测试--性能测试LoadRunner
目录
- 前言
- 一丶性能测试
-
- 1.性能问题和性能测试重要性
- 2.具体的实施流程
-
- <1>如何分析性能需求
-
- 1. 关 键 性 能 分 析 − − 性 能 指 标 \color{red}{1.关键性能分析--性能指标} 1.关键性能分析−−性能指标
- 2. 关 键 业 务 分 析 − − 业 务 功 能 \color{red}{2.关键业务分析--业务功能} 2.关键业务分析−−业务功能
- <2>关于性能指标
-
- 1. 并 发 用 户 数 − − 广 义 丶 狭 义 丶 系 统 丶 在 线 \color{red}{1.并发用户数--广义丶狭义丶系统丶在线} 1.并发用户数−−广义丶狭义丶系统丶在线
- 2. 响 应 丶 平 均 响 应 丶 事 务 响 应 时 间 和 每 秒 通 过 事 务 数 \color{red}{2.响应丶平均响应丶事务响应时间和每秒通过事务数} 2.响应丶平均响应丶事务响应时间和每秒通过事务数
- 3. 点 击 率 丶 吞 吐 量 丶 思 考 时 间 丶 资 源 利 用 率 \color{red}{3.点击率丶吞吐量丶思考时间丶资源利用率} 3.点击率丶吞吐量丶思考时间丶资源利用率
- <3>关于性能测试的模型
-
- 1. 曲 线 拐 点 模 型 \color{red}{1.曲线拐点模型} 1.曲线拐点模型
- 2. 地 铁 模 型 \color{red}{2.地铁模型} 2.地铁模型
- 3.关于性能测试的分类
-
- <1>代码级别的性能测试
- <2>基准性能测试
- <3>并发测试
- <4>压力测试
- <5>配置测试
- <6>可靠性测试
- <7>失效恢复测试
- 二丶开发测试脚本
-
- <1>关于LoadRunner的基本概念
- <2> 开发测试脚本
-
- 1.插入函数
-
- 控制脚本流程
- 字符串函数
- 输出函数
- LoadRunner 提供的标准函数
- 2.插入检查点
- 3.关联和参数化输入
-
- user先添加
- 方式一:File Path
- 方式二:Add Row
- 方式三:Edit with Notepad
- 更改用户数
- 关于字符串函数的应用
- 4.关于Parameter Properties一些小问题
- 三丶controller执行性能测试场景
-
- <1>选择测试脚本
- <2>选择测试路径
- <3>选择服务器
- <4>增加用户和增加组数
- <5>选择初始化用户数
- <4>每秒启动用户数
- <5>设置运行时间
- <6>退出设置
- 四丶数据分析
前言
这一部分是关于性能测试工具LoadRunner的使用,LoadRunner是一款桌面应用软件,可用来模拟用户完成性能测试工作。
一丶性能测试
1.性能问题和性能测试重要性
为什么要进行性能测试呢?我们用一个使用场景来进行说明,在所有的设备运转正常的证明我们业务的处理没有问题,那么业务处理没有问题就代表我们的业务可以正常使用嘛?再次确切一些,就是业务正常处理是正常处理,但是如果说业务响应时间及其的长,这个时候我们是不是就是业务就算可以正常处理了我们的业务也不可以投入使用。那么我们常见的性能问题有哪些呢?
1.资源泄露,包括内存泄露
2.CPU使用率过高,系统被锁定等
3.线程死锁,阻塞等问题造成系统处理速度过慢
4.查询速度慢,效率低下
5.受外部的影响因素越来越大
综上所述,所以我们的性能测试重要性愈发明显,那具体体现在哪里呢?
1.获取系统性能的指标,作为性能指标的基准
2.验证系统的性能指标是否达到要求(性能需求)
<1>应用程序是否能够满足系统要求的各中性能指标
<2>应用程序是否能处理预期的用户负载并有盈余能力
<3>应用程序是否能处理业务所需要的事务数量
<4>在预期和非预期的用户负载下,应用程序是否稳定
<5>是否能确保用户在真正使用软件时获得舒服的体验
3.发现系统的性能瓶颈,内存泄露等问题
4.系统正常工作情况下的最大容量
5.帮助系统运维部门能更好的规划硬件配置
2.具体的实施流程
关于性能测试的具体实施流程主要如下:
分析性能测试需求
根据性能测试的目标,设计性能测试的场景
开发性能测试场景和性能测试脚本
分析性能测试报告
根据性能测试报告排查和定能系统的性能瓶颈
那么接下来根据以上的流程,我们在这里先讨论一些基础的知识
<1>如何分析性能需求
我们如何确定性能测试的需求呢?主要可以通过以下两个方面去确定系统性能测试的需求。
1. 关 键 性 能 分 析 − − 性 能 指 标 \color{red}{1.关键性能分析--性能指标} 1.关键性能分析−−性能指标
什么意思呢?在进行系统的性能测试之前,我们要知道系统的性能需求,不能过于简单或者过于模糊的描述性能需求,系统性能的需求必须通过具体数据进行量化,也就是人们常说的性能指标。性能指标一旦量化,就可以度量,才具备可测试性(可验证性),即能确认系统的性能指标是否符合设计的要求,是否符合客户的需求。一组清晰定义的预期性能指标值,是性能测试的基本要素。
这里有一个问题,就是说如果当前软件是全新的应用系统,那你怎么确定具体的性能指标呢?
<1>通过基准测试,获取性能指标
<2>从业务,用户体验,竞品的的性能指标信息来定义性能指标的数据
<3>从商业需求,它的性能至少不能比同类产品性能差
<4>从技术需求,要从技术角度去分析它的性能,比如CPU使用率不超过70%
<5>标准要求,行业规定了某些软件的性能指标,相关的软件必须要达到。
2. 关 键 业 务 分 析 − − 业 务 功 能 \color{red}{2.关键业务分析--业务功能} 2.关键业务分析−−业务功能
系统的运行出错往往就是某一个环节出了问题,性能测试也是一样的,基本如果某一业务上不出问题,那么整体基本也不会出什么问题,而这也就是系统性能测试的关键业务所在。
所以在性能测试中,首先就是要了解那些功能是用户经常使用的,举一个例子
拿淘宝来说,首页肯定是访问次数最多的,那登淘宝肯定就是为了买东西,所以搜索也很常用,这样来说“首页显示”“搜索”就是性能测试的关键业务功能。
那么关键业务功能仅仅依靠使用的次数来定义的话准确嘛?当然不准确,你还有考虑其他因素,因为你仔细想想,其实搜索用户那么多,其中可能只有一小部分用户才会进行下单购买。
还是淘宝,提交订单和支付功能相对于上面两个功能来说使用的频率较少,但是,因为它涉及到相关数据库的读写,和外部接口的使用(支付宝),所以这两个才是我们性能测试的关键业务。
综上,确定性能测试的关键业务,要从使用率和功能计算量,资源消耗程度等来决定,确定好关键业务之后,我们在进行性能测试的时候只要对关键业务进行测试用例的设计,系统的测试脚本就会基于这些关键的业务进行开发。
<2>关于性能指标
1. 并 发 用 户 数 − − 广 义 丶 狭 义 丶 系 统 丶 在 线 \color{red}{1.并发用户数--广义丶狭义丶系统丶在线} 1.并发用户数−−广义丶狭义丶系统丶在线
狭义用户数:指的是同一时刻,使用系统的同一个功能(发送请求)的用户数量。
广义用户数:指的是同一时刻,给服务器产生压力的用户数量,不在要求同一功能
系统用户数:注册该系统的用户数量
在线用户数:某一时刻登录系统的数量
狭义和广义的并发放用户数,都是基于在给服务器发送请求的基础上计算的。而系统用户数和在线用户数它们不一定都正在给服务器发送请求。
例如:系统用户数中有注册后不再使用的,就不给服务器发送请求了。在线用户数中,如果是用户在浏览其中的页面,没有点击什么按钮发送请求,就不算是在线用户数。
问:1000个系统用户,500个用户在线,100个用户已经打开网页在浏览,200个用户在进行查询操作,100个用户在进行提交操作,100个用户去吃饭洗衣服,那么请问,给服务器产生压力的用户数有多少?
广义用户数来看,有300个。包括在进行查询操作的200个用户,在进行提交操作的100个用户。
2. 响 应 丶 平 均 响 应 丶 事 务 响 应 时 间 和 每 秒 通 过 事 务 数 \color{red}{2.响应丶平均响应丶事务响应时间和每秒通过事务数} 2.响应丶平均响应丶事务响应时间和每秒通过事务数
响应时间(RT):用户发送请求到期待的结果出现所经历的时间。(loadRunner中帮我们算了)
响应时间=人的反应时间+网络传输时间(来回)+服务器的处理时间+数据库的响应时间
平均响应时间(ART):就是各个功能响应时间的平均值,用来衡量系统的其中一个指标
首先回答一下什么是事务?
事务是一个业务度量单位,是指一组密切相关的子操作的组合。比如,一笔电子支付操作,
后台处理的时候可能需要经过会员系统,账务系统,支付系统,银行系统等,这就是是一个关于支付事
务里面包含的操作。而对于用户,往往也只关注整个支付花费了多长时间。
什么是事务响应时间(Transaction Reponse Time)?
就是每秒完成的事务数,也可以说是每秒成功的事务数
每秒通过事务数(Transaction Per Second):TPS 是指每秒系统能够处理的事务数。它是衡量系统处理能力的重要指标。当压力加大时,TPS曲线如果变化缓慢或
者有平坦的趋势,很有可能是服务器开始出现瓶颈了。如果环境没有发生大的变化,对于同一系统会存在一个最大处理事务能力,它并不随着并发用户的增减而改变。
3. 点 击 率 丶 吞 吐 量 丶 思 考 时 间 丶 资 源 利 用 率 \color{red}{3.点击率丶吞吐量丶思考时间丶资源利用率} 3.点击率丶吞吐量丶思考时间丶资源利用率
点击率(Hit Per Second):每秒点击数代表用户每秒向Web服务器发送的HTTP
请求数,点击率越大,服务器压力越大,当然这里的点击可能是一次点击发送多
个HTTP请求
吞吐量(Throughput):这里的吞吐量以单位时间为度量衡量
单位时间内系统处理的客户请求的数量,直接体现软件系统的性能承载能力,一般来
说用Requests/second,Pages/Second,Bytes/Second,从业务的角度,也可以
用访问人数/天或是处理的业务数/小时来衡量,从网络设置的的角度来说,也可以
用字节数/天来衡量。
思考时间(Think Time):指模拟正式用户在实际操作时的停顿间隔时间,从业
务的角度来讲,思考时间指的是用户在进行操作时,每个请求之间的间隔时间。
资源利用率:不同系统资源的使用情况。包含CPU,内存,硬盘,网络等。
<3>关于性能测试的模型
这里我想要介绍两个测试模型
1. 曲 线 拐 点 模 型 \color{red}{1.曲线拐点模型} 1.曲线拐点模型
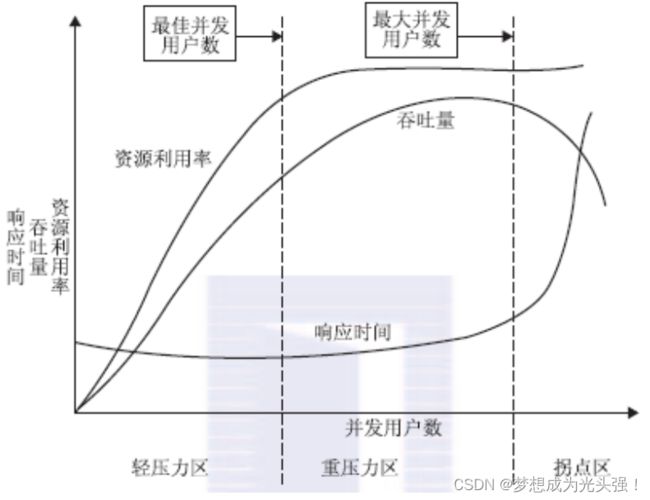
1)X轴代表并发用户数,Y轴代表资源利用率、吞吐量、响应时间。X轴与Y轴区域从左往右分别是轻压力区、重压力区、拐点区。
2)随着并发用户数的增加,在轻压力区的响应时间变化不大,比较平缓,进入重压力区后呈现增长的趋势,最后进入拐点区后倾斜率增大,响应时间急剧增加。
3)接着看吞吐量,随着并发用户数的增加,吞吐量增加,进入重压力区后逐步平稳,到达拐点区后急剧下降,说明系统已经达到了处理极限,有点要扛不住的感觉。
4)同理,随着并发用户数的增加,资源利用率逐步上升,最后达到饱和状态。
5)最后,把所有指标融合到一起来分析,随着并发用户数的增加,吞吐量与资源利用率增加,说明系统在积极处理,所以响应时间增加得并不明显,处于比较好的状态。但随着并发用户数的持续增加,压力也在持续加大,吞吐量与资源利用率都达到了饱和,随后吞吐量急剧下降,造成响应时间急剧增长。轻压力区与重压力区的交界点是系统的最佳并发用户数,因为各种资源都利用充分,响应也很快;而重压力区与拐点区的交界点就是系统的最大并发用户数,因为超过这个点,系统性能将会急剧下降甚至崩溃。
2. 地 铁 模 型 \color{red}{2.地铁模型} 2.地铁模型
假设:
某地铁站进站只有3个刷卡机。
人少的情况下,每位乘客很快就可以刷卡进站,假设进站需要1s。
乘客耐心有限,如果等待超过30min,就暴躁、唠叨,甚至放弃。
场景一:只有1名乘客进站时,这名乘客可以在1s的时间内完成进站,且只利用了一台刷卡机,剩余2台等待着。
场景二:只有2名乘客进站时,2名乘客仍都可以在1s的时间内完成进站,且利用了2台刷卡机,剩余1台等待着。
场景三:只有3名乘客进站时,3名乘客还能在1s的时间内完成进站,且利用了3台刷卡机,资源得到充分利用。
场景四:A、B、C三名乘客进站,同时D、E、F乘客也要进站,因为A、B、C先到,所以D、E、F乘客需要排队。
那么,A、B、C乘客进站时间为1s,而D、E、F乘客必须等待1s,所以他们3位在进站的时间是2s。
场景五:假设这次进站一次来了9名乘客,有3名的“响应时间”为1s,有3名的“响应时间”为2s(等待1s+进站1s),还有3名的“响应时间”为3s(等待2s+进站1s)。
场景六:如果地铁正好在火车站,每名乘客都拿着大小不同的包,包太大导致卡在刷卡机堵塞,每名乘客的进站时间就会又不一样。刷卡机有加宽的和正常宽度的两种类型,那么拿大包的乘客可以通过加宽的刷卡机快速进站(增加带宽)。
场景七:进站的乘客越来越多,3台刷卡机已经无法满足需求,为了减少人流的积压,需要再多开几个刷卡机,增加进站的人流与速度(提升TPS、增大连接数)。
场景八:终于到了上班高峰时间了,乘客数量上升太快,现有的进站措施已经无法满足,越来越多的人开始抱怨、拥挤,情况越来越糟。单单增加刷卡机已经不行了,此时的乘客就相当于“请求”,乘客不是在地铁进站排队,就是在站台排队等车,已经造成严重的“堵塞”,那么增加发车频率(加快应用服务器、数据库的处理速度)、增加车厢数量(增加内存、增大吞吐量)、增加线路(增加服务的线程)、限流、分流等多种措施便应需而生。
3.关于性能测试的分类
这一部分就是我最后要介绍的部分了,关于性能测试的分类,也就是你要对那些方面进行测试。
<1>代码级别的性能测试
代码级别的性能测试是指在单元测试阶段就对代码的时间性能和空间性能进行必要的测试和评估,以防止代码底层逻辑的效率问题在后期才发现的尴尬。
<2>基准性能测试
系统的第一个版本,研发团队团队也不清楚系统的性能能达到怎样的水平,这时进行的性能测试,其目标是获得系统标准配置下,有关的性能指标数据,作为将来性能改善的基准,这种测试称之为“性能基准测试。性能基准测试是通过性能测试获取系统的性能指标,建立一个性能基准,为以后性能测试的参考。系统进行性能基准测试可以在系统开发的较早的阶段发现性能问题。
