Redis学习笔记
参考链接
https://c.biancheng.net/redis/
https://redis.io/commands/
系统命令(macOS)
# 启动redis
brew services start redis
# 停止redis
brew services stop redis
# 重启redis
brew services restart redis
常用命令
在redis-cli中执行的命令
# 验证密码
AUTH 123456
# 打印字符串
ECHO message
# 查看服务是否运行正常
PING
# 关闭当前连接
QUIT
# 获取 Redis 服务器的各种信息和统计数值。
INFO [section]
# 返回当前数据库中 key 的数量。
DBSIZE
# 清空数据库中的所有键。
FLUSHALL
# 清空当前数据库的所有 key。
FLUSHDB
# 返回最近一次 Redis 成功将数据保存到磁盘上的时间,以 UNIX 格式表示。
LASTSAVE
# 查看主从实例所属的角色,角色包括三种,分别是 master、slave、sentinel。
ROLE
# 执行数据同步操作,将 Redis 数据库中的所有数据以 RDB 文件的形式保存到磁盘中。
SAVE
# 将数据同步到磁盘后,然后关闭服务器。
SHUTDOWN [NOSAVE] [SAVE]
# 此命令用于设置主从服务器,使当前服务器转变成为指定服务器的从属服务器,
# 或者将其提升为主服务器(执行 SLAVEOF NO ONE 命令)。
SLAVEOF host port
# 用来记录查询执行时间的日志系统。
SLOWLOG subcommand [argument]
# 用于同步主从服务器。
SYNC
# 切换到指定的数据库 0-15
127.0.0.1:6379[1]> SELECT 0
OK
# 查看key的类型
127.0.0.1:6379> type user:1
hash
# 删除键
127.0.0.1:6379> del string
# 设置key过期时间 expire key 秒数
# dump 将key做序列化处理
127.0.0.1:6379> dump key1
"\x00\x04val1\n\x00\x14\x95\x13\x9eD\x9f\xd4w"
# exists 判断key是否存在
127.0.0.1:6379> exists key1
(integer) 1
127.0.0.1:6379> expire string 10
# 毫秒级别的过期时间命令则在命令前加字母p
127.0.0.1:6379> pexpire string 10000
# 设置key过期时间 expireat key 时间戳(秒)
127.0.0.1:6379> expireat string 1700072630
# 在创建key时也可以通过ex参数指定过期时间
127.0.0.1:6379> set key1 val1 ex 100
# 查看剩余过期时间, -1表示无过期时间
127.0.0.1:6379> ttl key1
# 删除过期时间
127.0.0.1:6379> persist key1
# 修改key名称,参数1是原key名称,参数2是新的key名称
127.0.0.1:6379> renamenx key1 key2
# 查看所有key,线上环境禁止使用,查询会消耗大量资源影响稳定
127.0.0.1:6379> keys *
# 查找命令支持通配符模糊匹配
127.0.0.1:6379> keys s*
1) "set"
2) "string"
# move 将key移动到指定的库,范围0-15
127.0.0.1:6379> move key1 1
(integer) 1
# RANDOMKEY 随机返回一个key
127.0.0.1:6379> randomkey
# scan 查找key,参数0代表起始游标,match代表匹配内容,支持通配符,type代表类型
# 相似的命令有 SSCAN、HSCAN、ZSCAN,它们分别用于迭代集合、哈希散列与有序结合
scan 0 match li* type list
配置文件 redis.conf 位置(macOS)
# 配置文件路径在终端使用命令查看,如果有密码则加参数-a再带上密码,例如-a password
redis-cli info | grep config_file
redis-cli -a password info | grep config_file
# 从终端进入cli的命令
redis-cli
# 从cli中获取本地数据库存放目录
config get dir
设置密码
在配置文件(redis.conf)中修改:
# 打开这一行的注释,将foobared改为自己想设置的密码,然后重启。
requirepass foobared
Redis数据类型
值的五种类型:
- string 字符串
- hash 哈希散列
- list 列表
- set 集合
- zset 有序集合
string 字符串
二进制安全,最多能够存储 512 MB 的内容。
相关命令:
# 一次操作一个key
127.0.0.1:6379> set string "value"
OK
