Flink快速入门
1、大数据处理框架发展史
-
大数据-3v-tpezy-分而治之

-
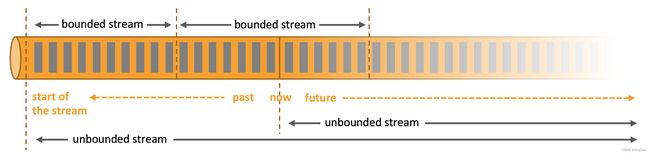
批处理流处理-微信运动、信用卡月度账单、国家季度GDP增速
-
MPI-节点间数据通信-c和python

-
MR-2004谷歌提出的编程范式-hadoop/storm/spark/flink

-
Hadoop-MR、HDFS、YARN(hive/pig/hbase/oozie)
-
Storm

-
Spark-cache/lineage-DAG/多线程池模型




-
Flink
- 2008年柏林理工大学一个研究性项目Stratosphere;
- 2014-04-16成为Apache孵化项目,从Stratosphere 0.6开始,正式更名为Flink;
- 2014-08-26,Flink 0.6发布;
- 2014-11-04,Flink 0.7.0发布,介绍了最重要的特性:Streaming API;
- 2016-03-08,Flink 1.0.0,支持Scala;
- 2016-08-08,Flink 1.1.0;
- 2017-02-06,Flink 1.2.0;
- 2017-11-29,Flink 1.4.0;
- 2018-05-25,Flink 1.5.0;
- 2018-08-08,Flink 1.6.0;
- 2018-11-30,Flink 1.7.0;
- 2019年初,阿里巴巴以1.033亿美元的价格收购了总部位于德国柏林的初创公司Data Artisans,Data Artisans的核心产品是正是Flink。
- 2019-02-15,Flink 1.7.2;
- 2019-04-09,Flink 1.8.0;
- 2019-07-10,Flink 1.8.1;
- 2019-09-12,Flink 1.8.2;
- 2019-08-22,Flink 1.9.0;
- 2019-10-18,Flink 1.9.1;
- 2020-02-11,Flink 1.10.0;
- 2020-05-08,Flink 1.10.1-rc3;
- …
- 2022-04-26,Flink 1.15.0;
- 2022-07-06,Flink 1.15.1;
- 2022-08-23,Flink 1.15.2;
2、Flink概述
Apache Flink是一个框架、一个分布式处理引擎,用于对无界和有界数据流进行状态计算。
Flink 能够提供毫秒级别的延迟,同时保证了数据处理的低延迟、高吞吐和结果的准确性,还提供了丰富的时间类型和窗口计算、支持exactly-once语义,支持进行状态管理,同时还提供 了 CEP(复杂事件处理)的支持。
3、Flink学习资料
- 官方文档 :https://flink.apache.org/
- Flink 中文社区 :https://www.slidestalk.com/FlinkChina
- Flink 中文社区视频课程 :https://github.com/flink-china/flink-training-course
- Flink源码 :https://github.com/apache/flink
- 官方提供的第三方连接器 :https://bahir.apache.org/#home
- 阿里Flink开发者社区 :https://developer.aliyun.com/profile/expert/fkjpbdp6zbdkm
- Flink-1.14-API:https://nightlies.apache.org/flink/flink-docs-release-1.14/api/java/
4、Flink应用场景
- 实时监控
1.用户行为预警、app crash预警、服务器攻击预警。
2.对用户行为或者相关事件进行实时监测和分析基于风控规则进行预警。
- 实时报表分析
1.双11、双12等活动直播大屏。
2.对外数据产品:生意参谋等。
3.数据化运营。
- 实时数仓与ETL
1.数据实时清洗、归并、结构化。
2.数仓的补充和优化。
- 流数据分析
1.实时计算相关指标反馈及时调整决策。
2.内容投放、无线智能推送、实时个性化推荐等。
- 舆情分析
有的客户需要做舆情分析,要求所有数据存放若干年,舆情数据每日数据量可能超百万,年数据量可达到几十亿的数据。而且爬虫爬过来的数据是舆情,通过大数据技术进行分词之后得到的可能是大段的网友评论,客户往往要求对舆情进行查询,做全文本搜索,并要求响应时间控制在秒级。爬虫将数据爬到大数据平台的Kafka里,在里面做Flink流处理,去重去噪做语音分析,写到ElasticSearch里。大数据的一个特点是多数据源,大数据平台能根据不同的场景选择不同的数据源。
- 实时机器学习
实时机器学习是一个更宽泛的概念,传统静态的机器学习主要侧重于静态的模型和历史数据进行训练并提供预测。很多时候用户的短期行为,对模型有修正作用,或者说是对业务判断有预测作用。对系统来说,需要采集用户最近的行为并进行特征工程,然后给到实时机器学习系统进行机器学习。如果动态地实施新规则,或是推出新广告,就会有很大的参考价值。
- 复杂事件处理
对于复杂事件处理,比较常见的集中于工业领域,例如对车载传感器,机械设备等实时故障检测,这些业务类型通常数据量都非常大,且对数据处理的时效性要求非常高。通过利用Flink提供的CEP进行时间模式的抽取,同时应用Flink的Sql进行事件数据的转换,在流式系统中构建实施规则引擎,一旦事件触发报警规则,便立即将告警结果通知至下游通知系统,从而实现对设备故障快速预警检测,车辆状态监控等目的。
- 实时欺诈检测
在金融领域的业务中,常常出现各种类型的欺诈行为,例如信用卡欺诈,信贷申请欺诈等,运用Flink流式计算技术能够在毫秒内就完成对欺诈行为判断指标的计算,然后实时对交易流水进行实时拦截,避免因为处理不及时而导致的经济损失。
- 实时智能推荐
利用Flink流计算帮助用户构建更加实时的智能推荐系统,对用户行为指标
进行实时计算,对模型进行实时更新,对用户指标进行实时预测,并将预
测的信息推送给Web/App端,帮助用户获取想要的商品信息,另一方面也
帮助企业提升销售额,创造更大的商业价值。