<3>并发测试
并发测试,指的是在同一时间内,同时调用后端服务,期间观察被调用服务在并发情况下的行为表现,目的是为了发现如资源竞争,死锁等问题。
这里的并发测试指的是严格的并发测试,也就是所有用户在同一时刻向后端服务器发送请求。
<4>压力测试
压力测试,通常指的是后端压力测试,一般采用后端性能测试的方法,不断对系统施加压力,验证系统长期处于临界饱和阶段的稳定性以及性能指标的变化。试图找到系统处于临界状态时的主要瓶颈点。在不断地加压过程中,一旦系统出现拐点(从量变到质变),系统可能就会出现崩溃,揭露高负载下系统的问题,例如资源竞争、同步问题、内存泄漏等;然后逐渐较少压力,观察瘫痪的系统是否可以自愈。
<5>配置测试
系统性能的好坏,不仅仅取决于软件自身的设计和实现,也取决于软件运行所依赖的硬件,网络环境。为了达到系统性能指标要求,就需要调整系统的硬件配置,如增加服务器或者服务器集群来达到更高的性能。这时,会在不同配置的情况下,来测定系统的性能指标,从而决定在系统部署时采用什么样的软,硬件配置。
<6>可靠性测试
验证系统在常规负载模式下长期运行的稳定性。
在一定的软硬件环境下,长时间运行一定的负载,确定系统在满足性能指标的前提下是否运行稳定。与压力测试不同的是系统的负载并不是处于极限的状态下。重点是满足性能要求的情况下,系统的稳定性,比如响应时间,TPS是否稳定。
<7>失效恢复测试
一个一个公司中的服务器不可能是一个,是很多个一起运行的。此时就要人为的破坏其中的一个服务器,看看其它服务器的性能指标的变化是否正常。该方法就是在测试中模拟设备故障,验证预期的恢复技术是否可以正常发挥作用。
但不是所有的系统都需要进行这种类型的测试,尤其是并没有明确给出系统需要持续运行指标的系统。
二丶开发测试脚本
<1>关于LoadRunner的基本概念
功能:LoadRunner是一种适用于许多软件体系架构的自动负载测试工具,从用户关注的响应时间、吞吐量,并发用户和性能计数器等方面来衡量系统的性能表现,辅助用户进行系统性能的优化。
原理:LR启动以后,在任务栏会有一个Agent进程,通过Agent进程,监视各种协议的Client与Server端的通讯,用LR的一套C语言函数来录制脚本,所以只要LR支持的协议,就不会存在录制不到的,然后LR调用这些脚本向服务器端发出请求,接受服务器的响应。至于服务器内部如何处理,它不关心。LoadRunner通过以模拟上千万用户实施并发负载及实时性能监测的方式来确认和查找问题,优化性能和加速应用系统的发布周期。
组成:LoadRunner主要包括三个前台功能组件,分别为VuGen(虚拟用户脚本生成器)、Controller(测试控制器)和Analysis(结果分析器)。系统会自动调用后台功能组件LG(负载生成器)和Proxy(用户代理)来完成性能测试工作。
VuGen 是录制与便携脚本的地方。通过录制或编写脚本来模拟用户的行为。
Controller是执行负载测试管理和监控的中心。在这里指定具体的性能测试方案,执行性能测试,收集测试数据,监控测试指标。监控工具将测试过程中收集到的客户机、服务器和网络性能指标数据显示在监控页面上,便于测试人员对系统表现进行随时掌握。
LG是模拟多用户并发访问被测试系统的组件。模拟多用户访问系统的前提是已经具备了虚拟用户脚本,VuGen是录制和编辑虚拟用户脚本的工具,录制好的脚本是不同语言表达的文本文件,在LG执行时被解析和执行。脚
本录制和回放过程是在Proxy支持下完成的。
Analysis在测试完成后,对测试过程中收集到的各种性能数据进行计算、汇总和处理,生成各种图表和报告,为系统性能测试结果分析提供支持。
首先在具体的使用之前,先了解一下几个概念
Scenario:场景。所谓场景,是指在每一个测试过程中发生的事件。
Vusers:虚拟用户。LoadRunner使用多线程或多进程来模拟用户对应用程序操作时产生的压力。一个场景可能包括多个虚拟用户,甚至成千上万个虚拟用户。
Vuser Script:脚本。用脚本来描述Vuser在场景中执行的动作。
Transactions:事务。事务代表了用户的某个业务过程,需要衡量这些业务过程的性能。
rendezvous :集合。当我们测试多个用户并发时,每个用户执行到该事务脚本的先后顺序是不确定的,所以得到的测试结果也并不是一个完全 并发的极限测试结果。在开始事务之前 ,插入一个“集合点”,那么在多用户执行时,就可以将用户请求停下来,直到用户数量达到满足的条件(默认是100%的用户都到达集合点)。那么,所有的用户都将同时发出接下来的请求。
所以一般情况下我们的性能测试流程如下

