Polish Questions to Catch the Inclination of Large Language Model: A Technical Report
Polish Questions to Catch the Inclination of Large Language Model: A Technical Report
Contents
- Polish Questions to Catch the Inclination of Large Language Model: A Technical Report
-
- Introduction
- Data Augmentation: from bad questions to good questions
-
- Methodology
- Prompts
- Code
- Experiment
- Dataset construction
- Weakness
- Knowledge transfer: enable model to polish questions
-
- Baseline
- Fine-tune GPT-2
-
- Text generation paradigm
- Seq2seq-like paradigm
- Few-shot prompt gpt-3.5-turbo
- Fine-tune FLAN-T5
- Discussion
-
- Chain-of-Thought prompt, really necessary?
- Tradeoff between performance and format
- Bottleneck of this work
- Further study
Introduction
In daily use of LLM, especially ChatGPT, it can be observed that one problem with different expressions may gain different outcomes. If the problem is described properly, LLM will solve it perfectly, while it may fail to solve the problem in another expression. As the meaning and conditions in different expressions are the same, what influences the performance of LLM, and is there a way to polish questions from bad expressions to good ones?
Data Augmentation: from bad questions to good questions
Currently, there is no dataset of “polishing question”, which provides “bad” and “good” versions of the same question. Therefore, it is necessary to generate the bad to good question pair first.
Methodology
There are two LLM, examiner model and examinee model. The examiner model will try to polish the original questions to make it easier to solve, and the examinee model will try to solve the rewritten questions to quantify the quality of the question.
To evaluate the quality of rewritten questions, each rewritten question will be answered by examinee model for m m m times. The frequency of correct answer F ( A ∣ Q ) F(A|Q) F(A∣Q) is considered as the approximation of the probability of answering the question correctly P ( A ∣ Q ) P(A|Q) P(A∣Q), also as the score of the quality of a question S ( Q ) S(Q) S(Q).
The whole data augmentation process is a beam search process with beam width of w w w and search depth of d d d. At each step, the original question will be rewritten by examiner model into n n n different versions, then rewritten questions will be scored as described above. The top w w w versions will be reserved to the next step.
Prompts
System prompt of gpt-3.5.turbo:
You are a helpful assistant.
Prompt template for rewriting questions:
Please rewrite the following question to make it easier to solve.
Question: [QUESTION]
Prompt template for scoring questions:
Q: [QUESTION]
A:
Code
Method polish is used to polish one question and collect its polishing trajectory.
def polish(dataset, base_question, answer, examiner_config, examinee_config, step_num, beam_width):
base_score = exam(dataset, base_question, answer, examinee_config)
polish_step = [[(base_score, len(base_question), base_question)]]
for index in range(1, step_num):
last_step = polish_step[index-1]
this_step = []
min_score = 1.0
max_score = 0.0
for score, length, question in last_step:
min_score = min(min_score, score)
max_score = max(max_score, score)
if min_score == 1.0: # if the min_score is equal to 1, no need to continue
break
for score, length, question in last_step:
this_step += augment(dataset, question, examiner_config) # rewrite questions
this_step = select(dataset, min_score, this_step, answer, beam_width, examinee_config, last_step) # score all rewritten questions and select top beam_width questions
if len(this_step) == 0:
this_step = last_step
polish_step.append(this_step)
print('Polish step#'+str(index), min_score, max_score)
return polish_step
Method augment is used to call LLM API and collect the rewritten versions of original questions.
def augment(dataset, question, examiner_config):
if dataset == 'GSM8K':
query = query_assemble.augment_GSM8K(question) # fill questions into template
response = llm.get_response(examiner_config, query) # call LLM API
augmentations = []
for choice in response['choices']:
if choice['finish_reason'] == 'stop': # throw uncomplete response
augmentations.append(choice['message']['content'])
return augmentations
Method select is used to select top w w w rewritten questions. The first key is score and the second key is length of question.
