深度学习手势识别算法实现 - opencv python 计算机竞赛
文章目录
- 1 前言
- 2 项目背景
- 3 任务描述
- 4 环境搭配
- 5 项目实现
-
- 5.1 准备数据
- 5.2 构建网络
- 5.3 开始训练
- 5.4 模型评估
- 6 识别效果
- 7 最后
1 前言
优质竞赛项目系列,今天要分享的是
深度学习手势识别算法实现 - opencv python
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 项目背景
手势识别在深度学习项目是算是比较简单的。这里为了给大家会更好的训练。其中的数据集如下:

3 任务描述
图像分类是根据图像的语义信息将不同类别图像区分开来,是计算机视觉中重要的基本问题。手势识别属于图像分类中的一个细分类问题。虽然与NLP的内容其实没有多大的关系,但是作为深度学习,DNN是一个最为简单的深度学习的算法,它是学习后序CNN、RNN、Lstm以及其他算法深度学习算法的基础。
实践环境:Python3.7,PaddlePaddle1.7.0。
用的仍然是前面多次提到的jupyter notebook,当然我们也可以用本地的pycharm。不过这里需要提醒大家,如果用的是jupyter
notebook作为试验训练,在实验中会占用很大的内存,jupyter
notebook默认路径在c盘,时间久了,我们的c盘会内存爆满,希望我们将其默认路径修改为其他的路径,网上有很多的修改方式,这里限于篇幅就不做说明了。这里需要给大家简要说明:paddlepaddle是百度
AI Studio的一个开源框架,类似于我们以前接触到的tensorflow、keras、caffe、pytorch等深度学习的框架。
4 环境搭配
首先在百度搜索paddle,选择你对应的系统(Windows、macOs、Ubuntu、Centos),然后选择你的安装方式(pip、conda、docker、源码编译),最后选择python的版本(Python2、python3),但是一般选择python3。
左后先则版本(GPU、CPU),但是后期我们用到大量的数据集,因此,我们需要下载GPU版本。,然后将该命令复制到cmd终端,点击安装,这里用到了百度的镜像,可以加快下载安装的速度。
python -m pip install paddlepaddle-gpu==1.8.3.post107 -i https://mirror.baidu.com/pypi/simple
学长电脑是window10系统,用的是pip安装方式,安装的版本是python3,本人的CUDA版本是CUDA10,因此选择的示意图以及安装命令如图所示。这里前提是我们把GPU安装需要的环境配好,网上有很多相关的文章,这里篇幅有限,就不进行展开叙述了。

环境配好了,接下来就该项目实现。
5 项目实现
5.1 准备数据
首先我们导入必要的第三方库。
import os
import time
import random
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import paddle
import paddle.fluid as fluid
import paddle.fluid.layers as layers
from multiprocessing import cpu_count
from paddle.fluid.dygraph import Pool2D,Conv2D
from paddle.fluid.dygraph import Linear
该数据集是学长自己收集标注的数据集(目前较小):包含0-9共就种数字手势,共2073张手势图片。
图片一共有3100100张,格式均为RGB格式文件。在本次实验中,我们选择其中的10%作为测试集,90%作为训练集。通过遍历图片,根据文件夹名称,生成label。
我按照1:9比例划分测试集和训练集,生成train_list 和 test_list,具体实现如下:
data_path = '/home/aistudio/data/data23668/Dataset' # 这里填写自己的数据集的路径,windows的默认路径是\,要将其路径改为/。
character_folders = os.listdir(data_path)
print(character_folders)
if (os.path.exists('./train_data.list')):
os.remove('./train_data.list')
if (os.path.exists('./test_data.list')):
os.remove('./test_data.list')
for character_folder in character_folders:
with open('./train_data.list', 'a') as f_train:
with open('./test_data.list', 'a') as f_test:
if character_folder == '.DS_Store':
continue
character_imgs = os.listdir(os.path.join(data_path, character_folder))
count = 0
for img in character_imgs:
if img == '.DS_Store':
continue
if count % 10 == 0:
f_test.write(os.path.join(data_path, character_folder, img) + '\t' + character_folder + '\n')
else:
f_train.write(os.path.join(data_path, character_folder, img) + '\t' + character_folder + '\n')
count += 1
print('列表已生成')
其效果图如图所示:

这里需要简单的处理图片。需要说明一些函数:
- data_mapper(): 读取图片,对图片进行归一化处理,返回图片和 标签。
- data_reader(): 按照train_list和test_list批量化读取图片。
- train_reader(): 用于训练的数据提供器,乱序、按批次提供数据
- test_reader():用于测试的数据提供器
具体的实现如下:
def data_mapper(sample):
img, label = sample
img = Image.open(img)
img = img.resize((32, 32), Image.ANTIALIAS)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1))
img = img / 255.0
return img, label
def data_reader(data_list_path):
def reader():
with open(data_list_path, 'r') as f:
lines = f.readlines()
for line in lines:
img, label = line.split('\t')
yield img, int(label)
return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 512)
5.2 构建网络
在深度学习中有一个关键的环节就是参数的配置,这些参数设置的恰当程度直接影响这我们的模型训练的效果。
因此,也有特别的一个岗位就叫调参岗,专门用来调参的,这里是通过自己积累的经验来调参数,没有一定的理论支撑,因此,这一块是最耗时间的,当然也是深度学习的瓶颈。
接下来进行参数的设置。
train_parameters = {
"epoch": 1, #训练轮数
"batch_size": 16, #批次大小
"lr":0.002, #学习率
"skip_steps":10, #每10个批次输出一次结果
"save_steps": 30, #每10个批次保存一次结果
"checkpoints":"data/"
}
train_reader = paddle.batch(reader=paddle.reader.shuffle(reader=data_reader('./train_data.list'), buf_size=256),
batch_size=32)
test_reader = paddle.batch(reader=data_reader('./test_data.list'), batch_size=32)
前面也提到深度神经网络(Deep Neural Networks, 简称DNN)是深度学习的基础。DNN网络图如图所示:

首先定义一个神经网络,具体如下
class MyLeNet(fluid.dygraph.Layer):
def __init__(self):
super(MyLeNet, self).__init__()
self.c1 = Conv2D(3, 6, 5, 1)
self.s2 = Pool2D(pool_size=2, pool_type='max', pool_stride=2)
self.c3 = Conv2D(6, 16, 5, 1)
self.s4 = Pool2D(pool_size=2, pool_type='max', pool_stride=2)
self.c5 = Conv2D(16, 120, 5, 1)
self.f6 = Linear(120, 84, act='relu')
self.f7 = Linear(84, 10, act='softmax')
def forward(self, input):
# print(input.shape)
x = self.c1(input)
# print(x.shape)
x = self.s2(x)
# print(x.shape)
x = self.c3(x)
# print(x.shape)
x = self.s4(x)
# print(x.shape)
x = self.c5(x)
# print(x.shape)
x = fluid.layers.reshape(x, shape=[-1, 120])
# print(x.shape)
x = self.f6(x)
y = self.f7(x)
return y
这里需要说明的是,在forward方法中,我们在每一步都给出了打印的print()函数,就是为了方便大家如果不理解其中的步骤,可以在实验中进行打印,通过结果来帮助我们进一步理解DNN的每一步网络构成。
5.3 开始训练
接下来就是训练网络。
为了方便我观察实验中训练的结果,学长引入了matplotlib第三方库,直观的通过图来观察我们的训练结果,具体训练网络代码实现如下:
import matplotlib.pyplot as plt
Iter=0
Iters=[]
all_train_loss=[]
all_train_accs=[]
def draw_train_process(iters,train_loss,train_accs):
title='training loss/training accs'
plt.title(title,fontsize=24)
plt.xlabel('iter',fontsize=14)
plt.ylabel('loss/acc',fontsize=14)
plt.plot(iters,train_loss,color='red',label='training loss')
plt.plot(iters,train_accs,color='green',label='training accs')
plt.legend()
plt.grid()
plt.show()
with fluid.dygraph.guard():
model = MyLeNet() # 模型实例化
model.train() # 训练模式
opt = fluid.optimizer.SGDOptimizer(learning_rate=0.01,
parameter_list=model.parameters()) # 优化器选用SGD随机梯度下降,学习率为0.001.
epochs_num = 250 # 迭代次数
for pass_num in range(epochs_num):
for batch_id, data in enumerate(train_reader()):
images = np.array([x[0].reshape(3, 32, 32) for x in data], np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
# print(images.shape)
image = fluid.dygraph.to_variable(images)
label = fluid.dygraph.to_variable(labels)
predict = model(image) # 预测
# print(predict)
loss = fluid.layers.cross_entropy(predict, label)
avg_loss = fluid.layers.mean(loss) # 获取loss值
acc = fluid.layers.accuracy(predict, label) # 计算精度
Iter += 32
Iters.append(Iter)
all_train_loss.append(loss.numpy()[0])
all_train_accs.append(acc.numpy()[0])
if batch_id != 0 and batch_id % 50 == 0:
print(
"train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num, batch_id, avg_loss.numpy(), acc.numpy()))
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
fluid.save_dygraph(model.state_dict(), 'MyLeNet') # 保存模型
draw_train_process(Iters, all_train_loss, all_train_accs)
训练过程以及结果如下:

前面提到强烈建议大家安装gpu版的paddle框架,因为就是在训练过程中,paddle框架会利用英伟达的GP加速,训练的速度会很快的,而CPU则特别的慢。因此,CPU的paddle框架只是在学习的时候还可以,一旦进行训练,根本不行。
可能GPU需要几秒的训练在CPU可能需要十几分钟甚至高达半个小时。其实不只是paddlepaddle框架建议大家安装GPU版本,其他的类似tensorflow、keras、caffe等框架也是建议大家按安装GPU版本。不过安装起来比较麻烦,还需要大家认真安装。
with fluid.dygraph.guard():
accs = []
model_dict, _ = fluid.load_dygraph('MyLeNet')
model = MyLeNet()
model.load_dict(model_dict) # 加载模型参数
model.eval() # 训练模式
for batch_id, data in enumerate(test_reader()): # 测试集
images = np.array([x[0].reshape(3, 32, 32) for x in data], np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image = fluid.dygraph.to_variable(images)
label = fluid.dygraph.to_variable(labels)
predict = model(image)
acc = fluid.layers.accuracy(predict, label)
accs.append(acc.numpy()[0])
avg_acc = np.mean(accs)
print(avg_acc)
5.4 模型评估
配置好了网络,并且进行了一定的训练,接下来就是对我们训练的模型进行评估,具体实现如下:

结果还可以,这里说明的是,刚开始我们的模型训练评估不可能这么好,可能存在过拟合或者欠拟合的问题,不过更常见的是过拟合,这就需要我们调整我们的epoch、batchsize、激活函数的选择以及优化器、学习率等各种参数,通过不断的调试、训练最好可以得到不错的结果,但是,如果还要更好的模型效果,其实可以将DNN换为更为合适的CNN神经网络模型,效果就会好很多,关于CNN的相关知识以及实验,我们下篇文章在为大家介绍。最后就是我们的模型的预测。
6 识别效果

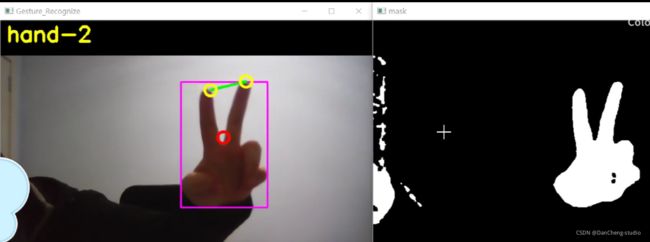
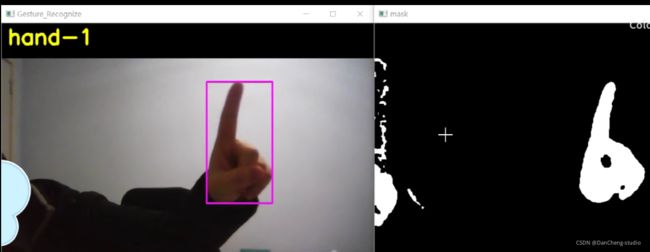
7 最后
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate