【论文解读】UC-NeRF: Neural Radiance Field for Under-Calibrated multi-view cameras in autonomous driving
UC-NeRF:欠校准的多视角摄像头系统的新颖视图合成方法
论文:https://arxiv.org/abs/2311.16945
代码:GitHub - kcheng1021/UC-NeRF: the official pytorch implementation of UC-NeRF

图 2:在欠校准的多摄像头系统中,NeRF的质量显著下降(第一行),伴随着颜色不一致(红色框),物体幻影(红色箭头)和错误的几何形状(第二行)。我们的UC-NeRF在具有挑战性的情况下实现了高质量的渲染和准确的几何形状。
1 摘要
本文主要解决NeRF应用于多摄像头系统的场景。
例如自动驾驶,因为它们极大地扩展了感知能力。尽管神经辐射场(NeRF)技术迅速发展并在室内外场景中得到广泛应用,但将NeRF应用于多摄像头系统仍然非常具有挑战性。
这主要是由于多摄像头设置中固有的欠校准问题,包括来自不同摄像头中分别校准的图像信号处理单元导致的不一致的成像效果,以及由行驶过程中的机械振动引起的系统错误,影响相对摄像头姿态。

在本文中,我们提出了UC-NeRF,这是一种专为欠校准的多视角摄像头系统的新颖视图合成方法。
首先,我们提出了一种基于层次的颜色校正,以纠正不同图像区域的颜色不一致性。
其次,我们提出了虚拟变形,以生成更具视点多样性但颜色一致的虚拟视图,用于颜色校正和3D恢复。
最后,我们设计了一种时空约束的姿态细化方法,以实现对多摄像头系统进行更强大和精确的姿态校准。
UC_NeRF 不仅在多摄像头设置中实现了最先进的新颖视图合成性能,而且还通过合成的新颖视图有效地促进了大规模室外场景的深度估计。
2 UC-NeRF框架概览
 图3:UC-NeRF框架概览。为了减轻多摄像头系统中颜色监督的不一致性,时空约束的姿态细化模块对姿态进行优化,而基于层次的颜色校正模块则对来自不同相机和时间戳的图像进行建模,以解决图像依赖的外观差异。虚拟变形模块生成具有几何和颜色一致性的多样虚拟视图,为颜色校正和3D场景恢复提供丰富的数据。
图3:UC-NeRF框架概览。为了减轻多摄像头系统中颜色监督的不一致性,时空约束的姿态细化模块对姿态进行优化,而基于层次的颜色校正模块则对来自不同相机和时间戳的图像进行建模,以解决图像依赖的外观差异。虚拟变形模块生成具有几何和颜色一致性的多样虚拟视图,为颜色校正和3D场景恢复提供丰富的数据。
3 基于图层的颜色校正(Layer-Based Color Correction)
在多摄像头系统中,不同的摄像头通常具有不同的图像信号处理器(ISP)配置,导致相同的3D区域的成像颜色不一致。因此,使用这些不一致的图像优化NeRF表示始终会导致低质量的渲染。
《Urban-NeRF》(Rematas等人,2022年)尝试为每个视图近似一个全局线性补偿变换,以减轻来自不同摄像头的视图之间的差异。值得注意的是,由于ISP过程的非线性特性,单个图像中具有不同强度的像素甚至具有各种ISP成像效果,因此使用单一的全局补偿变换来建模这些空间变化的颜色模式是不足够的。
为了在质量和效率之间取得平衡,我们提出将场景分为前景-天空层,并为每个层单独建模颜色补偿变换。这是因为天空区域通常比前景对象亮得多,并且它们呈现出不同的ISP成像效果。
我们首先将前景和天空分别建模为两个独立的NeRF模型 和 θ_sky。从光线 r 渲染的像素的颜色通过前景颜色 ![]() 和天空颜色
和天空颜色![]() 的加权组合获得,如下方程式所示:
的加权组合获得,如下方程式所示:
![]()
其中:
 是渲染的像素的颜色。
是渲染的像素的颜色。 是前景颜色。
是前景颜色。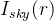 是天空颜色。
是天空颜色。 是前景的不透明度(权重),即前景颜色在混合中的权重。
是前景的不透明度(权重),即前景颜色在混合中的权重。


4 时空约束的位姿定义 (Spatiotemporally Constrained Pose Refinement )
NeRF的渲染质量在很大程度上依赖于相机姿势的准确性。先前的方法(Tancik等人,2022年;Xie等人,2023年)独立建模相机姿势并在NeRF框架内联合优化它们。它们未充分利用多摄像头系统中相机之间的空间相关性,导致了不受约束的姿势优化。此外,相机姿势优化取决于光度一致性假设,在多摄像头系统中拍摄的长时间视频通常违反该假设。鉴于相机在整个过程中与主要捕获设备(即驾驶汽车)保持固定的空间关系的条件,我们明确建立了相机之间的时间固定几何变换。

