block层IO调度器 (deadline调度算法) linux内核源码详解
本文是笔者在之前写过的一篇 《iostat IO统计原理linux内核源码分析----基于单通道SATA》盘基础上,对IO传输过程涉及的IO请求的合并、加入IO算法队列、从IO算法队列派发IO请求、deadline调度算法涉及的linux内核源码,做更深层次的探讨,内核版本3.10.96。更详细的源码注释见https://github.com/dongzhiyan-stack/kernel-code-comment。
跟上篇一样,开头先来个IO传输的入口函数submit_bio->generic_make_request->blk_queue_bio流程图。
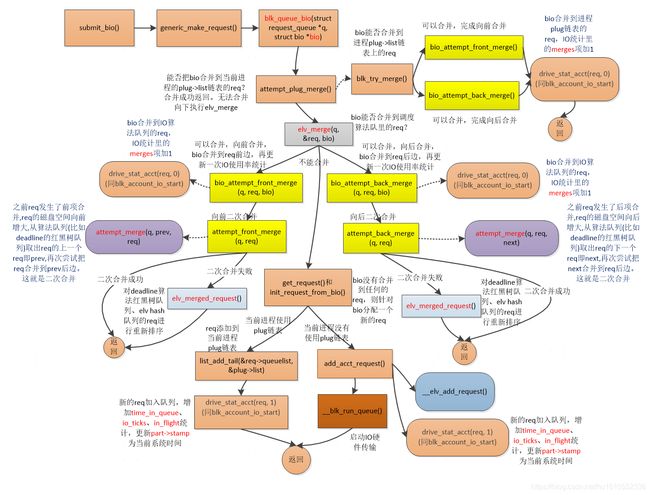
本文正式开讲前,先说几点,rq和req都是同一个意思,都代表IO请求struct request结构。流程图中的虚线代表进入一个新的函数。
1 blk_queue_bio函数IO请求的合并
1.1 bio的合并
1 blk_queue_bio()函数中,首先尝试能否将bio合并到进程plug->list链表上的req,合并成功直接返回。
2 接着执行elv_merge()函数尝试看能否将bio合并到IO算法队列里的req,如果可以合并则执行bio_attempt_front_merge()/bio_attempt_back_merge()将bio前项/后项到匹配的req。这个req合并bio后,req扇区起始/结束地址增大。接着需再尝试将req合并到其他req,就是req的二次合并,具体是执行attempt_front_merge()/attempt_back_merge()函数进行前项/后项二次req合并。如果二次合并失败,则执行elv_merged_request():因为req发生了前项或者后项合并,req的扇区起始或者结束地址增大,需要把req从hash队列或者调度算法deadline红黑树队列中剔除,再按照req新的扇区起始或者结束地址插入队列
3 如果bio没找到能合并的req,就需要get_request()分配新的req,然后调用__elv_add_request()函数把新分配的req添加到IO算法队列。
1.1.1 elv_merge函数讲解
先看下流程图

/*尝试3次合并:1 bio能否前项或者后项合并到q->last_merge;2 bio能否后项合并到hash队列的req;3:bio能否前项合并到deadline调度算法红黑树队列的req,返回值ELEVATOR_BACK_MERGE或ELEVATOR_FRONT_MERGE。如果三者都不能合并只有返回ELEVATOR_NO_MERGE。*/
- int elv_merge(struct request_queue *q, struct request **req, struct bio *bio)
- {
- struct elevator_queue *e = q->elevator;
- struct request *__rq;
- int ret;
- //是否可以把bio合并到q->last_merge,上次rq队列合并过的rq,elv_rq_merge_ok是做一些权限检查啥的
- if (q->last_merge && elv_rq_merge_ok(q->last_merge, bio)) {
- //检查bio和q->last_merge代表的req磁盘范围是否挨着,挨着则可以合并bio到q->last_merge,分为前项合并和后项合并
- ret = blk_try_merge(q->last_merge, bio);
- if (ret != ELEVATOR_NO_MERGE) {
- *req = q->last_merge;
- return ret;
- }
- }
- /*新加入IO调度队列的req会做hash索引,这是根据bio的扇区起始地址在hash表找匹配的req:遍历hash队列req,如果该req的扇区结束地址等于bio的扇区起始地址,bio可以后项合并到req*/
- __rq = elv_rqhash_find(q, bio->bi_sector);
- if (__rq && elv_rq_merge_ok(__rq, bio)) {
- *req = __rq;
- return ELEVATOR_BACK_MERGE;//找到可以合并的req,这里返回ELEVATOR_BACK_MERGE,表示后项合并
- }
- //具体IO调度算法函数cfq_merge或者deadline_merge,找到可以合并的bio的req,这里是把bio前项合并到req
- if (e->type->ops.elevator_merge_fn)
- /*deadline是在红黑树队列里遍历req,如果该req起始扇区地址等于bio的扇区结束地址,返回前项合并(bio合并到req的前边)。req是个双重指针,保存这个红黑树队列里匹配到的req*/
- return e->type->ops.elevator_merge_fn(q, req, bio);//返回ELEVATOR_FRONT_MERGE,前项合并
- return ELEVATOR_NO_MERGE;
- }
1.1.2 bio_attempt_front_merge、bio_attempt_back_merge函数讲解
bio_attempt_front_merge()/bio_attempt_back_merge()函数的源码比较简单,就是bio前项/后项合并到req,简单看下二者的源码。
//req和bio二者磁盘范围挨着,req向前合并本次的bio,合并成功返回真
