python可视化之——seaborn简单图绘制指南
0. 主要内容
该笔记主要包括常见的:散点,折线,box,violin,等图的绘制,可以帮助我们了解数据存在的变量之间的某种关系或者数据趋势。在日常工作中,我们可以进行简单的数据分析和可视化,用于汇报。
1. relplot
主要来自官方文档:https://seaborn.pydata.org/generated/seaborn.relplot.html
replot 用于创建具有子图网格的散点图或折线图形 返回的是一个FacetGrid对象
- 用途:绘制2个数值型变量之间的关系图表 ,包含散点和折线
- 参数:
- x,y : 自定义向量或来自data数据框 分别表示x轴和y轴上的变量
- hue:自定义向量(长度要和data数据长度一致)或来自data数据框 用于对数据进行分组的列名:例如(不同时间点和共享单车数量关系,分组于不同日期采用不同颜色)
- size:用于指定散点标志大小 自定义向量或来自data
- style:用于表示样式 自定义向量或data ,建议不要选择数值型data列建议选择类型特征data列
- data:传入的数据框
- kind:散点,线图(scatter,line)
- col: 以列展示每个类的子图,col=‘sex’,以sex分图展示 每个图是每个sex类 向量或data
- row:以行展示每个类的子图 向量或data
- col_waps:指定每行最大列数 若=2,4个子图会展示2行2列
- markers:bool类型,字典或者list,指定样式 依赖与style中style值,style几个值,markers就几个。
1.1.1 散点可视化

- 绘制total_bill 和 tip的关系,以 day 分组 1个图
注意: 参数data,x,y,hue是图的核心,其他参数大部分用于美观,data是要展示的整体数据框DataFrame,指明data后,x和y就可以直接使用数据框中的列名。若不指明data,x,y需要指明具体数据向量 。
sns.relplot(data=tips, x="total_bill", y="tip", hue="day")
sns.relplot(x=tips['total_bill'],y=tips['tip'],hue=tips['day'])
- 绘制total_bill 和 tip的关系,以 day 分组,以time分图表展示 以col(列)分子图展示
注意:relplot能根据kind实现散点图scatterplot和折线图lineplot的功能,但是relplot支持多个子图展示(col,row),但是没有ax(指定图展示位置)参数。
sns.relplot(data=tips, x="total_bill", y="tip", hue="day", col="time")
- 绘制total_bill 和 tip的关系,以 day 分组,以day分图表展示 展示4列1行,
sns.relplot(data=tips,x='total_bill',y='tip',hue='day',col='day')
- 绘制total_bill 和 tip的关系,以 day 分组,以time分列子图,以sex分列子图
注意:列子图展示: 以col(列)一列一个time类别 ,行子图展示row(行),一行一个sex类别,共(time类别数 × sex类别数)个图
sns.relplot(data=tips, x="total_bill", y="tip", hue="day", col="time", row="sex")

- 指定样式
注意:style指定可以来自data,每个类别散点样式不一样,有点是圆点,有的是X,size也可以来自数据框中data数据,指定散点大小,通过设置sizes最大最小的气泡 来设置成气泡图形式展示。
# sizes设置气泡最小1,最大300,style根据sex类别设置,hue分组,paletter根据hue类别来标记颜色,注意长度要与hue中分组个数一致
sns.scatterplot(data=tips,x='total_bill',y='tip',hue='time',size=tips['size'] * 100,sizes=(1, 300),style='sex',palette=['b','r'],alpha=0.5)

1.1.2 折线图可视化
relplot的kind指定散点还是折线,默认是散点。
# kind参数设置成line
sns.relplot(data=fmri, x="timepoint", y="signal", col="region",hue="event",
style="event", kind="line")

