leptjson 02学习笔记
重构
TDD 中的一个步骤──重构(refactoring),重构是一个这样的过程:
在不改变代码外在行为的情况下,对代码作出修改,以改进程序的内部结构。
在 TDD 的过程中,我们的目标是编写代码去通过测试。由于这个目标的引导性太强,我们可能会忽略正确性以外的软件品质。在通过测试之后,代码的正确性得以保证,我们就应该审视现时的代码,看看有没有地方可以改进,而同时能维持测试顺利通过。我们可以安心地做各种修改,因为我们有单元测试,可以判断代码在修改后是否影响原来的行为。
那么,哪里要作出修改?Beck 和 Fowler([1] 第 3 章)认为程序员要培养一种判断能力,找出程序中的坏味道。例如,在第一单元的练习中,可能大部分人都会复制 lept_parse_null() 的代码,作一些修改,成为 lept_parse_true() 和lept_parse_false()。如果我们再审视这 3 个函数,它们非常相似。这违反编程中常说的 DRY(don't repeat yourself)原则。
尝试合并三个parse为一个
static int lept_parse_literal(lept_context* c, lept_value* v,
const char* literal, lept_type type) {
size_t i;
EXPECT(c, literal[0]);
for(i = 0; literal[i + 1]; i++)
if(c->json[i] != literal[i + 1])
return LEPT_PARSE_INVALID_VALUE;
c->json += i;
v->type = type;
return LEPT_PARSE_OK;
}JSON的数字语法
number = [ "-" ] int [ frac ] [ exp ]
int = "0" / digit1-9 *digit
frac = "." 1*digit
exp = ("e" / "E") ["-" / "+"] 1*digit
number 是以十进制表示,它主要由 4 部分顺序组成:负号、整数、小数、指数。只有整数是必需部分。注意和直觉可能不同的是,正号是不合法的。
整数部分如果是 0 开始,只能是单个 0;而由 1-9 开始的话,可以加任意数量的数字(0-9)。也就是说,0123 不是一个合法的 JSON 数字。
小数部分比较直观,就是小数点后是一或多个数字(0-9)。
JSON 可使用科学记数法,指数部分由大写 E 或小写 e 开始,然后可有正负号,之后是一或多个数字(0-9)。

strtod详解
std::strtof, std::strtod, std::strtold
c语言strtod()函数详解
理解代码
static int lept_parse_number(lept_context* c, lept_value* v) {
const char* p = c->json;
if (*p == '-') p++;
if (*p == '0') p++;
else {
if (!ISDIGIT1TO9(*p)) return LEPT_PARSE_INVALID_VALUE;
for (p++; ISDIGIT(*p); p++);
}
if (*p == '.') {
p++;
if (!ISDIGIT(*p)) return LEPT_PARSE_INVALID_VALUE;
for (p++; ISDIGIT(*p); p++);
}
if (*p == 'e' || *p == 'E') {
p++;
if (*p == '+' || *p == '-') p++;
if (!ISDIGIT(*p)) return LEPT_PARSE_INVALID_VALUE;
for (p++; ISDIGIT(*p); p++);
}
errno = 0;
v->n = strtod(c->json, NULL);
if (errno == ERANGE && (v->n == HUGE_VAL || v->n == -HUGE_VAL))
return LEPT_PARSE_NUMBER_TOO_BIG;
v->type = LEPT_NUMBER;
c->json = p;
return LEPT_PARSE_OK;
}这段代码对我这种水平理解起来还就有点困难,不过也是花了一点时间理解了。
从test.c入手
static void test_parse_invalid_value() {
/* invalid number */
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "+0");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "+1");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, ".123"); /* at least one digit before '.' */
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "1."); /* at least one digit after '.' */
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "INF");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "inf");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "NAN");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "nan");