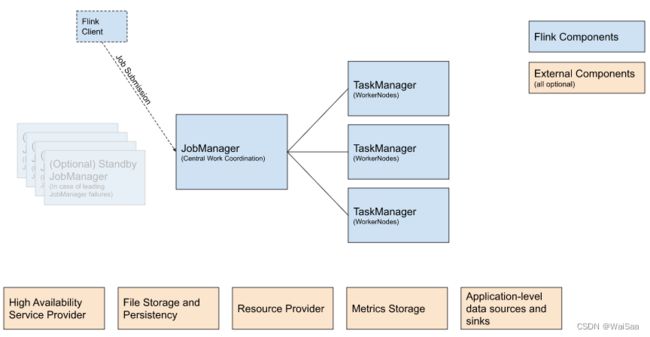
5、Flink基本架构


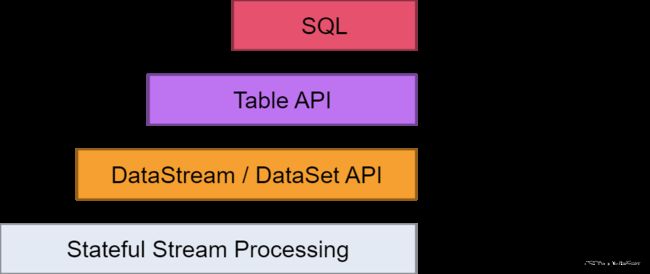

- client
- 客户端负责将任务提交到集群,与 JobManager构建Akka连接,然后任务提交到 JobManager,通过和 JobManager之间进行交互获取任务执行状态。
- 客户端提交任务可以采用CLI方式或者使用 WebuI提交。
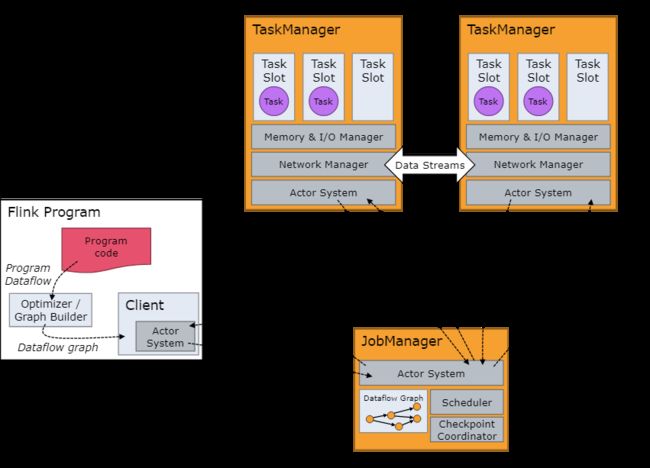
- JobManager
- JobManager负责整个Flink集群任务的调度以及资源管理;
- 从客户端中获取提交的应用,然后根据集群中TaskManager上TaskSlot的使用情况,为提交的应用分配相应的TaskSlots资源,并命令TaskManager启动从客户端中获取的应用;
- JobManager相当于整个集群的Master节点,且整个集群中有且仅有一个活跃的JobManager,负责整个集群的任务管理和资源管理;
- JobManager和TaskManager之间通过Actor System进行通信,获取任务执行的情况并通过Actor System将应用的任务执行情况发送给客户端;
- 同时在任务执行过程中,Flink JobManager会触发Checkpoint操作,每个TaskManager节点收到Checkpoint触发指令后,完成Checkpoint操作,所有的Checkpoint协调过程都是在Flink JobManager中完成;
- 当任务完成后,Flink会将任务执行的信息反馈给客户端,并释放掉TaskManager中的资源供下次提交任务的使用;
- JobManager 具有许多与协调 Flink 应用程序的分布式执行有关的职责:它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等;
- 始终至少有一个 JobManager。高可用(HA)设置中可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby;
- ResourceManager、Dispatcher、JobMaster;
- TaskManager
- TaskManager相当于整个集群的Slave节点,负责具体的任务执行和对应任务在每个节点上的资源申请与管理;
- 客户端通过将编写好的Flink应用编译打包,提交到JobManager,然后JobManager会根据已经注册在JobManager中的TaskManager的资源情况,将任务分配给有资源的TaskManager节点,然后启动并运行任务;
- TaskManager从JobManager接受需要部署的任务,然后使用Slot资源启动Task,建立数据接入的网路连接,接受数据并开始数据处理;
- TaskManager(也称为 worker)执行作业流的 task,并且缓存和交换数据流;
- 必须始终至少有一个 TaskManager。在 TaskManager 中资源调度的最小单位是 task slot。task slot是对内存资源的隔离,不涉及CPU。TaskManager 中 task slot 的数量表示并发处理 task 的数量,一个 task slot 中可以执行多个算子;