1.1 scatterplot
用于绘制两个数值型变量之间的关系,散点图形式展示。注意该绘图函数返回的是matplotlib.axes.Axes(绘图核心:绘图区域,包含一个坐标系和多个绘图元素。),不是FacetGrid,不支持绘制子图。
- 用途:绘制2数值型变量之间的散点图
- 参数:
- x,y : 向量或来自data数据框 分别表示x轴和y轴上的变量
- hue:向量或来自data数据框 用于对数据进行分组的列名:例如(不同时间点和共享单车数量关系,分组于不同日期采用不同颜色)
- size:用于指定散点标志大小 向量或来自data
- style:用于表示样式 向量或data
- data:传入的数据框
- sizes:设置大小
- markers:设置形状 dict :x,s,o形状等
- 与relplot的区别是没有 col row 子图 返回的不是FacetGrid
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="size", size="size",sizes=(20, 200))
# 指定markers
markers = {"Lunch": "s", "Dinner": "X"}
sns.scatterplot(data=tips, x="total_bill", y="tip", size='size',hue='time',palette=['b','r'],style="time", markers=markers)
指定markers展示
1.2 lineplot
返回的是matplotlib.axes.Axes,将返回值保存后,我们可以根据需要进一步设置图中其他元素。
- 用途:绘制2变量之间的折线图
- 参数:
- x,y : 向量或来自data数据框 分别表示x轴和y轴上的变量
- hue:向量或来自data数据框 用于对数据进行分组的列名:例如(不同时间点和共享单车数量关系,分组于不同日期采用不同颜色)
- size:用于指定散点标志大小 向量或来自data
- style:用于表示样式 向量或data
- data:传入的数据框
- sizes:设置大小
- 与relplot的区别是没有 col row 子图 不是FacetGrid,当然还有别的区别,还请自己探索
# 设置折线样式 event,设置分组 region
fmri = sns.load_dataset("fmri")
sns.lineplot(data=fmri, x="timepoint", y="signal", hue="region", style="event")

1.3 总结
可能有人疑问为啥已经有scatterplot和lineplot函数了,为何还存在relplot函数,我个人认为可能是因为relplot可以绘制子图,根据不同类别展示一个子图,简化代码。如果使用scatterplot展示进行多个类别筛选数据时就需要 先创建好子图,在根据ax定位不同类别的展示在子图中的位置。而relplot直接col row就可以实现,还可以根据col_wraps设置分几列展示col组数据,注意不能和row同时使用。
# relplot只需要一行代码
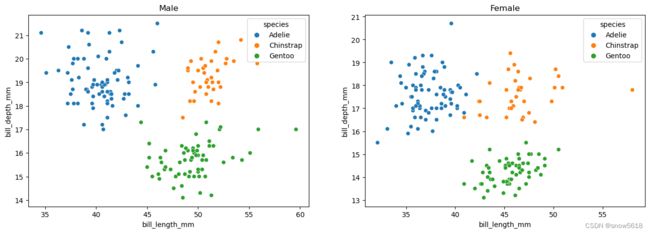
sns.relplot(data=penguins, x="bill_length_mm",y="bill_depth_mm", hue="species",col='sex')
# 散点图 分组统计 需要好几行代码
kw = {'width_ratios':[1,1]}
fig,axes = plt.subplots(1,2,figsize=(16,5),gridspec_kw=kw)
sns.scatterplot(data=penguins[penguins['sex']=='Female'], x="bill_length_mm",y="bill_depth_mm", hue="species",ax=axes[1])
axes[1].set(title="Female")
sns.scatterplot(data=penguins[penguins['sex']=='Male'], x="bill_length_mm",y="bill_depth_mm", hue="species",ax=axes[0])
axes[0].set(title="Male")
relplot

scatterplot
2. displot
用途:绘制单变量或者双变量分布的关系,可以绘制直方图,核密度图,ecdf图,帮助理解数据的分布情况
参数:
- data:向量或来自data
- x,y: 向量或来自data
- hue:data 分组
- weights:data 权重
- kind:图标类别,hist,kde,ecdf 默认hist 频率直方图
- col: 以列展示每个类的子图,col=‘sex’,以sex分图展示 每个图是每个sex类 向量或data
- row:以行展示每个类的子图 向量或data
- col_waps:指定每行最大列数 若=2,4个子图会展示2行2列
- legend:bool值默认false
- 判断是否正态分布
- KDE 图通常呈现出钟形曲线,即高峰在中心,两侧逐渐减小
- ECDF 图应该是一条平滑的、逐渐上升的曲线,没有明显的跳跃或波动。
2.0.1 hist图
displot 当kind=‘hist’ 绘制直方图,x和y都表示变量,单变量分布只需要观察一个x或y
- 若指定x,则横轴表示变量,纵轴表示频数(count)
- 若指定y,则纵轴表示变量,横轴表示频数(count)
- 若同时指定x,y,则显示俩变量分布,类似热力图。
# 指定x
penguins = sns.load_dataset("penguins")
sns.displot(data=penguins, x='body_mass_g',hue='sex')
# 指定y
sns.displot(data=penguins, y='body_mass_g',hue='sex')
# 指定x和y
sns.displot(data=penguins, x='flipper_length_mm',y='body_mass_g',hue='sex')
指定y 展示可以看出xy取值决定图的方向