- static bool bio_attempt_front_merge(struct request_queue *q,
- struct request *req, struct bio *bio)
- {
- const int ff = bio->bi_rw & REQ_FAILFAST_MASK;
- bio->bi_next = req->bio;
- req->bio = bio;
- req->buffer = bio_data(bio);//该bio对应的bh的内存page地址
- //req->__sector代表的磁盘空间起始地址=bio->bi_sector.显然req代表的磁盘空间范围向前扩张
- req->__sector = bio->bi_sector;
- req->__data_len += bio->bi_size; //req扇区范围向前增大
- req->ioprio = ioprio_best(req->ioprio, bio_prio(bio));
- drive_stat_acct(req, 0);
- return true;
- }
- //req和bio二者磁盘范围挨着,req向后合并本次的bio,合并成功返回真
- static bool bio_attempt_back_merge(struct request_queue *q, struct request *req,
- struct bio *bio)
- {
- const int ff = bio->bi_rw & REQ_FAILFAST_MASK;
- req->biotail->bi_next = bio;
- req->biotail = bio;
- //req->__sector没变,但是req->__data_len累加本次的bio磁盘范围bio->bi_size
- req->__data_len += bio->bi_size;
- req->ioprio = ioprio_best(req->ioprio, bio_prio(bio));
- //IO合并后,更改IO使用率等数据
- drive_stat_acct(req, 0);
- return true;
- }
1.1.3 attempt_front_merge()、attempt_back_merge()、attempt_merge()源码讲解
attempt_front_merge()/attempt_back_merge()函数都是调用attempt_merge()函数,如下:
//之前req发生了前项合并,req的磁盘空间向前增大,从算法队列(比如deadline的红黑树队列)取出req的上一个req即prev,再次尝试把req合并到prev后边
- int attempt_front_merge(struct request_queue *q, struct request *rq)
- {
- //红黑树中取出req原来的前一个req,即prev
- struct request *prev = elv_former_request(q, rq);
- if (prev)//把req合并到prev,然后把req从算法队列剔除掉,做一些剔除req的收尾处理,并更新IO使用率数据
- return attempt_merge(q, prev, rq);
- return 0;
- }
- //之前req发生了后项合并,req的磁盘空间向后增大,从算法队列(比如deadline的红黑树队列)取出req的下一个req即next,再次尝试把next合并到req后边
- int attempt_back_merge(struct request_queue *q, struct request *rq)
- {
- //只是从IO调度算法队列里取出req的下一个req给next,调用的函数elv_rb_latter_request(deadline算法)或noop_latter_request(noop算法)
- struct request *next = elv_latter_request(q, rq);
- if (next)//把next合并到req,然后把next从算法队列剔除掉,做一些剔除next的收尾处理,并更新IO使用率数据
- return attempt_merge(q, rq, next);
- //如果req没有next req,只能返回0
- return 0;
- }
下边现在重点看下attempt_merge()的流程图和源码实现。

- static int attempt_merge(struct request_queue *q, struct request *req,
- struct request *next)//把next合并到req后边,req来自比如q->last_merge或hash队列的req
- {
- //检查req扇区范围后边紧挨着next,没有紧挨着返回0
- if (blk_rq_pos(req) + blk_rq_sectors(req) != blk_rq_pos(next))
- return 0;
- //在这里更新req->nr_phys_segments,扇区总数,因为要把next合并到req后边吧
- if (!ll_merge_requests_fn(q, req, next))
- return 0;
- if (time_after(req->start_time, next->start_time))//如果next->start_time更小则赋值于req->start_time
- req->start_time = next->start_time;