}
static void test_parse_root_not_singular() {
TEST_ERROR(LEPT_PARSE_ROOT_NOT_SINGULAR, "null x");
/* invalid number */
TEST_ERROR(LEPT_PARSE_ROOT_NOT_SINGULAR, "0123"); /* after zero should be '.' or nothing */
TEST_ERROR(LEPT_PARSE_ROOT_NOT_SINGULAR, "0x0");
TEST_ERROR(LEPT_PARSE_ROOT_NOT_SINGULAR, "0x123");
TEST_ERROR(LEPT_PARSE_ROOT_NOT_SINGULAR, "0m");
TEST_ERROR(LEPT_PARSE_ROOT_NOT_SINGULAR, "0.5k6");
TEST_ERROR(LEPT_PARSE_ROOT_NOT_SINGULAR, "00");
}因为strtod是符合json格式的字符串能转换,不符合json格式的也能转换。所以我们需要对其进行解析剔除掉不符合json格式的字符串,即使它可以正确被strtod解析出来。
比如这个"0123",我们发现即使有前导0的存在仍可以被正确解析,如下图。但这不符合上面所提到的json的数字语法。
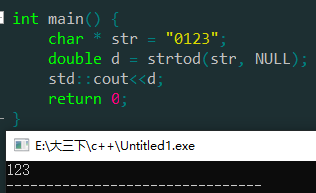
因为是只能是十进制,所以以0x前缀的16进制也不行。
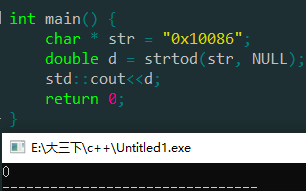
含字符的。
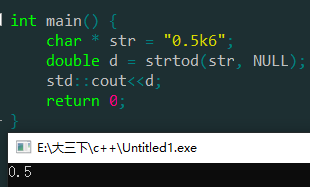
总而言之,我们不能通过strtod进行格式判断,因为strtod来者不拒。所以我们在strtod之前进行字符串解析。
const char* p = c->json;
if (*p == '-') p++;
if (*p == '0') p++;
else {
if (!ISDIGIT1TO9(*p)) return LEPT_PARSE_INVALID_VALUE;
for (p++; ISDIGIT(*p); p++);
}用一个指针p来进行遍历。先判断第一个是否是'-',如果是则跳过。
下面这几行基本上是判断第一个字符是不是数字,如果是"+0",".123","INF","nan"这类就会直接返回LEPT_PARSE_INVALID_VALUE。
if (*p == '.') {
p++;
if (!ISDIGIT(*p)) return LEPT_PARSE_INVALID_VALUE;
for (p++; ISDIGIT(*p); p++);
}这几行是用来判断小数点之后是否至少有一个数字,比如"1."就会报错。
if (*p == 'e' || *p == 'E') {
p++;
if (*p == '+' || *p == '-') p++;
if (!ISDIGIT(*p)) return LEPT_PARSE_INVALID_VALUE;
for (p++; ISDIGIT(*p); p++);
}这几行是用来判断指数的
按理来说,应该所有的格式不正确都是返回的LEPT_PARSE_INVALID_VALUE,但是包含前导的错误并不是这样。原作者在判断整数部分为0时默认将它认为是一个0。所以含有前导0的错误并不会在这几行解析出来。比如"0123",他可以正常通过lept_parse_number()并返回LEPT_PARSE_OK。
c->json已经变成了p指针所指向的位置,按理说如果这只是单个0,p应该指向'\0',但是p并没有指向'\0',而是指向了1(在'0123'情况下。所以在lept_parse_value()解析完后,在lept_parse()中判断LEPT_PARSE_ROOT_NOT_SINGULAR的情况时才可以发现这是一个含有前导0的错误。故在test.c中使用LEPT_PARSE_ROOT_NOT_SINGULAR来测试。
int lept_parse(lept_value* v, const char* json) {
lept_context c;
int ret;
assert(v != NULL);
c.json = json;
v->type = LEPT_NULL;
lept_parse_whitespace(&c);
if ((ret = lept_parse_value(&c, v)) == LEPT_PARSE_OK) {
lept_parse_whitespace(&c);
if (*c.json != '\0') {
v->type = LEPT_NULL;
ret = LEPT_PARSE_ROOT_NOT_SINGULAR;
}
}
return ret;
}同样这也可以判断0后面加字符之类的错误,如"0m","0.5k6",都是一个逻辑,strtod正常通过,但是p不指向'\0',报LEPT_PARSE_ROOT_NOT_SINGULAR错误。
超出范围
见std::strtof, std::strtod, std::strtold返回值
成功时为对应 str 内容的浮点值。若转换出的值落在对应返回类型的范围外,则发生值域错误并返回 HUGE_VAL 、 HUGE_VALF 或 HUGE_VALL 。若无法进行转换,则返回 0 并将 *str_end 设为 str 。
改进