2.0.2 kde图
当displot的kind参数取值"kde"时绘制kde图。
kde:是一种通过对数据进行平滑处理来估计其概率密度的非参数方法 KDE 在统计学和数据可视化中经常被用来理解数据分布的形状。
核心思想:它的核心思想是在每个数据点的位置上放置一个核(通常是高斯核),然后将这些核叠加起来形成平滑的概率密度估计。
KDE概率密度函数 :数学上,对于一组样本数据 ( x 1 , x 2 , … , x n {x_1, x_2, \ldots, x_n} x1,x2,…,xn), KDE 估计的概率密度函数 (f(x)) 可以表示为: f ( x ) = 1 n ⋅ h ∑ i = 1 n K ( x − x i h ) f(x) = \frac{1}{n \cdot h} \sum_{i=1}^{n} K\left(\frac{x - x_i}{h}\right) f(x)=n⋅h1∑i=1nK(hx−xi) ,其中 (K) 是核函数,通常是一个关于零中心对称的函数,(h) 是带宽(bandwidth),用于控制估计的平滑程度。 在kdeplot中可通过kernel选择核函数,通过bw_adjust参数选择带宽。
概率密度:对于一个连续型随机变量 (X),概率密度函数 (f(x)) 满足以下两个性质:
1. 概率密度函数 (f(x)) 是非负的:对于所有的 (x),有 ( f ( x ) ≥ 0 ) (f(x) \geq 0) (f(x)≥0)。
2. 在整个定义域上的积分等于1: ( ∫ − ∞ ∞ f ( x ) , d x = 1 ) (\int_{-\infty}^{\infty} f(x) ,dx = 1) (∫−∞∞f(x),dx=1)。
3. 例如:sns.kdeplot(data[“total_bill”], clip=(10, 30)) 只对数据集中落在(10,30)这个范围内的部分数据进行核密度估计
sns.displot(data=penguins, x='body_mass_g',hue='sex',kind='kde')
# 分子图展示
sns.displot(data=penguins, x="flipper_length_mm", hue="species", col="sex", kind="kde")
分子图展示

2.0.3 ecdf图
ECDF 是经验累积分布函数。
定义: 对于一个样本数据集 ({x_1, x_2, \ldots, x_n}),其 ECDF 是一个阶梯函数,定义如下: [ F ( x ) = 1 n ∑ i = 1 n I ( x i ≤ x ) ] [ F(x) = \frac{1}{n} \sum_{i=1}^{n} I(x_i \leq x) ] [F(x)=n1∑i=1nI(xi≤x)]
其中: (F(x)) 是在给定的观测值 (x) 处的 ECDF。 (n) 是样本大小(观测值的总数)。 ( I ( x i ≤ x ) ) (I(x_i \leq x)) (I(xi≤x)) 是一个指示函数,当 ( x i ≤ x ) (x_i \leq x) (xi≤x) 时为 1,否则为 0。
对于每个观测值 ( x i ) (x_i) (xi), ( I ( x i ≤ x ) ) (I(x_i \leq x)) (I(xi≤x))是一个二进制值,表示该观测值是否小于或等于 ( x ) (x) (x)。累积和部分就是对这些二进制值求和,最后除以样本大小 ( n ) (n) (n)。
sns.displot(
data=penguins, y="flipper_length_mm", hue="sex", col="species",kind="ecdf", height=4, aspect=.7,)

