Educational Codeforces Round 159 (Rated for Div. 2)补题
Binary Imbalance
题目大意:给定一个01串s,我们可以执行如下操作:1.在两相同的数之间插“1”;2.在两个不同的数之间插“0”.问能否使操作后的字串中0的个数严格大于1的个数。
思路:我们可以发现能插入字符总共三种情况:
1.00之间插1,然后得到010,然后就可以在01之间无限插0,那么0的个数一定可以大于1的个数
2.11之间插1,那么无论怎么样都不能在这个位置产生0
3.01、10之间插0,得到001、100,也是可以在01之间无限插0,那么0的个数大于1的个数,也是一定会实现的事情。
所以综上,只要s中有一个0,那么0的个数最终大于1的个数就是必然的事情。
#include
using namespace std;
int main()
{
int t;
scanf("%d",&t);
while(t--)
{
int n;
string s;
cin>>n>>s;
int x=0;
for(int i=0;i<=s.size();i++)
{
if(s[i]=='0') x++;
}
if(x) printf("YES\n");
else printf("NO\n");
}
} Getting Points
题目大意:M需要在n天内获得p分,他上一节课可以获得l分,完成一个任务可以获得t分,课程每天都有,但是任务会在1,8,15,...天依次解锁,只有解锁了才能去做这个任务。他每天最多上一节课做两个任务,问他最多可以休息多少天。
思路:我们可以发现他n天可以解锁的任务数为task=(n-1)/7+1个,而且我们注意到,我们如果在最后若干天做任务的话,此时的任务是全部解锁的,换句话说,我们一定可以规避做到还没解锁的任务,也即可以实现只要想就有任务做。那么我们来考虑,他只有dt=task/2天是每天可以做两个任务的,为了使效益最大化,他这些天同时听课,那么我们考虑同时听课并作任务需要多少天获得想要的分:nd=ceil(p*1.0/(l+2*t));然后我们需要考虑到,nd与dt的关系:
nd<=dt:即任务的个数支持他每天上一节课做两个任务直到分数足够;
nd>dt:任务数量不支持他一直做到学分足够,那么不够的分需要听课来解决,另外task如果是奇数个,就有一天只能做一个任务,需要考虑进去。
那么至此就,实际上就实现了。
#include
using namespace std;
#define int long long
signed main()
{
int t;
scanf("%lld",&t);
while(t--)
{
int n,p,l,t;
scanf("%lld%lld%lld%lld",&n,&p,&l,&t);
int task=(n-1)/7+1;
int dt=task/2;
int nd=ceil(p*1.0/(l+2*t));
if(nd<=dt)
{
printf("%lld\n",n-nd);
}
else
{
p-=dt*(l+2*t);
if(task%2)
{
p -= (l+t);
dt++;
if(p>0)
dt += ceil(p*1.0/l);
}
else
{
dt += ceil(p*1.0/l);
}
printf("%lld\n",n-dt);
}
}
} Insert and Equalize
题目大意:给定一个n长数组a[],a[]中的数各不相同,我们现在要插入另一个异于它们的数a[n+1],现在需要选择一个正整数x,每次操作我们可以将任意一个a[i]加上x(x对所有操作都相同),然后最后需要在若干操作数内实现让数组中所有的数都相等。问最小的操作是多少。
思路:先不考虑a[n+1],我们来看,每次加的数都是x,最后要使所有数都相同,那么就是将所有数都变成最大的,在一定程度上可以最小化操作数,那么来看,x该怎么选,实际上应该是所有数与最大数的差值的公因数,因为每次都要尽可能地多加一些,但是又要保证最后所有数要到最大数,那么就只能将x设为它们的最大公因数。然后来考a[n+1]的值,有两种情况,一种是将a[n+1]设为mx+g(g表示最大公因数),那么对于n个数,每个数的操作都要加一次;另一种保持mx不变,a[n+1]通过mx-k*g得到,那么新增的操作数就是k。另外要注意到一种情况-1e9,0,1e9,对于这种情况g=1e9,但是无论用以上两种方法中的哪种来取a[n+1]得到的数都会超过给定范围,所以我们要缩小g,最好的办法就是g/=2,这样的就可以使新增操作数最小。那么至此就实现了。
注意注意注意!最重要的一点,找最大值的过程一定要注意,mx的初值一定要设在数据范围之外,不能单纯的设置成0,因为可能所有的数都小于0,一定要注意,这种错没必要出现,就不要让它卡住你。
#include
using namespace std;