# setnx 设置key值,如果有key存在时则设置失败。
127.0.0.1:6379> setnx string "v1"
(integer) 0
# append 追加值
127.0.0.1:6379> append string 1
(integer) 6
127.0.0.1:6379> get string
"value1"
# strlen 获取字符串长度
127.0.0.1:6379> strlen string
(integer) 6
# getrange 获取指定范围内的子串
127.0.0.1:6379> getrange string 1 4
"alue"
# getset 获取旧值并把值设置为指定的新值
127.0.0.1:6379> getset string val1
"value1"
# setrange 用指定子串覆盖给定偏移量的字符串
127.0.0.1:6379> setrange string 3 12345
(integer) 8
# mset 一次设置多个key
127.0.0.1:6379> mset a1 "123" a2 "456"
OK
# msetnx 批量设置多个key,如果有某个key存在时则设置失败。
127.0.0.1:6379> msetnx a1 "123" a3 "789"
(integer) 0
# mget 获取多个key的值
127.0.0.1:6379> mget a1 a2
1) "123"
2) "456"
# 删除操作
127.0.0.1:6379> del a1 a2
(integer) 2
数值类型
用于记录点赞、关注、评论等等类似的数值类场景。数值范围是 64 位的有符号整型( -9223372036854775808 至 9223372036854775807)
相关命令:
# incr 做数值+1操作,若key不存在则自动创建
127.0.0.1:6379> incr like:10010
(integer) 1
# decr 做数值-1操作,若key不存在则自动创建
127.0.0.1:6379> decr like:10010
(integer) 0
# incrby 按指定数值增加操作,若key不存在则自动创建
127.0.0.1:6379> incrby like:10010 5
(integer) 5
# decrby 按指定数值减去操作,若key不存在则自动创建
127.0.0.1:6379> decrby like:10010 3
(integer) 2
# incrbyfloat float数值运算,正负数对应加减,注意有精度问题。
127.0.0.1:6379> incrbyfloat like:10010 0.5
"2.5"
127.0.0.1:6379> incrbyfloat like:10010 -0.2
"2.29999999999999982"
hash 哈希散列
可以理解为包含了多个键值对的集合,一般用来存对象。一个 Hash 中最多包含 2^32-1 个键值对(大约40亿个)
相关命令:
# hset 同时设置多个字段。hmset命令在4.0.0版本后已弃用。
127.0.0.1:6379> hset user:1 id 1 name test1 age 11
OK
# 查询全部字段
127.0.0.1:6379> hgetall user:1
1) "id"
2) "1"
3) "name"
4) "test1"
5) "age"
6) "11"
# hdel 删除字段
127.0.0.1:6379> hdel user:1 name age
(integer) 2
# hexists 判断是否存在指定字段,存在则返回1,否则返回0
127.0.0.1:6379> hexists user:1 id
(integer) 1
# hget 获取指定字段值
127.0.0.1:6379> hget user:1 id
"1"
# hincrby 字段值加减指定值,必须是数值
127.0.0.1:6379> hincrby user:1 id 2
(integer) 3
127.0.0.1:6379> hincrby user:1 id -2
(integer) 1
# 返回
127.0.0.1:6379> hlen user:1
(integer) 1
# hset 设置指定字段值
127.0.0.1:6379> hset user:1 id 2
(integer) 0
# hvals 返回所有字段值
127.0.0.1:6379> hvals user:1
1) "2"
list 列表
其中元素是字符串类型,按插入顺序排列,允许重复。最多包含2^32 -1 个(大约40亿个)。插入时可制定添加到头部或尾部。列表类型同样遵循索引机制。
相关命令:
# lpush 从左侧头部添加元素
127.0.0.1:6379> lpush list a1
(integer) 1
127.0.0.1:6379> lpush list a2
(integer) 2
127.0.0.1:6379> lpush list a3
(integer) 3
127.0.0.1:6379> lpush list a4
(integer) 4
# 可重复插入相同数据
127.0.0.1:6379> lpush list a4
(integer) 5