- 每个 worker(TaskManager)都是一个 JVM 进程,可以在单独的线程中执行一个或多个 subtask。为了控制一个 TaskManager 中接受多少个 task,就有了所谓的 task slots(至少一个)
6、Flink 常用算子
| Operator | Transformations |
|---|---|
| Map | DataStream → DataStream |
| FlatMap | DataStream → DataStream |
| Filter | DataStream → DataStream |
| KeyBy | DataStream → KeyedStream |
| Reduce | KeyedStream → DataStream |
| Window | KeyedStream → WindowedStream |
| WindowAll | DataStream → AllWindowedStream |
| Window Apply | WindowedStream → DataStream |
| WindowReduce | WindowedStream → DataStream |
| Connect | DataStream,DataStream → ConnectedStream |
| Union | DataStream* → DataStream |
| Window Join | DataStream,DataStream → DataStream |
| Interval Join | KeyedStream,KeyedStream → DataStream |
| Window CoGroup | DataStream,DataStream → DataStream |
| Broadcasting | DataStream → DataStream |
| ProcessFunction | events/state/timers【low-level】 |
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- ProcessJoinFunction
- BroadcastProcessFunction
- KeyedBroadcastProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
7、Flink 核心概念
-
并行度
特定算子的子任务(subtask)的个数称之为并行度(parallel),一般情况下,一个数据流的并行度可以认为是其所有算子中最大的并行度。Flink中每个算子都可以在代码中通过.setParallelism(n)来重新设置并行度。而并行执行的subtask要发布到不同的slot中去执行。 -
算子链
算子之间没有shuffle且并行度一样,则会形成operator chain,默认配置。
它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量。 -
Tasks
对于分布式执行的任务,Flink 将算子的 subtasks 链接成 tasks。每个 subtask 由一个线程执行。
下图中样例有2个并行度,数据流用 5 个 subtask 执行,因此有 5 个并行线程:

-
Task Slots 和资源
每个 worker(TaskManager)都是一个 JVM 进程,可以在单独的线程中执行一个或多个 subtask。为了控制一个 TaskManager 中接受多少个 task,就有了所谓的 task slots(至少一个)。每个 task slot 代表 TaskManager 中资源的固定子集。
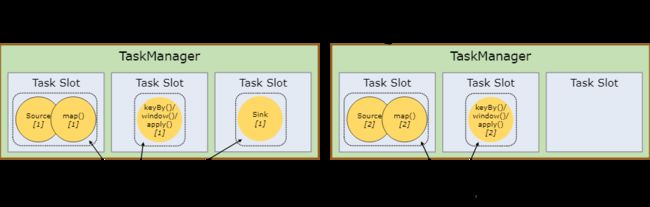
默认情况下,Flink 允许子任务共享slot,即使他们是不同任务的子任务。这样的结果就是一个slot可以保存作业的整个pipeline。
我们把上面的例子的并行度调大为6:
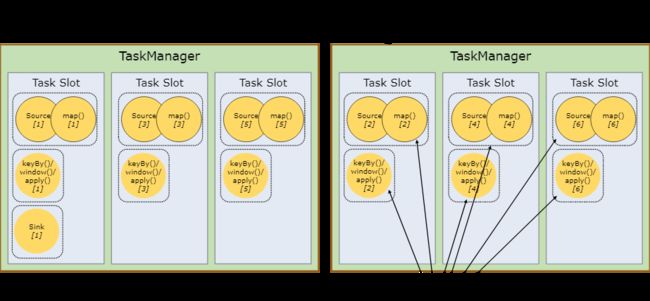
Task slot 是静态的概念,指的是TaskManager具有的并发执行能力。
Flink中slot是任务执行所申请资源的最小单元,同一个TaskManager上的所有slot都只是做了内存分离,没有做CPU隔离。
一个任务所用的总共slot为所有资源隔离组所占用的slot之和,同一个资源隔离组内,按照算子的最大并行度来分配slot。 -
分布式缓存
Flink 提供的分布式缓存类型 Hadoop,目的是为了在分布式环境中让每一个 TaskManager 节点保存一份相同的数据或者文件,当前计算节点的 task 就像读取本地文件一样拉取这些配置。
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.registerCachedFile("/Users/wangzhiwu/WorkSpace/quickstart/distributedcache.txt", "distributedCache");
//1:注册一个文件,可以使用hdfs上的文件 也可以是本地文件进行测试
DataSource<String> data = env.fromElements("Linea", "Lineb", "Linec", "Lined");
DataSet<String> result = data.map(new RichMapFunction<String, String>() {
private ArrayList<String> dataList = new ArrayList<String>();
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//2:使用该缓存文件
File myFile = getRuntimeContext().getDistributedCache().getFile("distributedCache");
List<String> lines = FileUtils.readLines(myFile);
for (String line : lines) {
this.dataList.add(line);
System.err.println("分布式缓存为:" + line);
}
}
@Override
public String map(String value) throws Exception {
//在这里就可以使用dataList
System.err.println("使用datalist:" + dataList + "-------" +value);
//业务逻辑
return dataList +":" + value;
}
});
result.printToErr();
}
-
故障恢复和重启策略
自动故障恢复是 Flink 提供的一个强大的功能,在实际运行环境中,我们会遇到各种各样的问题从而导致应用挂掉,比如我们经常遇到的非法数据、网络抖动等。Flink 提供了强大的可配置故障恢复和重启策略来进行自动恢复。 -
反压机制
flink利用自身作为纯数据流的特性优雅的实现反压机制。flink采用了有界的分布式阻塞队列(分布式缓冲队列使用缓冲池localBufferPoll实现),类似生产者消费者模式,一个较慢的接受者会减慢发送者的发送速率,因为一旦队列满了,发送者就会被阻塞。

-
状态容错、window机制和时间机制

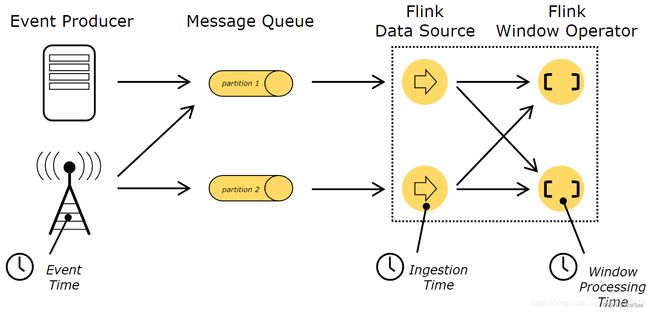
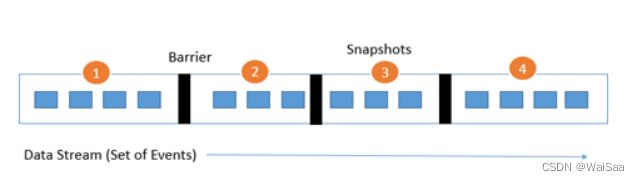
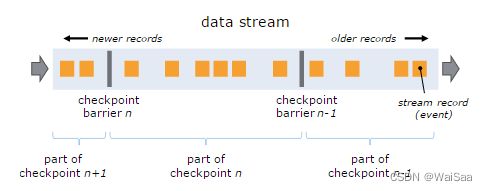

