用Python手把手教你实现一个爬虫(含前端界面)
目录
- 前言
- 爬虫基本原理
- 使用Python的requests库发送HTTP请求
- 使用BeautifulSoup库解析HTML页面
- 使用PyQt5构建前端界面
- 实现一个完整的爬虫程序
- 结语
前言
随着互联网的飞速发展,再加上科技圈的技术翻天覆地的革新,互联网上每天都会产生海量的数据,这些数据对于企业和个人都具有重要的价值。作为开发者对数据处理并不陌生,关于使用python应该也不会陌生,因为现在python语言已经在初中阶段就开始普及了,关于python的主要功能之一的爬虫想必也不陌生,其实爬虫(也称网络蜘蛛)是一种能够自动抓取网络数据的工具,它可以帮助我们从网络上获取所需的信息。那么本期主题就是关于爬虫的简单使用,本文将手把手地教你如何使用Python实现一个简单的爬虫,并使用 PyQt5 构建一个简单的前端界面来展示爬取的数据。本文将从爬虫的基本原理讲起,然后介绍如何使用Python的requests库来发送HTTP请求,以及如何使用BeautifulSoup库来解析HTML页面,最后实现一个完整的爬虫程序,希望能够对读这篇文章的开发者小伙伴们有所帮助和启发。
爬虫基本原理
作为程序员想必对爬虫这个概念很熟悉,这里再来了解一下爬虫的基本原理,爬虫的工作原理其实很简单,它首先会向目标网站发送一个HTTP请求,然后解析服务器返回的HTML页面,从中提取所需的信息,而这些信息可以是文本、图片、链接等。与此同时,爬虫可以根据这些信息来判断是否需要继续抓取该页面,以及如何抓取该页面的其他链接。另外,爬虫主要是通过python语言来具体实现的,本文也是以python语言来做示例语言进行介绍。下面再来分享一下爬虫的设计思路,具体如下图所示:
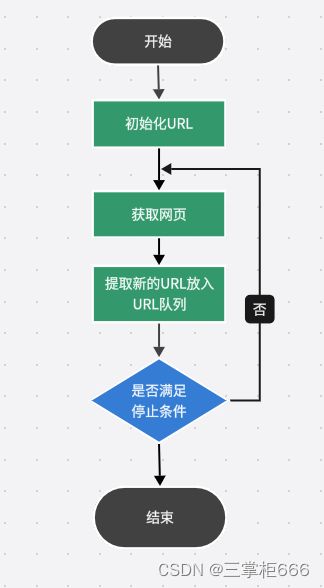
使用Python的requests库发送HTTP请求
使用过python的小伙伴想必都知道它的三方库非常强大且好用,这里要介绍一下python的关于网络请求的库:requests,也就是说Python的requests库是一个非常流行的HTTP库,它可以帮助我们开发人员轻松地发送HTTP请求。
具体使用requests库发送HTTP请求的步骤分为以下几步:
- 导入requests库;
- 创建一个Session对象;
- 使用Session对象发送HTTP请求;
- 获取HTTP请求的响应。
接下来分享一下具体的使用方法,下面就是一个使用requests库发送HTTP请求的示例代码:
import requests
# 创建一个Session对象
session = requests.Session()
# 发送HTTP请求
response = session.get('https://www.baidu.com')
# 获取HTTP请求的响应
print(response.text)使用BeautifulSoup库解析HTML页面
接下来再来介绍一下解析HTML页面的三方库,在python中也有对应的库来支持解析HTML页面,BeautifulSoup是一个非常流行的HTML解析库,它可以帮助我们轻松地解析HTML页面。具体使用BeautifulSoup库解析HTML页面的步骤如下所示:
- 导入BeautifulSoup库
- 创建一个BeautifulSoup对象
- 使用BeautifulSoup对象解析HTML页面
- 获取解析结果
接下来分享一下具体的使用方法,下面就是一个使用BeautifulSoup库解析HTML页面的示例代码:
from bs4 import BeautifulSoup
# 创建一个BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')
# 获取解析结果
print(soup.title.text)
使用PyQt5构建前端界面
接下来分享本文课题最后一个环节,就是通过前端界面展示爬虫爬取的数据,这里是通过使用PyQt5来构建前端界面,其实PyQt5是一个跨平台的GUI库,它可以帮助我们轻松地构建图形界面。具体使用PyQt5构建前端界面的步骤如下所示:
- 导入PyQt5库
- 创建一个QApplication对象
- 创建一个主窗口对象
- 在主窗口对象中添加控件
- 设置控件的属性
- 连接控件的信号和槽
接下来分享一下具体的使用方法,下面就是一个使用PyQt5构建前端界面的示例代码:
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QPushButton, QLabel
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
# 设置窗口标题
self.setWindowTitle("爬虫")
# 创建一个按钮
self.button = QPushButton("开始爬虫")
# 创建一个标签
self.label = QLabel("爬虫结果")
# 设置按钮的槽函数
self.button.clicked.connect(self.on_button_clicked)
# 在主窗口对象中添加控件
self.setCentralWidget(self.button)
# 设置控件的属性
self.label.setAlignment(Qt.AlignCenter)
# 显示窗口
self.show()
def on_button_clicked(self):
# 爬虫逻辑
# 更新标签的内容
self.label.setText("爬虫完成")
# 创建一个QApplication对象
app = QApplication(sys.argv)
# 创建一个主窗口对象
window = MainWindow()
# 进入主循环
sys.exit(app.exec_())实现一个完整的爬虫程序
经过上面分享的关键的两个爬虫必备的三方库使用,接下来我们将把前面的2个知识点组合起来,实现一个完整的爬虫程序。这个爬虫程序将从指定的URL开始,抓取该页面上的所有链接,然后并把这些链接存储到一个文件中。具体的示例代码如下所示:
import requests
from bs4 import BeautifulSoup
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QPushButton, QLabel
# 要抓取的URL
url = 'https://www.baidu.com'
# 创建一个Session对象
session = requests.Session()
# 发送HTTP请求
response = session.get(url)
# 获取HTTP请求的响应
html_doc = response.text
# 创建一个BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')
# 获取所有链接
links = soup.find_all('a')
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
# 设置窗口标题
self.setWindowTitle("爬虫")
# 创建一个按钮
self.button = QPushButton("开始爬虫")
# 创建一个标签
self.label = QLabel("爬虫结果")
# 设置按钮的槽函数
self.button.clicked.connect(self.on_button_clicked)
# 在主窗口对象中添加控件
self.setCentralWidget(self.button)
# 设置控件的属性
self.label.setAlignment(Qt.AlignCenter)
# 显示窗口
self.show()
def on_button_clicked(self):
# 爬虫逻辑
# 更新标签的内容
self.label.setText("爬虫完成")
# 创建一个QApplication对象
app = QApplication(sys.argv)
# 创建一个主窗口对象
window = MainWindow()
# 进入主循环
sys.exit(app.exec_())结语
通过本文的关于使用python来实现爬虫功能的介绍,且使用Python实现一个简单的爬虫示例,想必读者都学会了吧?本文先从爬虫的基本原理讲起,然后介绍了如何使用Python的requests库来发送HTTP请求,以及如何使用BeautifulSoup库来解析HTML页面,再到最后的前端界面展示爬取的数据,最最后,将这些拆解的知识点组合起来,实现了一个完整的爬虫程序。由于本案例属于简单爬虫程序,本文所介绍的只是较为简单的示例,希望能够读者带来一些启示,如果读者想要更深入了解和使用爬虫,请移步python开发者社区找找思路,也希望python相关领域大佬放过,高手请飘过。希望本教程能够帮助你学习爬虫,并能够实现你自己的爬虫程序,谢谢观赏!欢迎在评论区交流!