百度搜索万亿规模特征计算系统实践

作者 | Jay
导读
本文主要介绍百度搜索在全网万亿级规模内容做内容理解的工程实践,涉及机器学习工程化、资源调度、存储优化等多个Topic。
全文6648字,预计阅读时间17分钟。
01 业务背景
百度收录了互联网海量内容,要索引这些内容,需要先对内容做深度理解,提取包括内容语义、内容质量、内容安全等多维度信息,从而进一步支持内容筛选过滤、语义建库等需求。对全网海量内容做深度理解,挑战是非常大的,主要是体现在成本和效率上。
在成本上,计算量非常大,除了因全网内容数据量大(万亿规模)、特征数多外,有两个趋势也加剧了计算压力,一方面是互联网内容图文化、视频化比例持续大幅增长,图片/视频的计算量远大于文本,另一方面,深度学习技术大规模应用,特别近期大模型的兴起,对算力需求也随之剧增。在效率上,怎么让系统更易用,尽可能地提升业务迭代效率,是所有工程系统的核心目标之一。

02 关键思路
(1)成本优化:要满足如此庞大的算力需求,需要极致地『开源节流』。
1.『开源』:尽可能扩大计算资源池,通过采购来满足ROI低,挖潜现有资源是关键。从公司整体看,资源使用并不充分,在线资源存在波峰波谷,库存空闲资源也不少,而我们大多为离线计算,对资源稳定性要求不高,可以结合两者,建设一套弹性计算调度系统来解决资源问题。
2.『节流』:尽可能优化服务性能,降低单位计算成本,模型推理计算量大,但本身有较大的优化空间,结合模型结构和GPU硬件特点进行优化,可以大幅提升模型服务单卡吞吐。此外,优化CPU处理、使用百度自研昆仑芯片等多种方式也能降低单位成本。
(2)效率优化:如图所示,整体业务流程包括实时和离线计算两部分,新增特征需对存量数据离线刷一遍,而对Spider新收录的数据,会筛选高时效性的数据实时计算,其余的也离线计算,计算大头在离线部分。效率问题主要为:怎么支持模型快速工程化?怎么提升离线计算效率?
1.模型服务框架&平台:模型工程化是通过统一的模型服务框架和配套的模型服务平台来实现,模型服务框架和平台支持并涵盖从构建、测试、上线等模型服务全生命周期的各个环节。
2.特征批量计算平台:为了离线特征计算效率问题,建设了统一的批量计算平台,分析并深度优化从离线任务开发到计算过程中各环节的效率和性能瓶颈,尽可能地提升效率。

03 技术方案
3.1 整体架构
整体架构如下图所示,最核心的是模型服务平台、批量计算平台、计算调度系统、模型服务框架这几部分。
1.模型服务框架:算法同学使用统一的模型服务框架进行服务封装,基于研发效率考虑,选择Python作为框架语言,但Python性能问题也很明显,因此需要做很多针对性优化。此外,我们也在框架持续集成多种推理优化手段,尽可能地降低服务单位计算成本 。