def select(dataset, base_score, candidates, answer, beam_width, examinee_config, last_step):
question_score = []
for candidate in candidates:
score = exam(dataset, candidate, answer, examinee_config)
if score < base_score or score == 0.0:
continue
question_score.append((score, len(candidate), candidate))
question_score += last_step
question_score.sort(key=lambda x: (-x[0], x[1]))
return question_score[:beam_width]
Method exam is used to call LLM API and collect the m m m responses of each question.
def exam(dataset, question, answer, examinee_config):
with open(r'./augmentation/demo.txt', 'r') as f:
demo = f.read()
if dataset == 'GSM8K':
query = query_assemble.score_GSM8K(demo, question)
response = llm.get_response(examinee_config, query)
predicts = []
total = examinee_config['n']
for choice in response['choices']:
predict = metrics.clean_response(dataset, choice['message']['content']) # extract the last number in response as the answer
predicts.append(predict)
count = Counter(predicts)
correct = count[answer]
# print(predicts)
return correct/total
Experiment
The config in experiment is shown as follows:
raw_datasets: ['GSM8K']
data_formats:
CSQA: jsonl
GSM8K: jsonl
examiner_config:
model: gpt-3.5-turbo
batch_size: 32
temperature: 1.0
max_tokens: 256
frequency_penalty: 0
presence_penalty: 0
n: 16
examinee_config:
model: gpt-3.5-turbo
batch_size: 32
temperature: 1.0
max_tokens: 512
frequency_penalty: 0
presence_penalty: 0
n: 20
step_num: 3
beam_width: 4
The experiment is implemented on GSM8K, a graduate school math question dataset. Both examiner and examinee models are gpt-3.5-turbo, for its excellent performance in text generation and arithmetic reasoning. The beam search is set to be shallow, since deep search will oversimplify the question, such as merging several logic steps into one step or leaking the answer in the question. Therefore, the number of versions to be rewritten n n n is set to 16, the beam width w w w is set to 4 and the search depth d d d is set to 3. To ensure the score of questions is enough to differentiate bad questions and good questions, the number of times examinee model should answer for every question m m m is set to 20.
In total, 331 questions are polished and the polish trajectories in beam search are saved. An example of polish trajectories is:
{
"base_question": {
"question": "A concert ticket costs $40. Mr. Benson bought 12 tickets and received a 5% discount for every ticket bought that exceeds 10. How much did Mr. Benson pay in all?",
"score": 0.5
},
"best_question": {
"question": "Question: Mr. Benson bought 12 concert tickets, each costing $40. If he received a 5% discount for each of the extra 2 tickets, what was the total amount he paid?",
"score": 0.9
},
"log": [
[
{
"question": "A concert ticket costs $40. Mr. Benson bought 12 tickets and received a 5% discount for every ticket bought that exceeds 10. How much did Mr. Benson pay in all?",
"score": 0.5
}
],
[
{
"question": "Question: Mr. Benson bought 12 concert tickets at a price of $40 each. If he received a 5% discount for every ticket bought that exceeds 10, what was the total amount Mr. Benson paid for all the tickets?",
"score": 0.85
},
{