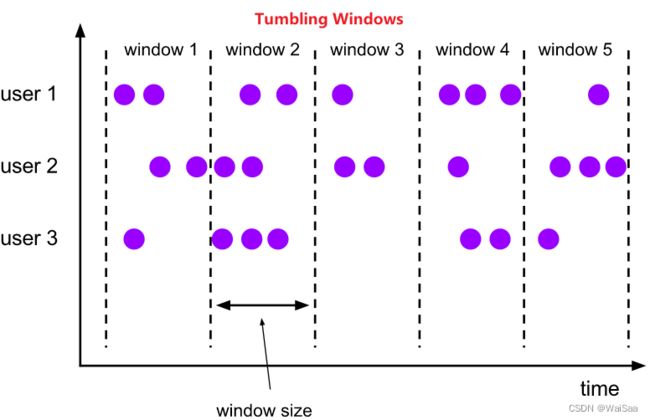


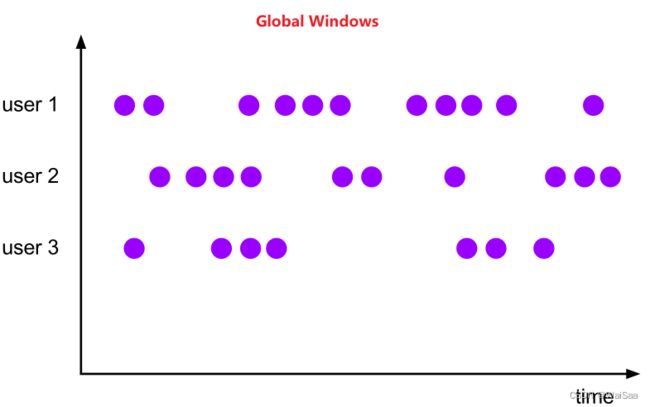
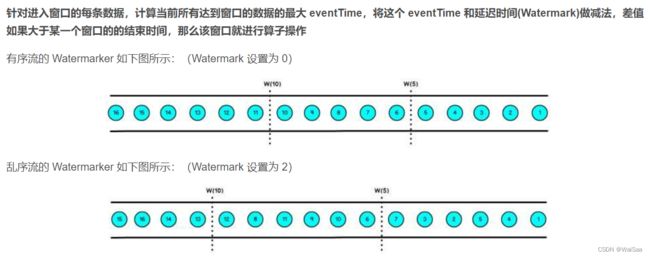

8、Flink 部署模式
Flink支持多种安装模式:
- Local—本地单机模式,学习测试时使用;
- Standalone—独立集群模式,Flink自带集群,开发测试环境使用;
- StandaloneHA—独立集群高可用模式,Flink自带集群,开发测试环境使用;