# rpush 从右侧尾部添加元素
127.0.0.1:6379> rpush list a0
(integer) 6
# linsert 指定元素前后插入数据,before(前)|after(后)
127.0.0.1:6379> linsert list after a2 a1.5
(integer) 7
127.0.0.1:6379> linsert list before a2 a2.5
(integer) 8
# lpop 从左侧弹出元素,加参数可指定弹出数量
127.0.0.1:6379> lpop list 2
1) "a4"
2) "a4"
# rpop 从右侧弹出元素,加参数可指定弹出数量
127.0.0.1:6379> rpop list
"a0"
# lrange命令查看指定范围list数据,根据插入顺序排列。
# 第二参数用-1、-2则代表倒数第一、第二以此类推,用来查询全部数据
127.0.0.1:6379> lrange list 0 -1
1) "a3"
2) "a2.5"
3) "a2"
4) "a1.5"
5) "a1"
# lpushx、rpushx与lpush、rpush类似,但只有在key存在时才会添加数据
127.0.0.1:6379> lpushx list2 a1
(integer) 0
127.0.0.1:6379> rpushx list2 a1
(integer) 0
# lrem 删除列表指定数量的指定值元素
# count > 0:从头部往尾部搜索,删除指定元素,数量为count
# count < 0:从尾部往头部搜索,删除指定元素,数量为count的绝对值
# count = 0:移除所有与指定值相等的值
127.0.0.1:6379> lrem list -2 a3
(integer) 1
# lset 将指定索引的value设置成指定值
127.0.0.1:6379> lset list 0 a3
OK
# rpoplpush 从列表1中的尾部取出元素,再插入到列表2的头部。
# brpoplpush 在rpoplpush基础上增加阻塞,第三个参数指定超时时间
127.0.0.1:6379> rpoplpush list list2
"a1"
# blpop、brpop与lpop、rpop类似,但增加了阻塞,第三个参数指定超时时间
127.0.0.1:6379> blpop list 10
1) "list"
2) "a3"
# lindex 返回指定index的值
127.0.0.1:6379> lindex list 0
"a2"
# llen 返回列表长度
127.0.0.1:6379> llen list
(integer) 2
# ltrim 将指定范围外的元素都删除
127.0.0.1:6379> ltrim list 0 3
OK
set 集合
是字符串类型元素构成的无序集合,元素不允许重复。基于哈希映射表实现。最多包含2^32 -1 个(大约40亿个)。
相关命令:
# sadd 添加元素
127.0.0.1:6379> sadd set s1
(integer) 1
127.0.0.1:6379> sadd set s2
(integer) 1
127.0.0.1:6379> sadd set s3
(integer) 1
# 添加成功则返回 1,如果元素已经存在,则返回 0
127.0.0.1:6379> sadd set s3
(integer) 0
127.0.0.1:6379> sadd set s4
(integer) 1
127.0.0.1:6379> sadd set s5
(integer) 1
127.0.0.1:6379> sadd set s6
(integer) 1
# smembers获取集合数据,无序排列
127.0.0.1:6379> smembers set
1) "s2"
2) "s1"
3) "s6"
4) "s3"
5) "s4"
6) "s5"
# scard 获取set中的元素数量
127.0.0.1:6379> scard set
(integer) 6
# sdiff 查询第一个set与其他set的差集
127.0.0.1:6379> sadd set2 s1
(integer) 1
127.0.0.1:6379> sadd set2 s2
(integer) 1
127.0.0.1:6379> sadd set2 s3
(integer) 1
127.0.0.1:6379> sdiff set set2
1) "s4"
2) "s6"
3) "s5"
# sdiffstore 查出set与set2的差集并存储到set3中
127.0.0.1:6379> sdiffstore set3 set set2
(integer) 3
127.0.0.1:6379> smembers set3
1) "s4"
2) "s6"
3) "s5"
# sinter 查出两个set的交集
127.0.0.1:6379> sinter set set2
1) "s3"
2) "s1"
3) "s2"
# sinterstore 查出两个set的交集并存储到set4中
127.0.0.1:6379> sinterstore set4 set set2
(integer) 3
127.0.0.1:6379> smembers set4