1.2 histplot
用途:绘制单变量或者双变量分布的直方图,帮助理解数据的分布情况 参数:
- data:向量或来自data
- x,y: 向量或来自data
- hue:data 分组
- weights:data 权重
- binwidth:条形宽度 取值int。调整条形宽度
- binrange:条形范围
- bins:条形个数
- fill:是否为条形填充颜色
- kde:是否展示核密度线 bool 仅与单变量相关
- legend:bool值默认false
- stat:count或sum统计个数或总和
- element:bars,step,poly 默认bars
- ax:指定子图位置
- car_ax:指定cbar位置
# 1 设置观察哪个变量的分布,设置条形个数30,绘制kde曲线
sns.histplot(data=penguins, x="flipper_length_mm",bins=30,kde=True)
# 2 设置分组,指定stack堆叠形式 设置不填充
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack",fill=False)
# 3 绘制阶跃函数
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
# 4 绘制2变量之间的分布,热图
sns.histplot(
penguins, x="bill_length_mm",y='bill_depth_mm',
cbar=True
)
展示第3个:绘制阶跃函数

1.3 kdeplot
用途:绘制单变量或者双变量分布的核密度,帮助理解数据的分布情况
参数:
- data:向量或来自data
- x,y: 向量或来自data
- hue:data 分组
- weights:data 权重
- fill:是否为条形填充颜色
- legend:bool值默认false
- ax:指定子图位置
- car_ax:指定cbar位置
- common_norm:bool类型, 默认True
- common_grid:bool类型
# 设置common_norm为False,设置size为分组 可视化total_bill的分布 的density即概率密度
sns.kdeplot(data=tips, x="total_bill", hue="size",fill=True, common_norm=False, palette="crest")

1.4 ecdfplot
用途:绘制单变量或者双变量分布的ecdf,帮助理解数据的分布情况
参数:
- data:向量或来自data
- x,y: 向量或来自data
- hue:data 分组
- weights:data 权重
- stat:count,proportion 其中proportion默认值
# 以species分组 stat统计个数 count
sns.ecdfplot(data=penguins, x="bill_length_mm", hue="species", stat="count")
sns.ecdfplot(data=penguins, x="bill_length_mm", hue="species", stat="proportion")

3. catplot
作用:绘制分类数据的图,显示数值与一个变量或多个类别之间的关系,可以指定图表类型,kind。当数据集中的特征变量是非数值型变量时可以进行绘制其类别。例如
房屋类别1,2,3对应房屋价格[…] 可以绘制其catplot等各种图。
- 分类散点图:
- stripplot:散点图 通常绘制一个分类变量下数值型变量的分布情况
- swarmplot:不重叠的散点图
- 分类估计图:
- pointplot:每个类别的点估计或者置信区间
- barplot:每个类别的均值(默认),还可以是其他
- countplot:每个类别的数量
- 分类分布图:
- boxplot:箱线图 显示数据的分布,中位数,异常值。
- violinplot:小提琴图
- boxenplot:箱线图的扩展
- 参数
- data:数据框
- x,y:data x,y
- hue:data 分组
- row,col:data 子图
- kind:默认散点图。 “strip”, “swarm”, “box”, “violin”, “boxen”, “point”, “bar”, “count”. 其中count显示的是一个类别的计数。
- estimator:估计每个分类箱内的统计函数
# 查看泰坦尼克号中,class类别中年龄的分布情况,并且以sex分组观察。
sns.catplot(data=df,x='class',y='age',kind='boxen',hue='sex')
# 分层绘制 catplot小提琴图和swarmplot
sns.catplot(data=df, x="age", y="class", kind="violin", color=".9", inner=None)
sns.swarmplot(data=df, x="age", y="class", size=3)

3.1 barplot
用途:绘制分类变量对应的数值变量的中心趋势(如均值) 参数:
参数:
- x,y,hue:绘制的x和y指定的数据,其中一个指定类别型变量特征,一个指定数值特征变量,hue指定分组
- data:数据框
# 当x和y同时数值型变量时 可以看出 histplot更适合(虽然是二维的热图)
kw = {'width_ratios':[1,1]}
fig,axes = plt.subplots(1,2,figsize=(16,5),gridspec_kw=kw)
sns.barplot(data=tips, x="total_bill", y="tip", hue="time",ax=axes[0])
axes[0].set(title="barplot")
sns.histplot(data=tips, x="total_bill", y="tip", hue="time",ax=axes[1])
axes[1].set(title="histplot")
# 当x和y,一个数值型一个类别型 可以看出barplot更适合
kw = {'width_ratios':[1,1]}
fig,axes = plt.subplots(1,2,figsize=(16,5),gridspec_kw=kw)
sns.barplot(data=tips, x='day',y="total_bill", hue="time",ax=axes[0])
axes[0].set(title="barplot")
sns.histplot(data=tips, x='day',y="total_bill", hue="time",ax=axes[1])
axes[1].set(title="histplot")