- //一个req对应了多个bio,req->biotail应该是指向next上的第一个bio吧
- req->biotail->bi_next = next->bio;
- //biotail貌似指向了next的最后一个bio
- req->biotail = next->biotail;
- //req吞并了next的磁盘空间范围
- req->__data_len += blk_rq_bytes(next);
- /*调用IO调度算法的elevator_merge_req_fn回调函数。在这里,next已经合并到了rq,在fifo队列里,把req移动到next节点的位置,更新req的超时时间。从fifo队列和红黑树剔除next,还更新dd->next_rq[]赋值next的下一个req。因为rq合并了next,扇区结束地址变大了,则rq从hash队列中删除掉再重新再hash中排序*/
- elv_merge_requests(q, req, next);
- //next合并打了req,没用了,这个next从in flight队列剔除掉,顺便执行part_round_stats更新io_ticks IO使用率计数
- blk_account_io_merge(next);
- //req优先级,cfq调度算法的概念
- req->ioprio = ioprio_best(req->ioprio, next->ioprio);
- if (blk_rq_cpu_valid(next))
- req->cpu = next->cpu;
- return 1;
- }
1.1.4 elv_merged_request()函数讲解
该函数流程图和源码如下:

/*req发生了前项或者后项合并,req的扇区起始或者结束地址增大,需要把req从调度算法deadline红黑树队列或者hash队列中剔除,再按照req新的扇区起始或者结束地址插入队列*/
- void elv_merged_request(struct request_queue *q, struct request *rq, int type)
- {
- struct elevator_queue *e = q->elevator;
- //如果刚req发生了前项合并,req扇区起始地址增大,把req从deadline的红黑树队列删除再按照新的扇区起始地址插入红黑树队列,具体调用deadline算法的deadline_merged_request函数
- if (e->type->ops.elevator_merged_fn)
- e->type->ops.elevator_merged_fn(q, rq, type);
- if (type == ELEVATOR_BACK_MERGE)
- //如果刚req发生了后项合并,req扇区结束地址增大,把req从hash队列删除再按照新的扇区结束地址插入hash队列
- elv_rqhash_reposition(q, rq);
- //q->last_merge保存刚发生合并的req
- q->last_merge = rq;
- }
1.1.5 __elv_add_request()函数讲解
该函数主要负责将req添加IO算法队列里,流程图与源码如下:

deadline算法elevator_add_req_fn接口函数是deadline_add_request(),目的是将req插入到红黑树队列和fifo队列__elv_add_request源码如下:
- //新分配的req插入IO算法队列,或者是把当前进程plug链表上req全部插入到IO调度算法队列
- void __elv_add_request(struct request_queue *q, struct request *rq, int where)
- {
- rq->q = q;
- switch (where) {
- case ELEVATOR_INSERT_REQUEUE:
- case ELEVATOR_INSERT_FRONT://前向合并
- rq->cmd_flags |= REQ_SOFTBARRIER;
- list_add(&rq->queuelist, &q->queue_head);//req直接插入q->queue_head链表头而已,并没有进行req合并
- break;
- case ELEVATOR_INSERT_BACK://后向合并
- rq->cmd_flags |= REQ_SOFTBARRIER;
- //循环调用deadline算法的elevator_dispatch_fn接口一直选择派发的req到q->queue_head链表
- elv_drain_elevator(q);
- list_add_tail(&rq->queuelist, &q->queue_head);
- //这里调用底层驱动数据传输函数,就会从rq->queue_head链表取出req发送给磁盘驱动去传输
- __blk_run_queue(q);
- break;
- case ELEVATOR_INSERT_SORT_MERGE://把进程独有的plug链表上的req插入IO调度算法队列里走这里
- if (elv_attempt_insert_merge(q, rq))
- break;
- case ELEVATOR_INSERT_SORT://新分配的req插入的IO调度算法队列
- BUG_ON(rq->cmd_type != REQ_TYPE_FS);
- rq->cmd_flags |= REQ_SORTED;
- //队列插入新的一个req
- q->nr_sorted++;