int a[200010],b[200010];
int main()
{
int t;
scanf("%d",&t);
while(t--)
{
int n;
scanf("%d",&n);
int mx=-1e9-7;
mapmp;
for(int i=1;i<=n;i++) scanf("%d",&a[i]),mx=max(mx,a[i]),mp[a[i]]=1;
if(n==1) printf("1\n");
else if(n==2) printf("3\n");
else
{
for(int i=1;i<=n;i++) b[i]=mx-a[i];
sort(b+1,b+1+n);
int x=b[2],y=b[3];
int g=gcd(x,y);
for(int i=4;i<=n;i++) g=gcd(g,b[i]);
int in=mx-g;
while(mp[in]==1) in-=g;
if(in<-1e9)
{
if(mx+g>1e9)
{
g /= 2;
in=mx-g;
while(mp[in]==1) in -= g;
long long ans=(long long)in/g;
for(int i=1;i<=n;i++) ans += b[i]/g;
printf("%lld\n",ans);
}
else
{
long long ans=(long long)in/g;
for(int i=1;i<=n;i++) ans += b[i]/g;
ans += n;
printf("%lld\n",ans);
}
}
else
{
in = mx-in;
long long ans = (long long)in/g;
for(int i=1;i<=n;i++) ans += b[i]/g;
printf("%lld\n",ans);
}
}
}
} Robot Queries
题目大意:现有一个机器人位于(0,0)位置,有一个指令字串s,同时有q个询问,每个询问由x,y,l,r构成,询问的内容是如果将s中[l,r]区间的指令倒置再执行s,是否会经过坐标为(x,y)的点。
思路:这个题很容易想到暴力,但是也很明显暴力会超时。但是我们就会想,不可能在路线都不走的情况下就知道它经过哪些点。诚然如此,但是我们先换个思路,找一找倒置的路线有什么特点。首先可以确定地是一个操作对应一个点,未必不重复,但是一个操作之后就可以得到一个点。我们想一想,在[l,r]之前的部分,路线是不变的,倒置的意义是什么呢?原本从起点出的边变成了指向终点的边,所以实际上,起点和终点是不变的(或者这个直接从图中得到)(或者我们再换个方法来看,我们只是交换操作的执行顺序,但在大方向上比如总共向上多少步,向下多少步,向左多少步,向右多少步都是不变的,那么无论按照什么顺序执行,起点和终点都是定的),那么终点不变的话,r后面的边和点自然也是不变的。那么如果(x,y)对应的点在第一遍执行s的时候经过的操作不在区间[l,r]中,那么自然可以的经过,然后遍历无法实现,那么我们考虑一下,如果点在路径上能不能映射到原路径上去,显然是可以的。那么该如果映射呢?
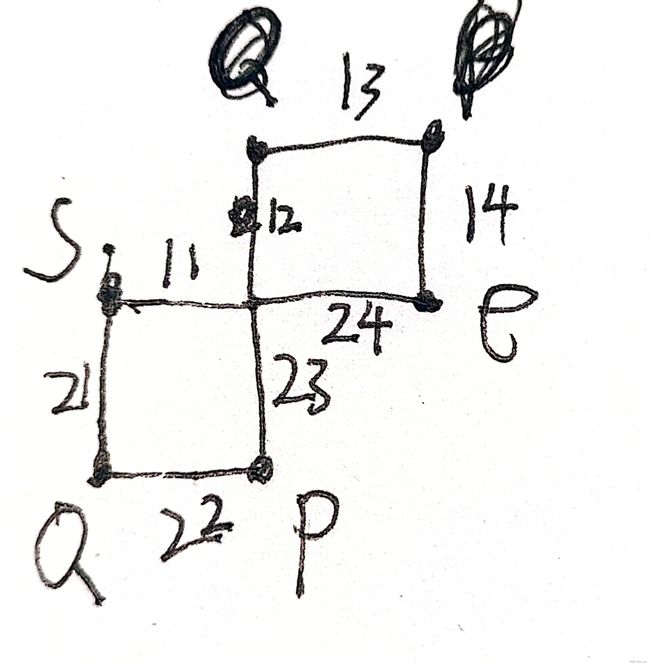
如图,s是起点,e是终点,1是原路径,2是倒置后的路径。我们看路径上的p点,它到e点需要经过23,24这两条边,这两条边可以还原到1路径中 ,那么对应的是哪两条边呢,很显然对应的是12,11这两条边,所以我们由此延伸,若(x,y)在倒置后的路径上,那么从(x,y)到e需要走的路径,刚好可以转化成从s出发走的路径,那么它对应的点也由此得到,当然曲曲折折太麻烦,我们直接将边全部平移拉直(或者换句话说,只关注从(x,y)到终点需要往哪个方向走多少步),再将这个对应给起点,然后就可以得到一个新的点,那么这个新的点如果在我们的原路径上,很显然(x,y)也在新路径上。由此思路理通。
然后来看实现,因为一个操作对应一个点,所以我们需要记录的的有两个,一个每一步操作得到的是哪个点,这个可以用vector
然后就是按照上面的思路将代码写出来就可。
#include
using namespace std;
char s[200010];
int main()
{
int n,q;
scanf("%d%d",&n,&q);
vector>p(n+10);
map,set>mp;
scanf("%s",s+1);
int x=0,y=0;
p[0]={0,0};
mp[{0,0}].insert(0);
for(int i=1;i<=n;i++)
{
if(s[i]=='U') y++;
else if(s[i]=='D') y--;
else if(s[i]=='R') x++;
else x--;
p[i]={x,y};
mp[{x,y}].insert(i);
}
while(q--)
{
int x,y,l,r;