在使用K台相机捕获多视图图像时,第i时刻第k台相机的姿势 ![]() 被表示为汽车的自我姿态
被表示为汽车的自我姿态  与相对变换
与相对变换![]() 的组合,其在时间上是一致且可优化的,如图5所示。明确建模相机之间的空间关系为姿势细化提供了更多的限制,因此有效增强了对所有帧上不正确的点匹配的鲁棒性。在建立相机姿势之间的时空约束后,建立了不同相机在不同时间捕获的图像之间的点对应关系作为相关图 E。然后,我们使用捆绑调整来最小化重投影误差,定义如下:
的组合,其在时间上是一致且可优化的,如图5所示。明确建模相机之间的空间关系为姿势细化提供了更多的限制,因此有效增强了对所有帧上不正确的点匹配的鲁棒性。在建立相机姿势之间的时空约束后,建立了不同相机在不同时间捕获的图像之间的点对应关系作为相关图 E。然后,我们使用捆绑调整来最小化重投影误差,定义如下:
![]() (7)
(7)

5 虚拟变形图像 (Virtual Warping )

虚拟变形图像的生成。对于每个已知的视点,我们使用多视图立体匹配(MVS)生成其深度图,并通过几何一致性检查筛选出不准确的深度。通过将来自已知视点的图像从实际视点变形到虚拟视点,得到每个虚拟视图。
在多摄像头系统中,来自不同视点的图像往往具有有限的重叠区域,相对于单个摄像头的帧来说,对齐它们的颜色更具挑战性。为了对齐多个摄像头的图像颜色,并防止颜色校正的优化潜在代码过度拟合到特定视点,我们提出了虚拟变形,它在训练时模拟了一组虚拟视点下更多样但颜色一致的图像。此外,虚拟变形自然地扩展了供NeRF使用的视角范围,从而增强了其重建3D场景的能力。图4显示了我们虚拟变形策略的流程。我们使用MVS方法(Ma等人,2022年)生成所有视图的深度图。为了消除离群值并保持多个视图之间一致的深度,我们进一步利用几何一致性检查过程(Schönberger等人,2016年)生成一个掩码M,该掩码仅在每个视图中保留可靠的深度值。
有了估计的深度,我们生成多个虚拟姿势,并将颜色和颜色校正代码扭曲到虚拟位置。具体而言,我们使用附加变换 ![]() 对现有姿势
对现有姿势![]() 进行扰动,形成一个虚拟姿势
进行扰动,形成一个虚拟姿势 ![]() 。旋转
。旋转 ![]() 是通过随机选择三个轴中的一个,并加上一个随机角度 ∈ [−20°, 20°] 生成的。平移
是通过随机选择三个轴中的一个,并加上一个随机角度 ∈ [−20°, 20°] 生成的。平移 ![]() 是一个具有长度 ∈ [0m, 1m] 的随机方向的三维向量。在摄像机姿势
是一个具有长度 ∈ [0m, 1m] 的随机方向的三维向量。在摄像机姿势![]() 下,现有图像中的每个像素
下,现有图像中的每个像素 ![]() 被扭曲到一个图像点
被扭曲到一个图像点![]() ,计算公式如下:
,计算公式如下:
![]()
其中![]() 是
是![]() 和
和 ![]() 的齐次坐标,K 是摄像机内部矩阵,
的齐次坐标,K 是摄像机内部矩阵, 和
和 ![]() 是虚拟视图中的像素深度和原始实际视图中相应像素的深度。考虑到对象遮挡,原始视图中可能有多个像素映射到虚拟视图中的相同位置,因此我们保留了深度最小的像素。
是虚拟视图中的像素深度和原始实际视图中相应像素的深度。考虑到对象遮挡,原始视图中可能有多个像素映射到虚拟视图中的相同位置,因此我们保留了深度最小的像素。
在扭曲后,几何一致性掩码 M 被应用于扭曲的像素,以过滤具有嘈杂深度的像素。然后,将原始视图中像素的颜色和颜色校正代码分配给虚拟视图中相应的扭曲像素。这为恢复场景的一致外观和几何提供了更多线索。
6 训练策略
我们的训练策略主要包括两个部分:
1)姿势细化和深度估计。我们从传感器融合SLAM初始化姿势,并使用我们提出的时空约束姿势细化模块进一步优化它们,如方程7所述。通过这些细化的姿势,我们为每个图像生成深度图和几何一致性掩码,遵循第3节中概述的过程。
2)端到端的NeRF优化。具体来说,我们在NeRF的优化中使用了提出的基于层次的颜色校正和虚拟变形,以实现高质量的渲染。在每个训练批次中,我们随机采样了B张真实图像,并使用我们的虚拟变形模块为每个真实图像创建了V个虚拟视图。从这些真实和虚拟视图中随机采样像素,作为NeRF训练的地面真实值。我们的UCNeRF根据方程4渲染这些像素,并由方程8中的损失函数进行监督:

其中,λ 和 γ 是 ![]() 和
和![]() 的权重。
的权重。

图 6:我们以5760 × 1280的分辨率渲染全景图以进行比较。值得注意的增强部分用蓝色和红色框标出,并显示裁剪的补丁以强调特定细节。与其他方法相比,我们的结果呈现出一致的颜色和清晰的细节,甚至可信地恢复了标语。