- if (rq_mergeable(rq)) {
- //新的req靠req->hash添加到IO调度算法的hash链表里
- elv_rqhash_add(q, rq);
- if (!q->last_merge)
- q->last_merge = rq;
- }
- //把req插入到IO调度算法队列里,deadline是插入到红黑树队列和fifo队列
- q->elevator->type->ops.elevator_add_req_fn(q, rq);//deadline算法函数是deadline_add_request()
- break;
- case ELEVATOR_INSERT_FLUSH:
- rq->cmd_flags |= REQ_SOFTBARRIER;
- blk_insert_flush(rq);
- break;
- }
- }
好的,前文主要讲解了:submit_bio->generic_make_request->blk_queue_bio发起的IO请求,bio怎么合并到IO算法队列,或者新分配的req怎么插入到IO算法队列。IO算法队列需要特别说明一下,一共有这几个:IO算法默认的hash队列、deadline调度算法特有的红黑树rb队列和fifo队列。
1 IO算法默认的hash队列:每一个新分配的req必然以“ req扇区结束地址”为key插入到hash队列。具体见elv_rqhash_add函数,里边执行hash_add(e->hash, &rq->hash, rq_hash_key(rq))把req添加到hash队列。rq_hash_key(rq)就是hash key,即req扇区结束地址。对hash队列的操作有这几处:
- 前文介绍过的blk_queue_bio–>elv_merged_request函数,里边执行elv_rqhash_reposition对req在hash队列重新排序。原因是前边blk_queue_bio–> bio_attempt_back_merge/ bio_attempt_front_merge把bio前项/后项合并到了req,req扇区结束地址可能变大了,就需要执行elv_merged_request函数对这个req按照新的扇区结束地址在hash链表中重新排序。
- blk_queue_bio->__elv_add_request->elv_rqhash_add流程是把新分配的req按照它的扇区结束地址添加到hash队列
- blk_queue_bio ->elv_merge->elv_rqhash_find 遍历hash队列的req,看哪个req的扇区结束地址等于bio的扇区起始地址,等于则可以把bio后项合并到req。
- 当一个req合并到其他req时,要从hash队列剔除掉它,函数流程是attempt_front_merge/attempt_back_merge->attempt_merge->elv_merge_requests->elv_rqhash_del
- 当派发req给磁盘驱动时,先执行blk_peek_request->__elv_next_request->deadline_dispatch_requests-> elv_dispatch_add_tail->elv_rqhash_del 从deadline 红黑树和fifo队列取出req到q->queue_head链表,然后把req从hash队列剔除掉,最后再从q->queue_head链表取出req派发个磁盘驱动。
2 deadline调度算法的红黑树rb队列和fifo队列:deadline_add_request()函数负责将新的req添加到红黑树队列和fifo队列。把新的req插入红黑树队列的规则是req的“扇区起始地址”从小到大依次排列。新的req 插入fifo队列比较简单,直接插入fifo 队列dd->fifo_list[data_dir]链表尾部即可。fifo队列存在的意义是,每个req都有一个超时时间dd->fifo_expire[data_dir] ,新的req都是插入fifo队列的尾部。
fifo队列尾部的req都是最晚插入fifo队列的,fifo队列头的req都是最早插入req的。fifo队列头的req最先被检查是否超时了,超时到了则选择该req派发。fifo队列存在的意义是为了保证队列头超时的req尽快得到传输,红黑树队列存在的意义感觉只是让req按照扇区起始地址在上边排列,方便req遍历查找、插入删除、合并等的。
deadline_add_request和deadline_add_rq_rb源码如下:
- static void deadline_add_request(struct request_queue *q, struct request *rq)
- {
- struct deadline_data *dd = q->elevator->elevator_data;
- const int data_dir = rq_data_dir(rq);
- //req添加到红黑树队列里
- deadline_add_rq_rb(dd, rq);
- //设置req调度超时时间,超时时间到,则会把fifo队列头的req派发给驱动
- rq_set_fifo_time(rq, jiffies + dd->fifo_expire[data_dir]);
- //req插入到fifo队列尾部
- list_add_tail(&rq->queuelist, &dd->fifo_list[data_dir]);
- }
- //req添加到红黑树队列里
- static void deadline_add_rq_rb(struct deadline_data *dd, struct request *rq)