"question": "Question: Mr. Benson bought 12 concert tickets for $40 each. He received a 5% discount for every ticket purchased beyond 10. What was the total amount Mr. Benson paid?",
"score": 0.8
},
{
"question": "Question: Mr. Benson bought 12 concert tickets, each costing $40. If he received a 5% discount for each of the tickets beyond the first 10, what was the total amount he paid?",
"score": 0.8
},
{
"question": "Question: Mr. Benson bought 12 concert tickets for $40 each. He received a 5% discount for every ticket bought above 10. What was the total amount Mr. Benson paid?",
"score": 0.7
}
],
[
{
"question": "Question: Mr. Benson bought 12 concert tickets, each costing $40. If he received a 5% discount for each of the extra 2 tickets, what was the total amount he paid?",
"score": 0.9
},
{
"question": "Mr. Benson bought 12 concert tickets, with the first 10 tickets costing $40 each and the last 2 tickets receiving a 5% discount. What was the total amount he paid?",
"score": 0.9
},
{
"question": "Question: Mr. Benson purchased a total of 12 concert tickets. Each ticket cost $40. If Mr. Benson received a 5% discount for every ticket beyond the first 10, what was the total cost of all the tickets he bought?",
"score": 0.9
},
{
"question": "Question: Mr. Benson bought 12 concert tickets, each costing $40. He received a 5% discount for the additional two tickets. What was the total amount he paid?",
"score": 0.85
}
]
]
}
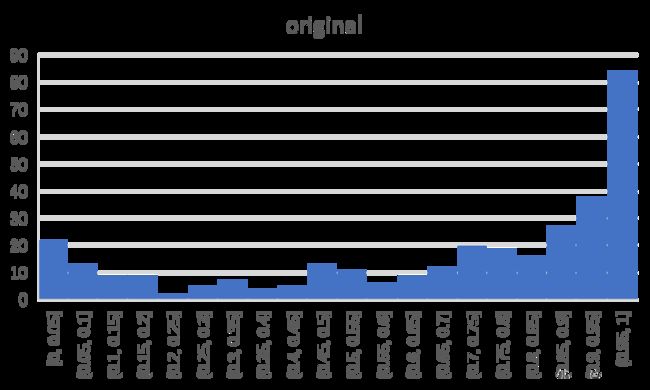
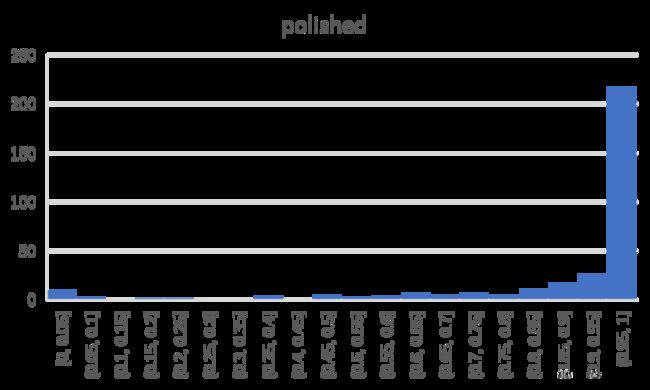
The two figures above show the score distribution of original and polished questions. It can be observed that the overall score is greatly improved, and most polished questions achieve score over 0.9. According to statistics, ∑ o r i g i n a l S ( Q ) = 232 \sum_{original} S(Q)=232 ∑originalS(Q)=232 and ∑ p o l i s h e d S ( Q ) = 295 \sum_{polished}S(Q)=295 ∑polishedS(Q)=295, which means the expected accuracies of original questions and polished question are 70.1% and 89.1% respectively. In the real test (let the examinee model answer each question only once), the accuracies of original questions and polished question are 71.3% and 84.0% respectively.
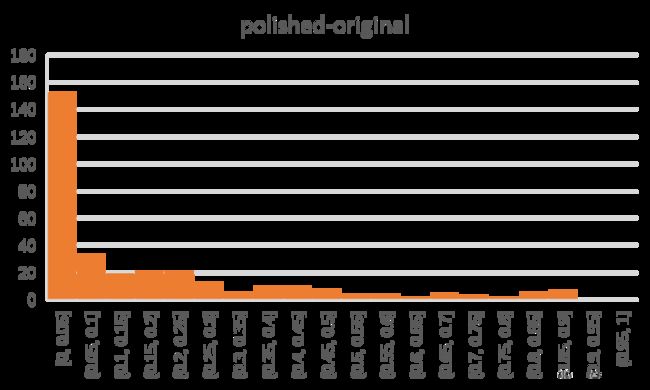
To see the improvement more directly, the gap between scores of polished and original questions is shown above. Half of the questions gain an improvement of 0.1 or more in score.
Dataset construction
Though most of the polished versions gain score improvement, there are still questions that do not and there may exist multiple good versions of one question. To filter the unimproved questions and make full use of the polish trajectories, only “eligible” polished question will be selected and pair with its original version. The function to judge whether a polished question is eligible is shown below.
def eligible(base, best, now): # original score, best polished score and currect score
if now <= base:
return False
if now <= 0.5 and now - base < 0.4: # current score should not be too low, and show enough improvement
return False
if now - base <= 0.05: # an improvement of 0.05 may be a deviation
return False
if best - now >= 0.3: # current score should not be much worse than best score
return False
return True
After filtering and pairing, the dataset consists of 931 (original question, polished question) pairs.
