第四篇:MySQL之binlog和redolog
1、引言
这篇文章说下MySQl中的恢复日志中的binlog和redolog。
2、binlog
binlog称为二进制日志或者归档日志,是MySQL中Server层的一个组件,主要记录除查询以外的操作(delete、update、insert、DML等),主要用于主从复制和数据恢复。
binlog的数据格式有如下三种
| 格式 | 做法 | 优点 | 缺点 |
|---|---|---|---|
| STATEMENT | 直接记录相关的SQL语句,在恢复的时候直接执行SQL语句 | 数据量小,节省磁盘IO | 由于某些函数UUID()、NOW()等函数,并且需要上下文关联,容易造成主从复制不一致 |
| ROW | 直接保存修改的行记录对应的数据,在恢复的时候直接利用主键找到相关记录直接进行修改 | 能正确无误的恢复数据 | 数据量大 |
| MIXED | STATEMENT和ROW的混合使用,一般使用STATEMENT记录,若碰到STATEMENT无法解决的情况,用ROW方式来记录 | 数据量小,并且能够正确复制 | ,如下图所示的读提交级别下的幻读问题,还是会造成数据不一致 |
binlog中的顺序B、C、A,C中新插入的记录会被A修改,造成数据不一致
所以说如果想要主从一致,还是建议把binlog设置为ROW。
binlog的刷盘策略
binlog首先会写入到内存,每个事务都单独享用一片内存,然后提交到操作系统的cache中,最后刷新到磁盘上
有以下三种策略:
1、取0,每次提交事务只写入到cache中,由系统自行决定从cache中刷盘到磁盘上
2、取1,每次提交事务都直接写入到cache中,然后提交到磁盘上
3、取N,每次提交事务都写入到cache中,每隔N个事务,然后从cache中提交到磁盘上。
3、redolog
redolog的出现原因
redolog是InnoDB引擎特有的功能,用来解决数据库重启或者发生异常造成的数据丢失,保证数据库的crash-safe。
为了更好的读取性能,MySQL在内存中开辟了BufferPool来存放数据页,相对于读取磁盘,可以加快读取效率。
当修改数据页后,将修改内容通过顺序写的方式写入到redolog日志中,相对于随机修改磁盘中的数据页,可以提高更新效率。顺序写相对于随机写效率更好。当出现异常的时候,通过对redolog日志重放,更新磁盘上的数据页,即可保证数据库的数据完整。这种做法也叫做WAL技术。全称为Write-Ahead Log,先写日志,即先写redolog日志。
redolog的结构图

redolog采用多个文件file首尾相连循环使用的方法来记录日志,当文件空间使用完毕后,会覆盖重复使用。其中checkpoint为检查点,checkpoint之前的所有日志均已经更新到磁盘上的数据页,可以覆盖。Write_Position为当前日志的写入点,checkpoint和Write_Position之间的日志代表尚未更新到磁盘上数据页的日志。
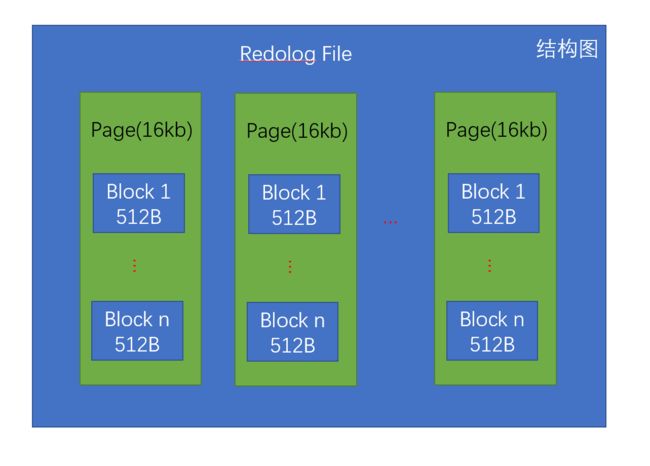
每个file对应多个page数据页,大小为16kb,一个数据也又对应着若干个block块,大小为512B。
每个文件的开头的4个Block不存放具体的redolog数据,用来存放管理信息。第一个Block被称为Header Block,主要用来存放本文件的startLsn。LSN全称为Log Sequence Num,也就是日志序列号。 LSN随着redolog的写入不断增加,是每个事物对应的redolog的唯一标志。剩下的三个Block主要用来存放checkpoint。剩余的Block用来存放具体的Redolog记录。
Block的具体格式如下

Block Header主要存放管理信息,比如Block的编号、Block中的写入的日志长度、Block中第一个日志Log的偏移位置等。
Log Block主要存放具体的Log信息,按照记录头尾相连的方式来排列。
Block Tailer 主要存放检验和,用来检验Block是否完全成功更新磁盘数据。
redolog的工作流程
1、一个事务对应着一个可变内存区域来暂时存放redolog数据。一个事务的逻辑事务对应着多个物理事务。逻辑事务就是指的我们通常说的事务:begin、commit的事务。一个物理事务就是对应着一个数据页page的更改。因为一个逻辑事务甚至是一条更新语句就会同时修改多个page。一个物理事务对应着一条redolog日志,该日志有着该事务前一条redolog日志的指针。
2、当满足一个物理事务后,会将redolog从可变临时内存拷贝到logBuffer中。此时就生成了redolog的对应的LSN,同时将LSN填入到内存中的数据页中。
3、根据刷盘策略将redolog日志刷到磁盘上。
redolog的刷盘策略
redolog从LogBuffer刷盘到file中的有三个模式,由变量innodb_flush_log_at_trx_commit控制,可以去以下三个值:
1、取0 ,由MySQL后台线程每秒将LogBuffer中的数据刷新到操作系统的OsBuffer中,接着刷盘到磁盘中。
2、取1 ,此时当事务提交时,立即将LogBuffer中的数据提交到OsBuffer中,接着刷盘到磁盘中。
3、取2,此时当事务提交时,立即将LogBuffer中的数据提交到OsBuffer中,然后等待操作系统的后台线程每秒将OsBuffer中的数据刷盘到磁盘中。
redolog的crash恢复策略:
我们首先关注两个问题:
1、未提交事务的redolog有可能刷盘:
因为redolog以物理事务为基本单位进行刷盘,所以有可能事务还未提交,而对应的redolog日志已经刷盘。 一个事务在redolog文件中的记录不一定是连续的,而一条redolog日志一定是连续的,对应着一个物理事务,也就是对一个数据页的修改。那你可能会有疑问,如果用户手动回滚了怎么办?是不是还得将redolog删除? 其实不是的,如果用户手动回滚的话,系统会往redolog文件中写入与之前操作的相反的数据,然后commit,这样就可以通过commit的方式来进行回滚。
2、checkpoint是什么?
在说checkpoint之前,我们先说下内存中统计了有两个表信息:
1、当前bufferpool中的脏页信息表
统计了bufferpool中的内存脏页号,以及导致该页为脏页的最小的LSN。
| dirty page no(脏页号) | LSN(导致该页为脏页的最早的LSN) |
|---|
2、当前活跃的事务信息表
统计当前活跃事务,也就是未提交事务的事务ID和该事务最新的lastedLSN。通过lastedLSN和redolog日志中的前一条redolog日志指针,就可以追溯到该事务的所有redolog日志。
| transaction id(脏页号) | lastedLSN(该事务最新的LSN) |
|---|
我们通常说的写checkpoint的就是将这两个表的信息写入到redolog中。
当满足一定条件时,系统会写checkpoint,触发写checkpoint的策略在下文中会详解。
有了这两个知识基础,我们开始说crash恢复。
1、首先找到离崩溃点最接近的的checkpoint,取出当中的活跃事务列表以及脏页列表。然后从 checkpoint 开始遍历redolog文件,直到文件结尾。
在遍历过程中,我们做以下两件事:
1、如果碰到某些事务的commit标记就将该事务从活跃事务列表中移出,如果碰到某些事务的begin标记就将该事务加入到活跃事务列表中。
2、如果某些数据页被修改了,并且该数据页是第一次被更改,就将该数据页号加入到脏页信息表中。
到达末尾之后,就可获取到数据库crash时对应的未提交的事务列表和脏页信息表。
脏页信息表中记录导致脏页变脏的最小的lsn。
事务信息表中记录了活跃事务对应的最新的lsn。
2、取脏页信息表中最小的LSN作为redo重放的起点,再一次遍历redolog文件,这次就开始进行恢复了,如果磁盘数据页中对应的LSN大于redolog日志记录中的LSN则说明该磁盘数据页已经刷过盘了,不需要更新了。
3、重放结束后,这时内存中就恢复了crash前的场景了,现在就差最后一步,需要把没有提交的事务,也就是活跃的事务进行回滚。我们之前已经得到了活跃的事务列表,事务列表中也记录了事务对应的最新的lsn。redolog中的记录存放的有同一个事务的上一条记录的prevLsn,我们靠着prevLsn和最新的lsn,可以顺着往前遍历其redolog日志记录,然后依次将其对应的反操作写入到redolog文件的末尾,并且重放就ok了。RedoLog中除了包含修改后的值,还有修改之前的值用于回滚。
4、回滚写入的redolog跟普通的redolog有点不同,回滚的redolog日志中有一个undoNxtLsn,记录的是上一条待回滚的记录的lsn。当系统在事务回滚的时候崩溃了,首先会遍历整个redolog,将系统恢复到了之前回滚一半的状态了。
然后从事务对应的最新的lsn开始回滚,一看最新的lsn对应的有undoNxtLsn字段,发现这是一个回滚日志,不会对回滚日志进行回滚,而是查看对应的undoNxtLsn字段,找到对应的之前的待回滚日志,然后接着进行回滚。
通过一个undoNxtLsn来区别回滚redolog和待回滚的redolog,不会造成对回滚redolog进行回滚的情况。
4、binlog和redolog的两阶段提交
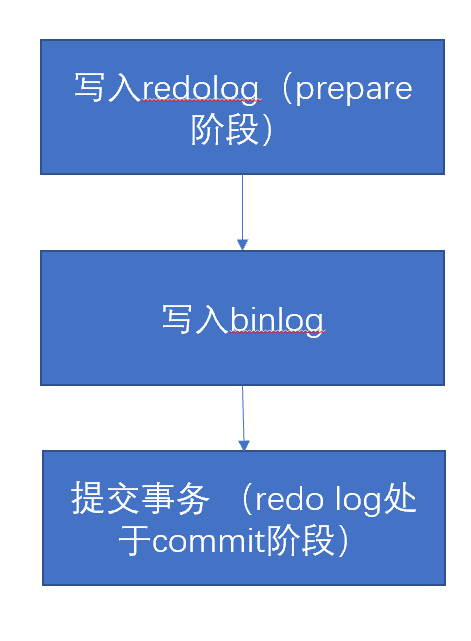
为了保证binlog和redolog的数据一致性,MySQL采用两阶段提交,此时binlog和redolog的刷盘策略必须设置为双1。,如果不设置双1的话,redolog和binlog都是各自写各自的,有可能会redolog刷盘了,而binlog没有刷盘或者redolog没有刷盘,而binlog刷盘了,无法确定是否一致。两阶段提交的话,先写redolog后写binlog,如果binlog没有写完则回滚redolog,如果binlog写完了则提交redolog的事务。
1、首先写入redo log,写完后,redolog处于prepare阶段
2、写入binlog
3、提交事务,将redo log转化为commit阶段
具体的原理如下:
1、当redolog没有写完后,系统崩溃。此时,当重放redo log时,没有检测到prepare标记,会回滚事务。此时binlog也没有写入,二者数据保持一致
2、当redolog写入prepare标记后,还未写完binlog时系统崩溃。此时也会回滚事务。二者的数据保持一致。
3、当binlog也写完后,事务提交时系统崩溃,此时需要查看redolog是否写完整,如果redolog有commit标记,则提交事务。如果redolog没有commit标记,则要查看binlog对应的commit标记,如果binlog有commit标记,则提交事务,如果没有commit标记则回滚事务。二者的数据仍保持一致
binlog和redolog通过XID来进行绑定,通过XID来查询对应的redolog和binlog。
5、redolog组提交和binlog组提交
因为redolog和binlog的写入有三个层次:内存、系统cache、磁盘。
从系统cache刷到磁盘上的操作叫做fsync。
当多个事务的redolog或binlog同时做fsync的时候,这多个事务可以合并为一组,批量写入,加快了刷盘的效率。
6、checkpoint机制
checkpoint触发的时候,主要干两件事:
1、 将Buffer Pool中的脏页刷新到磁盘上
2、 将对应的脏页信息和活跃事务信息写入到redolog日志中
checkpoint有以下好处:
1、可以缩短数据库的恢复时间
2、当buffer pool中的内存不够用时,刷新脏页到磁盘中
3、当redolog file不够用时,将脏页刷新到磁盘中
脏页就是在内存中被更改过的数据页,与磁盘上的数据页的数据不一致,称为脏页。
checkpoint就是将内存中统计的这两个表的信息刷新到redolog中:
1、当前bufferpool中的脏页信息表
统计了bufferpool中的内存脏页号,以及导致该页为脏页的最小的LSN。
| dirty page no(脏页号) | LSN(导致该页为脏页的最早的LSN) |
|---|
2、当前活跃的事务信息表
统计当前活跃事务,也就是未提交事务的事务ID和该事务最新的lastedLSN。通过lastedLSN和redolog日志中的前一条redolog日志指针,就可以追溯到该事务的所有redolog日志。
| transaction id(脏页号) | lastedLSN(该事务最新的LSN) |
|---|
我们通常说的写checkpoint的就是将这两个表的信息写入到redolog中。
当满足一定条件时,系统会写checkpoint,触发写checkpoint的策略在下文中会详解。
MySQL中有两类checkpoint,sharp checkpoint和fuzzy checkpoint。
1、sharp checkpoint
当数据库关闭的时候,将内存中的所有脏页全部刷入到磁盘中,这时redolog 就没用了,因为磁盘中的数据和内存中的数据保持一致,会刷新checkpoint。checkpoint就为空了。
2、fuzzy checkpoint
数据库运行的时候刷新脏页
2.1、Master线程每隔一段时间将Buffer Pool中的脏页刷新到磁盘上
2.2、当Buffer Pool中脏页过多时
2.3、当Buffer Pool中的空闲页过少时
2.4、当redolog file 文件容量不够时,触发Buffer Pool中的脏页刷盘。
上面这几种checkpoint会将最近未使用的脏页刷新到了磁盘上,最近未使用的脏页对应的lsn是最小的,这样的话,checkpoint中统计的脏页信息表的最小lsn就会变大。
那么小于脏页信息表中的最小lsn的redolog中的redo记录都可以被覆盖了,因为对应的数据已经被刷新到磁盘上了。