一次讲清楚京东科技百亿级用户画像平台的探索和实践 | 京东云技术团队
背景
如果你是用户,当你使用抖音、小红书的时候,假如平台能根据你的属性、偏好、行为推荐给你感兴趣的内容,那就能够为你节省大量获取内容的时间。
如果你是商家,当你要进行广告投放的时候,假如平台推送的用户都是你潜在的买家,那你就可以花更少的钱,带来更大的收益。
这两者背后都有一项共同的技术支撑,那就是用户画像。
业务能力
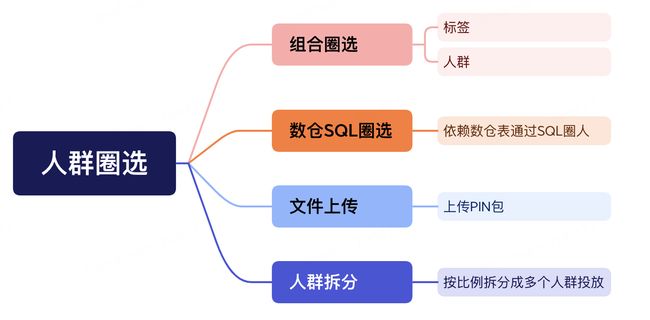
京东科技画像系统,提供标准的画像功能服务,包含标签市场、人群管理、数据服务、标签管理等,可以将用户分群服务于其他各个业务系统。


![]()
挑战
- 数据量大
目前平台拥有百亿+的用户ID、5000+的标签,单个人群包内的用户数量可达数十亿级,每天更新的人群也有2W多个。
- 计算复杂
标签圈选的条件复杂,底层依赖的数据量级较高,人群计算需要进行大量的交并差计算。
- 查询时间短
如果人群数预估、人群创建的耗时较长,对业务方的影响较大。
- 数据存储成本高
大量的人群数据存储需要高昂的存储成本。
- 数据查询量大、性能要求高
大促期间接口调用量高达百万QPS,接口响应要求要在40毫秒以内,而且要支持批量人群调用。
压缩的Bitmap
Bitmap 是一个二进制集合,用0或1标识某个值是否存在,使用Bitmap的特点和标签、人群结果的结构高度契合,正常1亿的人群包使用Bitmap存储只需要50MB左右。
在求两个集合的交并差运算时,不需要遍历两个集合,只要对位进行与运算即可。无论是比较次数的降低(从 O(N^2) 到O(N) ),还是比较方式的改善(位运算),都给性能带来巨大的提升。
从RoaringBitmap说起
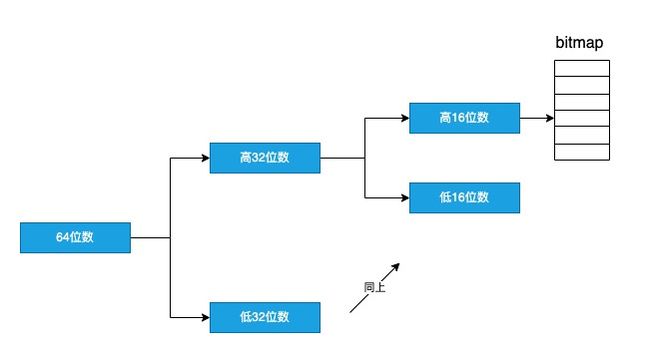
RoaringBitmap(简称RBM)是一种高效压缩位图,本质上是将大块的bitmap分成各个小桶,其中每个小桶在需要存储数据的时候才会被创建,从而达到了压缩存储和高性能计算的效果。
在实际存储时,先把64位的数划分成高32位和低32位,建立一个我们称为Container的容器,同样的再分别为高低32位创建高16位和低16位的Container,最终可以通过多次二分查找找到offset所在的小桶。
选择Clickhouse
- Clickhouse的特点
完备的数据库管理功能,包括DML(数据操作语言)、DDL(数据定义语言)、权限控制、数据备份与恢复、分布式计算和管理。
列式存储与数据压缩: 数据按列存储,在按列聚合的场景下,可有效减少查询时所需扫描的数据量。同时,按列存储数据对数据压缩有天然的友好性(列数据的同类性),降低网络传输和磁盘 IO 的压力。
关系模型与SQL: ClickHouse使用关系模型描述数据并提供了传统数据库的概念(数据库、表、视图和函数等)。与此同时,使用标准SQL作为查询语言,使得它更容易理解和学习,并轻松与第三方系统集成。
数据分片与分布式查询: 将数据横向切分,分布到集群内各个服务器节点进行存储。与此同时,可将数据的查询计算下推至各个节点并行执行,提高查询速度。
- 为什么选择Clickhouse
分析性能高:在同类产品中,ClickHouse分析性能遥遥领先,复杂的人群预估SQL可以做到秒级响应。
简化开发流程:关系型数据库和SQL对于开发人员有天然的亲和度,使得所有的功能开发完全SQL化,支持JDBC,降低了开发和维护的成本。
开源、社区活跃度高:版本迭代非常快,几乎几天到十几天更新一个小版本,发展趋势迅猛。