3.2 pointplot
3.3 countplot
用途:用于对类别型特征变量的个数统计
参数:
- x or y,hue:绘制的x和y指定的数据,x和y只是表示类别变量所在的轴,不能同时出现。hue指定分组
- data:数据框
# 当x是数值型可以看出不适合统计
kw = {'width_ratios':[1,1]}
fig,axes = plt.subplots(1,2,figsize=(16,5),gridspec_kw=kw)
sns.countplot(data=tips, x='day', hue="time",ax=axes[0])
axes[0].set(title="countplot")
sns.countplot(data=tips, x="total_bill", hue="time",ax=axes[1])
axes[1].set(title="countplot")

3.4 boxplot 和boxenplot
用途:都是绘制箱线图,也是类别和数值变量关系的查看,类别型变量对应的数值型变量分布情况,不同是boxenplot展示的数据范围更多
参数:
- x,y,hue:绘制的x和y指定的数据,其中一个指定类别型变量特征,一个指定数值特征变量,hue指定分组
- data:数据框
penguins = sns.load_dataset("titanic")
kw = {'width_ratios':[1,1]}
fig,axes = plt.subplots(1,2,figsize=(16,5),gridspec_kw=kw)
sns.boxplot(data=penguins, x="class", y="age", hue="alive",ax=axes[0])
axes[0].set(title="boxplot")
sns.boxenplot(data=penguins, x="class", y="age", hue="alive",ax=axes[1])
axes[0].set(title="boxenplot")

3.5 violinplot
用途:绘制小提琴图,也是类别和数值变量关系的查看,类别型变量对应的数值型变量分布情况
参数:
- x,y,hue:绘制的x和y指定的数据,其中一个指定类别型变量特征,一个指定数值特征变量,hue指定分组
- data:数据框
- split:bool True表示不用分隔开,
# 绘制class中的age分布情况,采用split不同的值,查看图表
penguins = sns.load_dataset("titanic")
kw = {'width_ratios':[1,1]}
fig,axes = plt.subplots(1,2,figsize=(16,5),gridspec_kw=kw)
sns.violinplot(data=penguins, x="class", y="age", hue="alive",split=True,ax=axes[0])
sns.violinplot(data=penguins, x="class", y="age", hue="alive",ax=axes[1])
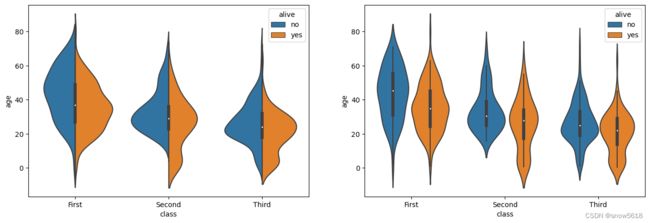
3.6 striplot
用途:绘制一个类别变量的数值型分布情况,与scatterplot区别scatterplot用于绘制两个数值型变量之间的关系
kw = {'width_ratios':[1,1]}
fig,axes = plt.subplots(1,2,figsize=(16,5),gridspec_kw=kw)
# 从scatterplot和stripplot绘制中看到,scatterplot看不出数据的分布形态,stripplot更适合观察数值型和类别型变量的分布形态。
sns.stripplot(data=tips, x="day", y="tip", hue="time",ax=axes[0])
axes[0].set(title="stripplot")
sns.scatterplot(data=tips, x="day", y="tip", hue="time",ax=axes[1])
axes[1].set(title="scatterplot")

# 当x和y都是数值型变量时 可以看出stripplot不适合查看两个数值型散点图,x轴标签都已经重叠
kw = {'width_ratios':[1,1]}
fig,axes = plt.subplots(1,2,figsize=(16,5),gridspec_kw=kw)
sns.stripplot(data=tips, x="total_bill", y="tip", hue="time",ax=axes[0])
axes[0].set(title="stripplot")
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time",ax=axes[1])
axes[1].set(title="scatterplot")