scanf("%d%d%d%d",&x,&y,&l,&r);
//置换部分:起点p[l-1],终点p[r]
int a=p[l-1].first+(p[r].first-x);
int b=p[l-1].second+(p[r].second-y);
if(mp.count({x,y})&&(*mp[{x,y}].begin()=r)) printf("YES\n");
else if(mp.count({a,b}))
{
//(a,b)对应的操作要有一个落在我们[l,r)内
int flag=0;
setsi=mp[{a,b}];
for(auto t:si)
{
if(l<=t&&t Collapsing Strings
题目大意:给定n个字符串,我们对任意两个字符串s1,s2,它们的c(s1,s2)的计算方法如下:
1.s1为空,c(s1,s2)=s2;
2.s2为空,c(s1,s2)=s1;
3.s1的结尾字母==s2的开头字母,c(s1,s2)=s1[1,sz-1]+s2[2,sz];(即相同字母相互抵消)
4.s1的结尾字母!=s2的开头字母,c(s1,s2)=s1+s2
|C(s1,s2)|表示生成字符串的长度。
求![]() 。
。
思路:我们可以发现两者能相互抵消,那么就是说两者的前后缀相同,然后将前后缀的部分相互抵消掉。那么我们能不能统计出每个字串的所有前缀和所有后缀,并将它们分别放入两个数组,然后用总长减去相同的前后缀匹配的对数产生的抵消呢?有点道理但不多,因为会出现如下情况:
s1=abcd,s2=bcd
d会在前后缀数组中被统计
cd会在前后缀数组中被统计
bcd会在前后缀数组中被统计
我们减去抵消的时候是没办法区分它们的,那么很显然我们会多减很多,得不偿失。
所以说,就不能只盯着前后缀来看,我们再看细一点,既然前后缀这种字串会算重复,那么我们直接去看两个字母,我们讨论后缀直接将整个字符串你过来作为一个新的字符串来看。那么我们来看两个字母可以抵消的条件是什么:1.这两个字母相同,2.两个字母前面的字母也相同;只要满足这两个条件,那么这两个字母就可以抵消。也就是说对于一个字母,它的状态由两个因素决定,一个是它本身的值,一个是它的前面字符产生的状态。如果我们用一个特定的数字来表示它的状态,我们可以发现,它后面那个字母的前面字符产生的状态实际上是可以用它的状态来表示的(有点递归的感觉),那么现在我们只用处理出每一个字母的状态,并统计出从前往后访问每个状态出现的次数,以及从后往前访问每个状态出现的次数,如果一个状态在从前往后访问的记录数组中出现,在从后往前访问的记录数组中出现,那么这两个字母一定是可以抵消掉的。那么问题就很好解决了。
但是要注意到,我们记录每个字母的状态需要将二维的状态映射到一维,才方便统计,这个映射用到hash的思想,但是实现的时候却只能用数组,我试验过,如果使用map
至此问题差不多分析清楚了,我们再来总的复盘一遍,能抵消的话就是前后缀相同,但是统计前后缀会导致重复计算,所以转而去看单个的字母,这样的话,两个字母能够抵消的前提是它们本身相同,而且它们前面的字母也相同(从后往前的我们视为一个新的正着的字符串),那么就要去记录每个字母的状态,以及每个状态在正向和逆向中出现的次数。只要得到了每个字母的状态,那么出现次数很容易记录,那么每个字母的状态该怎么得到呢?我们发现它的状态跟两个因素有关,那么我们就用一个二维的对来记录它的状态,一个维度肯定要用来表示它本身,这个很容易表示,另一个维度要用来表示它前面所有字母的状态,这个看上去有点麻烦,但是却可以通过递归得到,我们先将二维的状态顺次映射成一维的数,那么一个一维的数就对应一个二维的状态,那么我们可以递归的用前一个字母状态对应的一维的数来表示后一个字母的前字状态,至此,每种情况都有了特定的表示,最后累计一下即可。
#include
using namespace std;
const int N=2e6+10;
int idx;
int ha[N][30],pr[N],la[N];
int main()
{
int n;
scanf("%d",&n);
long long ans=0;
for(int i=1;i<=n;i++)
{
string s;
cin>>s;
int p=0;
for(int i=0;i=0;i--)
{
int c=s[i]-'a';
if(!ha[p][c]) ha[p][c]=++idx;
la[ha[p][c]]++;
p=ha[p][c];
}
ans += 2ll*n*s.size();//每个字串对于这n的字串都以首尾的位置各出现一次,所以总长这么累加
}
for(int i=1;i<=idx;i++) ans -= 2ll*pr[i]*la[i];//一对匹配可以删掉两个字母,总对数等于乘积
printf("%lld",ans);
} ps:这个题最妙的还是它的hash以及状态表示和转移的过程,一一映射的hash,递归的状态转移。