开发测试脚本
LoadRunner 使用虚拟用户的活动来模拟真实用户来操作Web 应用程序,而虚拟用户的活动就包含在
测试脚本中,所以说测试脚本对于测试来说是非常重要的。开发测试脚本要使用 VuGen 组件。测试脚本要完成的内容有:
每一个虚拟用户的活动
参数化
定义事物
定义检查点
设计运行场景
运行场景描述在测试活动中发生的各种事件。一个运行场景包括一个运行虚拟用户活动的Load
Generator 机器列表,一个测试脚本的列表以及大量的虚拟用户和虚拟用户组。
运行、监视测试
一切配置妥当,开始运行测试。在运行过程中,需要监视各个服务器的运行情况(DataBase Server、
Web Server 等)。
分析测试结果
所有前面的准备都是为了这一步。我们需要分析大量的图表,生成各种不同的报告,最后会得出结论。
LoadRunner用3个主要功能模块来覆盖性能测试的基本流程。
Virtual User Generator
Controller
Analysis
接下来我们针对其操作一一进行讲解。
<2> 开发测试脚本
首先就是要打开在WebTours文件夹下的StartServer.bat的批处理文件,点击他以后启动VUGen才有效。
打开了VUGen以后,先创建一个Script:

这里上面是我们要使用的协议,这里我们选择为HTTP/HTML,点击创建后进入主窗体。
在解决方案资源管理器中可以看到该脚本的组成部分。简单说明一下:VuGen 中的脚本分为三部分:vuser_init、vuser_end 和Action。vuser_init用于用户初始化,vuser_end用于用户清理工作。Action用于具体的需要测试的操作。类似于unittest等测试框架。
这里我们暂时先只针对于Action进行操作,在Action页面点击录制按钮