支持压缩位图:数据结构上支持压缩位图,有完善的Bitmap函数支撑各种业务场景。
- Clickhouse的部署架构
采用分布式多分片部署,每个分片保证至少有2个节点互为主备,来达到高性能、高可用的目的。
分片和节点之间通过Zookeeper来保存元数据,以及互相通信。这样可以看出Clickhouse本身是对Zookeeper是强依赖的,所以通常还需要部署一个3节点的高可用Zookeeper集群。

- 分布式表和本地表
本地表指每个节点的实际存储数据的表,有两个特点:
1、每个节点维护自己的本地表;
2、每个本地表只管这个节点的数据。
本地表每个节点都要创建,CK通常是会按自己的策略把数据平均写到每一个节点的本地表,本地数据本地计算,最后再把所有节点的结果汇总到一起。
通常我们也可以通过DDL里加上ON CLUSTER [集群模式] 这样的形式在任意节点执行即可在全部节点都创建相同的表。
例如通过ON CLUSTER模式执行DDL语句在每个节点创建名为[test]的库,其中[default]为创建集群时配置的集群名称
CREATE DATABASE test ON CLUSTER default
通常我们可以在应用里通过JDBC在每个节点执行SQL得到结果后,再在应用内进行聚合,要注意的是像平均值这样的计算,只能是通过先求SUM再求COUNT来实现了,直接使用平均值函数只能得到错误的结果。
分布式表是逻辑上的表、可以理解位视图。比如要查一张表的全量数据,可以去查询分布式表,执行时分发到每一个节点上,等所有节点都执行结束再在一个节点上汇总到一起(会对单节点造成压力)。
查询分布式表时,节点之间通信也是依赖zk,会对zk造成一定的压力。
同样的分布式表如果需要每个节点都能查询,就得在每一个节点都建表,当然也可以使用ON CLUSTER模式来创建。
例如为test.test_1在所有节点创建分布式表:
CREATE TABLE test.test_1_dist ON CLUSTER default
as test.test_1 ENGINE = Distributed('default','test','test_1',rand());
- 对Bitmap的支持
a、创建包含有Bitmap列的表
CREATE TABLE cdp.group ON CLUSTER default
(
`code` String,
`version` String,
`offset_bitmap` AggregateFunction(groupBitmap, UInt64)
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/cdp/{shard}/group_1',
'{replica}')
PARTITION BY (code)
ORDER BY (code)
SETTINGS storage_policy = 'default',
use_minimalistic_part_header_in_zookeeper = 1,
index_granularity = 8192;
b、Bitmap如何写入CK
通常有2种方式来写入Bitmap:
1、第一种通过INSERT … SELECT…来执行INSERT SQL语句把明细数据中的offset转为Bitmap
INSERT INTO cdp.group SELECT 'group1' AS code, 'version1' AS version, groupBitmapState(offset) AS offset_bitmap FROM tag.tag1 WHERE ....