3.7 swarmplot
散点不会重叠在一起,所有散点都会展示出来。
kw = {'width_ratios':[1,1]}
fig,axes = plt.subplots(1,2,figsize=(16,5),gridspec_kw=kw)
sns.stripplot(data=tips, x="day", y="tip", hue="time",ax=axes[0])
axes[0].set(title="stripplot")
sns.swarmplot(data=tips, x="day", y="tip", hue="time",ax=axes[1])
axes[1].set(title="scatterplot")

总结:123
关于数据探索中如下:
- 数值型数据:
- 可以采用分布图进行探索其分布特征,displot 包含hist,kde,ecdf ,histplot,kdeplot等
- 类别型数据:scatterplot, lineplot,catplot,boxplot
- 统计个数:count
- 观察类别中与其他变量之间的关系:
- 例如:船舱类别中年龄分布
- 例如:船舱类别和票价分布
- 例如:日期和共享单车个数分布
- 例如:时间段中共享单车个数分布以日期分组
- 例如:不同时间销售额分布:折线,x=time,y=sales
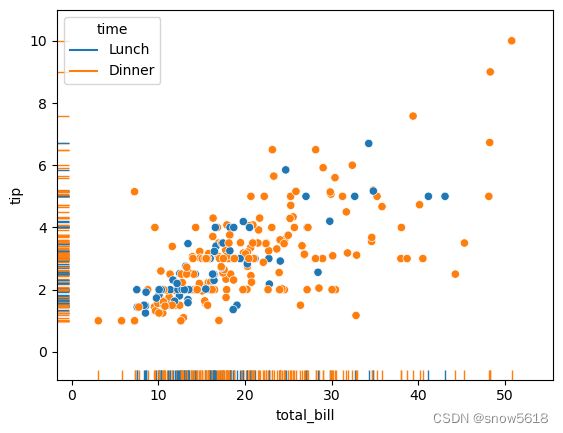
4. rugplot
用途:绘制标签边际分布,旨在使得绘制的图形更加明显 参数:
- data:向量或来自data
- x,y: 向量或来自data
- hue:data 分组
- height: 高度
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time")
sns.rugplot(data=tips, x="total_bill", y="tip", hue="time")
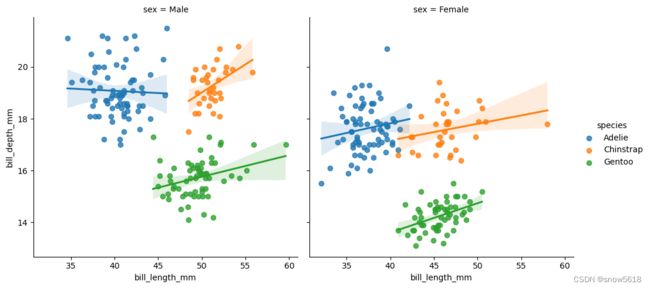
5. implot
用途:绘制线性回归拟合模型的图,散点图上拟合并显示回归线,可绘制多个散点图和线性回归线
参数:
- data:数据
- x,y:数值型变量 查看关系
- hue:分组 data
- col:子图 data
- row:子图
- lowess:内置统计函数 bool
- logistic:内置统计函数 bool
- robust:内置统计函数 bool
# implot绘制线性回归拟合曲线,其实就是在散点图上画一条回归线
sns.lmplot(data=penguins, x="bill_length_mm", y="bill_depth_mm", hue="species",col="sex")
6. regplot
作用:绘制线性回归拟合模型的图,散点图上拟合并显示回归线,绘制单个散点图和线性回归线
参数:
- data:数据
- x,y:数值型变量 查看关系
- 不能绘制多个散点图的拟合,不能分组,也不能分子图
sns.regplot(data=penguins, x="bill_length_mm", y="bill_depth_mm")