1) "s1"
2) "s3"
3) "s2"
# smove 将set4中的元素s1移动到set3
127.0.0.1:6379> smove set4 set3 s1
(integer) 1
127.0.0.1:6379> smembers set3
1) "s1"
2) "s4"
3) "s6"
4) "s5"
# spop 随机删除一个元素
127.0.0.1:6379> spop set3
"s6"
# srandmember 从set3随机返回2个参数,没有删除操作
127.0.0.1:6379> srandmember set3 2
1) "s1"
2) "s5"
# srem 删除set3中的一个(也可以多个)元素
127.0.0.1:6379> srem set3 s5
(integer) 1
# sunion 返回两个set中的所有元素,去重
127.0.0.1:6379> smembers set2
1) "s3"
2) "s1"
3) "s2"
127.0.0.1:6379> smembers set3
1) "s1"
2) "s4"
127.0.0.1:6379> sunion set2 set3
1) "s4"
2) "s1"
3) "s3"
4) "s2"
# sunionstore 将两个set中的所有元素去重并存储到set5中
127.0.0.1:6379> sunionstore set5 set2 set3
(integer) 4
127.0.0.1:6379> smembers set5
1) "s4"
2) "s1"
3) "s3"
4) "s2"
zset 有序集合
是字符串类型元素构成的有序集合,元素不允许重复,并且每个元素关联double 类型的分数,根据分数值排序,分数值允许重复。
相关命令:
# zadd 添加元素和分值
127.0.0.1:6379> zadd zset 0 a1
(integer) 1
# 相同的分值允许重复
127.0.0.1:6379> zadd zset 1 a2
(integer) 1
127.0.0.1:6379> zadd zset 1 a3
(integer) 1
# 相同的元素不允许重复,即使分值不同
127.0.0.1:6379> zadd zset 1 a3
(integer) 0
127.0.0.1:6379> zadd zset 2 a3
(integer) 0
127.0.0.1:6379> zadd zset 2 a4
(integer) 1
# zscore 查看分数
127.0.0.1:6379> zscore zset a2
"1"
# zrank 按分数从小到大排序,查看元素的分数排名
127.0.0.1:6379> zrank zset a3
(integer) 2
# zrevrank 与zrank相反,分数从大到小排序
127.0.0.1:6379> zrevrank zset a3
(integer) 1
# zrange 查看指定范围元素值,按从小到大排序。
# 第二参数用-1、-2则代表倒数第一、第二以此类推,用来查询全部数据
# withscores 代表同时返回分数
127.0.0.1:6379> zrange zset 0 4 withscores
1) "a1"
2) "0"
3) "a2"
4) "1"
5) "a3"
6) "1"
7) "a4"
8) "2"
# (1 2 byscore 代表 1< score <=2 的区间
# REV 代表倒序排序, 使用rev参数时区间要对调。3>=score>1
# [limit offset count] 从offset的位置开始查,返回数量为count。
# zrange zset 3 1 rev byscore
127.0.0.1:6379> zadd zset 3 a5
127.0.0.1:6379> zrange zset 3 1 rev byscore withscores limit 0 2
1) "a5"
2) "3"
3) "a4"
4) "2"
# zcard 返回zset中的数据量
127.0.0.1:6379> zcard zset
(integer) 4
# zcount 返回zset中分数值在0与1间的元素的数量
127.0.0.1:6379> zcount zset 0 1
(integer) 3
# zincrby 对zset中的a4元素的分值做增量操作,提供负数则是减去
127.0.0.1:6379> zincrby zset -1 a4
"1"
# zinter 找到两个集合中的交集(相同的元素),不指定AGGREGATE时默认将分数相加
# weights 有几个key就设几个,默认值是1,代表调用aggregate参数前会把分数值分别乘以
# 对应的weights,aggregate有min、sum、max三种,分别是最小,相加,最大的分数。
# withscores参数在输出时会一起输出分数
127.0.0.1:6379> zadd zset2 1 a2 1 a3
(integer) 2
127.0.0.1:6379> zinter 2 zset zset2 weights 2 2 aggregate sum withscores
1) "a2"
2) "4"
3) "a3"
4) "4"