- {
- struct rb_root *root = deadline_rb_root(dd, rq);
- //把rq添加到红黑树里,就是按照每个req的起始扇区排序的
- elv_rb_add(root, rq);
- }
2 进程plug链表req的插入IO算法队列
内核很多地方派发req实际是执行blk_flush_plug_list()函数把req插入IO算法队列,比如blk_queue_bio()->blk_flush_plug_list(),blk_flush_plug()->blk_flush_plug_list()。blk_flush_plug_list函数源码和流程图如下:

//把进程plug链表上的req依次插入IO调度算法队列上
- void blk_flush_plug_list(struct blk_plug *plug, bool from_schedule)
- {
- struct request_queue *q;
- unsigned long flags;
- struct request *rq;
- LIST_HEAD(list);
- unsigned int depth;
- list_splice_init(&plug->list, &list);
- //对plug链表上的req排序,应该是按照每个req的起始扇区地址排序,起始扇区小的排在前
- list_sort(NULL, &list, plug_rq_cmp);
- q = NULL;
- depth = 0;
- //依次取出进程plug链表上的req依次插入IO调度算法队列上
- while (!list_empty(&list)) {
- //取出req
- rq = list_entry_rq(list.next);
- //从plug链表删除req
- list_del_init(&rq->queuelist);
- //在这里把req插入到IO调度算法队列里
- __elv_add_request(q, rq, ELEVATOR_INSERT_SORT_MERGE);
- //深度depth加1
- depth++;
- }
- if (q)//里边执行__blk_run_queue派发req给磁盘驱动
- queue_unplugged(q, depth, from_schedule);
- }
这个函数就是就是依次取出进程plug链表上的req依次执行__elv_add_request()插入IO算法队列。__elv_add_request()函数源码上一节已经详细解释过。还有一点需要注意,blk_flush_plug_list()函数最后执行queue_unplugged()才会把刚才插入IO算法队列的req派发给磁盘驱动,才能完成最终的磁盘数据传输。queue_unplugged()里实际是执行__blk_run_queue()->__blk_run_queue_uncond()->scsi_request_fn()把req派发给磁盘驱动。下文重点讲解。
3 __blk_run_queue()派发req到磁盘驱动
3.1 req整体派发流程
先看下整体流程图

//从IO算法队列选择req派发给磁盘驱动
- static void scsi_request_fn(struct request_queue *q)
- {
- struct scsi_device *sdev = q->queuedata;
- struct Scsi_Host *shost;
- struct scsi_cmnd *cmd;
- struct request *req;
- shost = sdev->host;
- for (;;) {
- int rtn;
- //把IO算法队列req先添加到q->queue_head链表头(默认是链表尾,IO高优先级进程是链表头),然后从q->queue_head链表头取出待派发的req,针对req的信息分配SCSI命令结构体cmd并赋值
- req = blk_peek_request(q);
- //如果req为NULL或者向磁盘驱动队列派发的req太多break跳出,不再派发
- if (!req || !scsi_dev_queue_ready(q, sdev))
- break;
- //req 传输前的一些操作,主要是把req从q->queue_head链表尾剔除掉
- blk_start_request(req);
- cmd = req->special;
- //发送SCSI命令,真正开始传输数据
- rtn = scsi_dispatch_cmd(cmd);
- }
- }
重点是执行blk_peek_request()选择派发的req,分配SCSI命令cmd并赋值,源码如下:
- struct request *blk_peek_request(struct request_queue *q)
- {
- /* 循环执行__elv_next_request(),从q->queue_head队列取出待进行IO数据传输的req。如果q->queue_head没有req,则执行deadline_dispatch_requests从fifo队列选择派发的req到q->queue_head链表*/
- while ((rq = __elv_next_request(q)) != NULL) {
- /*1 分配一个struct scsi_cmnd *cmd,使用req对cmd进行部分初始化cmd->request=req,req->special = cmd,还有cmd->transfersize传输字节数、cmd->sc_data_direction DMA传输方向
