【AIGCode】让AI生成随机数据
用户测试数据库性能,SQL性能等。
交互流程:
假如我的表结构是:
CREATE TABLE prd_article_inf (
ARTICLE_INF_ID int(11) NOT NULL AUTO_INCREMENT,
ARTICLE_AUTHOR varchar(24) DEFAULT NULL,
ARTICLE_BRIEF varchar(255) DEFAULT NULL,
ARTICLE_CATEGORY_ID int(11) DEFAULT NULL,
ARTICLE_CONT longblob NOT NULL,
ARTICLE_COVER_PICT_ID int(11) DEFAULT NULL,
ARTICLE_POSITION int(11) NOT NULL,
ARTICLE_SOURCE varchar(128) DEFAULT NULL,
ARTICLE_TAG varchar(255) DEFAULT NULL,
ARTICLE_TITLE varchar(64) NOT NULL,
BROWSE_TIMES int(11) DEFAULT NULL,
CONT_ATTACHMENT_FILE_IDS varchar(128) DEFAULT NULL,
EXTERNAL_LINK varchar(255) DEFAULT NULL,
IF_RELEASE varchar(1) DEFAULT NULL,
IF_SYS_RESERVE varchar(2) NOT NULL,
META_DESCR varchar(255) DEFAULT NULL,
META_KEYWORDS varchar(255) DEFAULT NULL,
META_TITLE varchar(128) DEFAULT NULL,
RELEASE_TIME datetime DEFAULT NULL,
RELEASE_USER_ID int(11) DEFAULT NULL,
PRIMARY KEY (ARTICLE_INF_ID)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
帮我写一个python脚本,写一个能给这个结构表随机插入10万条数据的脚本,假设本地MYSQL数据库名为my_test,访问用户和密码都为test文心一言生成的有错误,通义千问的生成正确:
首先,你需要确保你已经安装了Python的MySQL连接库(如:mysql-connector-python)。如果没有,请使用以下命令进行安装:
bash
pip install mysql-connector-python
然后,你可以使用以下脚本来生成并插入随机数据到你的数据库中:
python
import random
import string
import mysql.connector
from datetime import datetime, timedelta
# 连接数据库
cnx = mysql.connector.connect(user='test', password='test',
host='localhost',
database='my_test')
# 创建一个游标对象
cursor = cnx.cursor()
# 定义一些函数来生成随机数据
def generate_string(length):
return ''.join(random.choice(string.ascii_letters) for _ in range(length))
def generate_datetime(start_date, end_date):
time_between_dates = end_date - start_date
days_between_dates = time_between_dates.days
random_number_of_days = random.randrange(days_between_dates)
return start_date + timedelta(days=random_number_of_days)
# 生成10万条随机数据并插入到数据库中
for _ in range(100000):
article_author = generate_string(24)
article_brief = generate_string(255)
article_category_id = random.randint(1, 1000)
article_cont = b'\x00' * random.randint(100, 10000) # 随机二进制内容
article_cover_pict_id = random.randint(1, 1000)
article_position = random.randint(1, 1000)
article_source = generate_string(128)
article_tag = generate_string(255)
article_title = generate_string(64)
browse_times = random.randint(1, 100000)
cont_attachment_file_ids = generate_string(128)
external_link = generate_string(255)
if_release = random.choice(['Y', 'N'])
if_sys_reserve = random.choice(['Y', 'N'])
meta_descr = generate_string(255)
meta_keywords = generate_string(255)
meta_title = generate_string(128)
release_time = generate_datetime(datetime(2020, 1, 1), datetime.now())
release_user_id = random.randint(1, 1000)
query = ("INSERT INTO prd_article_inf "
"(ARTICLE_AUTHOR, ARTICLE_BRIEF, ARTICLE_CATEGORY_ID, ARTICLE_CONT, ARTICLE_COVER_PICT_ID, ARTICLE_POSITION, ARTICLE_SOURCE, "
"ARTICLE_TAG, ARTICLE_TITLE, BROWSE_TIMES, CONT_ATTACHMENT_FILE_IDS, EXTERNAL_LINK, IF_RELEASE, IF_SYS_RESERVE, META_DESCR, "
"META_KEYWORDS, META_TITLE, RELEASE_TIME, RELEASE_USER_ID) "
"VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)")
data = (article_author, article_brief, article_category_id, article_cont, article_cover_pict_id, article_position,
article_source, article_tag, article_title, browse_times, cont_attachment_file_ids, external_link,
if_release, if_sys_reserve, meta_descr, meta_keywords, meta_title, release_time, release_user_id)
