pos_ori": true,
"control_delta": true,
"interpolation": null,
"ramp_ratio": 0.2
},
"robots": [
"Panda"
],
"camera_depths": false,
"camera_heights": 84,
"camera_widths": 84,
"reward_shaping": false,
"camera_names": [
"agentview",
"robot0_eye_in_hand"
],
"render_gpu_device_id": 0
}
}
==== Dataset Structure ====
episode demo_0 with 200 transitions
key: actions with shape (200, 7)
key: dones with shape (200,)
key: obs
observation key agentview_image with shape (200, 84, 84, 3)
observation key object with shape (200, 57)
observation key robot0_eef_pos with shape (200, 3)
observation key robot0_eef_pos_rel_pod with shape (200, 3)
observation key robot0_eef_pos_rel_pod_holder with shape (200, 3)
observation key robot0_eef_quat with shape (200, 4)
observation key robot0_eef_quat_rel_pod with shape (200, 4)
observation key robot0_eef_quat_rel_pod_holder with shape (200, 4)
observation key robot0_eef_vel_ang with shape (200, 3)
observation key robot0_eef_vel_lin with shape (200, 3)
observation key robot0_eye_in_hand_image with shape (200, 84, 84, 3)
observation key robot0_gripper_qpos with shape (200, 2)
observation key robot0_gripper_qvel with shape (200, 2)
observation key robot0_joint_pos with shape (200, 7)
observation key robot0_joint_pos_cos with shape (200, 7)
observation key robot0_joint_pos_sin with shape (200, 7)
observation key robot0_joint_vel with shape (200, 7)
key: rewards with shape (200,)
key: states with shape (200, 47)
# core/coffe_preparate.hdf5
total transitions: 689273
total trajectories: 1000
traj length mean: 689.273
traj length std: 48.51659995300578
traj length min: 591
traj length max: 760
action min: -1.0
action max: 1.0
==== Filter Keys ====
no filter keys
==== Env Meta ====
{
"env_name": "CoffeePreparation_D0",
"env_version": "1.4.1",
"type": 1,
"env_kwargs": {
"has_renderer": false,
"has_offscreen_renderer": true,
"ignore_done": true,
"use_object_obs": true,
"use_camera_obs": true,
"control_freq": 20,
"controller_configs": {
"type": "OSC_POSE",
"input_max": 1,
"input_min": -1,
"output_max": [
0.05,
0.05,
0.05,
0.5,
0.5,
0.5
],
"output_min": [
-0.05,
-0.05,
-0.05,
-0.5,
-0.5,
-0.5
],
"kp": 150,
"damping": 1,
"impedance_mode": "fixed",
"kp_limits": [
0,
300
],
"damping_limits": [
0,
10
],
"position_limits": null,
"orientation_limits": null,
"uncouple_pos_ori": true,
"control_delta": true,
"interpolation": null,
"ramp_ratio": 0.2
},
"robots": [
"Panda"
],
"camera_depths": false,
"camera_heights": 84,
"camera_widths": 84,
"render_gpu_device_id": 0,
"reward_shaping": false,
"camera_names": [
"agentview",
"robot0_eye_in_hand"
]
}
}
==== Dataset Structure ====
episode demo_0 with 673 transitions
key: actions with shape (673, 7)
key: dones with shape (673,)
key: obs
observation key agentview_image with shape (673, 84, 84, 3)
observation key object with shape (673, 86)
observation key robot0_eef_pos with shape (673, 3)
observation key robot0_eef_pos_rel_pod with shape (673, 3)
observation key robot0_eef_pos_rel_pod_holder with shape (673, 3)
observation key robot0_eef_quat with shape (673, 4)
observation key robot0_eef_quat_rel_pod with shape (673, 4)
observation key robot0_eef_quat_rel_pod_holder with shape (673, 4)
observation key robot0_eef_vel_ang with shape (673, 3)
observation key robot0_eef_vel_lin with shape (673, 3)
observation key robot0_eye_in_hand_image with shape (673, 84, 84, 3)
observation key robot0_gripper_qpos with shape (673, 2)
observation key robot0_gripper_qvel with shape (673, 2)
observation key robot0_joint_pos with shape (673, 7)
observation key robot0_joint_pos_cos with shape (673, 7)
observation key robot0_joint_pos_sin with shape (673, 7)
observation key robot0_joint_vel with shape (673, 7)
key: rewards with shape (673,)
key: states with shape (673, 62)
数据对比
| 文件名 | source | core |
|---|---|---|
| demo数量 | 10 | 1000 |
| trajs | 10 | 10 |
| 轨迹采样点 | 不定600-800 | 不定 |
| 点表示 | 未知 | 未知 |
轨迹点实例:
ipdb> f['data']['demo_4']['actions'][1]
>> array([-0.00477523, 0.25546803, -0.08610821, -0.00303893, 0.03876611, -0.02707935, -1.])