2、在应用内生成Bitmap通过JDBC直接写入
com.clickhouse
clickhouse-jdbc
0.3.2-patch11
all
*
*
String sql = "INSERT INTO cdp.group SELECT code,version,offset_bitmap FROM input('code String,version String,offset_bitmap AggregateFunction(groupBitmap,UInt64)')";
try (PreparedStatement ps = dataSource.getConnection().prepareStatement(
sql)) {
ps.setString(1, code); // col1
ps.setString(2, uuid); // col2
ps.setObject(3, ClickHouseBitmap.wrap(bitmap.getSourceBitmap(), ClickHouseDataType.UInt64)); // col3
ps.addBatch();
ps.executeBatch();
}
c、从CK读取Bitmap
直接读取:
ClickHouseStatement statement =null;
try{
statement = connection.createStatement();
ClickHouseRowBinaryInputStream in = statement.executeQueryClickhouseRowBinaryStream(sql);
ClickHouseBitmap bit = in.readBitmap(ClickHouseDataType.UInt64);
Roaring64NavigableMap obj =(Roaring64NavigableMap) bit.unwrap();
returnnewExtRoaringBitmap(obj);
}catch(Exception e){
log.error("查询位图错误 [ip:{}][sql:{}]", ip, sql, e);
throw e;
}finally{
DbUtils.close(statement);
}
上面的方法直接读取Bitmap会大量占用应用内存,怎么进行优化呢? 我们可以通过Clickhouse把Bitmap转成列,通过流式读取bitmap里的offset,在应用里创建Bitmap
privatestatic String SQL_WRAP="SELECT bitmap_arr AS offset FROM (SELECT bitmapToArray(offset_bitmap) AS bitmap_arr FROM (SELECT ({}) AS offset_bitmap LIMIT 1)) ARRAY JOIN bitmap_arr";
publicstatic Roaring64NavigableMap getBitmap(Connection conn, String sql){
Statement statement =null;
ResultSet rs =null;
try{
statement = conn.createStatement(
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY);
String exeSql = ATool.format(SQL_WRAP, sql);
rs = statement.executeQuery(exeSql);
Roaring64NavigableMap bitmap =newRoaring64NavigableMap();
while(rs.next()){
Long offset = rs.getLong(1);
if(offset !=null){
bitmap.add(offset);
}
}
return bitmap;
}catch(Exception e){
log.error("从CK读取bitmap错误, SQL:{}", sql, e);
}finally{
ATool.close(rs, statement);
}
returnnull;
}
京东科技CDP
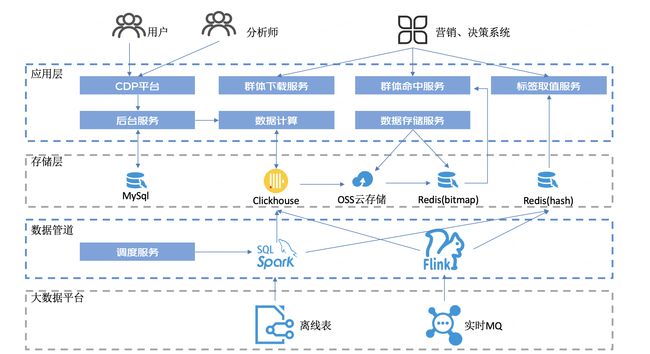