不知道算不算改进,就是将上文解释的前导0进行修改,将LEPT_PARSE_ROOT_NOT_SINGULAR错误修改成为LEPT_PARSE_INVALID_VALUE错误。
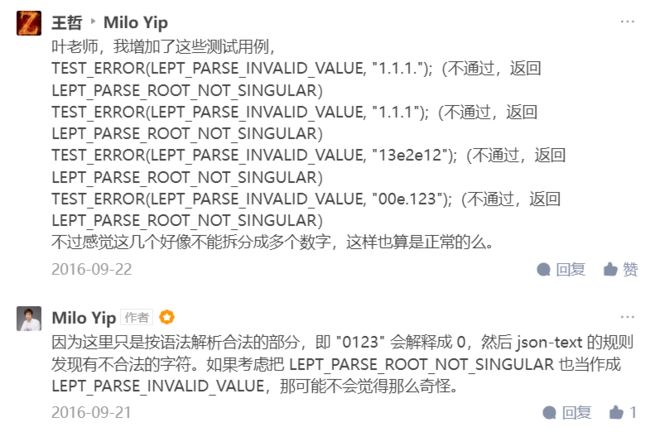
按照TDD的思想,我首先把这一部分移至test_parse_invalid_value(),并将错误改成LEPT_PARSE_INVALID_VALUE。
/* invalid number */
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "0123"); /* after zero should be '.' or nothing */
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "0x0");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "0x123");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "0m");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "0.5k6");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "00");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "1.1.1.");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "1.1.1");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "13e2e12");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "00e.123");
多定义了一部分宏
#define EXPECT_EQ(equality, except, actual)\
do {\
if (equality)\
return actual;\
else {\
ret = actual;\
}\
} while(0)
#define ISLEPT_PARSE_OK(except, actual) EXPECT_EQ((except) == (actual), except, actual)修改后的lept_parse_value()。
static int lept_parse_value(lept_context* c, lept_value* v) {
int flag, ret;
flag = 0;
lept_parse_whitespace(c);
switch (*c->json) {
case 't': {
ret = lept_parse_literal(c, v, "true", LEPT_TRUE);
ISLEPT_PARSE_OK(LEPT_PARSE_INVALID_VALUE, ret);break;
}//这里不写一起是因为lept_parse_literal会执行两遍。
case 'f': {
ret = lept_parse_literal(c, v, "false", LEPT_FALSE);
ISLEPT_PARSE_OK(LEPT_PARSE_INVALID_VALUE, ret);break;
}
case 'n': {
ret = lept_parse_literal(c, v, "null", LEPT_NULL);
ISLEPT_PARSE_OK(LEPT_PARSE_INVALID_VALUE, ret); break;
}
default : {
flag = 1;
ret = lept_parse_number(c, v);
ISLEPT_PARSE_OK(LEPT_PARSE_NUMBER_TOO_BIG, ret); break;
//这里用宏的原因是return LEPT_PARSE_NUMBER_TOO_BIG后,p不会赋值给c->json
//p不会赋值给c->json,所以p不会是'\0'
//会执行下面的lept_parse_whitespace(),返回错误的错误号。
lept_parse_whitespace()
break;
}
case '\0': ret = LEPT_PARSE_EXPECT_VALUE;
}
lept_parse_whitespace(c);
if (*c->json != '\0') {
v->type = LEPT_NULL;
if(flag == 1) return LEPT_PARSE_INVALID_VALUE;
return LEPT_PARSE_ROOT_NOT_SINGULAR;
}
return ret;
}修改后的lept_parse()
int lept_parse(lept_value* v, const char* json) {
lept_context c;
int ret;
assert(v != NULL);
c.json = json;
v->type = LEPT_NULL;
ret = lept_parse_value(&c, v);
return ret;
}效果:不符合JSON格式的数字都会返回LEPT_PARSE_INVALID_VALUE,上面名为“王哲”的网友测试用例也可以通过。
个人也觉得全是LEPT_PARSE_INVALID_VALUE比较自然,所以进行了修改。

写宏之后debug是真难受。
水平较低,若有错误,请斧正。