- 2 先遍历req上的每一个bio,再得到每个bio的bio_vec,把bio对应的文件数据在内存中的首地址bvec->bv_pag+bvec->bv_offset写入scatterlistscatterlist是磁盘数据DMA传输有关的数据结构,scatterlist保存到bidi_sdb->table.sgl,bidi_sdb是req的struct scsi_data_buffer成员。
- */
- ret = q->prep_rq_fn(q, rq);//scsi_prep_fn
- if (ret == BLKPREP_OK) {
- break;
- }
- }
blk_peek_request()函数整体总结如下:
1 从q->queue_head队列头取出待进行IO数据传输的req.如果q->queue_head没有req,则执行deadline_dispatch_requests从fifo队列选择派发的req
2 分配一个struct scsi_cmnd *cmd,使用req对cmd进行部分初始化cmd->request=req,req->special = cmd,还有cmd->transfersize传输字节数、cmd->sc_data_direction DMA传输方向
3 先遍历req上的每一个bio,再得到每个bio的bio_vec,把bio对应的文件数据在内存中的首地址bvec->bv_pag+bvec->bv_offset写入scatterlist。scatterlist是磁盘数据DMA传输有关的数据结构,scatterlist保存到bidi_sdb->table.sgl,bidi_sdb是req的struct scsi_data_buffer成员。
blk_peek_request()函数里执行__elv_next_request(),目的是:从q->queue_head链表取出待传输的req,如果q->queue_head链表没有req,则执行deadline_dispatch_requests()从fifo队列选择派发的req到q->queue_head。
- static inline struct request *__elv_next_request(struct request_queue *q)
- {
- while (1) {
- //从q->queue_head取出待传输的req,如果q->queue_head没有req,则执行deadline_dispatch_requests从fifo队列选择派发的req
- if (!list_empty(&q->queue_head)) {
- rq = list_entry_rq(q->queue_head.next);
- return rq;
- }
- if (unlikely(blk_queue_bypass(q)) ||
- !q->elevator->type->ops.elevator_dispatch_fn(q, 0))//deadline_dispatch_requests()选择派发的req
- return NULL;
- }
deadline_dispatch_requests()函数是deadline IO调度算法的核心,重点讲解。
3.2 deadline_dispatch_requests()IO调度算法派发req
deadline_dispatch_requests()函数流程,源码和流程图如下:
static int deadline_dispatch_requests(struct request_queue *q, int force)
- {
- struct deadline_data *dd = q->elevator->elevator_data;
- //如果fifo队列有read req,list_empty返回0,reads为1
- const int reads = !list_empty(&dd->fifo_list[READ]);
- //如果fifo队列有write req,list_empty返回0,writes为1
- const int writes = !list_empty(&dd->fifo_list[WRITE]);
- struct request *rq;
- int data_dir;
- //每次从红黑树选取一个req发给驱动传输,这个req的下一个req保存在next_rq[],现在又向驱动发送req传输,优先先从next_rq取出req
- if (dd->next_rq[WRITE])
- rq = dd->next_rq[WRITE];
- else
- rq = dd->next_rq[READ];
- /*如果dd->batching大于等于dd->fifo_batch,不再使用next_rq,否则会一直只向后使用红黑树队列的req向驱动发送传输,队列前边的req得不到发送*/
- if (rq && dd->batching < dd->fifo_batch)
- goto dispatch_request;
- /*选择read或write req,因为一直选择read req给驱动传输,那write req就饿死了*/
- if (reads) {
- BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[READ]));
- /*有write req要传送给驱动,并且write req被饥饿次数达到上限,就强制选择跳转选择write req,防止一直选择read req给驱动传输,write req得不到选择而starve饥饿,每次write req得不到选择而饥饿则starved++。writes_starved是饥饿的次数上限,starved大于writes_starved,就强制选择write req*/
