flink入门基础知识整理(持续更新)
目录
1.入门概念
1.1 核心特点
1.1.1 批流数据
1.1.2 容错能力
1.1.3 高吞吐低延迟
1.1.4 大规模复杂计算
1.1.5 多平台部署
2.API 介绍
2.1 API层次
2.2 DataStream体系
2.3 数据读取(Source)
2.3.1 内存读取
2.3.2 文件读取
2.3.3 SOCKET接入
2.3.4 自定义读取
2.4 数据转换处理(Transformation)
2.5 数据输出(Sink)
3. 时间与窗口
3.1 时间概念
3.2 窗口概念
3.2.1 计数窗口
3.2.2 时间窗口
3.2.3会话窗口
1.入门概念
1.1 核心特点
按照老中少三代来区分大数据框架,老一代为 处理流式数据的storm,中一带为 处理批式数据的hadoop、spark(微批为流),少一代为 本文章描述的 flink,自从阿里接管 flink 的开源后,今天的 flink已经已经十分强大,兼有 批流一体、高容错、高吞吐低延迟、大规模计算、多平台部署等核心特点
1.1.1 批流数据
传统的大数据理解中,数据源源不断的产生,没有终止,同时也积累的许多。针对以上,源源不断的来的即为流式数据(无界数据),积累的一批为批式数据(有界数据)。批数据除了是已经产生的数据,还可以由流式数据作一定规则的细分截取产生。具体的的应用 应视情况而定,可以针对流式数据作聚合操作,也可以等攒齐了 一次性操作。Flink同时支持对流式数据操作和批示数据操作,且强于以上框架。
1.1.2 容错能力
Flink容错能力主要有三种:依赖于集群管理、依赖于协调组件、依赖于自身快照机制
一:集群管理
Flink支持多平台部署,其中k8s之类的容器集群管理平台本身自带当进程挂掉时,重启新进程接管工作的功能。
二:协调组件
Flink可通过相应配置开启HA模式,依赖于Zookeeper的分布式协调服务。
三:快照机制
Flink通过设计检查点和状态存储,来保证重启后可接着上次断点后继续工作。
1.1.3 高吞吐低延迟
Flink除了在计算、传输、序列化做了优化外,得益于本身的快照机制,不依赖会产生阻塞的调度,从而可以持续处理数据
1.1.4 大规模复杂计算
计算方面也得益于 flink本身的容错机制和状态存储设置,可以使 flink已聚合的方式逐批处理数据,并聚合保存之前和现有的状态 于本地内存中(数据是否共享有待研究,个人觉得是共享的 ),如此一来可以极大的降低大数据的调度】管理等
1.1.5 多平台部署
和其他常见组件或应用一样,flink支持 容器化部署、云部署等
2.API 介绍
2.1 API层次
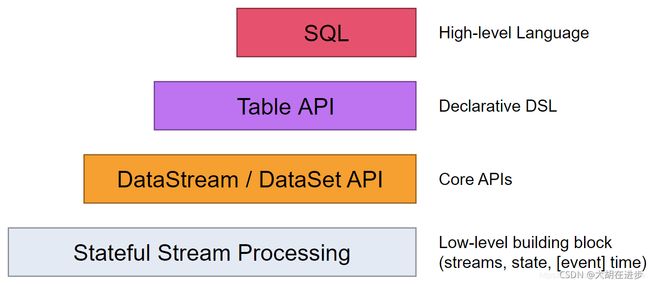
- 最下层,为有状态流式编程,它提供了ProcessFunctionAPI。flink在这个底层api上帮我们实现了最基础的流式处理能力,我们可以在上门进行有状态编程,并且我们可以自定义定时器,可以实现复杂的时间语义处理。
- core api层,flink提供了DataStreamAPI和DataSetAPI(逐步被舍弃)。这两个API提供了数据处理的基本操作:各种数据转化,分组,开窗,状态编程等等。
- Table API是基于表的声明式dsl。它与DataStream区别主要在以下几个方面:遵循关系型数据模型,自带schema,提供了类sql操作,如select,project,join,group-by等等。
- flink提供的最高层api是flink-sql。它的抽象层次与Table API类似,但是允许用户直接写sql便可以执行job。
这四层关系很好理解,上层是下层的通用性封装,若不满足个性化需求场景,可自己根据下层api自定义开发,但最低为状态流的处理。