# zinterstore 将zinter的结果存储到zset3中去
127.0.0.1:6379> zinterstore zset3 2 zset zset2 weights 2 2 aggregate sum
(integer) 2
# zrem 删除元素
127.0.0.1:6379> zrem zset a5
(integer) 1
# zremrangebyrank key start stop 删除指定区间的元素, start\stop是索引
127.0.0.1:6379> zremrangebyrank zset 0 1
(integer) 2
# zremrangebyscore key min max 删除指定区间的元素, min\max是分数
# ZUNION numkeys key [key ...] [WEIGHTS weight [weight ...]]
# [AGGREGATE ] [WITHSCORES]
# zunion 获取两个zset的并集,weights参数为各自要做乘法加权的权重,
# aggregate默认是sum,有三种min、sum、max分别代表最小、总和、最大
# withscores 代表返回时带分数
127.0.0.1:6379> zunion 2 zset zset2 weights 1 1 aggregate sum withscores
1) "a1"
2) "0"
3) "a2"
4) "2"
5) "a3"
6) "2"
7) "a4"
8) "2"
# zunionstore 与zunion类似,加了个存储返回值到zset3的操作
127.0.0.1:6379> zunionstore zset3 2 zset zset2 weights 1 1 aggregate sum
(integer) 4
bitmap 位图操作
主要用来存取大量的bool类型数据。如签到,日活等数据。用二进制数据表示
相关命令:
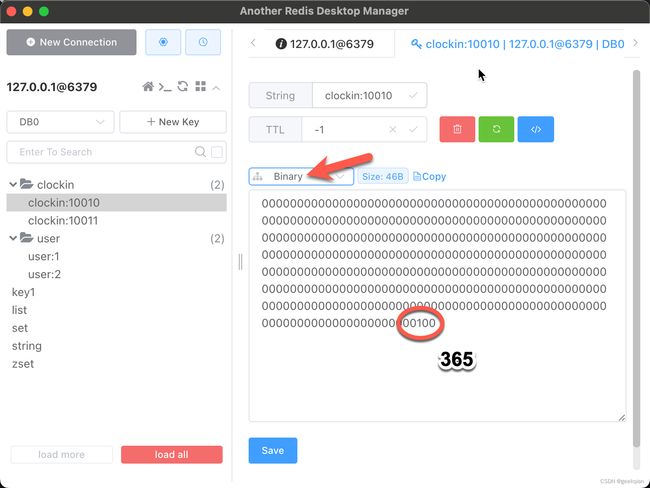
# 例子:setbit命令设置id为10010的用户第365天签到数据为1
# id为10011的用户第180天签到数据为1
127.0.0.1:6379> setbit clockin:10010 365 1
(integer) 0
127.0.0.1:6379> setbit clockin:10011 180 1
(integer) 0
# getbit 获取指定位的值
127.0.0.1:6379> getbit clockin:10010 365
(integer) 1
127.0.0.1:6379> getbit clockin:10011 180
(integer) 1
127.0.0.1:6379> exists abc
(integer) 0
# key不存在也会返回0
127.0.0.1:6379> getbit abc 1
(integer) 0
# bitcount 计算给定区间内有多少个值为1的位
127.0.0.1:6379> bitcount clockin:10010 0 365
(integer) 1
HyperLoglog 基数统计
HyperLoglog 是 Redis 重要的数据类型之一,它非常适用于海量数据的计算、统计,其特点是占用空间小,计算速度快。典型使用场景是统计网站用户日、月活量或网站页面的UV(网站独立访客),数据会有 0.81%的标准误差。
相关命令:
# pfadd 添加数据
127.0.0.1:6379> pfadd websize:uv:20231122 uid1 uid2 uid3
(integer) 1
# 重复数据无法添加
127.0.0.1:6379> pfadd websize:uv:20231122 uid1 uid2
(integer) 0
# pfcount 统计key中有多少数据
127.0.0.1:6379> pfcount websize:uv:20231122
(integer) 3
# pfmerge 合并两个key,自动去重
127.0.0.1:6379> pfadd websize:uv:20231123 uid2 uid3 uid4
(integer) 1
127.0.0.1:6379> pfmerge websize:uv:20231122-23 websize:uv:20231122 websize:uv:20231123
OK