- if (writes && (dd->starved++ >= dd->writes_starved))
- goto dispatch_writes;
- //否则下面选择read req
- data_dir = READ;
- goto dispatch_find_request;
- }
- if (writes) {
- dispatch_writes:
- BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[WRITE]));
- //dd->starved清0
- dd->starved = 0;
- //下面选择write req,就一个赋值操作
- data_dir = WRITE;
- goto dispatch_find_request;
- }
- return 0;
- dispatch_find_request:
- //deadline_check_fifo:如果deadline fifo队列有超时的req要传输返回1,或者next_rq没有暂存req,if都成立。则从fifo队列头取出req
- if (deadline_check_fifo(dd, data_dir) || !dd->next_rq[data_dir]) {
- //取出fifo队列头的req,最早入fifo队列的req,最早入队的req当然更容易超时
- rq = rq_entry_fifo(dd->fifo_list[data_dir].next);
- } else {
- //否则直接取出next_rq暂存的req
- rq = dd->next_rq[data_dir];
- }
- //batching清0
- dd->batching = 0;
- dispatch_request://到这里,req直接来自next_rq或者fifo队列,这个req就要被发给驱动传输了
- //batching加1
- dd->batching++;
- /*把req添加到rq的queue_head队列,设置新的next_rq,并把req从fifo队列和红黑树队列剔除,将来磁盘驱动程序就是从queue_head链表取出req传输的*/
- deadline_move_request(dd, rq);
- return 1;
- }
deadline_dispatch_requests()函数简单来说是:选择合适待派发给驱动传输的req,然后把req添加到q->queue_head链表,然后设置新的next_rq,并把req从fifo队列和红黑树队列剔除。将来向磁盘驱动程序派发的req就是从queue_head链表取出的。req来源有:上次派发设置的next_rq;read req派发过多而选择的write req;fifo 队列上超时要传输的req,统筹兼顾,有固定策略。
1 首先呢,从dd->next_rq[WRITE/ READ]获取上次派发req后设置的next req,if (rq && dd->batching < dd->fifo_batch)这个判断是为了防止一直派发dd->next_rq[WRITE/ READ],每派发一个next req,dd->batching就会加1,如果dd->batching < dd->fifo_batch成立,就goto dispatch_request直接使用dd->next_rq[WRITE/ READ]指定的next req。
2 如果if (rq && dd->batching < dd->fifo_batch) 不成立,说明派发的dd->next_rq[WRITE/ READ]指定的next req太多了,该派发fifo队列的req了,这个req更紧急。此时就会进入if (reads) 或者if (writes) 分支,最后执行goto dispatch_find_request从dd->fifo_list[data_dir] fifo队列选择派发的req,具体流程是:先执行if (deadline_check_fifo(dd, data_dir) || !dd->next_rq[data_dir]),deadline_check_fifo(dd, data_dir)函数是判断fifo队列有没有超时的req,有则执行rq = rq_entry_fifo(dd->fifo_list[data_dir].next) 取出fifo队列头的req(这是最早加入fifo队列的req,最早入队的req当然更容易超时)。
3 回到第二步,还有一点没讲,就是if (reads)分支里的if (writes && (dd->starved++ >= dd->writes_starved)) ,每派发一个read req(即data_dir = READ)则dd->starved++加1,等到dd->starved++ >= dd->writes_starved则goto dispatch_writes执行data_dir = WRITE,这样就会派发write req。dd->starved的作用是派发dd->writes_starved个read req后,就该派发write req了,防止write req饿着。
deadline_dispatch_requests()最后执行的deadline_move_request()函数,作用是把req添加到q->queue_head链表,设置新的next_rq,并把req从fifo队列和红黑树队列剔除,将来磁盘驱动程序就是从q->queue_head链表取出req派发的。源码如下:
//把req添加到q->queue_head链表,设置新的next_rq,并把req从fifo队列和红黑树队列剔除,将来磁盘驱动程序就是从q->queue_head链表取出req传输的
- static void deadline_move_request(struct deadline_data *dd, struct request *rq)
- {
- //req是read还是write
- const int data_dir = rq_data_dir(rq);
- dd->next_rq[READ] = NULL;
- dd->next_rq[WRITE] = NULL;
- //从红黑树队列中取出req的下一个req作为next_rq,下次deadline_dispatch_requests()选择派发给的req时就可能是它了
- dd->next_rq[data_dir] = deadline_latter_request(rq);
- //req的磁盘空间end地址
- dd->last_sector = rq_end_sector(rq);
- //把req添加到q->queue_head链表,并把req从fifo队列和红黑树队列剔除,将来磁盘驱动程序就是从queue_head链表取出req派发的
- deadline_move_to_dispatch(dd, rq);
- }
deadline_move_to_dispatch()函数源码如下:
//把req添加到q->queue_head链表,并把req从fifo队列和红黑树队列剔除,将来磁盘驱动程序就是从queue_head链表取出req派发的
- static inline void deadline_move_to_dispatch(struct deadline_data *dd, struct request *rq)
- {
- struct request_queue *q = rq->q;
- //从fifo队列和红黑树队列剔除req
- deadline_remove_request(q, rq);
- //把req添加到q->queue_head链表,将来磁盘驱动程序就是从queue_head链表取出req派发的
- elv_dispatch_add_tail(q, rq);
- }
deadline_remove_request()源码如下:
//deadline算法从fifo队列和红黑树剔除req。剔除前如果req原本是dd->next_rq[]保存req,还要找到req在红黑树的下一个req赋值给dd->next_rq[]
- static void deadline_remove_request(struct request_queue *q, struct request *rq)
- {
- struct deadline_data *dd = q->elevator->elevator_data;
- //从fifo队列剔除rq
- rq_fifo_clear(rq);
- //如果req原本是dd->next_rq[]保存req,则要找到req在红黑树的下一个req赋值给dd->next_rq[],然后把req从红黑树中剔除
- deadline_del_rq_rb(dd, rq);
- }
deadline_del_rq_rb()函数源码如下:
//如果req原本是dd->next_rq[]保存req,则要找到req在红黑树的下一个req赋值给dd->next_rq[],然后把req从红黑树中剔除
- static inline void deadline_del_rq_rb(struct deadline_data *dd, struct request *rq)
- {
- const int data_dir = rq_data_dir(rq);
- /*这个if判断是说rq原本是dd->next_rq[]保存req,现在rq马上要从红黑树中剔除,则要找到rq在红黑树的下一个req赋值给dd->next_rq[]。deadline算法选择派发的req时会优先选择dd->next_rq[]保存的req*/
- if (dd->next_rq[data_dir] == rq)
- dd->next_rq[data_dir] = deadline_latter_request(rq);
- //deadline_rb_root(dd, rq)是取出调度算法的读或者写红黑树队列头rb_root,然后把req从这个红黑树队列剔除掉
- elv_rb_del(deadline_rb_root(dd, rq), rq);
- }
//把req添加到rq->queue_head链表,将来磁盘驱动程序就是从queue_head链表取出req派发的
- void elv_dispatch_add_tail(struct request_queue *q, struct request *rq)
- {
- if (q->last_merge == rq)
- q->last_merge = NULL;
- //req从hash队列剔除
- elv_rqhash_del(q, rq);
- q->nr_sorted--;
- //结束扇区
- q->end_sector = rq_end_sector(rq);
- q->boundary_rq = rq;
- //把req添加到rq->queue_head链表,将来磁盘驱动程序就是从queue_head链表取出req派发的
- list_add_tail(&rq->queuelist, &q->queue_head);
- }