Weakness
The cost of scoring is quite high, because the generation format of gpt-3.5-turbo is not limited and it will generate long response, containing chain-of-thought of the question, which occupies a large number of output tokens. However, restrict the output format of gpt-3.5-turbo will harm the performance of gpt-3.5-turbo in arithmetic reasoning, which will be discussed in the following sections. Moreover, the real performance of polished questions is marginally lower than expected, which might be caused by inadequate m m m or polished samples.
Knowledge transfer: enable model to polish questions
As the data is collected, the next step is to “teach” models how to polish a question. This section will display all attempts.
Baseline
The baseline is to input the original questions to gpt-3.5-turbo. Since gpt-3.5-turbo can generate chain-of-thought without any explicit prompt, no format restriction is applied on gpt-3.5-turbo and the last number in the response is extracted as the output answer. Though it is not rigorous, gpt-3.5-turbo still achieve surprising performance with an accuracy of 0.69.
Fine-tune GPT-2
In the experiment, the largest version of GPT-2, gpt2-large (1.5B), is chosen as the backbone LLM.
Text generation paradigm
The problem of question polishing is considered to be the sub-task of style transfer: converting the original question to a new style that LLM prefers. Following a blog about fine-tuning gpt2 for style transfer, the (original question, polished question) pair is organized in the following format:
[ORIGINAL QUESTION]->[POLISHED QUESTION]
Each line contains one pair of questions, and all of them are saved to a txt file for text generation fine-tune.
text_path = r'./augmentation/GSM8K/training_data.txt'
with open(text_path, 'w', encoding='utf-8') as f:
for item in train_data:
new_line = '' + item[0] + '->'
+ item[1] + '\n'
f.write(new_line)
With the huggingface Trainer class, fine-tune GPT-2 is rather easy.
def distill_trainer(text_path, epochs, model_name, batch_size, output_dir):
model = GPT2LMHeadModel.from_pretrained(model_name, device_map='auto')
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
train_dataset = TextDataset(tokenizer=tokenizer, file_path=text_path, block_size=256)
training_args = TrainingArguments(
output_dir=output_dir,
num_train_epochs=epochs,
per_device_train_batch_size=batch_size,
warmup_steps=500,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
)
trainer.train()
# trainer.save_model(output_dir)
model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
After training, the loss achieves 0.2. However, the results are disappointing that questions polished by the fine-tuned GPT-2 only gains 0.06. When inspect the polished questions of the GPT-2, it is found that the meaning and conditions in the original question are totally falsified. As shown below, GPT-2 seems have not learnt the core discipline of polishing is DO NOT CHANGE THE MEANING AND CONDITION OF QUESTION.
Original: Cody eats three times as many cookies as Amir eats. If Amir eats 5 cookies, how many cookies do both of them eat together?
Polished: If Cody eats 10 cookies and Amir eats 15 cookies per day, how many cookies do the two of them eat in a week?
In the text generation paradigm, the data collator will cut the training text into equal-length (e.g., 256-token) pieces, so one [POLISHED QUESTION][ORIGINAL QUESTION]->
Seq2seq-like paradigm
As style transfer is a typical seq2seq problem, a seq2seq-like paradigm is more suitable for question polishing problem than text generation paradigm. Although GPT is a generative model, seq2seq-like paradigm can ensure one (original, polished) pair will not be separated.
Following a work about distill knowledge to gpt-2, each pair will be encoded into two kinds of token id sequences. inputs is a batch of target sequences, including original and polished questions and bases only contains original questions.