2.2 DataStream体系
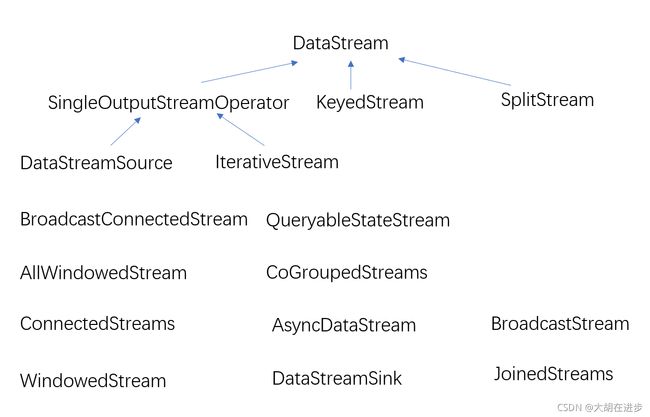
- DataStream: 其为 Flink 数据流的 核心抽象,其上定义了对数据流的 一系列操作,同时也定义了与其他类型DataStream的相互转化关系。每个DataStream都有一个transformation对象,表示该DataStream 从上游的 DataStream 使用该 Transformation而来。
- SingleOutputStreamOperator:旁路输出,主要用来看过程信息
- KeyedStream:其用来表示根据指定的key(针对某个值)进行分组的数据流。
- SplitStream:其用来将流根据标记(针对,讴歌属性)划分成多个流,再通过select()获取指定(值)的流
- DataStreamSource:其为DataStream的起点,由环境对象的 StreamExcutionEnvironment.addSource(SourceFunction)创建而来,其中的 SourceFunction定义了从数据源获取数据的具体逻辑
- IterativeStream:迭代流,Flink的Datastream正常情况下是不会结束的,所以也没有所谓的最大迭代次数。这种情况下,你需要自己指定哪个类型的数据需要回流去继续迭代,哪个类型的数据继续向下传输,这个分流的方式有两种:split和filter。
- BroadcastConnectedStream && BroadcastStream: BroadcastStreams实际上是对一个普通的DataStream的封装,提供里广播行为;BroadcastConnectedStream则是BroadcastStreams与DataStream链接而来。
- QueryableStateStream:类似于一个接收器,无法进行进一步转换, 接收传入的数据(内部或者外部)并更新状态
- AllWindowedStream&&WindowedStream: WindowedStream代表了根据key分组且基于WindowAssigner切分窗口的数据流。所以Windowed都是KeyedStream衍生而来,在WindowedStream进行的任何转化也都将转会变为DataStream
- JoinedStreams&& CoGroupedStreams:join是COGroup的一种特例,JoinedStreams底层使用的COGroupStreams来实现。CoGroup侧重于Group, 对数据进行分组,是对同一个key上的两组集合进行操作,而join侧重的是数据对,对同一个key上的每一对元素进行操作。CoGroup更通用,单join比较常见。
- ConnectedStreams:其表示两个数据流的组合,数据流类型可以不一样。整合后的数据流共享 state。一种典型的场景就是两个流中一种是业务流,一种是规则流,业务流根据规则流来对数据进行处理。
- AsyncDataStream:是一个工具,提供在DataStream上使用异步函数的能力
- DataStreamSink:由 DataStream。addSink(SinkFunction)创建而来,其中SinkFunction定义了写出数据到外部存储的具体逻辑。
2.3 数据读取(Source)
这是flink流计算的起点, 第一个DataStream由此产生,主要有四种方式:内存读取、文件读取、socket读取、自定义
2.3.1 内存读取
主要是从 各种本地的数据结构中读取数据方法一般为 from开头,如 fromElements()、formCollection()、等
2.3.2 文件读取