2.模型服务平台:模型服务平台支持模型服务DevOps和能力输出,平台以『算子』作为管理粒度,『算子』代表一种完整功能,如视频分类等,它通常需要多个模型服务组合使用。算法同学在平台注册算子,提供服务拓扑等元信息,也通过自动性能调参、自动化压测等生成性能报告,服务拓扑和性能报告是后续调度的重要输入。平台也提供算子检索、调研试用等功能,以中台化方式支持其他业务需求。
3.计算调度系统:计算调度系统做流量和资源的统一调度,所有对模型服务的请求都会经过计算调度系统的网关,执行流控和路由等流量策略,计算调度系统也会调度百度多个PaaS的多种空闲异构资源,自动化部署合适的算子,给离线计算提供更大吞吐。
4.批量计算平台:批量计算平台支持离线作业的任务生成、任务调度、DevOps等功能,建设基于HTAP的存储方案,解决Scan吞吐瓶颈问题,并联动计算调度系统,支持大规模离线计算。
3.2 技术关键点
本章节主要阐述系统技术关键点,包括遇到的技术难点、思考和权衡折衷,一些共性问题也期望读者能和我们多多交流。
3.2.1 模型服务框架
在实际业务场景,模型服务框架有几个关键问题需要解决:业务编程模型、Python服务性能优化、以及推理性能优化,下面介绍。
3.2.1.1 业务编程模型
实现某个功能往往需要组合使用多个模型和多种数据处理逻辑,为了抽象表达处理流,实现通用逻辑复用,采用方案如下:
-
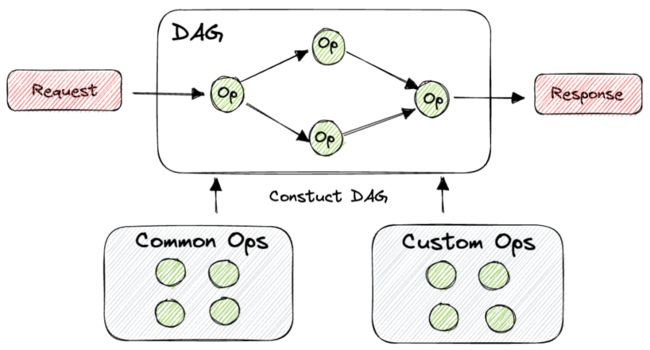
将业务逻辑描述成DAG(有向无环图),DAG上的节点称为Op,DAG有多个Op组成,Op之间存在串联和并联关系,一个OP可以是模型推理或者一段处理逻辑,Op之间通过数据白板进行上下文传递。通过DAG能清晰地呈现整体处理流程,提升代码可读性和可维护性。
-
建设通用Op库,像模型推理、视频抽帧、视频转换等通用逻辑被整合成通用Op库,支持业务复用。业务也可根据需要,定制扩展Op,并注册到框架使用。
3.2.1.2 Python服务性能优化
选择Python降低了开发成本,但也引入了Python GIL(全局解释器锁)问题,导致不能充分利用CPU多核,极大限制了服务吞吐,解决方案如下:
-
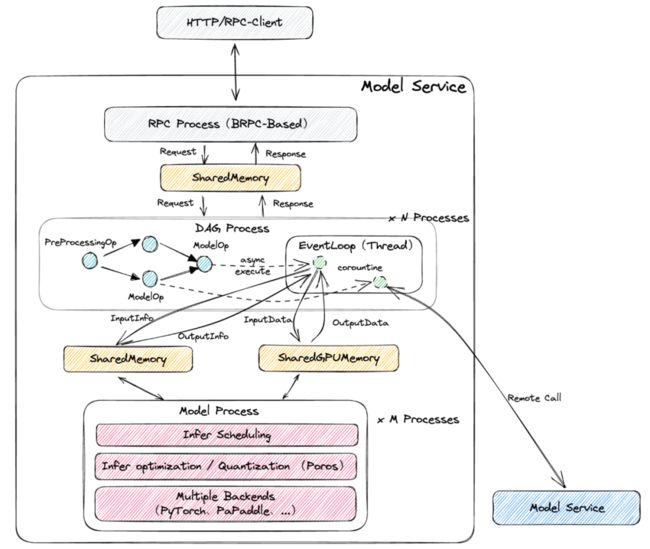
采用多进程+异步协程+CPU/GPU计算分离的并发方案,服务包含三类进程:RPC进程、DAG进程、模型进程,它们之间通过共享内存/显存进行数据交互。
-
PRC进程负责网络通讯,基于BRPC开发(开源版本:https://github.com/apache/brpc ),我们优化了BRPC的Python实现,使其支持Python多进程和协程的并发模式,在实际业务场景测试下,优化后性能提升5倍+。
-
DAG进程负责DAG执行(CPU处理),通过多DAG进程和Op执行异步协程化来充分利用CPU多核。另一个比较重要的是ModelOp,它实际是推理代理(类似RPC),真正推理是在本地模型进程或者远程服务执行,ModelOp屏蔽了调用细节,支持用户方便地使用模型。
-