cursor.execute(query, data)
# 提交事务
cnx.commit()
# 关闭游标和连接
cursor.close()
cnx.close()
这个脚本会生成10万条随机数据并将其插入到名为prd_article_inf的表中。请注意,这个脚本可能需要一些时间才能完成运行,具体取决于你的系统性能。
但是执行效率还是会比较低,直接询问AI进行优化:
优化一下上面算法优化后还是不错的,只要在循环里加入个百分比输出就差不多了
为了提高脚本的性能,我们可以考虑批量插入数据,而不是每次插入一条数据。以下是一个优化后的版本:
python
import random
import string
import mysql.connector
from datetime import datetime, timedelta
# 连接数据库
cnx = mysql.connector.connect(user='test', password='test',
host='localhost',
database='my_test')
# 创建一个游标对象
cursor = cnx.cursor()
# 定义一些函数来生成随机数据
def generate_string(length):
return ''.join(random.choice(string.ascii_letters) for _ in range(length))
def generate_datetime(start_date, end_date):
time_between_dates = end_date - start_date
days_between_dates = time_between_dates.days
random_number_of_days = random.randrange(days_between_dates)
return start_date + timedelta(days=random_number_of_days)
# 生成10万条随机数据并插入到数据库中
data_list = []
for _ in range(100000):
article_author = generate_string(24)
article_brief = generate_string(255)
article_category_id = random.randint(1, 1000)
article_cont = b'\x00' * random.randint(100, 10000) # 随机二进制内容
article_cover_pict_id = random.randint(1, 1000)
article_position = random.randint(1, 1000)
article_source = generate_string(128)
article_tag = generate_string(255)
article_title = generate_string(64)
browse_times = random.randint(1, 100000)
cont_attachment_file_ids = generate_string(128)
external_link = generate_string(255)
if_release = random.choice(['Y', 'N'])
if_sys_reserve = random.choice(['Y', 'N'])
meta_descr = generate_string(255)
meta_keywords = generate_string(255)
meta_title = generate_string(128)
release_time = generate_datetime(datetime(2020, 1, 1), datetime.now())
release_user_id = random.randint(1, 1000)
data = (article_author, article_brief, article_category_id, article_cont, article_cover_pict_id, article_position,
article_source, article_tag, article_title, browse_times, cont_attachment_file_ids, external_link,
if_release, if_sys_reserve, meta_descr, meta_keywords, meta_title, release_time, release_user_id)
data_list.append(data)
if len(data_list) == 1000: # 每次插入1000条数据
query = ("INSERT INTO prd_article_inf "
"(ARTICLE_AUTHOR, ARTICLE_BRIEF, ARTICLE_CATEGORY_ID, ARTICLE_CONT, ARTICLE_COVER_PICT_ID, ARTICLE_POSITION, ARTICLE_SOURCE, "
"ARTICLE_TAG, ARTICLE_TITLE, BROWSE_TIMES, CONT_ATTACHMENT_FILE_IDS, EXTERNAL_LINK, IF_RELEASE, IF_SYS_RESERVE, META_DESCR, "
"META_KEYWORDS, META_TITLE, RELEASE_TIME, RELEASE_USER_ID) "
"VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)")
cursor.executemany(query, data_list)
cnx.commit()
data_list.clear()
# 插入剩余的数据(如果有的话)
if len(data_list) > 0:
query = ("INSERT INTO prd_article_inf "
"(ARTICLE_AUTHOR, ARTICLE_BRIEF, ARTICLE_CATEGORY_ID, ARTICLE_CONT, ARTICLE_COVER_PICT_ID, ARTICLE_POSITION, ARTICLE_SOURCE, "
"ARTICLE_TAG, ARTICLE_TITLE, BROWSE_TIMES, CONT_ATTACHMENT_FILE_IDS, EXTERNAL_LINK, IF_RELEASE, IF_SYS_RESERVE, META_DESCR, "
"META_KEYWORDS, META_TITLE, RELEASE_TIME, RELEASE_USER_ID) "
"VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)")
cursor.executemany(query, data_list)
cnx.commit()
data_list.clear()
# 关闭游标和连接
cursor.close()
cnx.close()
这个脚本会一次性插入1000条数据,从而减少了数据库操作的次数,提高了插入速度。
跑出来的结果还是不错的: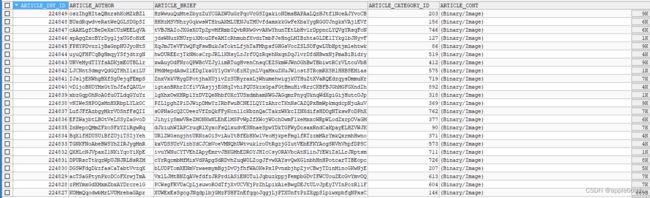
根据这个思路,我们还可以根据要求让AI生成的一对多子表的信息,类似方式