ipdb> len(f['data']['demo_4']['actions'])
>> 711
轨迹点示例如下:

数据对照:
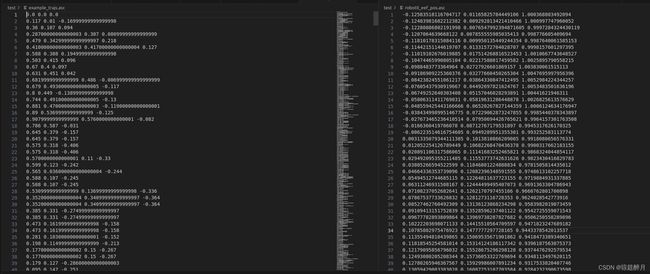
数据解析
hdf5 数据结构如下:
数据域如下
-data
-- attr: env_args
-- attr: total
-- demo_0 # n 组
--- attr: model_file
--- arrt: num_samples # 676
--- actions # 676 * 7
--- dones # 0/1
--- rewards # 0/1
--- states # 676 * 62
--- obs
---- agentview_image
---- object # 676 * 86
---- robot0_eef_pos # 676 * 3
---- robot0_eef_pos_rel_pod # 676 * 3
---- robot0_eef_pos_rel_pod_holder # 676 * 3
---- robot0_eef_quat
---- robot0_eef_quat_rel_pod
---- robot0_eef_quat_rel_pod_holder
---- robot0_eef_vel_ang
---- robot0_eef_vel_lin
---- robot0_eye_in_hand_image
---- robot0_gripper_qpos
---- robot0_gripper_qvel
---- robot0_joint_pos
---- robot0_joint_pos_cos
---- robot0_joint_pos_sin
---- robot0_joint_vel
-mask
-- first_10
重点数据示例:
env_args的内容如下:
![]()
demo/model_file的内容如下:
\n
\n
\n
\n
\n
\n \n \n \n \n \n \n '
PT文件解析
policy 信息
============= Loaded Policy =============
ObservationKeyToModalityDict: mean not found, adding mean to mapping with assumed low_dim modality!
ObservationKeyToModalityDict: scale not found, adding scale to mapping with assumed low_dim modality!
ObservationKeyToModalityDict: logits not found, adding logits to mapping with assumed low_dim modality!
BC_RNN_GMM (
ModuleDict(
(policy): RNNGMMActorNetwork(
action_dim=7, std_activation=softplus, low_noise_eval=True, num_nodes=5, min_std=0.0001
encoder=ObservationGroupEncoder(
group=obs
ObservationEncoder(
Key(
name=agentview_image
shape=[3, 84, 84]
modality=rgb
randomizer=CropRandomizer(input_shape=[3, 84, 84], crop_size=[76, 76], num_crops=1)
net=VisualCore(
input_shape=[3, 76, 76]
output_shape=[64]
backbone_net=ResNet18Conv(input_channel=3, input_coord_conv=False)
pool_net=SpatialSoftmax(num_kp=32, temperature=1.0, noise=0.0)
)
sharing_from=None
)
Key(
name=robot0_eef_pos
shape=[3]
modality=low_dim
randomizer=None
net=None
sharing_from=None
)
Key(
name=robot0_eef_quat
shape=[4]
modality=low_dim
randomizer=None
net=None
sharing_from=None
)
Key(
name=robot0_eye_in_hand_image
shape=[3, 84, 84]
modality=rgb
randomizer=CropRandomizer(input_shape=[3, 84, 84], crop_size=[76, 76], num_crops=1)
net=VisualCore(
input_shape=[3, 76, 76]
output_shape=[64]
backbone_net=ResNet18Conv(input_channel=3, input_coord_conv=False)
pool_net=SpatialSoftmax(num_kp=32, temperature=1.0, noise=0.0)
)
sharing_from=None
)
Key(
name=robot0_gripper_qpos
shape=[2]
modality=low_dim
randomizer=None
net=None
sharing_from=None
)
output_shape=[137]
)
)
rnn=RNN_Base(
(per_step_net): ObservationDecoder(
Key(
name=mean
shape=(5, 7)
modality=low_dim
net=(Linear(in_features=1000, out_features=35, bias=True))
)
Key(
name=scale
shape=(5, 7)
modality=low_dim
net=(Linear(in_features=1000, out_features=35, bias=True))
)
Key(
name=logits
shape=(5,)
modality=low_dim
net=(Linear(in_features=1000, out_features=5, bias=True))
)coffee_preparation_d0
)
(nets): LSTM(137, 1000, num_layers=2, batch_first=True)
)
)
)
)
ckpt数据
keys = dict_keys(['model', 'config', 'algo_name', 'env_metadata', 'shape_metadata'])