def formulate(base):
return '' + base + '->'
def batch_encode(params, batch_data, tokenizer):
inputs = [formulate(base)+polished+'' for base, polished in batch_data]
# print(inputs[0])
inputs = tokenizer.batch_encode_plus(
inputs,
max_length=params['MAX_INPUT_KG_LENGTH'],
pad_to_max_length=True,
truncation=True,
padding='max_length',
return_tensors='pt',
)
bases = [formulate(base) for base, polished in batch_data]
# print(bases[0])
bases = tokenizer.batch_encode_plus(
bases,
max_length=params['MAX_INPUT_KG_LENGTH'],
pad_to_max_length=True,
truncation=True,
padding='max_length',
return_tensors='pt',
)
return {
'inputs_ids': inputs['input_ids'].to(dtype=torch.long),
'inputs_mask': inputs['attention_mask'].to(dtype=torch.long),
'bases_ids': bases['input_ids'].to(dtype=torch.long),
'bases_mask': bases['attention_mask'].to(dtype=torch.long),
}
Method distill will fine-tune the GPT-2 model, encouraging model generate target sequences.
def distill(tokenizer, model, data, optimizer):
model.train()
optimizer.zero_grad()
ids = data['inputs_ids'].to(device, dtype=torch.long)
ids[data['inputs_ids'] == tokenizer.pad_token_id] = 0
mask = data['inputs_mask'].to(device, dtype=torch.long)
bases_mask = data['bases_mask'].to(device, dtype=torch.long)
labels = data['inputs_ids'].clone().detach()
labels[data['inputs_ids'] == tokenizer.pad_token_id] = -100 # set to -100 ignore the pad tokens in loss computing
for index, base_mask in zip(range(labels.size(0)), bases_mask):
labels[index, :base_mask.sum()] = torch.tensor([-100 for i in range(base_mask.sum())]).to(device) # also mask the original part in input
labels = labels.to(device, dtype=torch.long)
outputs = model(input_ids=ids, attention_mask=mask, labels=labels)
loss = outputs.loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
Unfortunately, this attempt still failed and encountered the same problem. GPT-2 fails to keep the meaning and conditions in questions unchanged.
Few-shot prompt gpt-3.5-turbo
If GPT-2 is too small to learn the process of question polishing, gpt-3.5-turbo will 175B parameters must be large enough. Previous studies show that few-shot prompt greatly improves the performance of LLM, demonstrating to LLM what output users want. Additionally, gpt-3.5-turbo is good at understanding and following the commands of polishing a question.
The few-shot prompt template used is shown below.
System prompt: You are a helpful AI question rewriter. Please read the given exemplars carefully and rewrite the question.
The following exemplars show how to rewrite questions to make them easier:
[DEMOS]
Now please rewrite the following question. Don't omit any useful information, especially the numbers.
To retrieve the demonstrations for few-shot prompt, the similarity between current question and all original questions in dataset is computed. Then, top 4 original question and its polished version with the highest score will be selected as the demonstrations.
def retrieve_demo(demo_ids, tokenizer, text, demo_num):
text_ids = tokenizer.encode_plus(
text,
max_length=150,
pad_to_max_length=True,
truncation=True,
padding='max_length',
return_tensors='np'
)
text_ids = text_ids['input_ids'].astype(dtype='int64')
demo_len = np.sqrt(np.sum(demo_ids*demo_ids, axis=1))
text_len = np.sqrt(np.sum(text_ids*text_ids))
similarity = (text_ids * demo_ids.T)/demo_len/text_len
idx = similarity.argsort().tolist()[0][-demo_num:]
return idx
However, 4 (or more) demonstrations seem to be not enough to show the key in question polishing. Even though much effort is made in adjusting the few-shot prompt, the polished questions does not outperform their original versions. In the experiment, the accuracy on polished questions is 0.68 and accuracy on original questions is 0.69. Among 100 questions in test dataset, 16 of the polished questions are answered correctly while their original versions are not, and 17 of polished questions are not answered correctly while their original versions can be answered correctly.
An example of polished version outperforms the original one:
Original: Every day, Wendi feeds each of her chickens three cups of mixed chicken feed, containing seeds, mealworms and vegetables to help keep them healthy. She gives the chickens their feed in three separate meals. In the morning, she gives her flock of chickens 15 cups of feed. In the afternoon, she gives her chickens another 25 cups of feed. How many cups of feed does she need to give her chickens in the final meal of the day if the size of Wendi's flock is 20 chickens?
