大数据生态圈及分布式文件系统HDFS实践-part1
Hadoop入门
第一章 大数据概述
1.1 大数据概念
“人类正在从IT时代走向DT时代”。
大数据(Big Data):指的是传统数据处理应用软件不足以处理(存储和计算)它们的大而复杂的数据集。
主要解决,海量数据的存储和海量数据的运算问题。

1.2 大数据特征

容量大,种类多,速度快,价值高
1、容量(Volume):数据的大小决定所考虑的数据的价值和潜在的信息
微博,5 亿用户,每天上亿条微博
朋友圈,10亿用户,每天亿级别朋友圈
2、种类(Variety):数据类型的多样性,包括文本,图片,视频,音频
结构化数据:可以用二维数据库表来抽象,抽取数据规律
半结构化数据:介于结构化和非结构化之间,主要指 XML,HTML 等,也可称非结构化
非结构化数据:不可用二维表抽象,比如图片,图像,音频,视频等
3、速度(Velocity):指获得数据的速度以及处理数据的速度
数据的产生呈指数式爆炸式增长
处理数据要求的延时越来越低
4、价值(Value):合理运用大数据,以低成本创造高价值
综合价值大,隐含价值大
单条数据记录无价值,无用数据多
1.3 大数据应用场景
1、物流

2、零售

3、旅游

4、商业推荐

5、“新基建”

1.4 大数据部门的一般业务流程

1.5 大数据部门的一般组织架构

第二章 Hadoop及大数据生态圈
2.1 Hadoop产生背景
1、Hadoop 最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题 ——如何解决数十亿网页的存储和索引问题
Doug Cutting Lucene
2、2003 -2004年谷歌发表的三篇论文为该问题提供了可行的解决方案
- 1、分布式文件系统 GFS,可用于处理海量网页的存储
GFS HDFS
- 2、分布式计算框架 MapReduce,可用于处理海量网页的索引计算问题
MapReduce MapReduce
- 3、分布式数据库 BigTable,每一张表可以存储上 billions 行和 millions 列
BigTable HBase
3、Nutch的开发人员完成了相应的开源实现HDFS 和 MapReduce,并从Nutch中剥离成为独立项目Hadoop,到 2008 年 1 月,Hadoop 成为Apache 顶级项目,迎来了它的快速发展期。
2.2 什么是Hadoop?
1、Hadoop 是 Apache 旗下的一套开源软件平台
2、Hadoop 提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
存储+运算(调度)
3、Hadoop 的核心组件有:
- A.Common(基础功能组件)
- B.HDFS(Hadoop Distributed File System 分布式文件系统)
- C.YARN(Yet Another Resources Negotiator 运算资源调度系统)
- D.MapReduce(Map 和 Reduce 分布式运算编程框架)
4、广义上来说,Hadoop 通常是指一个更广泛的概念–Hadoop 生态圈
5、官网介绍:http://hadoop.apache.org/

2.3 Hadoop发行版本
Hadoop 三大发行版本: Apache、Cloudera、Hortonworks
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera公司:Cloudera产品主要为CDH,Cloudera Manager。兼容性,安全性,稳定性上较强。
Hortonworks公司:Hortonworks Data Platform(HDP),可以使用安装和管理系统Ambari进行统一安装和管理监控。


2.4 Hadoop就业情况
到各大招聘网站上面看看。
第三章 分布式集群的安装与部署
详见单独的安装文档和视频
在课前的时候已经分发给大家啦
在安装的过程中,大家可以给官网中的默认配置文件ctrl+s保存到本地,方便后续调优的时候查找参数。
第四章 Hadoop运行演示
4.1 官方WordCount案例
1、创建一个wcinput文件夹,注意是在hdfs上面创建,不是在本地创建

2、在本地任意文件夹下面创建文件并上传到hdfs上面,我这里是在本地的/home/data目录下面创建的wordcount.txt



3、任意目录下运行官方wordcount程序
官方案例的路径为:/software/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar
编写的时候注意路径不要写错了!注意是HDFS上面的路径。
hadoop jar /software/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /wcinput /wcoutput
4、去hdfs上面查看

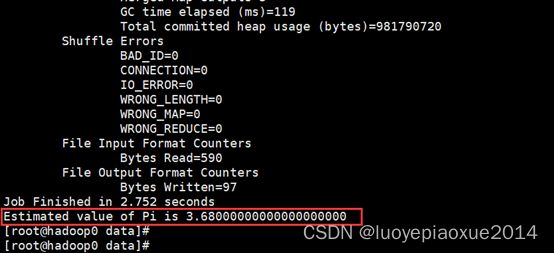
4.2 官方求圆周率π案例
1、任意目录直接运行即可
hadoop jar /software/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar pi 5 5 //pi + map数量 + reduce数量
2、查看结果
声明:
文章中代码为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361 点击打开链接
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接