然后会跳出来一个弹窗

Application中是选择录制的浏览器。如果是第一次录制,URL address中是空白的,加上http://127.0.0.1:1080/WebTours/。
然后点击Start Recording之后就会开始录制我们的脚本。
首先它会打开一个网页,然后让我们输入同户名和密码

那么用户名和密码你怎么知道是多少呢?那就要去看我们对应的储存了

去查看你LoaRunner下的users中存储的对应文件,如果说你想要新增用户,那么复制粘贴源文件之后进行修改即可。
在登录之前,可以先设置一个集合,确保用户数是在同一时刻登录的。然后再开启一个事务,再进行登录。
设置集合和开启事务的方法如下图:左边的图标为开启事务,右边的图标为开启集合。

登录成功之后,就可以发现我们的页面上显示

注意这个显示内容,我们之后要用到,登录好之后,终止事务再停止录制,最后关闭浏览器。此时返回Action页面就可以发现生成了我们的测试代码,然后点击Replay按钮开启验证

当然这个页面你是看不到的,如果想看到,你可以去进行设置

但是这个没啥意义,因为页面显示很快,你不一定能看到,相反它还浪费你的资源。
1.插入函数
VuGen 中可以使用C 语言中比较标准的函数和数据类型,语法和C 语言相同。下面简单介绍一下比较常
用的函数和数据类型。
在脚本页面,通过右键-插入-新建步骤可以查看函数列表
控制脚本流程
if { } else { }
for{ }
while{ }
总之 C 语言的控制流程的语句这里都可以直接使用
字符串函数
由于在 VuGen 脚本中使用最多的还是字符串,所以字符串函数在脚本中使用非常频繁。具体的语法请参考帮助说明。
strcmp 比较两个字符串
strcat 连接两个字符串
strcpy 拷贝字符串
输出函数
输出函数在调试脚本时非常有用。
lr_output_message 输出一条消息
LoadRunner 提供的标准函数
lr_eval_string 该函数功能是得到参数(参数化输入中)当前的值
exg: lr_output_message("temp = %s", lr_eval_string("{WCSParam2}"));
lr_save_string 该函数功能是把一个字符串保存到参数中
exg: lr_save_string("439","WCSParam3");
2.插入检查点
在进行压力测试时,为了检查Web 服务器返回的网页是否正确,VuGen 允许我们插入Text 检查点,这些检查点验证网页上是否存在指定的Text,还可以测试在比较大的压力测试环境中,被测的网站功能是否保持正确。检查点的含义和unittest中的断言功能基本上一致。通过菜单—查看—快照,可以查看到http数据视图,选择检查的文本,选择添加文本检查步骤,即可添加一个检查点。
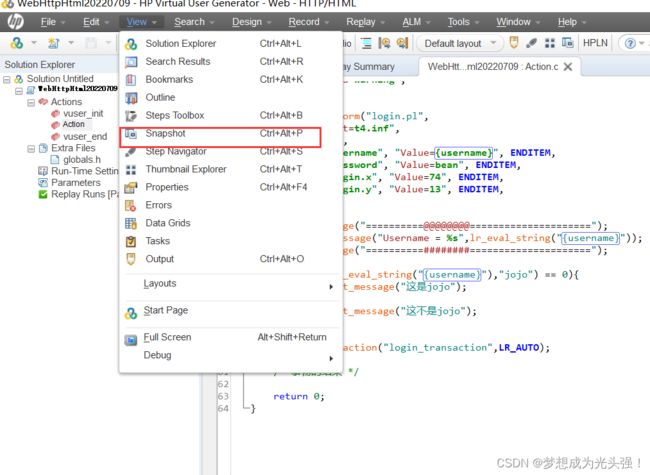
首先添加Snapshot,刚才我们说了可以通过是否存在指定的HTML来检查。
那首先第一步,鼠标移动到web_submit_form()当中去,然后单击左键,出现如下页面

然后点击Response Body,就可以看到我们的响应体,然后在其中寻找我们的定位内容,也就是我的蓝色字体标记部分。
右击点击之后,选择add

然后就会生成如下检查点

如果你是系统自动生成之后直接运行,这里是肯定有问题的,因为检查在登录之前。所以为了解决这一情况,这里我们需要增加一行代码就是我上面的SaveCount哪一行,意思就是说:如果说当前没有找到,那我不着急,等运行完之后我再检查。
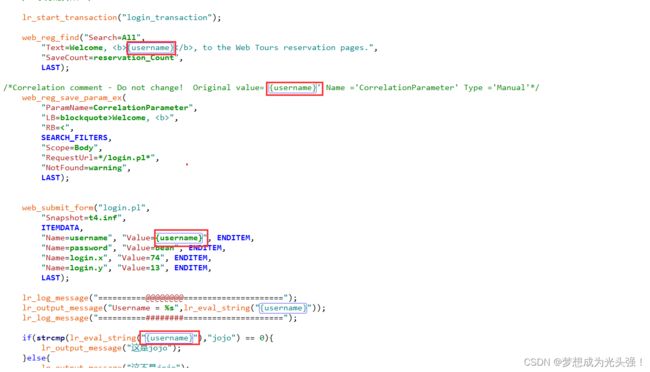
web_reg_find("Search=All",
"Text=Welcome, {username}, to the Web Tours reservation pages.",
"SaveCount=reservation_Count",
LAST);
这个时候就没有问题了。
3.关联和参数化输入
首先,什么是关联呢?
之前我们的登录都是单用户登录,但是如果想多用户登录测试并发性呢?不可能改一次代码登录一次吧?这个时候就是我们的关联和参数化输入的作用了。
如果说想要参数化输入,那么首先肯定就是关联,不同的场景有不同的用户名登录,则关联的是用户名。
首先就是在Snapshot中,找到用户名