Polished: If Wendi feeds each of her chickens three cups of mixed chicken feed, and she has a flock of 20 chickens, then how many cups of feed does she need to give her chickens in the final meal of the day, considering that she gives them 15 cups of feed in the morning and 25 cups of feed in the afternoon?
An opposite example:
Original: Melanie is a door-to-door saleswoman. She sold a third of her vacuum cleaners at the green house, 2 more to the red house, and half of what was left at the orange house. If Melanie has 5 vacuum cleaners left, how many did she start with?
Polished: If Melanie has 5 vacuum cleaners left after selling a third of them at the green house, 2 more at the red house, and half of what was left at the orange house, how many vacuum cleaners did she start with?
Fine-tune FLAN-T5
T5 is a 100% seq2seq model, and FLAN-T5 is its fine-tuned version with great performance improvement on a large number of tasks. Therefore FLAN-T5 should be more competent than GPT-2 in question polishing task.
At this time, Seq2SeqTrainer class of huggingface is used for fine-tuning. Inspired by a work about refining output of LLM, considering the similarity between original and polished version might be helpful. In the t5_trainer class, method compute_loss is overwritten and the similarity is added to the loss function. A hyper-parameter α \alpha α is used to control the weight of similarity in loss function.
class t5_trainer(Seq2SeqTrainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs['labels']
outputs = model(**inputs)
loss = outputs['loss']
logits = outputs['logits']
pred = logits.argmax(dim=2)
simi = metrics.similarity_ids(inputs['input_ids'], pred)
return loss + model_params['ALPHA']*(1-simi)
Also, a method compute_metrics is needed to evaluate the model in Seq2SeqTrainer class.
def compute_metrics(eval_preds):
preds, labels = eval_preds # To be compatible with the Seq2Seq Trainer, answer of the question is sent by labels
if isinstance(preds, tuple):
preds = preds[0]
preds = np.where(preds != -100, preds, tokenizer.pad_token_id)
pred_texts = tokenizer.batch_decode(preds, skip_special_tokens=True)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
queries = [query_assemble.score_GSM8K('', item) for item in pred_texts]
outputs = llm.async_query(test_config, queries)
outputs = [metrics.clean_response('GSM8K', item[0]) for item in outputs]
correct = sum([int(decoded_labels[i]) == outputs[i] for i in range(len(labels))])
return {'acc': correct/len(outputs)}
Besides, the training and evaluation data must be converted into Dataset type.
def preprocess_train(sample, padding='max_length'):
inputs = ["Rewrite: " + item for item in sample['base']]
model_inputs = tokenizer(inputs, max_length=256, padding=padding, truncation=True)
labels = tokenizer(text_target=sample['polished'], max_length=256, padding=padding, truncation=True)
if padding == "max_length":
labels["input_ids"] = [[(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]]
model_inputs["labels"] = labels["input_ids"]
return model_inputs
def preprocess_eval(sample, padding='max_length'):
inputs = ["Rewrite: " + item for item in sample['question']]
model_inputs = tokenizer(inputs, max_length=256, padding=padding, truncation=True)
labels = tokenizer(sample['answer'], max_length=256, padding=padding, truncation=True)
model_inputs['labels'] = labels['input_ids']
return model_inputs
After these work, FLAN-T5-XL with 3B parameters can be fine-tuned by the following code.
model_params = {
"MODEL_NAME": 'google/flan-t5-xl',
"TRAIN_BATCH_SIZE": 4, # batch size within each alternative training loop
"EVAL_BATCH_SIZE": 4,
"TRAIN_EPOCHS": 1, # number of training epochs
"LEARNING_RATE": 5e-5,
"ALPHA": 0,
"SEED": 42, # set seed for reproducibility
}
label_pad_token_id = -100
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=8
)
model_dir = f"./distilled_model/{model_params['MODEL_NAME'].split('/')[1]}"
training_args = Seq2SeqTrainingArguments(
output_dir=model_dir,
per_device_train_batch_size=model_params['TRAIN_BATCH_SIZE'],
per_device_eval_batch_size=model_params['EVAL_BATCH_SIZE'],
predict_with_generate=True,
fp16=False, # Overflows with fp16
learning_rate=model_params['LEARNING_RATE'],
num_train_epochs=model_params['TRAIN_EPOCHS'],
# logging & evaluation strategies
generation_max_length=512,
logging_dir=f"{model_dir}/logs",
logging_strategy="steps",
logging_steps=500,
evaluation_strategy="epoch",
save_strategy="epoch",
save_total_limit=2,
load_best_model_at_end=True,
)
# Create Trainer instance
trainer = t5_trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=tokenized_train,
eval_dataset=tokenized_eval,
compute_metrics=compute_metrics,
)
trainer.train()
The results show that FLAN-T5 does outperform GPT-2 in Seq2Seq task, but not enough. The real test accuracy of questions polished by fine-tuned FLAN-T5 is 0.57, which is much higher than performance of GPT-2, but lower than baseline. Maybe the model just learnt how to retain the existing information in original question rather than reorganize them in a better manner.