model 部分局部截图,推测为 policy 中用到的具体参数
config 为训练时指定的 json 内容,详细数据如下:
'{\n "algo_name": "bc",\n "experiment": {\n "name": "core_coffee_preparation_d0_image",\n "validate": false,\n "logging": {\n "terminal_output_to_txt": true,\n "log_tb": true,\n "log_wandb": false,\n "wandb_proj_name": "debug"\n },\n "save": {\n "enabled": true,\n "every_n_seconds": null,\n "every_n_epochs": 20,\n "epochs": [],\n "on_best_validation": false,\n "on_best_rollout_return": false,\n "on_best_rollout_success_rate": true\n },\n "epoch_every_n_steps": 500,\n "validation_epoch_every_n_steps": 50,\n "env": null,\n "additional_envs": null,\n "render": false,\n "render_video": true,\n "keep_all_videos": false,\n "video_skip": 5,\n "rollout": {\n "enabled": true,\n "n": 50,\n "horizon": 800,\n "rate": 20,\n "warmstart": 0,\n "terminate_on_success": true\n }\n },\n "train": {\n "data": "/home/idm/Documents/mimicgen/mimicgen_environments/mimicgen_envs/../datasets/core/coffee_preparation_d0.hdf5",\n "output_dir": "/home/idm/Documents/mimicgen/mimicgen_environments/mimicgen_envs/../training_results/core/coffee_preparation_d0/image/trained_models",\n "num_data_workers": 2,\n "hdf5_cache_mode": "low_dim",\n "hdf5_use_swmr": true,\n "hdf5_load_next_obs": false,\n "hdf5_normalize_obs": false,\n "hdf5_filter_key": null,\n "hdf5_validation_filter_key": null,\n "seq_length": 10,\n "pad_seq_length": true,\n "frame_stack": 1,\n "pad_frame_stack": true,\n "dataset_keys": [\n "actions",\n "rewards",\n "dones"\n ],\n "goal_mode": null,\n "cuda": true,\n "batch_size": 128,\n "num_epochs": 600,\n "seed": 1\n },\n "algo": {\n "optim_params": {\n "policy": {\n "optimizer_type": "adam",\n "learning_rate": {\n "initial": 0.0001,\n "decay_factor": 0.1,\n "epoch_schedule": [],\n "scheduler_type": "multistep"\n },\n "regularization": {\n "L2": 0.0\n }\n }\n },\n "loss": {\n "l2_weight": 1.0,\n "l1_weight": 0.0,\n "cos_weight": 0.0\n },\n "actor_layer_dims": [],\n "gaussian": {\n "enabled": false,\n "fixed_std": false,\n "init_std": 0.1,\n "min_std": 0.01,\n "std_activation": "softplus",\n "low_noise_eval": true\n },\n "gmm": {\n "enabled": true,\n "num_modes": 5,\n "min_std": 0.0001,\n "std_activation": "softplus",\n "low_noise_eval": true\n },\n "vae": {\n "enabled": false,\n "latent_dim": 14,\n "latent_clip": null,\n "kl_weight": 1.0,\n "decoder": {\n "is_conditioned": true,\n "reconstruction_sum_across_elements": false\n },\n "prior": {\n "learn": false,\n "is_conditioned": false,\n "use_gmm": false,\n "gmm_num_modes": 10,\n "gmm_learn_weights": false,\n "use_categorical": false,\n "categorical_dim": 10,\n "categorical_gumbel_softmax_hard": false,\n "categorical_init_temp": 1.0,\n "categorical_temp_anneal_step": 0.001,\n "categorical_min_temp": 0.3\n },\n "encoder_layer_dims": [\n 300,\n 400\n ],\n "decoder_layer_dims": [\n 300,\n 400\n ],\n "prior_layer_dims": [\n 300,\n 400\n ]\n },\n "rnn": {\n "enabled": true,\n "horizon": 10,\n "hidden_dim": 1000,\n "rnn_type": "LSTM",\n "num_layers": 2,\n "open_loop": false,\n "kwargs": {\n "bidirectional": false\n }\n },\n "transformer": {\n "enabled": false,\n "context_length": 10,\n "embed_dim": 512,\n "num_layers": 6,\n "num_heads": 8,\n "emb_dropout": 0.1,\n "attn_dropout": 0.1,\n "block_output_dropout": 0.1,\n "sinusoidal_embedding": false,\n "activation": "gelu",\n "supervise_all_steps": false,\n "nn_parameter_for_timesteps": true\n }\n },\n "observation": {\n "modalities": {\n "obs": {\n "low_dim": [\n "robot0_eef_pos",\n "robot0_eef_quat",\n "robot0_gripper_qpos"\n ],\n "rgb": [\n "agentview_image",\n "robot0_eye_in_hand_image"\n ],\n "depth": [],\n "scan": []\n },\n "goal": {\n "low_dim": [],\n "rgb": [],\n "depth": [],\n "scan": []\n }\n },\n "encoder": {\n "low_dim": {\n "core_class": null,\n "core_kwargs": {},\n "obs_randomizer_class": null,\n "obs_randomizer_kwargs": {}\n },\n "rgb": {\n "core_class": "VisualCore",\n "core_kwargs": {\n "feature_dimension": 64,\n "backbone_class": "ResNet18Conv",\n "backbone_kwargs": {\n "pretrained": false,\n "input_coord_conv": false\n },\n "pool_class": "SpatialSoftmax",\n "pool_kwargs": {\n "num_kp": 32,\n "learnable_temperature": false,\n "temperature": 1.0,\n "noise_std": 0.0\n }\n },\n "obs_randomizer_class": "CropRandomizer",\n "obs_randomizer_kwargs": {\n "crop_height": 76,\n "crop_width": 76,\n "num_crops": 1,\n "pos_enc": false\n }\n },\n "depth": {\n "core_class": "VisualCore",\n "core_kwargs": {},\n "obs_randomizer_class": null,\n "obs_randomizer_kwargs": {}\n },\n "scan": {\n "core_class": "ScanCore",\n "core_kwargs": {},\n "obs_randomizer_class": null,\n "obs_randomizer_kwargs": {}\n }\n }\n },\n "meta": {\n "hp_base_config_file": null,\n "hp_keys": [],\n "hp_values": []\n }\n}'
env_meta内容如下,来源于训练数据中的env_args:
{'env_name': 'CoffeePreparation_D0', 'env_version': '1.4.1', 'type': 1, 'env_kwargs': {'has_renderer': False, 'has_offscreen_renderer': True, 'ignore_done': True, 'use_object_obs': True, 'use_camera_obs': True, 'control_freq': 20, 'controller_configs': {'type': 'OSC_POSE', 'input_max': 1, 'input_min': -1, 'output_max': [0.05, 0.05, 0.05, 0.5, 0.5, 0.5], 'output_min': [-0.05, -0.05, -0.05, -0.5, -0.5, -0.5], 'kp': 150, 'damping': 1, 'impedance_mode': 'fixed', 'kp_limits': [0, 300], 'damping_limits': [0, 10], 'position_limits': None, 'orientation_limits': None, 'uncouple_pos_ori': True, 'control_delta': True, 'interpolation': None, 'ramp_ratio': 0.2}, 'robots': ['Panda'], 'camera_depths': False, 'camera_heights': 84, 'camera_widths': 84, 'render_gpu_device_id': 0, 'reward_shaping': False, 'camera_names': ['agentview', 'robot0_eye_in_hand']}}
shape_meta 主要表示大小,详细内容如下:
ipdb> ckpt_dict['shape_metadata']
{'ac_dim': 7, 'all_shapes': OrderedDict([('agentview_image', [3, 84, 84]), ('robot0_eef_pos', [3]), ('robot0_eef_quat', [4]), ('robot0_eye_in_hand_image', [3, 84, 84]), ('robot0_gripper_qpos', [2])]), 'all_obs_keys': ['agentview_image', 'robot0_eef_pos', 'robot0_eef_quat', 'robot0_eye_in_hand_image', 'robot0_gripper_qpos'], 'use_images': True}
场景修改
阶段一:能实现在现有简单场景中,添加标准几何物体



阶段二:可修改现有场景中的配置文件xml
阶段三:搭建新的场景