python数据挖掘
文章目录
- 数据挖掘
- 1. matplotlib
-
- 1.1 matplotlib三层结构
- 1.2 折线图plot与基础绘图功能
- 1.3 散点图 scatter
- 1.4 柱状图bar
- 1.5 直方图
- 1. 6饼图
- 2. numpy
-
- 2.1 ndarray
- 2.2 基本操作
-
- 2.2.1 生成数组的方法
- 2.2.2 数组的索引、切片
- 2.2.3 形状修改
- 2.2.4 类型修改
- 2.2.5 数组的去重
- 2.3 ndarray运算
-
- 2.3.1 逻辑运算
- 2.3.2 统计运算
- 2.3.3 数组间运算
- 2.3.4 矩阵运算
- 2.4 合并与分割
- 2.5 IO操作与数据处理
- 3. pandas
-
- 3.1 核心数据结构
-
- 3.1.1 DataFrame
- 3.1.2 MultiIndex与Panel
- 3.1.3 Series
- 3.2 基本数据操作
-
- 3.2.1 索引操作
- 3.2.2 赋值操作
- 3.2.3 排序操作
- 3.2 DataFrame运算
- 3.3 pandas画图
- 3.4 文件读取与存储
- 3.5 缺失值处理
- 3.6 数据离散化
- 3.7 合并
- 3.8 交叉表与透视表
- 3.9 分组与聚合
数据挖掘
1. matplotlib
matplotlib专门用于开发2D图表(包括3D图表),以渐进、交互式方式实现数据可视化,是一个画二维图表的python库
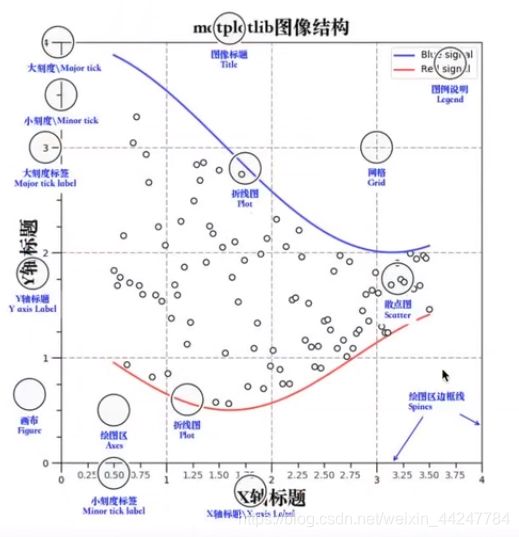
1.1 matplotlib三层结构
- 容器层
容器层包括画板层Canvas,在画板层上又有画布层Figure,画布层上有绘图区/坐标系Axies - 辅助显示层
在绘图区上用来添加一些辅助显示的功能 - 图像层
在绘图区上画出不同的图像
1.2 折线图plot与基础绘图功能
折线图能够用来显示数据的变化趋势
基本框架:
import matplotlib.pyplot as plt
def plot_demo():
# 展现上海一周的天气温度
# 1.创建画布
plt.figure()
# 2.绘制图像,绘制x轴和y轴
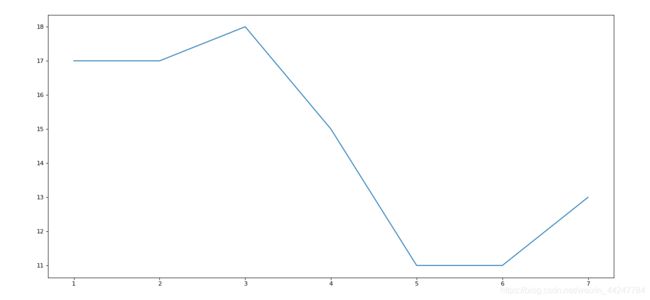
plt.plot([1,2,3,4,5,6,7],[17,17,18,15,11,11,13])
# 3.显示图像
plt.show()
if __name__ == "__main__":
plot_demo()
在容器层上完善:
设置画布属性与图片保存:

import matplotlib.pyplot as plt
def plot_demo():
# 展现上海一周的天气温度
# 1.创建画布
plt.figure(figsize=(20,8),dpi=80)
# 2.绘制图像,绘制x轴和y轴
plt.plot([1,2,3,4,5,6,7],[17,17,18,15,11,11,13])
# 保存图片,要写在show方法前,因为show方法会释放figure资源,保存的图片是空图片
plt.savefig("test.png")
# 3.显示图像
plt.show()
if __name__ == "__main__":
plot_demo()
在辅助显示层进行完善:
import matplotlib.pyplot as plt
import random
import matplotlib.font_manager as mf
def plot_demo2():
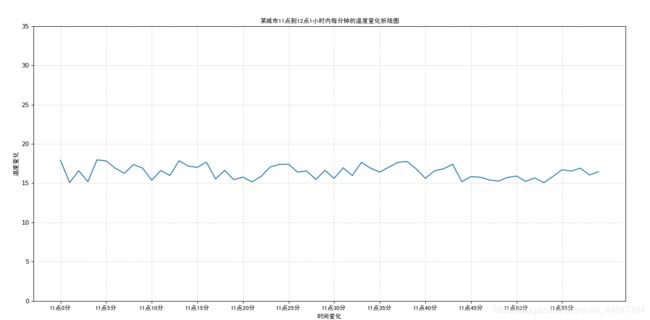
# 画出某城市11点到12点1小时内每分钟的温度变化折线图,温度范围在15-18度
# 1.准备数据x y
x = range(60)
y_shanghai = [random.uniform(15,18) for i in x]
# 2.创建画布
plt.figure(figsize=(20,8),dpi=80)
# 3.绘制图像
plt.plot(x,y_shanghai)
# 修改x,y刻度
# 准备x的刻度说明
x_label = ["11点{}分".format(i) for i in x]
# 设置字体
my_font = mf.FontProperties(fname="D:\wampserver\www\code\shujuwajue\simhei.ttf")
# 取步长为5
plt.xticks(x[::5],x_label[::5],fontproperties=my_font)
plt.yticks(range(0,40,5))
# 添加网格显示,线条风格,透明度
plt.grid(True,linestyle="--",alpha=0.5)
# 添加x、y轴标签
plt.xlabel("时间变化",fontproperties=my_font)
plt.ylabel("温度变化",fontproperties=my_font)
plt.title("某城市11点到12点1小时内每分钟的温度变化折线图",fontproperties=my_font)
# 4.显示图像
plt.show()
if __name__ == "__main__":
plot_demo2()
在图像层上完善:
import matplotlib.pyplot as plt
import random
import matplotlib.font_manager as mf
def plot_demo2():
# 1.准备数据x y
x = range(60)
y_shanghai = [random.uniform(15,18) for i in x]
# 再添加一个城市的温度变化
y_beijing = [random.uniform(1,3) for i in x]
# 2.创建画布
plt.figure(figsize=(20,8),dpi=80)
# 3.绘制图像
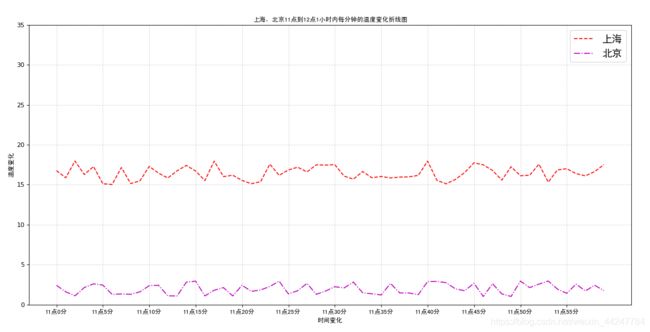
plt.plot(x,y_shanghai,color="r",linestyle="--",label="上海")
plt.plot(x,y_beijing,color="m",linestyle="-.",label="北京")
# 设置字体
my_font = mf.FontProperties(fname="D:\wampserver\www\code\shujuwajue\simhei.ttf")
# 显示图例
plt.legend(prop={'family' : 'simhei', 'size' : 16})
# 修改x,y刻度
# 准备x的刻度说明
x_label = ["11点{}分".format(i) for i in x]
# 取步长为5
plt.xticks(x[::5],x_label[::5],fontproperties=my_font)
plt.yticks(range(0,40,5))
# 添加网格显示,线条风格,透明度
plt.grid(True,linestyle="--",alpha=0.5)
# 添加x、y轴标签
plt.xlabel("时间变化",fontproperties=my_font)
plt.ylabel("温度变化",fontproperties=my_font)
plt.title("上海,北京11点到12点1小时内每分钟的温度变化折线图",fontproperties=my_font)
# 4.显示图像
plt.show()
if __name__ == "__main__":
plot_demo2()
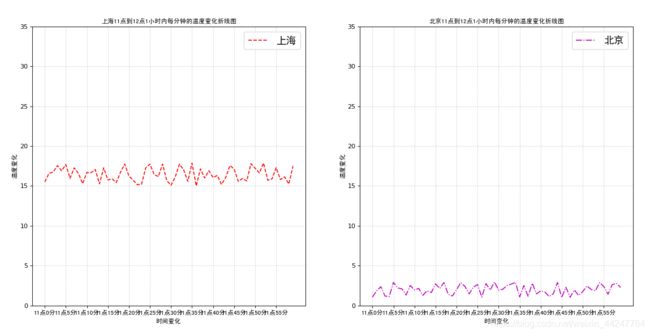
多个坐标系画图:

import matplotlib.pyplot as plt
import random
import matplotlib.font_manager as mf
def plot_demo3():
# 多个坐标系绘图
# 1.准备数据x y
x = range(60)
y_shanghai = [random.uniform(15,18) for i in x]
# 再添加一个城市的温度变化
y_beijing = [random.uniform(1,3) for i in x]
# 2.创建画布
# plt.figure(figsize=(20,8),dpi=80)
figure,axes = plt.subplots(nrows=1,ncols=2,figsize=(20,8),dpi=80)
# 3.绘制图像
axes[0].plot(x,y_shanghai,color="r",linestyle="--",label="上海")
axes[1].plot(x,y_beijing,color="m",linestyle="-.",label="北京")
# 显示图例
axes[0].legend(prop={'family' : 'simhei', 'size' : 16})
axes[1].legend(prop={'family' : 'simhei', 'size' : 16})
# 设置字体
my_font = mf.FontProperties(fname="D:\wampserver\www\code\shujuwajue\simhei.ttf")
# 修改x,y刻度
# 准备x的刻度说明
x_label = ["11点{}分".format(i) for i in x]
# 取步长为5
axes[0].set_xticks(x[::5])
axes[0].set_xticklabels(x_label[::5],fontproperties=my_font)
axes[1].set_xticks(x[::5])
axes[1].set_xticklabels(x_label[::5],fontproperties=my_font)
axes[0].set_yticks(range(0,40,5))
axes[1].set_yticks(range(0,40,5))
# 添加网格显示,线条风格,透明度
axes[0].grid(True,linestyle="--",alpha=0.5)
axes[1].grid(True,linestyle="--",alpha=0.5)
# 添加x、y轴标签
axes[0].set_xlabel("时间变化",fontproperties=my_font)
axes[0].set_ylabel("温度变化",fontproperties=my_font)
axes[0].set_title("上海11点到12点1小时内每分钟的温度变化折线图",fontproperties=my_font)
axes[1].set_xlabel("时间变化",fontproperties=my_font)
axes[1].set_ylabel("温度变化",fontproperties=my_font)
axes[1].set_title("北京11点到12点1小时内每分钟的温度变化折线图",fontproperties=my_font)
# 4.显示图像
plt.show()
if __name__ == "__main__":
plot_demo3()
扩展:绘制数学图像
import matplotlib.pyplot as plt
import numpy as np
def plot_demo4():
# 生成-1到1的1000个数
x = np.linspace(-1,1,1000)
y = 2*x*x
plt.figure(figsize=(20,8),dpi=80)
plt.plot(x,y)
plt.show()
if __name__ == "__main__":
plot_demo4()

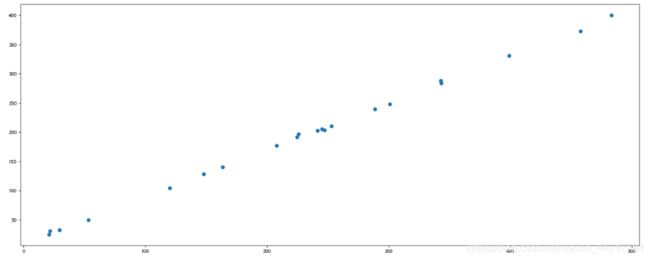
1.3 散点图 scatter
散点图主要用于判断变量之间是否存在数量关联趋势,展示离群点(分布规律)
import matplotlib.pyplot as plt
def scatter_demo():
# 需求:探究房屋面积和房屋价格的关系
# 1、准备数据
x = [225.98, 247.07, 253.14, 457.85, 241.58, 301.01, 20.67, 288.64,
163.56, 120.06, 207.83, 342.75, 147.9 , 53.06, 224.72, 29.51,
21.61, 483.21, 245.25, 399.25, 343.35]
y = [196.63, 203.88, 210.75, 372.74, 202.41, 247.61, 24.9 , 239.34,
140.32, 104.15, 176.84, 288.23, 128.79, 49.64, 191.74, 33.1 ,
30.74, 400.02, 205.35, 330.64, 283.45]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制图像
plt.scatter(x, y)
# 4、显示图像
plt.show()
if __name__ == "__main__":
scatter_demo()
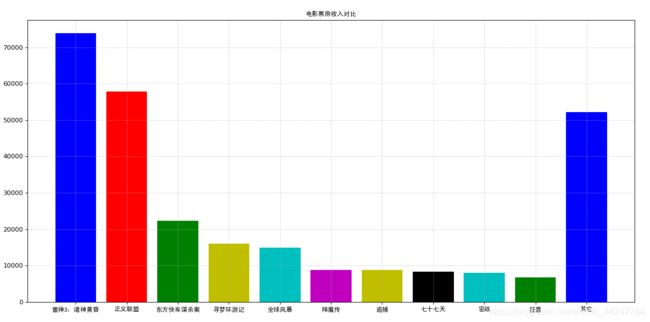
1.4 柱状图bar
柱状图用于绘制离散的数据,能够直观地看到数据的差别,主要用于对比

import matplotlib.pyplot as plt
import matplotlib.font_manager as mf
def bar_demo():
# 1、准备数据
movie_names = ['雷神3:诸神黄昏','正义联盟','东方快车谋杀案','寻梦环游记','全球风暴', '降魔传','追捕','七十七天','密战','狂兽','其它']
tickets = [73853,57767,22354,15969,14839,8725,8716,8318,7916,6764,52222]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制柱状图
x_ticks = range(len(movie_names))
plt.bar(x_ticks, tickets, color=['b','r','g','y','c','m','y','k','c','g','b'])
# 设置字体
my_font = mf.FontProperties(fname="D:\wampserver\www\code\shujuwajue\simhei.ttf")
# 修改x刻度
plt.xticks(x_ticks, movie_names,fontproperties=my_font)
# 添加标题
plt.title("电影票房收入对比",fontproperties=my_font)
# 添加网格显示
plt.grid(linestyle="--", alpha=0.5)
# 4、显示图像
plt.show()
if __name__ == "__main__":
bar_demo()
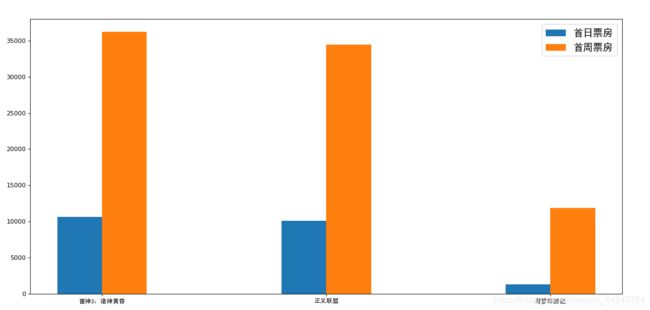
import matplotlib.pyplot as plt
import matplotlib.font_manager as mf
def bar_demo2():
# 1、准备数据
movie_name = ['雷神3:诸神黄昏','正义联盟','寻梦环游记']
first_day = [10587.6,10062.5,1275.7]
first_weekend=[36224.9,34479.6,11830]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 设置字体
my_font = mf.FontProperties(fname="D:\wampserver\www\code\shujuwajue\simhei.ttf")
# 3、绘制柱状图
plt.bar(range(3), first_day, width=0.2, label="首日票房")
plt.bar([0.2, 1.2, 2.2], first_weekend, width=0.2, label="首周票房")
# 显示图例
plt.legend(prop={'family' : 'simhei', 'size' : 16}
)
# 修改刻度
plt.xticks([0.1, 1.1, 2.1], movie_name,fontproperties=my_font)
# 4、显示图像
plt.show()
if __name__ == "__main__":
bar_demo2()
1.5 直方图
直方图用于绘制连续性的数据展示一组或者多组数据的分布状况



import matplotlib.pyplot as plt
def hist_demo():
# 需求:电影时长分布状况
# 1、准备数据
time = [131, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138, 131, 102, 107, 114, 119, 128, 121, 142, 127, 130, 124, 101, 110, 116, 117, 110, 128, 128, 115, 99, 136, 126, 134, 95, 138, 117, 111,78, 132, 124, 113, 150, 110, 117, 86, 95, 144, 105, 126, 130,126, 130, 126, 116, 123, 106, 112, 138, 123, 86, 101, 99, 136,123, 117, 119, 105, 137, 123, 128, 125, 104, 109, 134, 125, 127,105, 120, 107, 129, 116, 108, 132, 103, 136, 118, 102, 120, 114,105, 115, 132, 145, 119, 121, 112, 139, 125, 138, 109, 132, 134,156, 106, 117, 127, 144, 139, 139, 119, 140, 83, 110, 102,123,107, 143, 115, 136, 118, 139, 123, 112, 118, 125, 109, 119, 133,112, 114, 122, 109, 106, 123, 116, 131, 127, 115, 118, 112, 135,115, 146, 137, 116, 103, 144, 83, 123, 111, 110, 111, 100, 154,136, 100, 118, 119, 133, 134, 106, 129, 126, 110, 111, 109, 141,120, 117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125, 126,114, 140, 103, 130, 141, 117, 106, 114, 121, 114, 133, 137, 92,121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139, 113,134, 106, 144, 110, 137, 137, 111, 104, 117, 100, 111, 101, 110,105, 129, 137, 112, 120, 113, 133, 112, 83, 94, 146, 133, 101,131, 116, 111, 84, 137, 115, 122, 106, 144, 109, 123, 116, 111,111, 133, 150]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制直方图
distance = 2
group_num = int((max(time) - min(time)) / distance)
plt.hist(time, bins=group_num, density=True)
# 修改x轴刻度
plt.xticks(range(min(time), max(time) + 2, distance))
# 添加网格
plt.grid(linestyle="--", alpha=0.5)
# 4、显示图像
plt.show()
if __name__ == "__main__":
hist_demo()
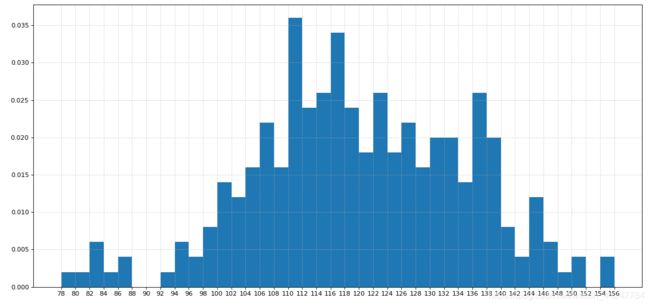
直方图应用场景:

1. 6饼图
饼图用于显示分类数据的占比情况

import matplotlib.pyplot as plt
def pie_demo():
# 1、准备数据
movie_name = ['雷神3:诸神黄昏','正义联盟','东方快车谋杀案','寻梦环游记','全球风暴','降魔传','追捕','七十七天','密战','狂兽','其它']
place_count = [60605,54546,45819,28243,13270,9945,7679,6799,6101,4621,20105]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 设置字体
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
# 3、绘制饼图
plt.pie(place_count, labels=movie_name, colors=['b','r','g','y','c','m','y','k','c','g','y'], autopct="%1.2f%%")# 倒数第二个%代表转义
# 显示图例
plt.legend(prop={'family' : 'simhei', 'size' : 16})
# 保持饼图长宽一样
plt.axis('equal')
# 4、显示图像
plt.show()
if __name__ == "__main__":
pie_demo()

2. numpy

2.1 ndarray
用ndarray存储一个二维数组,存储的数据类型是一样的
import numpy as np
score = np.array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
print(score)
print(type(score))
结果:
[[80 89 86 67 79]
[78 97 89 67 81]
[90 94 78 67 74]
[91 91 90 67 69]
[76 87 75 67 86]
[70 79 84 67 84]
[94 92 93 67 64]
[86 85 83 67 80]]
<class 'numpy.ndarray'>
python原生list也能够存储这种二维数组,但是使用ndarray来存储的话,在进行存储和输入输出的时候,速度会快很多。
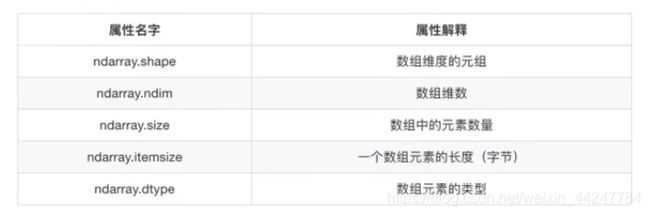
ndarray的属性:
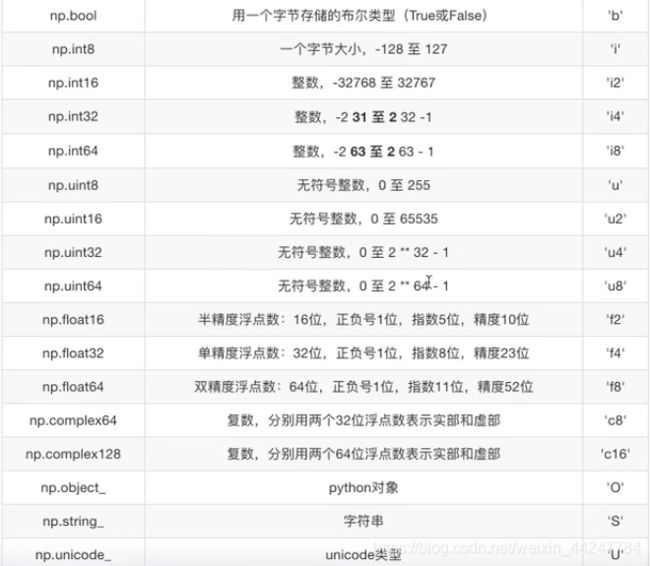
ndarray的类型:

2.2 基本操作
numpy的基本操作有两种方法:
- ndarray.方法()
- np.函数名()
2.2.1 生成数组的方法
生成0和1:有很多方法,常用的ones和zeros方法

从现有数组生成:np.array()和np.copy()是深拷贝(生成一个新的),而np.asarray()是浅拷贝,相当于一个索引

生成固定范围的数组:

或者使用np.arange(a,b,c),生成的数组是从a开始,以c为步长,到b结束(不取b)
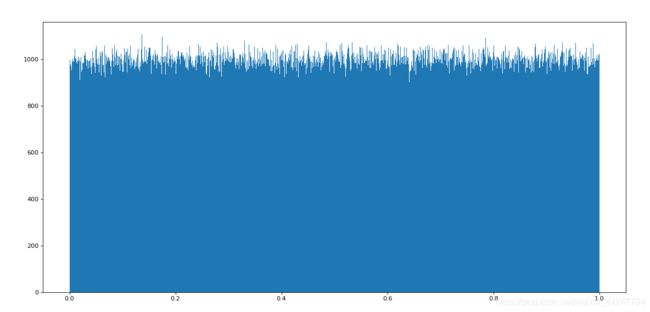
生成随机数组:

import numpy as np
import matplotlib.pyplot as plt
data1 = np.random.uniform(0,1,1000000)
plt.figure(figsize=(20,8),dpi=80)
plt.hist(data1,1000)
plt.show()
正态分布:

import numpy as np
import matplotlib.pyplot as plt
data1 = np.random.normal(loc=1.75,scale=0.1,size=1000000)
plt.figure(figsize=(20,8),dpi=80)
plt.hist(data1,1000)
plt.show()
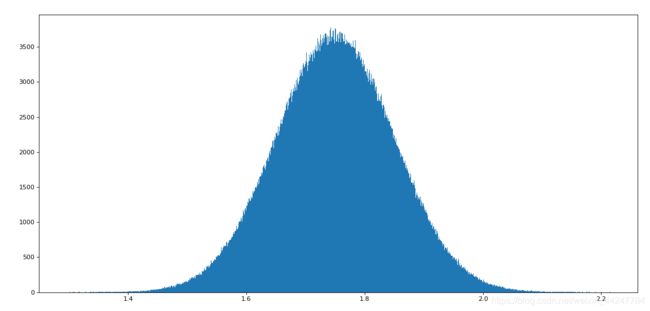
2.2.2 数组的索引、切片
import numpy as np
import matplotlib.pyplot as plt
data1 = np.random.normal(loc=1.75,scale=0.1,size=(8,10))
print(data1)
# 取第一行前三列的数据data1[0,:3]等价于data1[0,0:3]
print(data1[0,:3])
data2 = np.array([ [[1,2,3],[4,5,6]], [[12,3,34],[5,6,7]]])
print(data2)
# 三维数组的索引
print(data2[1,0,2])
2.2.3 形状修改
import numpy as np
data1 = np.zeros([2,3])
print("1:\n",data1)
# reshape只修改形状,返回新的ndarray,原始数据没有改变
data2 = data1.reshape((3,2))
print("2:\n",data2)
# resize没有返回值,对原始的ndarray进行了修改
data1.resize((3,2))
print("3:\n",data1)
# T对ndarray进行转置
print("4:\n",data1.T)
1:
[[0. 0. 0.]
[0. 0. 0.]]
2:
[[0. 0.]
[0. 0.]
[0. 0.]]
3:
[[0. 0.]
[0. 0.]
[0. 0.]]
4:
[[0. 0. 0.]
[0. 0. 0.]]
2.2.4 类型修改
import numpy as np
data1 = np.random.normal(loc=1,scale=0.1,size=(8,10))
print(data1.dtype)
# 类型修改
data2 = data1.astype("int64")
print(data2)
# 序列化
data3 = data1.tostring()
print(data3)
结果:
float64
[[1 0 0 1 0 1 1 1 0 0]
[0 0 1 0 0 0 0 1 0 1]
[1 0 0 1 1 0 0 0 1 0]
[0 0 1 1 1 0 0 1 0 1]
[1 1 0 0 1 1 0 1 1 1]
[0 1 0 0 1 0 1 1 1 1]
[1 0 1 0 0 0 1 1 1 1]
[1 1 1 1 1 1 1 0 1 0]]
b'\xc8k}\xa3\xbe\x11\xf0?\xbd\x9cG\xd7\x1c{\xef?mq\xb8@W\xef\xef?{\x0bU?\x1fT\xf1?X\x1c\x86\x97\x99\x05\xef?\xe1\xe6\xa8\xe0\xb7\x0b\xf2?p\x8f\xcdEn\xbd\xf0?\xf2\xd9fe\xda\x04\xf0?\xbe\xad\xdc\x8a\xa7h\xed?\x87D*m\xc9\x98\xed?5]u\x9f\x0e^\xed?~\x87\xcd5\xfb#\xee?\xb6\xf8\x9d\xfb\xfb\xd4\xf0?54\x80L\x18\xd8\xeb?H\x88\xd1\xff\x9a\x04\xee?^\xa8\xdb\xe6\x81\xe4\xed?(\xdf[4e1\xef?%\xce\x0e\x1d\xa8\x0f\xf0?\xbc\'{\xf8\xb7i\xec?\xef\x17VI4\x1b\xf1?\x8d\xeb\xe78lm\xf1?\xee\xc0\xff38<\xe8?R\xb5\x82H\xf9\xc8\xe9?\x8c\xcbUb\x02\xe0\xf2?\xb4\xca\xbfx\xd34\xf0?\xb81\t\x0f)\xea\xe7?m/\x1f\xce\xbc\x96\xeb?^\nkv\xb8R\xef?\xa4[^<\xf8*\xf1?CB\x82\x08=\x17\xee?\xc3j\'\\\x06P\xeb?\xaf\x01*c8\xf4\xef?\xe9\x1b\xb9Pom\xf0?Y"e\x81\x84\xef\xf2?Rk+\xb1\xf2\x8b\xf1?\xe9\xc7\xfcM2$\xee?m4\x0es\x0c\x07\xee?\xbcm\x86>{>\xf2?\xf5\xee\x9c\xd2v\xcb\xef?\xdewp+~\x1d\xf0?Y\xe3k=q_\xf0?\'\xa5\xfe\r^W\xf0?\xc28\x01\x7f\xb8\xda\xee?\x80JG;\xec\xbe\xee?\xd0\xb3-\xcc\x95k\xf0?\xdb\xfa\x8b\xb7cE\xf0?T\xe3=\x19?\xf5\xee?\xd6\xef4tM\x85\xf4?"\xd8.\x1f\xca\x9d\xf2?\xe8\xb6\xe0\x96W}\xf2?\xa3\x97Qm\x07W\xee?\xb7&\xe2\xc0\xf2\xb5\xf1?\x18&<\'\xe0\\\xec?\x0f\xb7\xf86f\xcb\xeb?\xda\x8c\xed\x02\x84K\xf3?h\x9f\xee$\xf9G\xed?w\xc3\t\x91\xbc7\xf0?+\x9a7!\x15\xea\xf3?g\x1b\xf5\xa9\xcb<\xf1?\x8c\xdf:\xc8\x8fN\xf1?t.j\xac\x97\x8b\xf1?\xe1\xe9\x01\x17\r\x9a\xef?bC\x92\r\x91\xa3\xf3?\x0cv\xc8\xc1o5\xeb?\rs \xe9\xc4\xbc\xe5?6\x1d\xd0\xcd\xb1\xaf\xec?\x95\xe4)\xa2\x92[\xf0?\xaa\xab\xaf+\xe0\x01\xf0?d\x19\xd2\x19^Z\xf2?a@\xb8J\xcb\xc8\xf1?\xfeybv\xe9s\xf1?O\xf5\x9e\xfe\xe5j\xf0?g\x0b\xc4t\x98n\xf0?\x9c\xbf\xc6\xa4\xe7~\xf0?\x08=\xbbt\x05\x08\xf1?H\xe8\xb2\xff0\xea\xf0?\xf3\x02)<\xa8g\xf0?=\xf0\xe9\x1f\xc0\x83\xef?\xbb89\xd4\xb5\x12\xf1?]\x93.\x97\x18\xcf\xec?'
2.2.5 数组的去重
import numpy as np
temp = np.array([[1, 2, 3, 4],[3, 4, 5, 6]])
data = np.unique(temp)
print(data)
# 或者用set方法生成一个集合,也能达成去重的目的,不过要先把二维数组变为一维的
print(temp.flatten())
print(set(temp.flatten()))
结果:
[1 2 3 4 5 6]
[1 2 3 4 3 4 5 6]
{1, 2, 3, 4, 5, 6}
2.3 ndarray运算
2.3.1 逻辑运算
import numpy as np
data = np.random.normal(loc=0,scale=1,size=(5,5))
print(data)
# 逻辑运算
print(data>0.5)
# 布尔索引
print(data[data>0.5])
data[data>0.5] = 1
print(data)
结果:
[[-1.89311291 -0.51306242 -1.22346404 -0.49061863 0.04836732]
[ 0.59307836 0.44042051 -1.12431881 0.03605291 0.05548059]
[-0.45315164 0.08906275 -0.6471477 0.83119816 1.25936722]
[-1.14910547 -0.14752106 -0.49678266 1.31114501 0.16939203]
[-1.53786751 0.95142564 0.27759299 -0.84624445 -2.24571034]]
[[False False False False False]
[ True False False False False]
[False False False True True]
[False False False True False]
[False True False False False]]
[0.59307836 0.83119816 1.25936722 1.31114501 0.95142564]
[[-1.89311291 -0.51306242 -1.22346404 -0.49061863 0.04836732]
[ 1. 0.44042051 -1.12431881 0.03605291 0.05548059]
[-0.45315164 0.08906275 -0.6471477 1. 1. ]
[-1.14910547 -0.14752106 -0.49678266 1. 0.16939203]
[-1.53786751 1. 0.27759299 -0.84624445 -2.24571034]]
通用判断函数:
- np.all(布尔值):只要有一个False就返回False,只有全是True才会返回True
- np.any(布尔值):只要有一个True就会返回True
import numpy as np
data = np.random.normal(loc=0,scale=1,size=(5,5))
print(data)
print(np.all(data[0] > 0))
print(np.any(data[0] > 0))
结果:
[[ 1.22394761 1.33289219 0.56466567 -0.67953222 0.73741191]
[ 0.01991565 -0.10610982 -0.18347376 0.38228431 0.01443358]
[ 1.58708902 -0.30316035 -0.55083269 -0.05782425 -1.12939524]
[-0.46860363 -0.2294725 0.0955936 -1.73961446 1.33468551]
[ 0.45294435 0.74245908 0.08533173 -0.17264419 0.79747899]]
False
True
三元运算符np.where:
np.where(布尔值,True的位置的值,False的位置的值)
import numpy as np
data = np.random.normal(loc=0,scale=1,size=(5,5))
print(data)
# 相当于先进行逻辑运算data>0得到一个ndarray,然后把对应True的位置置为1,False的位置置为0
data1 = np.where(data > 0, 1, 0)
print(data1)
结果:
[[ 0.11080382 -0.1179309 -1.55094384 0.25423423 1.29751584]
[ 1.08838769 1.41292936 -0.79543218 -1.39932488 -1.26759735]
[-0.69989322 -0.20730347 1.00627191 -0.75223068 0.68962569]
[-0.9184576 0.66804706 1.88649588 0.50797293 0.20220698]
[ 1.29315456 0.40723844 -0.56877209 0.39613761 1.47368112]]
[[1 0 0 1 1]
[1 1 0 0 0]
[0 0 1 0 1]
[0 1 1 1 1]
[1 1 0 1 1]]
如果要使用复合逻辑的话需要结果np.logical_and和np.logical_or使用
import numpy as np
data = np.random.normal(loc=0,scale=1,size=(5,5))
print(data)
data1 = np.where(np.logical_and(data>0.5,data<1), 1, 0)
print(data1)
data2 = np.where(np.logical_or(data>0.5,data<-0.5), 1, 0)
print(data2)
结果:
[[-0.52511441 0.65996722 -1.20778434 1.05130233 -0.7585256 ]
[ 0.74864035 -0.16776849 0.20230609 -0.48764068 1.56020515]
[ 0.11840678 1.77650363 0.19863168 -0.43933524 0.48151308]
[ 1.10890068 0.51173525 -0.2720509 -0.7335989 -0.26495815]
[ 0.18345985 0.31088769 -1.59680767 0.08237096 -1.64944385]]
[[0 1 0 0 0]
[1 0 0 0 0]
[0 0 0 0 0]
[0 1 0 0 0]
[0 0 0 0 0]]
[[1 1 1 1 1]
[1 0 0 0 1]
[0 1 0 0 0]
[1 1 0 1 0]
[0 0 1 0 1]]
2.3.2 统计运算
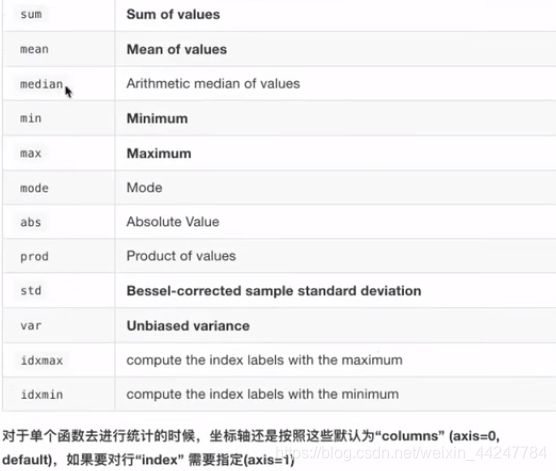
统计指标相关api:可以使用np.函数名或使用ndarray.方法名去使用,效果是一样的


以上的方法返回的是一个包含数值的数组,如果要返回索引的话要调用以下方法:

2.3.3 数组间运算
数组与数的运算,ndarray可以直接跟数进行加减乘除,而原生python的list就没有这种操作
import numpy as np
data = np.random.normal(loc=0,scale=1,size=(5,5))
print(data)
print(data + 1)
print(data / 2)
了解数组间运算之前,先理解广播机制:

比如这些例子是满足广播机制的,可以进行运算:

这两个例子则不能进行运算:

import numpy as np
arr1 = np.array([[1,2,3,2,1,40],[5,6,1,2,3,1]])
arr2 = np.array([[1],[3]])
print(arr1+arr2)
结果:
[[ 2 3 4 3 2 41]
[ 8 9 4 5 6 4]]
2.3.4 矩阵运算
numpy存储矩阵的两种方法:
import numpy as np
data = np.array([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
print(data)
data_mat = np.mat([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
print(data_mat)
如果用ndarray存储矩阵的话,就可以使用np.matmul和np.dot或使用@实现矩阵乘法
import numpy as np
data = np.array([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
weights = np.array([[0.3],[0.7]])
print(np.matmul(data,weights))
print(np.dot(data,weights))
print(data@weights)
结果:
[[84.2]
[80.6]
[80.1]
[90. ]
[83.2]
[87.6]
[79.4]
[93.4]]
[[84.2]
[80.6]
[80.1]
[90. ]
[83.2]
[87.6]
[79.4]
[93.4]]
[[84.2]
[80.6]
[80.1]
[90. ]
[83.2]
[87.6]
[79.4]
[93.4]]
如果用matrix存储矩阵的话,直接用乘法运算符即可:
import numpy as np
data = np.mat([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
weights = np.mat([[0.3],[0.7]])
print(data*weights)
结果:
[[84.2]
[80.6]
[80.1]
[90. ]
[83.2]
[87.6]
[79.4]
[93.4]]
2.4 合并与分割
合并:水平拼接和垂直拼接,以及指定轴的方式来决定水平拼接还是垂直拼接

import numpy as np
arr1 = np.array([1,2,3])
arr2 = np.array([4,5,6])
print(np.hstack((arr1,arr2)))
print(np.vstack((arr1,arr2)))
arr3 = np.array([[1],[2],[3]])
arr4 = np.array([[4],[5],[6]])
print(np.hstack((arr3,arr4)))
print(np.vstack((arr3,arr4)))
arr5 = np.array([[1,2],[3,4]])
arr6 = np.array([[5,6]])
# 垂直拼接
print(np.concatenate((arr5,arr6),axis=0))
# 水平拼接
print(np.concatenate((arr5,arr6.T),axis=1))
结果:
[1 2 3 4 5 6]
[[1 2 3]
[4 5 6]]
[[1 4]
[2 5]
[3 6]]
[[1]
[2]
[3]
[4]
[5]
[6]]
[[1 2]
[3 4]
[5 6]]
[[1 2 5]
[3 4 6]]
分割:

2.5 IO操作与数据处理
numpy读取数据文件:
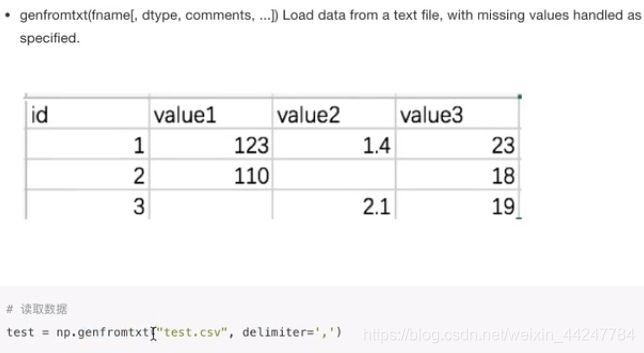
numpy读取数据文件的时候,如果读取到字符串的话会将该位置的数据置为缺失值。
对于缺失值的处理,一般是将确实的数值替换为均值或者是直接删除有缺失值的一行。
可以使用以下的函数来进行操作,但是比较麻烦,可以使用pandas库来一步搞定

3. pandas
pandas有便捷的数据处理能力,读取文件方便,封装了matplotlib,numpy的画图和计算
3.1 核心数据结构
3.1.1 DataFrame
DataFrame相当于既有行索引又有列索引的二维数组

import numpy as np
import pandas as pd
def demo1():
data = np.random.normal(0, 1, (10, 5))
print(data)
data1 = pd.DataFrame(data)
print(data1)
# 添加行索引
stock = ["股票{}".format(i) for i in range(10)]
# 添加列索引
date = pd.date_range(start="20210126",periods=5,freq="B")
data2 = pd.DataFrame(data,index=stock,columns=date)
print(data2)
if __name__ == "__main__":
demo1()
结果:
[[-1.28095016 -0.26045133 0.20035658 1.84401709 0.2503178 ]
[-1.20290407 0.10720534 0.90878277 -0.02548693 -0.14479546]
[ 0.5995495 1.033036 -0.31881776 2.6453967 0.29442546]
[ 0.11401251 -1.07258195 1.99018016 -0.11760257 1.24822281]
[ 1.46695719 -0.05683459 -0.68458832 -1.13641318 0.64074207]
[ 0.65036273 -1.58222221 -0.33273749 0.02905233 0.38896147]
[ 1.89940071 -0.46578123 -1.83647957 -0.01680048 0.76208353]
[-0.62733603 -1.10112921 -0.66519253 -0.29831209 -0.12972078]
[-1.52099949 0.03118658 -0.38919282 -0.87170288 0.01137859]
[ 0.54014074 -0.35009398 0.59009802 -0.72442847 -0.42871635]]
0 1 2 3 4
0 -1.280950 -0.260451 0.200357 1.844017 0.250318
1 -1.202904 0.107205 0.908783 -0.025487 -0.144795
2 0.599549 1.033036 -0.318818 2.645397 0.294425
3 0.114013 -1.072582 1.990180 -0.117603 1.248223
4 1.466957 -0.056835 -0.684588 -1.136413 0.640742
5 0.650363 -1.582222 -0.332737 0.029052 0.388961
6 1.899401 -0.465781 -1.836480 -0.016800 0.762084
7 -0.627336 -1.101129 -0.665193 -0.298312 -0.129721
8 -1.520999 0.031187 -0.389193 -0.871703 0.011379
9 0.540141 -0.350094 0.590098 -0.724428 -0.428716
2021-01-26 2021-01-27 2021-01-28 2021-01-29 2021-02-01
股票0 -1.280950 -0.260451 0.200357 1.844017 0.250318
股票1 -1.202904 0.107205 0.908783 -0.025487 -0.144795
股票2 0.599549 1.033036 -0.318818 2.645397 0.294425
股票3 0.114013 -1.072582 1.990180 -0.117603 1.248223
股票4 1.466957 -0.056835 -0.684588 -1.136413 0.640742
股票5 0.650363 -1.582222 -0.332737 0.029052 0.388961
股票6 1.899401 -0.465781 -1.836480 -0.016800 0.762084
股票7 -0.627336 -1.101129 -0.665193 -0.298312 -0.129721
股票8 -1.520999 0.031187 -0.389193 -0.871703 0.011379
股票9 0.540141 -0.350094 0.590098 -0.724428 -0.428716
DataFrame的常用属性:
- shape:返回数据的形状
- index:返回DataFrame的行索引列表
- columns:返回DataFrame的列索引列表
- values:直接获取其中array的值,返回ndarray
- T:进行行列转置
DataFrame的方法:
- head():返回前几行数据,默认是前5行
- tail():返回后几行数据,默认是后5行
DataFrame索引的修改:
DataFrame不支持修改某一行的索引,如果要修改需要整体进行修改,可以直接通过对index属性进行赋值来修改
可以使用reset_index(drop=True)来重设索引,drop=True的话则将原来的索引删除
,drop=False的话则将原来的索引变为新一列然后再增加一列索引
import numpy as np
import pandas as pd
def demo2():
data = np.random.normal(0, 1, (10, 5))
data1 = pd.DataFrame(data)
# 添加行索引
stock = ["股票{}".format(i) for i in range(10)]
# 添加列索引
date = pd.date_range(start="20210126",periods=5,freq="B")
data2 = pd.DataFrame(data,index=stock,columns=date)
print(data2)
print(data2.reset_index(drop=True))
print(data2.reset_index(drop=False))
if __name__ == "__main__":
demo2()
结果:
2021-01-26 2021-01-27 2021-01-28 2021-01-29 2021-02-01
股票0 0.171717 -0.389784 -1.239821 1.780470 -0.690360
股票1 0.018914 1.747446 -0.888195 0.780313 -1.101143
股票2 0.718999 -1.890617 -1.871154 -2.109124 0.027405
股票3 -0.279745 -0.218660 2.359334 -1.006337 0.793396
股票4 0.585856 -1.324523 0.525067 1.310303 -0.549742
股票5 0.133212 0.495472 0.531882 -0.153663 0.912411
股票6 -0.772119 -0.356099 1.697367 1.379959 -1.261392
股票7 1.410630 -0.192533 -0.222263 1.414229 -0.263878
股票8 -0.872018 0.624336 0.785457 1.442378 -1.867311
股票9 2.030647 0.599307 -0.268699 -0.202927 0.227605
2021-01-26 2021-01-27 2021-01-28 2021-01-29 2021-02-01
0 0.171717 -0.389784 -1.239821 1.780470 -0.690360
1 0.018914 1.747446 -0.888195 0.780313 -1.101143
2 0.718999 -1.890617 -1.871154 -2.109124 0.027405
3 -0.279745 -0.218660 2.359334 -1.006337 0.793396
4 0.585856 -1.324523 0.525067 1.310303 -0.549742
5 0.133212 0.495472 0.531882 -0.153663 0.912411
6 -0.772119 -0.356099 1.697367 1.379959 -1.261392
7 1.410630 -0.192533 -0.222263 1.414229 -0.263878
8 -0.872018 0.624336 0.785457 1.442378 -1.867311
9 2.030647 0.599307 -0.268699 -0.202927 0.227605
index 2021-01-26 00:00:00 2021-01-27 00:00:00 2021-01-28 00:00:00 2021-01-29 00:00:00 2021-02-01 00:00:00
0 股票0 0.171717 -0.389784 -1.239821 1.780470 -0.690360
1 股票1 0.018914 1.747446 -0.888195 0.780313 -1.101143
2 股票2 0.718999 -1.890617 -1.871154 -2.109124 0.027405
3 股票3 -0.279745 -0.218660 2.359334 -1.006337 0.793396
4 股票4 0.585856 -1.324523 0.525067 1.310303 -0.549742
5 股票5 0.133212 0.495472 0.531882 -0.153663 0.912411
6 股票6 -0.772119 -0.356099 1.697367 1.379959 -1.261392
7 股票7 1.410630 -0.192533 -0.222263 1.414229 -0.263878
8 股票8 -0.872018 0.624336 0.785457 1.442378 -1.867311
9 股票9 2.030647 0.599307 -0.268699 -0.202927 0.227605
以某列值作为新的索引:

import pandas as pd
def demo3():
# 使用字典创建DataFrame
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
print(df)
# 以月份作为新的索引
print(df.set_index("month",drop=True))
# 以月份和年作为新的索引,此时DataFrame变成一个具有MultiIndex的DataFrame
print(df.set_index(["month","year"],drop=True))
if __name__ == "__main__":
demo3()
结果:
month year sale
0 1 2012 55
1 4 2014 40
2 7 2013 84
3 10 2014 31
year sale
month
1 2012 55
4 2014 40
7 2013 84
10 2014 31
sale
month year
1 2012 55
4 2014 40
7 2013 84
10 2014 31
3.1.2 MultiIndex与Panel
MultiIndex:

df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
data2 = df.set_index(["month","year"],drop=True)
print(data2.index.names,data2.index.levels)
结果:
['month', 'year'] [[1, 4, 7, 10], [2012, 2013, 2014]]
Panel:Panel相当于DataFrame的容器


3.1.3 Series
Series相当于带索引的一维数组,DataFrame可以视为Series的容器,每一行都是一个Series
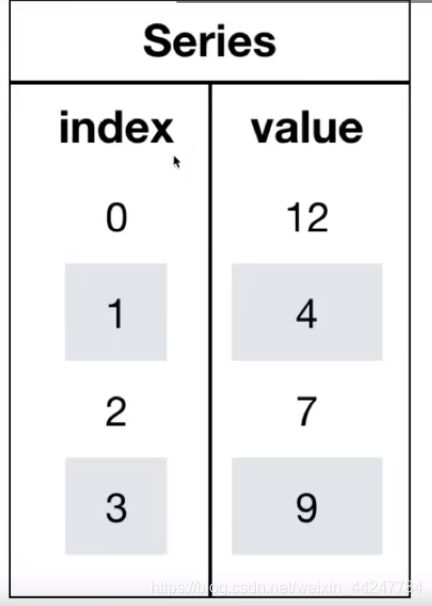

import numpy as np
import pandas as pd
def demo4():
data = np.random.normal(0, 1, (10, 5))
data1 = pd.DataFrame(data)
# 添加行索引
stock = ["股票{}".format(i) for i in range(10)]
# 添加列索引
date = pd.date_range(start="20210126",periods=5,freq="B")
data2 = pd.DataFrame(data,index=stock,columns=date)
print(data2)
# 使用iloc函数获取DataFrame的某一行能够得到一个Series对象
data3 = data2.iloc[1,:]
print(type(data3))
# 获取Series对象的索引
print(data3.index)
# 获取Series对象的值
print(data3.values)
if __name__ == "__main__":
demo4()
结果:
2021-01-26 2021-01-27 2021-01-28 2021-01-29 2021-02-01
股票0 -0.737851 2.013700 -0.266148 -0.446014 -1.354341
股票1 0.878132 1.277722 -0.677113 0.616920 0.780589
股票2 -0.051506 -1.219969 -0.422884 -1.374329 1.894216
股票3 1.421975 -0.525249 -0.110309 0.823349 -1.401268
股票4 -2.392069 1.072458 0.436807 -1.253221 -0.207052
股票5 0.329841 0.728191 0.125691 1.513885 0.811281
股票6 -0.692596 -0.809229 -0.707335 -0.541207 -0.776394
股票7 -0.373827 0.496062 -1.497040 0.962436 -0.299243
股票8 -0.746395 0.380131 -1.139016 0.513748 -0.031234
股票9 -0.742670 0.031685 1.117365 -0.054933 -0.820402
<class 'pandas.core.series.Series'>
DatetimeIndex(['2021-01-26', '2021-01-27', '2021-01-28', '2021-01-29',
'2021-02-01'],
dtype='datetime64[ns]', freq='B')
[ 0.87813154 1.27772211 -0.67711334 0.61691971 0.78058908]
3.2 基本数据操作
3.2.1 索引操作
直接索引:
DataFrame直接进行数字索引的话会报错,如果想要直接进行索引的话要先行后列
import pandas as pd
# 读取数据
data = pd.read_csv("D:\wampserver\www\code\shujuwajue\stock_day.csv")
# 按列删除一些数据让数据变得更简单一些
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
print(data)
# 直接索引,必须先列后行
print(data['open']['2018-02-23'])
如果要先行后列进行索引 ,必须借助loc,即按名字索引:
import pandas as pd
# 读取数据
data = pd.read_csv("D:\wampserver\www\code\shujuwajue\stock_day.csv")
# 按列删除一些数据让数据变得更简单一些
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
print(data)
print(data.loc['2018-02-23']['open'])
print(data.loc['2018-02-23','open'])
结果:
open high close low volume price_change p_change turnover
2018-02-27 23.53 25.88 24.16 23.53 95578.03 0.63 2.68 2.39
2018-02-26 22.80 23.78 23.53 22.80 60985.11 0.69 3.02 1.53
2018-02-23 22.88 23.37 22.82 22.71 52914.01 0.54 2.42 1.32
2018-02-22 22.25 22.76 22.28 22.02 36105.01 0.36 1.64 0.90
2018-02-14 21.49 21.99 21.92 21.48 23331.04 0.44 2.05 0.58
... ... ... ... ... ... ... ... ...
2015-03-06 13.17 14.48 14.28 13.13 179831.72 1.12 8.51 6.16
2015-03-05 12.88 13.45 13.16 12.87 93180.39 0.26 2.02 3.19
2015-03-04 12.80 12.92 12.90 12.61 67075.44 0.20 1.57 2.30
2015-03-03 12.52 13.06 12.70 12.52 139071.61 0.18 1.44 4.76
2015-03-02 12.25 12.67 12.52 12.20 96291.73 0.32 2.62 3.30
[643 rows x 8 columns]
22.88
22.88
如果要按数字索引的话要借助iloc:
# 读取数据
data = pd.read_csv("D:\wampserver\www\code\shujuwajue\stock_day.csv")
# 按列删除一些数据让数据变得更简单一些
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
print(data)
print(data.iloc[1,0])
结果:
open high close low volume price_change p_change turnover
2018-02-27 23.53 25.88 24.16 23.53 95578.03 0.63 2.68 2.39
2018-02-26 22.80 23.78 23.53 22.80 60985.11 0.69 3.02 1.53
2018-02-23 22.88 23.37 22.82 22.71 52914.01 0.54 2.42 1.32
2018-02-22 22.25 22.76 22.28 22.02 36105.01 0.36 1.64 0.90
2018-02-14 21.49 21.99 21.92 21.48 23331.04 0.44 2.05 0.58
... ... ... ... ... ... ... ... ...
2015-03-06 13.17 14.48 14.28 13.13 179831.72 1.12 8.51 6.16
2015-03-05 12.88 13.45 13.16 12.87 93180.39 0.26 2.02 3.19
2015-03-04 12.80 12.92 12.90 12.61 67075.44 0.20 1.57 2.30
2015-03-03 12.52 13.06 12.70 12.52 139071.61 0.18 1.44 4.76
2015-03-02 12.25 12.67 12.52 12.20 96291.73 0.32 2.62 3.30
[643 rows x 8 columns]
22.8
3.2.2 赋值操作
赋值操作通常结合索引操作来进行,直接对索引到的数进行赋值即可
3.2.3 排序操作
排序操作即可以对DataFrame进行排序,也可以对Series进行排序
对内容排序:
使用sort_values()对DataFrame的内容进行排序

# 读取数据
data = pd.read_csv("D:\wampserver\www\code\shujuwajue\stock_day.csv")
# 按列删除一些数据让数据变得更简单一些
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
# 按一个字段进行排序
data1 = data.sort_values(by="open",ascending=False)
print(data1)
# 按多个字段进行排序
data2 = data.sort_values(by=["open","high"],ascending=False)
print(data2)
对Series的内容进行排序的话也是用这个方法,只不过不用指定字段,直接调用即可
对索引排序:
使用DataFrame.sort_index()对索引进行排序
# 读取数据
data = pd.read_csv("D:\wampserver\www\code\shujuwajue\stock_day.csv")
# 按列删除一些数据让数据变得更简单一些
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
data3 = data.sort_index()
print(data3)
对Series的索引进行排序的话也是用这个方法,直接调用即可
3.2 DataFrame运算
算术运算:即可以用算术运算符,也可以用相关函数
# 读取数据
data = pd.read_csv("D:\wampserver\www\code\shujuwajue\stock_day.csv")
# 按列删除一些数据让数据变得更简单一些
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
# 给open列+3
print((data['open'] + 3).head())
print(data['open'].add(3).head())
# 给open列-3
print((data['open'] - 3).head())
print(data['open'].sub(3).head())
逻辑运算:
可以对DataFrame使用逻辑运算符<,>,|,&,同时可以进行布尔索引
# 使用逻辑运算符
print(data['open'] > 20)
# 进行布尔索引
print(data[(data['open'] > 20) & (data['open'] < 25) ])
逻辑运算函数:
- query(),传入一个具有逻辑运算符的字符串进行查询
- isin(),判断某些值是否为指定的值
# 使用query函数达成更上面进行布尔索引一样的效果
print(data.query('open > 20 & open < 25'))
# 找出turnover列值为4.19和2.39的值
print(data[data['turnover'].isin([4.19,2.39])])
统计运算:
统计函数:
- describe():能够一次性得出很多统计指标的数值
print(data.describe())
结果:
open high close low volume price_change p_change turnover
count 643.000000 643.000000 643.000000 643.000000 643.000000 643.000000 643.000000 643.000000
mean 21.272706 21.900513 21.336267 20.771835 99905.519114 0.018802 0.190280 2.936190
std 3.930973 4.077578 3.942806 3.791968 73879.119354 0.898476 4.079698 2.079375
min 12.250000 12.670000 12.360000 12.200000 1158.120000 -3.520000 -10.030000 0.040000
25% 19.000000 19.500000 19.045000 18.525000 48533.210000 -0.390000 -1.850000 1.360000
50% 21.440000 21.970000 21.450000 20.980000 83175.930000 0.050000 0.260000 2.500000
75% 23.400000 24.065000 23.415000 22.850000 127580.055000 0.455000 2.305000 3.915000
max 34.990000 36.350000 35.210000 34.010000 501915.410000 3.030000 10.030000 12.560000
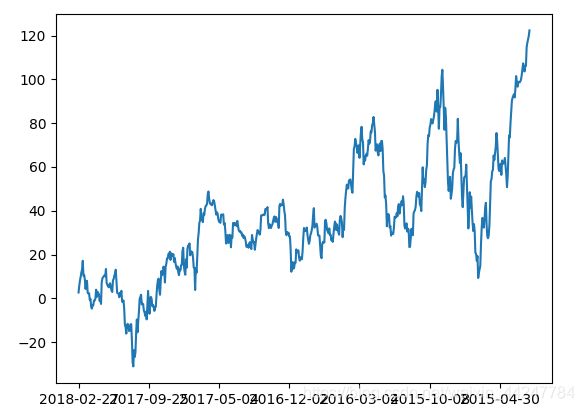
累计统计函数:

print(data['p_change'].cumsum())
data['p_change'].cumsum().plot()
plt.show()
结果:
2018-02-27 2.68
2018-02-26 5.70
2018-02-23 8.12
2018-02-22 9.76
2018-02-14 11.81
...
2015-03-06 114.70
2015-03-05 116.72
2015-03-04 118.29
2015-03-03 119.73
2015-03-02 122.35
Name: p_change, Length: 643, dtype: float64
自定义运算:如果不满足pandas提供的函数,可以使用自己定义的函数,然后通过apply函数进行调用

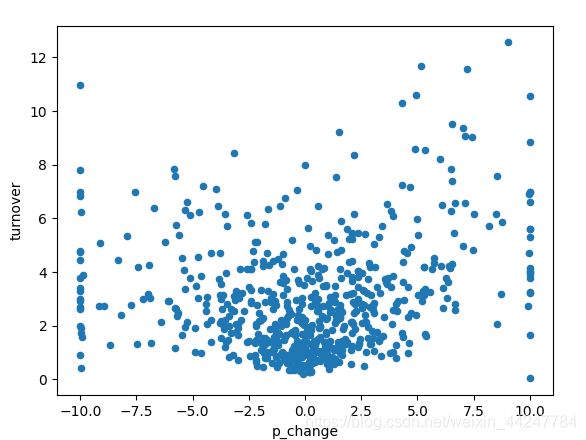
3.3 pandas画图

import pandas as pd
import matplotlib.pyplot as plt
data.plot(x="p_change",y="turnover",kind="scatter")
plt.show()
3.4 文件读取与存储
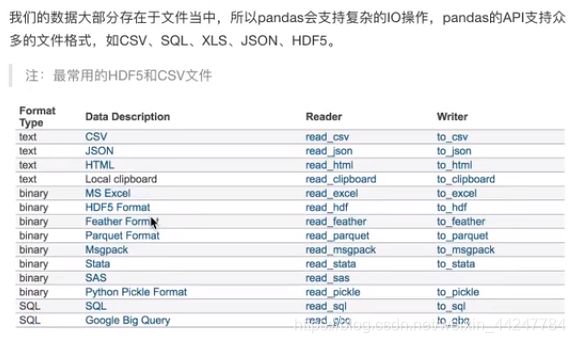
读取csv文件:

如果csv文件没有字段名的话,那么会默认将第一行作为字段名,因此还可以使用一个参数names,传入一个列表来作为参数
pd.read_csv("./stock_day/stock_day.csv", usecols=["high", "low", "open", "close"]).head()
data = pd.read_csv("stock_day2.csv", names=["open", "high", "close", "low", "volume", "price_change", "p_change", "ma5", "ma10", "ma20", "v_ma5", "v_ma10", "v_ma20", "turnover"])
写入csv文件:

# 保存'open'列的数据,可以指定是否要保存索引
data[:10].to_csv("test.csv", columns=["open"],index=False,mode='a',header=False)
HDF5文件的读取和存储:
HDF5文件是可以用来存储三维数据的二进制文件,是因为一个DataFrame是一个二维数据,每个DataFrame又需要对应一个键,

day_close = pd.read_hdf("./stock_data/day/day_close.h5")
day_close.to_hdf("test.h5", key="close")
day_open = pd.read_hdf("./stock_data/day/day_open.h5")
pd.read_hdf("test.h5", key="close").head()
当hdf5文件中只有一个键时,读取hdf5文件不用指定key,而当hdf5文件中不只一个key时,读取hdf5文件的时候就必须指定key,否则会报错,把dataframe数据存储到hdf5文件中需要指定键

JSON文件的读取和存储:
读取json文件必须指定的参数除了文件路径外,还需要指定orient参数,告诉api读取进来的json文件以何种方式进行展示,一般都指定为records,还要指定lines,是否按行读取对象,一般写True

sa = pd.read_json("Sarcasm_Headlines_Dataset.json", orient="records", lines=True)
sa.to_json("test.json", orient="records", lines=True)
3.5 缺失值处理
对缺失值NaN的处理:

使用dropna方法的话,可以指定一个inplace参数,指定为True,修改原始的DataFrame,如果指定为False(默认)的话,会返回一个新的DataFrame
import numpy as np
import pandas as pd
# 使用numpy的any和all方法来判断是否含有缺失值
print(np.any(pd.isnull(movie))) # 返回True,说明数据中存在缺失值
print(np.all(pd.notnull(movie))) # 返回False,说明数据中存在缺失值
# pandas也有相应的方法,不过返回的是每个字段是否含有缺失值
print(pd.isnull(movie).any())
print(pd.notnull(movie).all())
# 删除缺失值
data1 = movie.dropna()
# 替换缺失值
# 含有缺失值的字段
# Revenue (Millions)
# Metascore
movie["Revenue (Millions)"].fillna(movie["Revenue (Millions)"].mean(), inplace=True)
movie["Metascore"].fillna(movie["Metascore"].mean(), inplace=True)
结果:
True
False
Rank False
Title False
Genre False
Description False
Director False
Actors False
Year False
Runtime (Minutes) False
Rating False
Votes False
Revenue (Millions) True
Metascore True
dtype: bool
Rank True
Title True
Genre True
Description True
Director True
Actors True
Year True
Runtime (Minutes) True
Rating True
Votes True
Revenue (Millions) False
Metascore False
dtype: bool
当缺失值不是nan,而是其他的默认标记的话,需要这样:

3.6 数据离散化
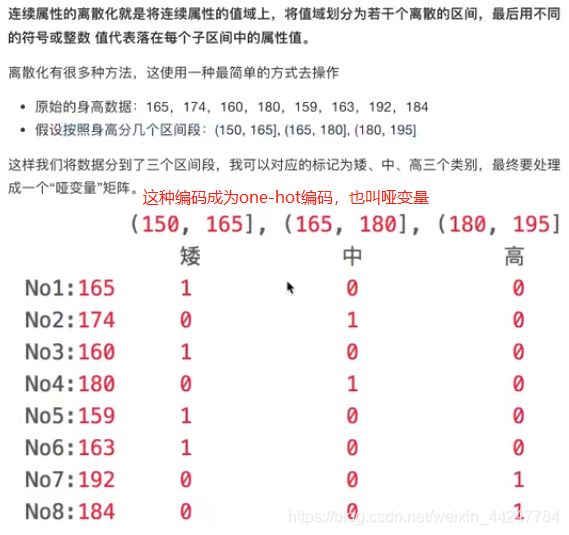

如何进行数据离散化:

qcut函数的data参数为要进行分组的数据,bins为组数
cut函数的data参数为要进行分组的数据,bins为设定好的区间,是列表形式
分完组会返回一个Series对象
将返回的Series对象传递给get_dummies函数
自动分组:
import pandas as pd
# 数据离散化
# 1.准备数据
data = pd.Series([165,174,160,180,159,163,192,184], index=['No1:165', 'No2:174','No3:160', 'No4:180', 'No5:159', 'No6:163', 'No7:192', 'No8:184'])
print(data)
# 2.分组
# 自动分组
sr = pd.qcut(data,3)
print(type(sr))
print(sr)
# 3.转换成one-hot编码
data1 = pd.get_dummies(sr,prefix="height")
print(type(data1))
print(data1)
结果:
No1:165 165
No2:174 174
No3:160 160
No4:180 180
No5:159 159
No6:163 163
No7:192 192
No8:184 184
dtype: int64
<class 'pandas.core.series.Series'>
No1:165 (163.667, 178.0]
No2:174 (163.667, 178.0]
No3:160 (158.999, 163.667]
No4:180 (178.0, 192.0]
No5:159 (158.999, 163.667]
No6:163 (158.999, 163.667]
No7:192 (178.0, 192.0]
No8:184 (178.0, 192.0]
dtype: category
Categories (3, interval[float64]): [(158.999, 163.667] < (163.667, 178.0] < (178.0, 192.0]]
<class 'pandas.core.frame.DataFrame'>
height_(158.999, 163.667] height_(163.667, 178.0] height_(178.0, 192.0]
No1:165 0 1 0
No2:174 0 1 0
No3:160 1 0 0
No4:180 0 0 1
No5:159 1 0 0
No6:163 1 0 0
No7:192 0 0 1
No8:184 0 0 1
自定义分组:
import pandas as pd
# 数据离散化
# 1.准备数据
data = pd.Series([165,174,160,180,159,163,192,184], index=['No1:165', 'No2:174','No3:160', 'No4:180', 'No5:159', 'No6:163', 'No7:192', 'No8:184'])
# 2.分组
# 自定义分组,列表包含边界即可
bins = [150,165,180,195]
sr = pd.cut(data,bins)
# 查看分组情况
print(sr.value_counts)
# 3.转化为one-hot编码
print(pd.get_dummies(sr,prefix="height"))
结果:
<bound method IndexOpsMixin.value_counts of No1:165 (150, 165]
No2:174 (165, 180]
No3:160 (150, 165]
No4:180 (165, 180]
No5:159 (150, 165]
No6:163 (150, 165]
No7:192 (180, 195]
No8:184 (180, 195]
dtype: category
Categories (3, interval[int64]): [(150, 165] < (165, 180] < (180, 195]]>
height_(150, 165] height_(165, 180] height_(180, 195]
No1:165 1 0 0
No2:174 0 1 0
No3:160 1 0 0
No4:180 0 1 0
No5:159 1 0 0
No6:163 1 0 0
No7:192 0 0 1
No8:184 0 0 1
3.7 合并
按方向拼接:
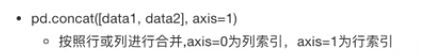
按索引拼接:能够指定拼接方式,这点跟数据库表的连接类似

内连接:保留指定列共有的部分进行连接

左连接:保留左表指定列全部数据,右表配合连接

右连接:保留右表指定列全部数据,左表配合连接
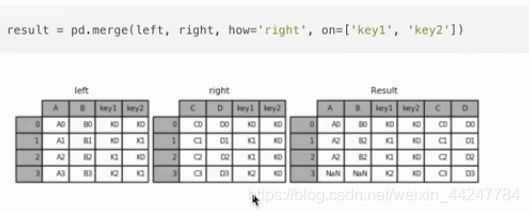
外连接:保留左右表指定列全部数据

import pandas as pd
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(left)
print(right)
print(pd.merge(left,right,how="inner",on=["key1","key2"]))
print(pd.merge(left,right,how="left",on=["key1","key2"]))
print(pd.merge(left,right,how="right",on=["key1","key2"]))
print(pd.merge(left,right,how="outer",on=["key1","key2"]))
结果:
key1 key2 A B
0 K0 K0 A0 B0
1 K0 K1 A1 B1
2 K1 K0 A2 B2
3 K2 K1 A3 B3
key1 key2 C D
0 K0 K0 C0 D0
1 K1 K0 C1 D1
2 K1 K0 C2 D2
3 K2 K0 C3 D3
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
5 K2 K0 NaN NaN C3 D3
3.8 交叉表与透视表
探索两个变量之间的关系可以使用交叉表与透视表
交叉表:

# 星期数据以及涨跌幅数据之间关系-交叉表
# 读取数据
data = pd.read_csv("D:\wampserver\www\code\shujuwajue\stock_day.csv")
# pandas日期类型
date = pd.to_datetime(data.index)
print(type(date))
# 调用对应的方法获取对应的星期
print(date.weekday)
# 准备星期数据列
data['week'] = date.weekday
# 准备涨跌幅数据列
data['pona'] = np.where(data['p_change'] > 0,1,0)
print(data)
# 交叉表
data1 = pd.crosstab(data['week'],data['pona'])
# 求出频率
data1 = data1.div(data1.sum(axis=1),axis=0)
print(data1)
结果:
<class 'pandas.core.indexes.datetimes.DatetimeIndex'>
Int64Index([1, 0, 4, 3, 2, 1, 0, 4, 3, 2,
...
4, 3, 2, 1, 0, 4, 3, 2, 1, 0],
dtype='int64', length=643)
open high close low volume price_change p_change ... ma20 v_ma5 v_ma10 v_ma20 turnover week pona
2018-02-27 23.53 25.88 24.16 23.53 95578.03 0.63 2.68 ... 22.875 53782.64 46738.65 55576.11 2.39 1 1
2018-02-26 22.80 23.78 23.53 22.80 60985.11 0.69 3.02 ... 22.942 40827.52 42736.34 56007.50 1.53 0 1
2018-02-23 22.88 23.37 22.82 22.71 52914.01 0.54 2.42 ... 23.022 35119.58 41871.97 56372.85 1.32 4 1
2018-02-22 22.25 22.76 22.28 22.02 36105.01 0.36 1.64 ... 23.137 35397.58 39904.78 60149.60 0.90 3 1
2018-02-14 21.49 21.99 21.92 21.48 23331.04 0.44 2.05 ... 23.253 33590.21 42935.74 61716.11 0.58 2 1
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
2015-03-06 13.17 14.48 14.28 13.13 179831.72 1.12 8.51 ... 13.112 115090.18 115090.18 115090.18 6.16 4 1
2015-03-05 12.88 13.45 13.16 12.87 93180.39 0.26 2.02 ... 12.820 98904.79 98904.79 98904.79 3.19 3 1
2015-03-04 12.80 12.92 12.90 12.61 67075.44 0.20 1.57 ... 12.707 100812.93 100812.93 100812.93 2.30 2 1
2015-03-03 12.52 13.06 12.70 12.52 139071.61 0.18 1.44 ... 12.610 117681.67 117681.67 117681.67 4.76 1 1
2015-03-02 12.25 12.67 12.52 12.20 96291.73 0.32 2.62 ... 12.520 96291.73 96291.73 96291.73 3.30 0 1
[643 rows x 16 columns]
pona 0 1
week
0 0.504000 0.496000
1 0.419847 0.580153
2 0.462121 0.537879
3 0.492188 0.507812
4 0.464567 0.535433
使用透视表实现:
# 使用透视表,相当于使pona列的数据基于week列进行分类
data1 = data.pivot_table(['pona'],index=['week'])
print(data1)
结果:
pona
week
0 0.496000
1 0.580153
2 0.537879
3 0.507812
4 0.535433
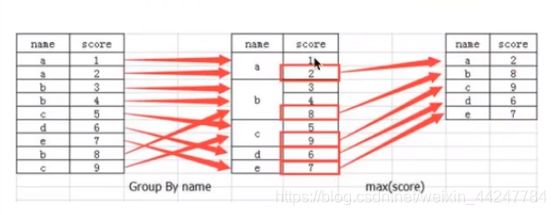
3.9 分组与聚合
分组与聚合是分析数据的一种方式,通常与统计函数一起使用,查看数据的分组情况
![]()
用DataFrame的方法进行分组
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
print(col)
# 对颜色进行分组,对价格进行聚合
data = col.groupby(by="color")['price1'].max()
print(data)
结果:
color object price1 price2
0 white pen 5.56 4.75
1 red pencil 4.20 4.12
2 green pencil 1.30 1.60
3 red ashtray 0.56 0.75
4 green pen 2.75 3.15
color
green 2.75
red 4.20
white 5.56
Name: price1, dtype: float64
用Series的方法进行分组,结果是一样的
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
print(col)
# 对颜色进行分组,对价格进行聚合
data = col['price1'].groupby(col['color']).max()
print(data)
结果:
color object price1 price2
0 white pen 5.56 4.75
1 red pencil 4.20 4.12
2 green pencil 1.30 1.60
3 red ashtray 0.56 0.75
4 green pen 2.75 3.15
color
green 2.75
red 4.20
white 5.56
Name: price1, dtype: float64