【Web系列二十四】使用JPA简化持久层接口开发
目录
环境配置
1、引入依赖
配置文件
代码编写
实体类创建
JPA常用注解
Service与ServiceImpl
Service
ServiceImpl
Controller
Dao
三种实现Dao功能方式
1.继承接口,使用默认接口+实现
2.根据接口命名规则默认生成实现
3.自定义接口+实现(类似MyBatis)
多表关联
1.一对一关联
2.一对多、多对一
3.多对多
参考资料
Spring Data JPA
Spring Data JPA 是Spring提供的一套简化JPA开发的持久层框架,根据实体类自动生成表 (注意库仍旧自己创建),按照约定好的【方法命名规则】写dao层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等。
Spring Data JPA 可以理解为 JPA 规范的再次封装抽象,底层还是使用了 Hibernate 的 JPA 技术实现。
SpringBoot集成新框架环境往往很容易:引入依赖,编写配置、[启用]、代码编写。
环境配置
1、引入依赖
首先要引入jpa的依赖
org.springframework.boot
spring-boot-starter-data-jpa
配置文件
spring:
jpa:
hibernate:
ddl-auto: update
show-sql: true- ddl-auto:自动创建表,有4个选项
- create:每次启动将之前的表和数据都删除,然后重新根据实体建立表。
- create-drop:比上面多了一个功能,就是在应用关闭的时候,会把表删除。
- update:最常用的,第一次启动根据实体建立表结构,之后重启会根据实体的改变更新表结构,不删除表和数据。
- validate:验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值,运行程序会校验实体字段与数据库已有的表的字段类型是否相同,不同会报错
- show-sql:指运行时,是否在控制台展示sql
代码编写
和mybatis主要的区别在于JPA可以根据实体类自动创建表,并且会提供默认的DAO方法。
实体类创建
创建一个models文件夹,并新建文件algo.java
package com.xxx.xxx.xxx.models;
import lombok.Data;
import org.springframework.data.annotation.CreatedDate;
import javax.persistence.*;
import java.util.Date;
@Entity
@Table(name = "algo")
@Data
public class Algo {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Integer id;
@Column(name = "name", length = 200)
private String name;
@CreatedDate
@Column(name = "create_time", updatable = false, nullable = false)
private Date createTime;
}JPA常用注解
| 注解 | 作用 |
|---|---|
| @Entity | 声明类为实体或表. |
| @Table | 声明表名。 |
| @Basic | 指定非约束明确的各个字段。 |
| @Embedded | 指定类或它的值是一个可嵌入的类的实例的实体的属性。 |
| @Id | 指定的类的属性,用于识别(一个表中的主键)。 |
| @GeneratedValue | 指定如何标识属性可以被初始化,参数strategy有以下选项: TABLE:使用一个特定的数据库表格存放主键。 |
| @Transient | 指定该属性为不持久属性,即:该值永远不会存储在数据库中。 |
| @AccessType | 这种类型的注释用于设置访问类型。如果设置@AccessType(FIELD),则可以直接访问变量并且不需要getter和setter,但必须为public。如果设置@AccessType(PROPERTY),通过getter和setter方法访问Entity的变量。 |
| @JoinColumn | 指定一个实体组织或实体的集合。这是用在多对一和一对多关联。 |
| @UniqueConstraint | 指定的字段和用于主要或辅助表的唯一约束。 |
| @ColumnResult | 参考使用select子句的SQL查询中的列名。 |
| @ManyToMany | 定义了连接表之间的多对多一对多的关系。 |
| @ManyToOne | 定义了连接表之间的多对一的关系。 |
| @OneToMany | 定义了连接表之间存在一个一对多的关系。 |
| @OneToOne | 定义了连接表之间有一个一对一的关系。 |
| @NamedQueries | 指定命名查询的列表。 |
| @NamedQuery | 指定使用静态名称的查询。 |
Service与ServiceImpl
Service
public interface AlgoService {
//查询全部
List findAlgoList();
//查询一条
User findAlgoById(int id);
//添加
void insertAlgo(Algo algo);
//删除
void deleteAlgo(int id);
//修改
void updateAlgo(Algo algo);
} ServiceImpl
查询一条数据时没有直接使用User而是使用Optional< User >,这是由于Dao层直接使用了默认的方法。Optional 类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
修改和添加都是save方法,修改时对象id有值,添加时id无值。
@Service
public class AlgoServiceImpl implements AlgoService {
@Autowired
private AlgoRepository algoRepository;
@Override
public List findAlgoList() {
return algoRepository.findAll();
}
@Override
public AlgofindAlgoById(int id) {
//Optional 类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
Optional ao = algoMapper.findById(id);
return ao.orElse(null);
}
@Override
public void insertAlgo(Algo algo) {
algoRepository.save(algo);
}
@Override
public void deleteAlgo(int id) {
algoRepository.deleteById(id);
}
@Override
public void updateAlgo(Algo algo) {
Algo emp = algoRepository.findById(algo.getId()).orElse(null);
assert emp != null;
BeanUtils.copyProperties(algo,emp); //属性值拷贝
algoRepository.save(emp);
}
} Controller
@RestController
public class JpaController {
@Autowired
private AlgoService algoService;
@PostMapping("/add")
public Map addAlgo(){
Algo algo = new Algo();
algo.setName("张三");
algo.setPassword("123456");
algo.setSex("男");
algoService.insertAlgo(algo);
Map map = new HashMap<>();
map.put("msg","操作成功");
return map;
}
} Dao
继承JpaRepository,它默认的提供了一些常见dao方法,主要是完成一些增删改查的操作。
@Repository
public interface AlgoRepository extends JpaRepository {
//约束1为实体类类型、约束2为主键类型
} 三种实现Dao功能方式
1.继承接口,使用默认接口+实现
| 接口 | 作用 |
|---|---|
| CrudRepository | 提供默认增删改查方法 |
| PagingAndSortingRepository | CRUD方法+分页、排序 |
| JpaRepository | 针对关系型数据库优化 |
2.根据接口命名规则默认生成实现
默认提供了常见方法,但仍可以根据命名规则自动生成方法。
此表内容来源于官网:
Spring Data JPA - Reference Documentation
| 关键词 | 示例 | JPQL片段 |
|---|---|---|
| Distinct | findDistinctByLastnameAndFirstname | select distinct … where x.lastname = ?1 and x.firstname = ?2 |
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is, Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull, Null | findByAge(Is)Null | … where x.age is null |
| IsNotNull, NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 |
| Containing | Containing | … where x.firstname like ?1 |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection ages) | … where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstname) = UPPER(?1) |
3.自定义接口+实现(类似MyBatis)
使用注解方式 @Query
使用 @Query()注解来生成sql语句,注意此注解默认value属性值与myBatis有点不同,它使用的是JPQL。
如果想使value值为原生SQL,则添加属性:nativeQuery = true 即可。
表名映射:可以直接使用表对应类名,如果想用表名:#{#entityName}
参数映射:?n表示第n个参数、:参数名(参数可用@Param指定)
#{#entityName}:SPEL表达式,实体类使用了@Entity后,它的值为实体类名,如果@Entity的name属性有值,则它的值为该name值。
@Modifying:标记仅映射参数的方法。
@Transactional:开启事务,并将只读改为非只读。
@Repository
//约束1为实体类、约束2为主键
public interface AlgoRepository extends JpaRepository {
//添加:使用了原生sql
@Transactional//开启事务为非只读
@Modifying
@Query(value = "insert into jpa_test(name, userId) values(:#{#algo.name}, :#{#algo.userId}) ", nativeQuery = true)