9、Flink 1.14 新特性
-
流批一体

-
Checkpoint 机制优化


-
资源管理性能优化
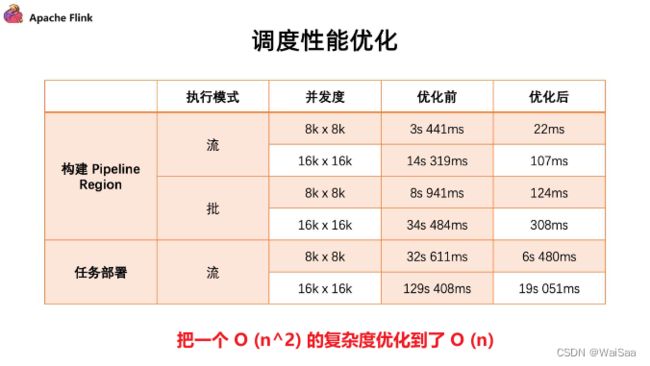

- Table / SQL / Python API性能优化
10、Flink-CDC
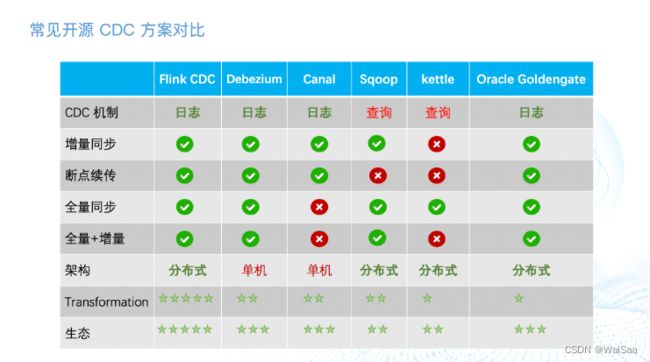
* 【mysql配置】
* 1.开启 binlog
* server_id=1
* log_bin=mysql-bin
* binlog_format=ROW
* expire_logs_days=1
* 2.赋权
* SELECT 允许从表中查看数据
* REPLICATION SLAVE 允许执行show master status,show slave status,show binary logs命令
* REPLICATION CLIENT 允许slave主机通过此用户连接master以便建立主从复制关系
flink-cdc github地址:https://github.com/ververica/flink-cdc-connectors
flink-cdc 官方文档:https://ververica.github.io/flink-cdc-connectors/master/
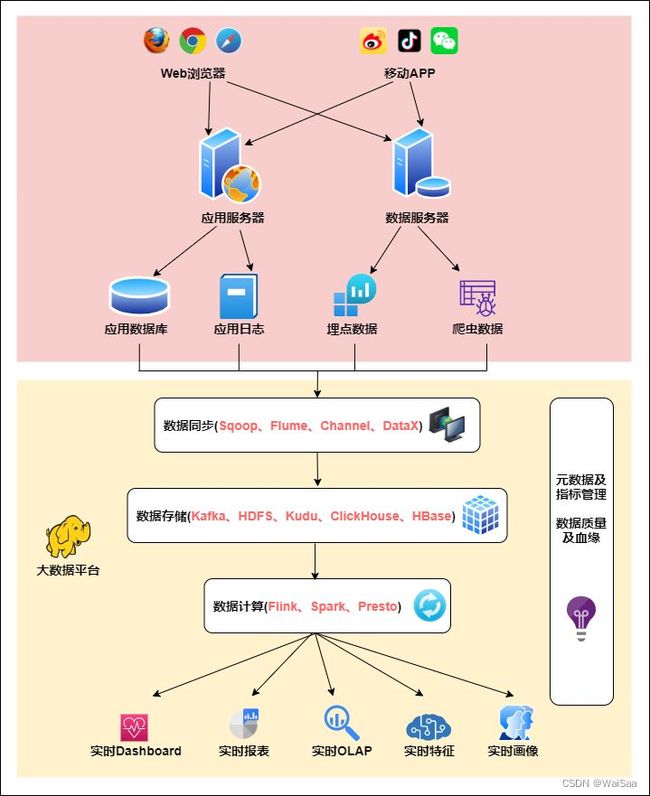
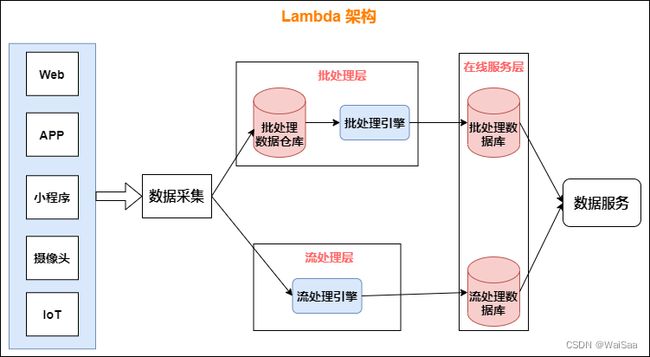
11、实时计算架构


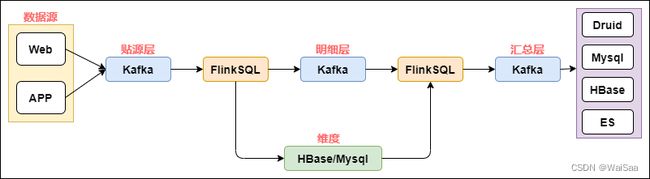
12、构建工具的进化

- make-1976年出现【销声匿迹】
- ant-2000年Apache独立项目【屈指可数】
- maven-2001年诞生,于2004年首次发布【日薄西山】
- gradle-2012年发布【如日中天】