分类数据的分析-卡方检验运用
概念
分类数据
观测值只能被分为几个类别中的某一类,如某个公民的国籍,也称定性数据。
多项试验
当分类数据只涉及到两个响应结果(是或不是,成功或失败等等),就是一个二项分布。如果分类数据涉及到两个以上的响应结果,则是一个多项试验。
多项试验的特点:
1. 这种试验有n个同质的试验构成(进行了样本为n次试验)
2.每次试验都有k种可能都结果,这些结果被称为类
3.对于每次试验,这k中结果发生都概率用p1,p2,...,pk表示,并且在每次试验中都相同,其中p1+p2+...+pk=1
4.每次试验相互独立
5.感兴趣的随机变量是格子计数(cell counts):n1,n2,...,nk,即落入k个类中每一类的观测值数目。
分类概率的检验
单向表
只有一个变量被分类,试验的结果可以汇总在一个单向表(one-way table)内
举例:
一家大型连锁超市想根据消费者在店内购买的面包的品牌,来了解消费者偏好。假设这家超市销售三个品牌的面包——两个市场上的大品牌A和B,以及这家连锁店自由品牌。为进行这次调查,随机抽取来150个消费者作为观测对象,将每中品牌的皮娜好数量记录下来,如下表:
消费者面包品牌偏好调查的结果
| 品牌A |
品牌B |
自由品牌 |
| 61 |
53 |
36 |
试分析消费者对各个品牌对偏好比例是否有差异。
分析:
首先,这个试验符合多项试验对条件。我们将p1,p2,p3分别表示为消费者偏好品牌A,B和自由品牌对比例,这个比例的真实数值未知。
为了判断消费者是否对这些品牌存在特殊偏好,我们将原假设确定为消费者对面包品牌存在相同对偏好(即p1=p2=p3=1/3),备选假设是消费者至少对一个品牌对偏好较大(即p1,p2,p3至少有一个超过1/3)。
1. 因此我们的假设是:
H0:p1=p2=p3=1/3
Ha:至少存在一个概率大于1/3
2. 计算统计量卡方
如果H0为真,则各面包品牌消费者人数E1=E2=E3=n*p1=50人,计数卡方统计量χ2:
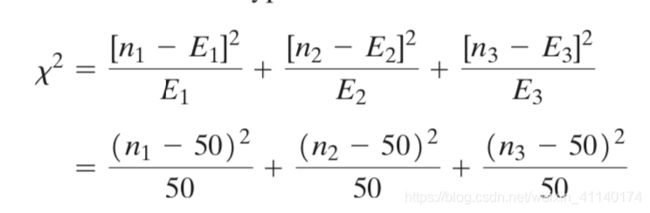
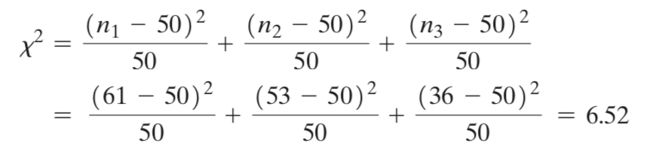
3. 做出判断
当H0为真时,此问题的χ2近似符合卡方分布,对这个简单对分类,自由度为3-1=2,取α=0.05, 则χ2(α=0.05)=5.99,拒绝域为χ2>χ2(α=0.05)
由于χ2=6.52>5.99,因此拒绝原假设,即在显著性水平α=0.05下,我们有理由相信,消费者总体对三个品牌中至少一个存在较大对偏好