7. residplot
用途:用于绘制残差图的函数。残差图是通过观察实际观测值与模型预测值之间的差异,用于评估模型的拟合程度
参数:
- data:数据
- x,y:数值型变量 查看关系
- lowess:内置统计函数 bool
- robust:内置统计函数 bool
8. heatmap
用途:将矩形数据,绘制成颜色编码热力图 参数:
- data:矩阵数据
- vmin,vmax:颜色图的值
- cmap:指定颜色空间
- robust:bool
- annot:bool 数据展示
- fmt:数据展示位数
- annot_kws:设置数据展示,font,size等dict格式
- cbar:bool 是否展示
- cbar_ax:指定子图
- xticklabels:是否显示x标签
- yticklabels:是否显示y标签
- mask:遮盖
- square:bool是否强制将图绘制成正方形
- ax:指定展示图位置
sns.heatmap(glue, annot=True, fmt=".2f",annot_kws={'fontsize':6},vmin=50,vmax=100)
9. clustermap
用途:用于创建簇图
参数:
- data:数据
- cmap:颜色图
- col_cluster:bool 是否对列进行层次聚类
- row_cluster: bool 是否对行进行层次聚类
- method:层次聚类方法:single,compete,average
- metric:层次聚类的距离度量:euclidean,correlation
- figsize:图形大小
10. pairplot
用途:绘制数据集中俩变量之间的关系,其中对角线上是单变量分布
参数:
- data:数据集 绘制的是俩数值型变量之间的关系分布
- hue:分组
- kind:scatter,hist,kde,reg 默认scatter
- 其中reg是 regplot的,拟合散点图的回归线
- hist 直方图,由于俩变量 展示的是热图
- scatter:散点图
- kde:核密度图,由于俩变量展示的是密度图,像压强线
- diag_kind:设置对角线上图展示
# 绘制data数据中的数值型变量之间的分布关系,reg拟合回归线,并设置map_lower绘制下三角区域
# 采用kdeplot绘制
penguins = sns.load_dataset("penguins")
g = sns.pairplot(data=penguins,kind='reg')
g.map_lower(sns.kdeplot, levels=4, color=".2")

11. jointplot
用途:绘制2数值型变量之间的分布关系,由于histplot,kdeplot展示观察2个变量之间的关系时绘制成热图或者密度图,很难看出单变量分布情况,jointplot不仅可以看出2变量之间,还在轴上绘制单变量分布情况。
参数:
- data:数据
- x,y,hue:来自data列,
- kind:绘制分布图的类型:hist,kde,scatter,hex,reg 默认scatter ,其中hex,reg不支持分组
# 绘制2变量之间的分布关系,以sex分组,hist格式
sns.jointplot(data=penguins, x="bill_length_mm", y="bill_depth_mm",hue='sex',kind='hist')

12. 总结
- displot 是histplot,kdeplot,ecdfplot的合并
可以根据kind选择合适的图表,支持分子图展示(col,row)取值于data列中。探究数值型变量的分布情况- catplot是countplot,stripplot,swarmplot,violinplot,boxplot,boxenplot,barplot,pointplot的合并,可以根据kind选择合适的图表,支持分子图展示(col,row)取之于data,探究类别变量和数值型变量之间的分布关系。
- implot是绘制拟合回归线,可以根据col,row分子图展示不支持ax,regplot也是拟合,但是只能单个变量。支持ax
- heatplot是热图展示 .pairplot是展示整个数据中数值型变量两两之间的关系
- joinplot是探究数值型变量2个变量之间的关系时,分别在各自轴上绘制单个变量分布关系。
13. 补充dendrogram
用途:绘制层次聚类图
- from scipy.cluster.hierarchy import linkage, dendrogram
- 首先:linkage求层次聚类连接矩阵,dendrogram绘制
- linkage参数:
data:二维数值型数据 相关性系数
mathod:聚类的常用方法:ward,single,complete,average- dendrogram参数:
linkage_matrix:linkage求的聚类连接矩阵
labels:数据点标签
leaf_rotation:标签旋转度数
import numpy as np
from scipy.cluster.hierarchy import linkage, dendrogram
import matplotlib.pyplot as plt
# 生成随机数据
np.random.seed(0)
data = np.random.rand(10, 2)
# 计算聚类链接矩阵
linkage_matrix = linkage(data, method='ward')
# 输出聚类链接矩阵
print("聚类链接矩阵:\n", linkage_matrix)
# 绘制 Dendrogram
dendrogram(linkage_matrix)
# 添加标题和标签
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Data Points')
plt.ylabel('Distance')
# 显示图形
plt.show()

以上来自与seaborn结合自己的理解,若有不足的地方,还请批评指正。不积跬步无以至千里 共勉!