- 整体架构
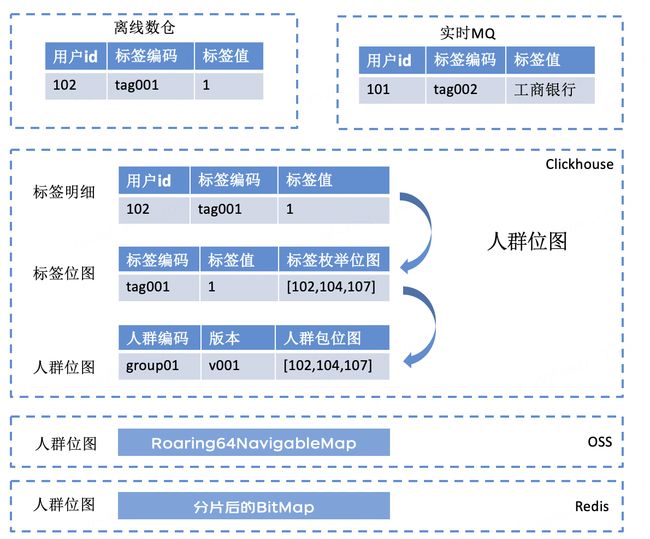
- 数据流转
- 进一步优化
1. 并行计算
前面提到了Clickhouse通常把数据按照分片数把数据拆分成n份,只要我们保证相同用户id的数据在每一张本地表中都在同一个节点,那么我们多表之间进行JOIN计算时只需要每一个节点的本地表之间进行计算,从而达到了并行计算的效果。
为了达到这个目的,那必须要从开始的明细表就要通过一定的策略进行切分,定制什么样的切分策略呢?这就要从RoaringBitmap的特性和机制来考虑。
2. 提高Bitmap在各节点的压缩率
标签和人群的最终结果数据都是用RoaringBitmap来存储的,如果每个Bitmap存储的小桶数量越少,那么计算和存储的成本就会更小,使用哪种策略来切分就变得至关重要。
先按照RoaringBitmap的策略将数据按照2的16次方为单位,切分成多个小桶,然后为小桶进行编号,再按编号取余来切分。这样同一个RoaringBitmap小桶中的offset只会在1个分片上,从而达到了减少小桶个数的目的。
//把数据拆分成10个分片,计算每个offset再哪个分片上
long shardIndex = (offset >>> 16) % 10
再进一步向上看,明细表如果也保持这样的分片逻辑,那么从明细转成Bitmap后,Bitmap自然就是高压缩的。
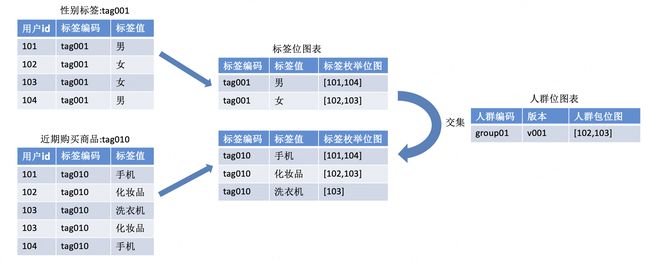
3.标签Bitmap表
标签明细数据怎么存,严重关系到人群计算的效率,经过长期的探索和优化,最终通过按枚举分组来加工出标签Bitmap来实现高效、高压缩的存储策略,但整个进化过程是一步步递进完成的。
| 阶段 | 方案 | 优势 | 劣势和瓶颈 |
|---|---|---|---|
| 第一阶段 | 标签宽表(单表) | 查询速度快、支持复杂条件 | 1、单表压力大 2、合并单表、单表写的时间过长,出错就要全量重推 3、存储成本高 |
| 第二阶段 | 标签窄表(多表) | 1、轻量化表管理灵活 2、标签时效性提升较为突出 | 1、计算需要多表JOIN,计算时间长,还时常会有超时和计算不出结果的情况; |
| 第三阶段 | 每个标签按照枚举分组计算出标签枚举的Bitmap保存为中间结果表 | 解决了阶段二计算时间长的问题,极大的节约了存储和计算资源 | 表数量和数据分区过多会增加ZK集群的压力; |
数据服务
人群加工完成后要对外提供命中服务,为了支撑高并发高性能的调用需求,人群Bitmap的存储必须使用缓存来存储。
起初是把一个完整的Bitmap切分成了8份,存储到8台物理机的内存里,每台机器存储了1/8的数据。这种存储方式本身是没有问题的,但面临着运维复杂,扩容困难的问题。

那么我们能不能使用Redis来存储人群数据呢?经过探索发现Redis本身是不支持压缩位图的,当我们写入一个2的64次方大小的offset时,就会创建一个庞大的Bitmap,占用大量的内存空间。这时我们就想到了使用压缩位图的原理把位图按照2的16次方大小切分成多个小桶,把大的Bitmap转成小的Bitmap,在保存时减去一定的偏移量,在读取时在加上偏移量,那么每一个小桶就是一个65536(2^16)大小的Bitmap。从而我们开发了一套完整的Agent程序来记录元数据信息,进行路由和读写Redis,最终实现了Redis存储压缩Bitmap的目的。
long bucketIndex = offset / 65536L;
long bucketOffset = offset % 65536L;
//其中偏移量就是bucketIndex * 65536L
保存时只需要把key+[bucketIndex]作为key,使用bucketOffset来setBit()。
进一步查文档发现,Redis本身就是支持把Bitmap转成字节数组后一次性写入的,这样又进一步的提升了数据写入的效率。
总结
京东科技CDP画像平台通过对用户分群,针对不同的用户投放以不同形式的不同内容,实现千人千面的精准投放,最终实现用户的增长。对外提供多样的数据服务,服务于不同的业务,以支持精准营销、精细化运营,智能外呼等营销场景。
随着时代的发展,离线人群已经不能满足日益增长的运营需求。从去年开始,CDP着手建设数据实时化,目前已经完全做到了人群命中实时计算。
作者:京东科技 梁发文
来源:京东云开发者社区 转载请注明来源