单向表卡方检验方法

单向表卡方检验需要满足对条件
1.进行了一次多项试验
2.样本量n足够大,要求每个类都要满足期望计数Ei大于等于5
双向(列联)表
有两个变量被分类,试验的结果可以汇总在一个双向表(two-way table)内。
举例
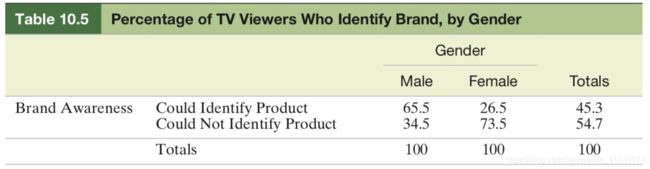
研究人员调查观众都性别和品牌意识之间都关系,结果如下表:
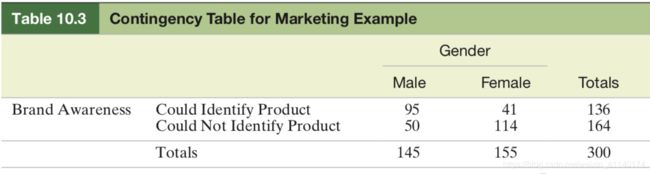
could Identify Product为能够识别品牌产品,试分析品牌意识都男女观众是否有现在差异
1. 原假设和备选假设
H0:男女对品牌识别没有差别
Ha:男女对品牌识别有差别
2. 计算统计量卡方
为了表示方便,表10.3的观察频数和概率分别为n11,n12,n13,n14,p11,p12,p13,p14,
如下图:
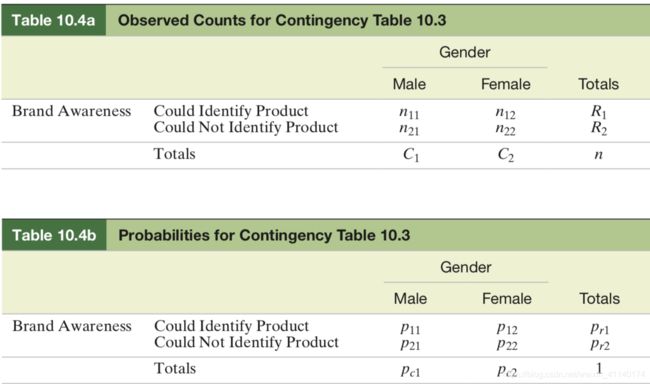
其中pr1,pr2,pc1,pc2称为行和列的边际概率(marginal probability)
先计算各单元格的频次的期望,假设H0为真(即男女没有差别),则
E11=n*p11=n*pr1*pc1(样本总数*识别出品牌的观众的概率*男生占总人群的概率)
由于真实概率未知,用(R1/n)估计pr1,(C1/n)估计pc1,则
E11=R1*C1/n=136X145/300=65.73
同理,可以计算
E12=R1*C2/n=70.27,E21=R2*C1/n=79.27,E22=R2*C2/n=84.73
计算卡方值为:

3. 做出判断
在一个双向列联表中检验独立假设时,自由度为(r-1)*(c-1)=(2-1)X(2-1)=1,取α=0.05, 则χ2(α=0.05)=3.814,拒绝域为χ2>χ2(α=0.05)
由于χ2=46。14>χ2(α=0.05)=3.814,因此拒绝原假设,即男女在识别品牌上有差异。
两个变量的依赖关系在将观测值转化为比例后看得更清楚,在这个例子中,选择观众的性别作为基础变量,然后将第二各变量(这里是观众的品牌意识)的每个水平的响应值表示为基础变量分类汇总的百分比,如男性识别品牌的比例为95/145=65.5%。如果观众的性别和品牌意识是独立的,则表中每个单元格的百分比应该近似等于行百分比。此例中,男女百分比明显有差异:
双向表卡方检验方法

双向表卡方检验需要满足对条件
1.n各观测到的计数是从总体中舟曲的随机样本,我们可以将此视为一个具有rXc中可行结果的多项试验
2.样本量n足够大,要求每个单元格都要满足期望计数Eij大于等于5
使用卡方检验需要注意的地方
1.如果期望计数很小时,应该避免使用卡方概率分布作为卡方统计量的抽样分布的近似,这种近似会非常弱,真实的α水平将与制表值有很大的差异。作为经验法则,单元格的期望计数至少包含5个。
2.如果卡方值没有超过已经确定的卡方临界值,只能说不能拒绝原假设,而不能说接受原假设,否则可能会犯第二类错误,且犯这种错误的概率是未知的。
3.如果卡方值确实超过已经确定的卡方临界值,我们要谨慎,避免推断两种分类变量存在因果关系,只能说这两种变量在统计意义上是相互依赖的。