主要是从本地文件读取, 除了自定义IO流之外,flink也封装了一系列的方法, 主要是以read 开头的方法 如readTextFlie()、readFile()等。读取模式分为一次性读取或持续读取两种吗,一般默认一次性读取。
2.3.3 SOCKET接入
主要从网络端口获取,一般方法以 socket开头。常用的 自测方法可以 以 在服务器开启 nc 服务指定端口,然后输入数据就可以创建一个简单的队列生产端 和 服务端, 本地监听端口,为消费端,源源不断的获取数据
2.3.4 自定义读取
可以使用flink连接器,自定义数据读取函数,与外部存储系统交互,包括但不限于 kafka、jdbc等,一般方法以 add 或者 create开头。
2.4 数据转换处理(Transformation)
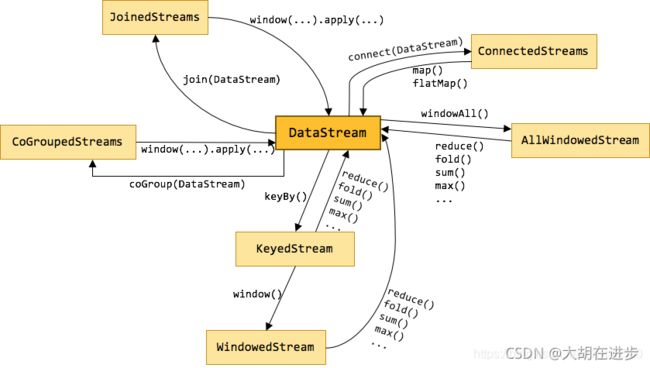
由图中看出,并不是所有的 DataSTream都可以相互转换。里面转换算子网上有更详细的教程,后面的demo 会有所涉及,此处不做详解。
2.5 数据输出(Sink)
数据读取的API 是在 环境对象上,但是数据输出的API绑定在 DataStream。最新版本只支持输出到控制台、socket、自定义 三大类,文件相关的一致标记为废弃,但是可以使用或在自定义中实现。自定义输出的 接口为 DataStream.addSink().
除正常输出外,还有一些过程监控、特殊捕获的旁路输出,主要使用 SingleOutputStreamOperator,且只能在特定的函数中使用。
3. 时间与窗口
3.1 时间概念
时间是 流式数据中 用来区分数据的一个维度,流式数据一般是无穷尽的,有的应用是来一条数据就处理一条数据, 有的则是通过时间雷积累一批或者通过数量来积累一批 再处理。一般 时间也是数据的一个属性,主要有以下三种类型:
- 事件时间:
指事件发生的时间,唯一确定时间,且可用来还原时间发生顺序
- 摄取时间:
指时间流入流处理系统时间,即数据被系统读取的时间,理论上应该与时间事件相近且顺序一致,但因为分布式等原因,可能会乱序
- 处理时间:
指数据被计算引擎处理的时间,以各个计算节点的本地时间为准,其会随着各个节点的传递而不断变化
3.2 窗口概念
在技术窗口和 时间窗口中都分为滚动窗口和滑动窗口,这里可以做一个比喻来形象的描述一下同类型窗口中相邻窗口之间的关系。
滚动窗口: 第一个窗口相当于放一个扑克牌于桌上,第二个窗口就是 让扑克牌沿着右边翻滚一下,或者说是向右平移一个扑克牌宽度的位置,第三个窗口则是进行相同的操作。
滑动窗口:滑动窗口有两个概念:窗口大小和滑动步长。跟上面类似,第一个窗口相当于一张扑克牌放于桌上,第二个窗口就是第一个窗口向右平移步长大小是位置(所以窗口会重叠),步长可以是计数窗口的数量或者时间窗口的时长。
3.2.1 计数窗口
3.2.1.1滚动计数窗口
累计固定个数(窗口个数大小)的元素视为一个窗口,该类型的窗口无法像时间窗口那样事先切割分好,因为数据不是随着时间均匀的流入的
3.2.1.2滑动计数窗口
累计固定个数(窗口个数大小)的元素视为一个窗口,每超过一定个数的原则个数(滑动步长,滑动个数大小),则产生一个新窗口
3.2.2 时间窗口
3.2.2.1滚动时间窗口
表示在时间上按照事先约定的窗口大小(窗口时间大小)切分的窗口,窗口之间不会重合,窗口里面的 数据数量不一定一致,因为数据流入不是匀称的
3.2.2.2滑动时间窗口
表示在时间上按照事先约定的窗口大小(窗口时间大小)、滑动步长(滑动时间大小)切分的窗口,滑动窗口之间可能会存在相互重叠的情况(根据窗口大小和步长而定)
3.2.3 会话窗口
其为一种 特殊的窗口,当超过一段时间,该窗口没有数据,则自动关闭,也可以是超过一段时间,该窗口有了数据,也可以自动关闭,一种动态变化产生的窗口。同一种规则定义下而定窗口也不会重叠。