void addAlgo(@Param("algo") Algo algo);
//删除
@Transactional(timeout = 10)
@Modifying
@Query("delete from Algo where id=:id")
void deleteAlgoById(@Param("id") Integer id);
//修改
@Transactional(timeout = 10)
@Modifying
@Query("update Algo u set u.name=:#{#algo.name}, u.createTime=:#{#algo.createTime}, u.userId=:#{#algo.userId} where u.id=:#{#algo.id}")
void updateAlgo (@Param("algo")Algo algo);
//查询一条
@Query("select u from Algo u where u.id=?1 ")
User findAlgoById(Integer id);
//查询全部
@Query("select u from Algo u")
List findAllAlgo();
} 对象属性的绑定:使用 @Param(映射名) 注解 + :#{#映射名.属性}
多表关联
JPA中一般只需要创建关联性即可,默认方法会自动关联查询。
1.一对一关联
两张表a、b,a的每条对应着b最多一条数据。
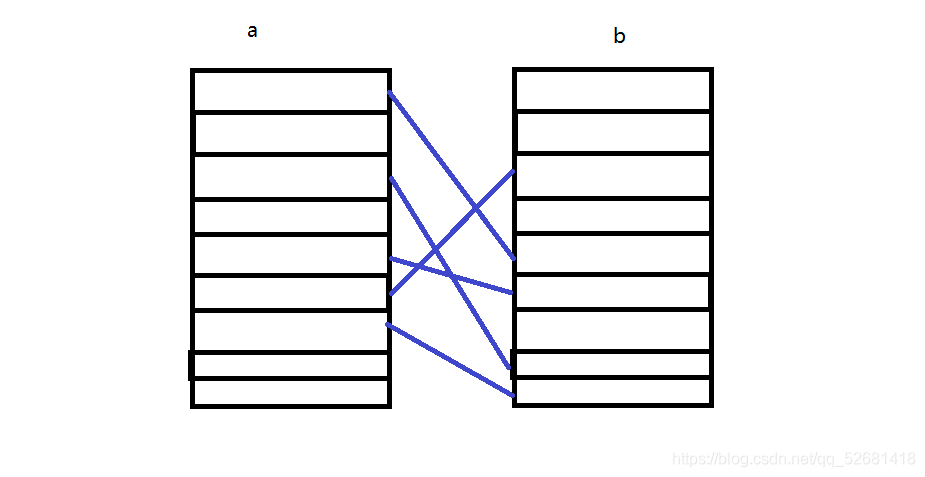
jpa实现如下:
/**
* 表A
*/
@Entity
@Table(name = "a")
public class A{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToOne(cascade = {CascadeType.ALL})//一对一关系,级联删除
@JoinColumn(name="b",referencedColumnName = "id")//关联 b的id字段
private B b;
}
/**
* 表B
*/
@Entity
@Table(name = "b")
public class B{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
}
上面是A级联B,即可以通过A查到B,如果想通过B查到A则需要为B添加级联属性。
2.一对多、多对一
一对多: 两张表A、B,A的一条记录对应B的多条记录,B每条只能对应1个A。A对B的关系为一对多;B对 A的关系为多对一。

jpa实现如下:
/**
* 球员表
*/
@Entity//球员表
@Table(name = "sportmans")
public class SportMan implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
private String sportManName;
@ManyToOne(cascade = {CascadeType.MERGE,CascadeType.PERSIST})
@JoinColumn(name="duty") //库中添加的外键字段
private Duty duty;
}
/**
* 位置表
*/
@Data
@Entity
@Table(name = "dutys")
public class Duty implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
private String dutyName;
@JsonIgnore//不反向查询
//级联保存、更新、删除,删除时会删除所有球员
@OneToMany(mappedBy = "duty",cascade = CascadeType.ALL,fetch = FetchType.LAZY)
private List sportManList;
} 不使用@JsonIgnore注解时,查询球员,球员里关联出位置,位置反向关联球员,会无限递归查询,因此添加此注解,防止此字段被查出来时自动回查。
3.多对多
两张表A、B,一条A记录对应多条B,一条B记录对应多条A。
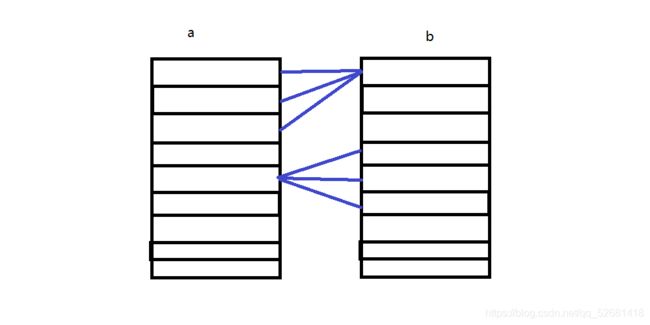
jpa实现如下:
/**
* 表A
*/
@Entity
@Table(name = "a")
public class A{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToMany(cascade = {CascadeType.ALL})
@JoinColumn(name="b",referencedColumnName = "id")//关联 b的id字段
private B b;
}
/**
* 表B
*/
@Entity
@Table(name = "b")
public class B{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToMany(cascade = {CascadeType.ALL})
@JoinColumn(name="a",referencedColumnName = "id")//关联 a的id字段
private A a;
}
参考资料
SpringBoot 一文搞懂Spring JPA_springboot jpa_马踏飞燕&lin_li的博客-CSDN博客
使用springJpa创建数据库表_jpa可以动态创建数据库表吗_阿圣同学的博客-CSDN博客
【Spring JPA总结】@GeneratedValue注解介绍 - 简书 (jianshu.com)
spring boot 中使用 jpa(详细操作)_springboot jpa_熬菜的博客-CSDN博客
Spring Boot+JPA_springboot+jpa_火恐龙的博客-CSDN博客