A confusing fact is that many outputs of the FLAN-T5 contains two rewritten versions, and the second version is prefixed by "Rewritten question: ", which never appears in the training data.
Original: Cody eats three times as many cookies as Amir eats. If Amir eats 5 cookies,\u00a0how many cookies do both of them eat together?
Polished: If Amir eats 5 cookies and Cody eats three times as many cookies as Amir, how many cookies do both of them eat together? Rewritten question: If Amir eats 5 cookies and Cody eats three times as many cookies as Amir, how many cookies do both of them eat together?
Discussion
Chain-of-Thought prompt, really necessary?
Previous works definitely show that Chain-of-Thought prompt is a powerful method to enable LLM to solve complex tasks, especially reasoning ones. However, few-shot CoT and zero-shot CoT did not implement experiments on gpt-3.5-turbo. According to this work, gpt-3.5-turbo shows strong ability in arithmetic reasoning that it can generate reasoning logic without any explicit CoT prompt. In the experiment, the query template does not contain any few-shot demos or words that encourages gpt-3.5-turbo to “think step by step”, but it does solve the question successfully with a correct reasoning logic.

Compared with other “more generative” models (e.g., GPT-3, text-davinci-002), gpt-3.5-turbo is optimized for chat, and may have learnt the logical requirement in human conversation, offering logical reasoning steps spontaneously.
Tradeoff between performance and format
Another problem occurred in this work is how to extract the answer in the full response from LLM. An intuitive method is to provide few-shot samples or instruction to LLM and restrict its output format.
Therefore, 3 kinds of prompts are applied to restrict the output format of LLM. The strictest one gives an instruction forcing the LLM do not output any other words except the answer and offers an example. The second one gives several demonstrations of “The answer is x x x” format. The last one does not give any prompt (or add classic “Let’s think step by step.” as the prefix of the answer) and LLM can output discretionarily.

The results show that these attempts to restrict the output format of LLM may harm its performance, especially the strictest one, reducing its accuracy dramatically (all the experiments are implemented on gpt-3.5-turbo).
Bottleneck of this work
Results of real test show the polished questions in dataset do outperform their original versions in accuracy, but the language models cannot learn from them. Most possible reason is that the scale of dataset is too small to fine-tune LLMs with more than 1B parameters. Unfortunately, there is no research on how much data is needed to fine-tune a LLM with different scales, which is also greatly influenced by the type of the task. At least according to current experiment, a dataset with less than 1k items is obviously not enough. Besides, the distribution of good questions may be very complicated and such small dataset cannot describe it comprehensively.
Another dispiriting fact is that the good polished questions are sampled from random distributions of the LLM, which means the whether the LLM outputs good or bad questions, its parameters are identical. In other words, polishing question may be not an inherent ability of LLM. When try to transfer knowledge from LLM using more advanced distillation techniques (e.g., aligning parameters in teacher and student models, assuming the parameter of LLM can be accessed), the student model cannot learn from the teacher model.
Further study
Compared with the large number of parameters in LLM, the limited scale of dataset is not sufficient. Instead of fine-tuning the whole LLM, it is more plausible to train an additional small network, such as a MLP with several layers, as the prefix of LLM. Such method greatly reduces the parameters to train and may gain more improvements in question polishing.