然后点击关联
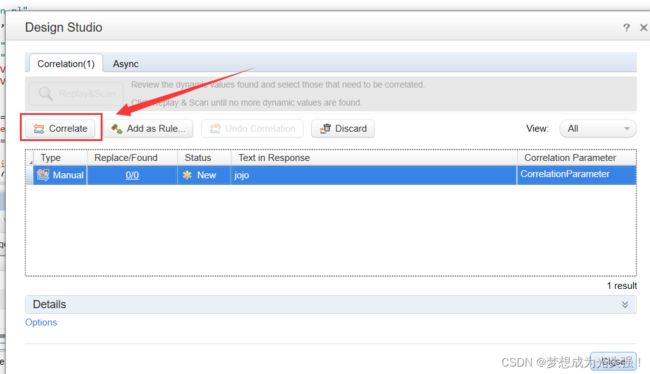
此时关联成功,生成如下代码

但是此时你运行可能会报错,所以这里我们还需要添加一行代码
"NotFound=warning",
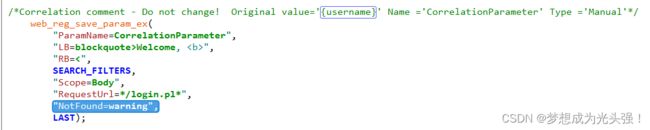
然后单次就可以成功运行。那么我们此时要测试的不止一个用户呀?那就要开始我们的参数化输入了
首先双击web_submit_form()中的用户名,然后改成把Parameter改成username
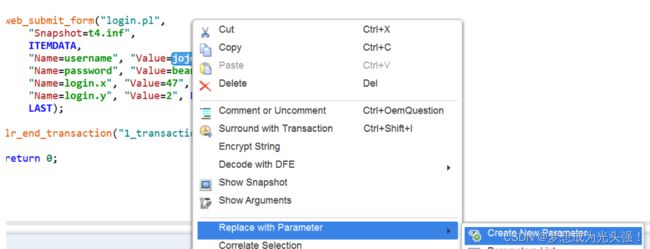
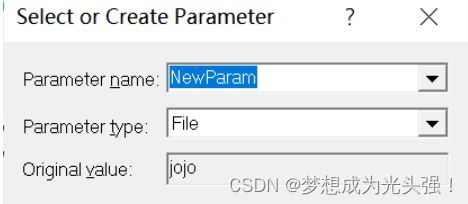
此时界面显示如下
但是此时我们也只会运行一次,所以就要增加参数了。

此时我们有多种方式增加参数
user先添加
这里就是我们上面密码查询时候的users所在地
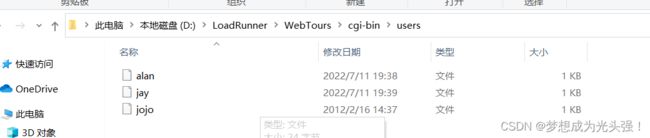
这里其实就是我们复制粘贴然后修改


以上是修改的对应例子,这里我们就先增加两个用户,这里先增加了之后,然后我们才可以通过一些方式来进行参数化输入。
方式一:File Path


这是一种方式,就是直接加用户名就好
方式二:Add Row
方式三:Edit with Notepad
这种好像和第一种差不多哈

添加了之后我们的关联就完成了。
但是这里我最后特别说一遍,要必须现在user中有对应的用户名你才可以添加,不然的话没有添加的必要。
更改用户数
但是你可以发现只运行了一次,为什么呢?这里我们对上面的输出参数进行一个应用来进行检测
lr_log_message("==========@@@@@@@@=====================");
lr_output_message("Username = %s",lr_eval_string("{username}"));
lr_log_message("==========########=====================");
此时运行之后我们就可以发现只有jojo运行了,原因是什么呢?
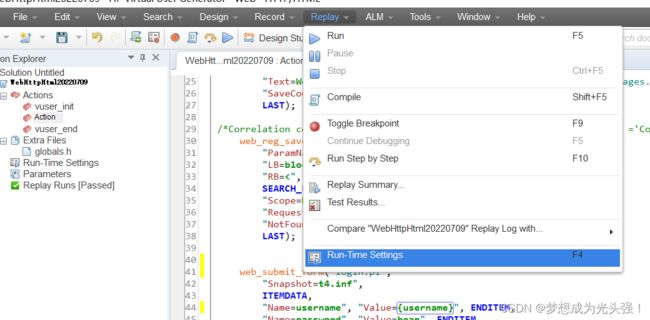
在这里,点开之后你发现我们的用户就是1
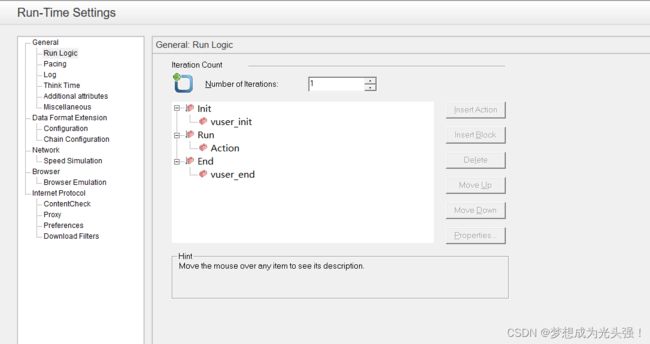
然后我们增加到三个,此时再次运行
(它的运行代码太长了,这里就不截图了)
关于字符串函数的应用
这里的话就说一下关于字符串函数的应用部分
strcmp 比较两个字符串
这里如果说用户是jojo,我们就输出这是jojo
if(strcmp(lr_eval_string("{username}"),"jojo") == 0){
lr_output_message("这是jojo");
}else{
lr_output_message("这不是jojo");
}
特别注意,这里的代码部分!!!写法挺重要的。还有就是正确是0,不正确是1。
4.关于Parameter Properties一些小问题
Parameter Properties界面,在Update value on选项中,Each iteration是按照我们设置的参数的顺序去Replay,而Each occurrence 是随机地抽取变量去Replay,抽取的结果可能会重复,而Once 是选择变量的第一个进行Replay,如果是要Replay三次,那么运行的三次可能都是该变量。
接下来我们选择Each occurrence,然后运行脚本之后我们就会发现一个神奇的事情



以上是三个用户运行完毕之后的判断顺序,username不是jojo的时候给你打印说是jojo,username是jojo的时候给你打印说不是jojo,咋回事呢?
其实它这里的判断顺序是根据我们在Parameter Properties当中用户名的顺序是一样的。

三丶controller执行性能测试场景
这一部分说一下我们controller里面的一些属性。


然后点击ok,他就会自动生成到我们的controller里面,然后对里面的值进行说明。
<1>选择测试脚本

<2>选择测试路径
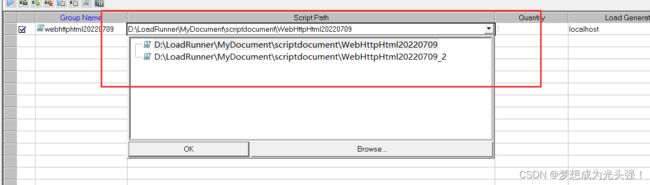
<3>选择服务器
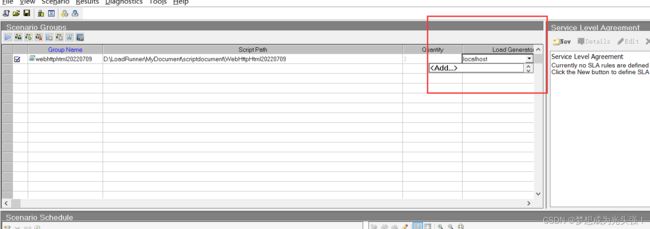
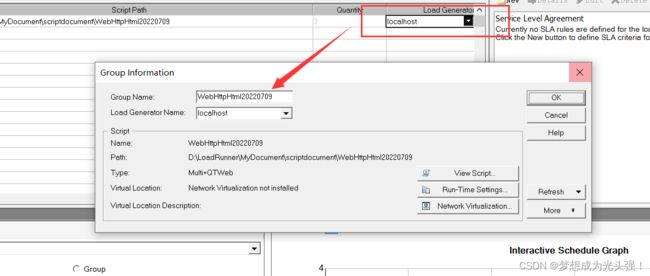
这里我们默认是本地,但是如果是以后工作了,那么我们的测试服务器可能部署在其他地方,这个时候就要选择对应服务器和填写URL了

然后这里的话对应一些参数说一下

View Script:查看自己的脚本
Run-Time Settings:设置运行的次数
NetWork Virtualizaton:设置虚拟网络部分
<4>增加用户和增加组数

这里的话就是增加用户数,当然你还可以增加我们的测试group,这里的话我们当前就运行了一个脚本,所以先不需要增加,需要再在增加
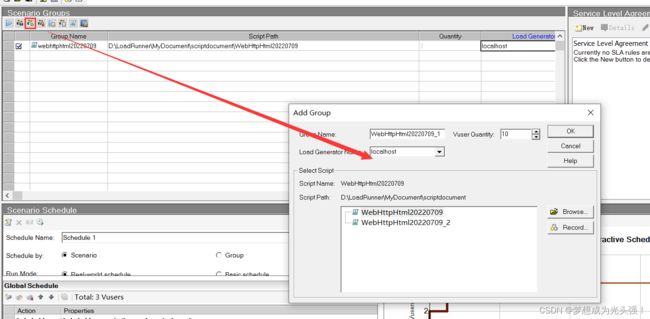
<5>选择初始化用户数
这里描述的不是很准确,应该是每秒增加多少用户
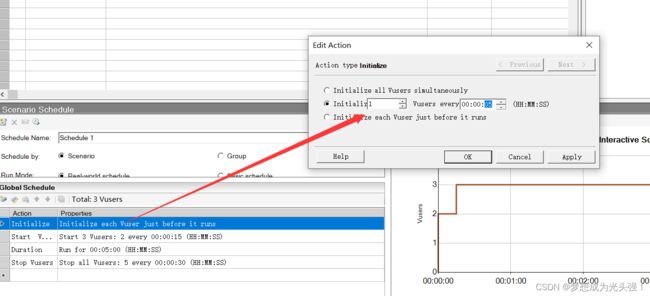
这里我们设置五秒初始化一个
<4>每秒启动用户数

这里我们选择每五秒启动一个用户数
<5>设置运行时间

这里我们设置跑三分钟
<6>退出设置
这里设置退出的时间我们设置每五秒退一个

然后完成以上工作之后,我们就可以运行脚本了,运行完脚本之后,就会自动的生成Analysis,然后根据以上情况去分析就好啦。
四丶数据分析
首先在具体的分析之前别忘了设置我们的数据自动收集,没设置的设置一下。

设置完了之后就运行就好

以上的这些参数仅做说明,电脑原因,所以可能有些地方测试数据有点不太对。然后开始对以上的部分点进行说明

然后是下面的那部分

上面大约是这几种

然后目前LoadRunner的基础知识点和使用方法就大约是这些