模型进程负责模型推理(GPU处理),考虑显存有限等原因,模型进程和DAG进程分离独立,模型进程支持Pytorch、Paddle等多种推理引擎,并做了很多推理优化工作。由于Tensor数据通常较大,DAG和模型进程传输Tensor直接使用共享显存,避免不必要的内存拷贝。
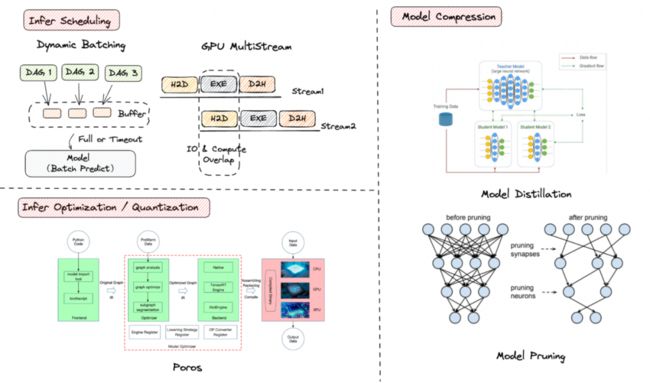
主要有推理调度、推理优化、模型量化、模型压缩等优化手段,经过优化,服务单卡吞吐相比原生实现通常有数倍提升。
1.推理调度:动态批量处理(DynamicBatching)和多Stream执行。GPU批量计算效率更高,由于服务也接受实时单条请求,没法请求时拼Batch,因此采用服务内缓存拼Batch,牺牲时延换吞吐。Stream可看做GPU任务队列,默认全局单条,任务串行执行,会出现GPU IO操作(内存显存互拷)时,计算单元闲置,通过创建多Stream,不同推理请求走不同Stream让IO和计算能充分并行。
2.推理优化:业界主流方案是使用TensorRT,但是实际应用会有动态图静态化失败、TensorRT Op覆盖不全等问题。为解决这些问题,团队自研Poros(开源版本:https://github.com/PaddlePaddle/FastDeploy/tree/develop/poros ) ,结合TorchScript、图优化、TensorRT、vLLM等技术,实现无需复杂模型转化,添加几行代码即可大幅提升推理性能,效率和性能双赢,同时Poros也支持昆仑等异构硬件。
3.模型量化:GPU、昆仑等硬件对低精度都有更强的算力,量化虽有少量效果损失,但带来大幅吞吐提升,因此,上线都会采用FP16乃至INT8/INT4量化,这部分也是通过Poros支持。
4.模型压缩:通过模型蒸馏、模型裁剪等方法精简模型参数,减少计算量,但是需要训练,且效果有损,通常和算法同学一起合作优化。
3.2.2 计算调度系统
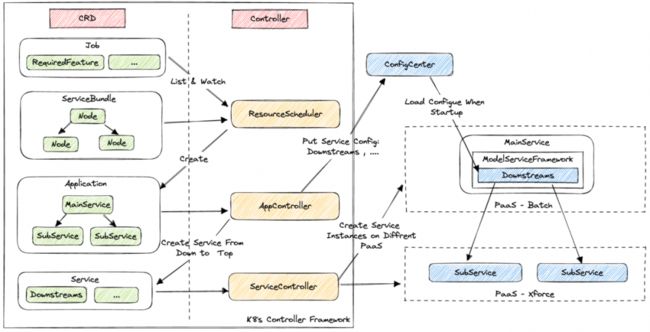
计算调度系统的运行架构图如下,所有请求流量都通过统一的网关(FeatureGateway),网关支持流控、路由等多种流量策略。离线作业也通过网关提交计算需求,网关会将需求转发给调度器(SmartScheduler)进行调度。调度器对接了百度内多个PaaS,不断检测空闲资源,根据需求、多种指标、空闲异构资源分布等,自动化调度部署合适的算子,算子元信息从服务平台获取,调度完成后,调度器会调整网关的流控和路由等。
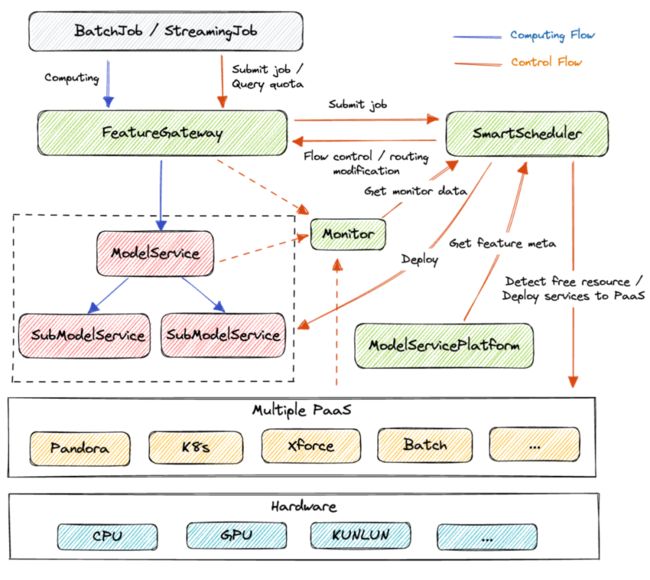
系统比较关键的两个问题:怎么实现算子(复合服务,含复杂服务拓扑)自动化部署?怎么在流量分布不稳定、多异构资源等复杂条件下进行调度?
3.2.2.1 自动化部署
为简化调度器开发复杂度,采用声明式编程,实际是基于k8s controller机制开发。算子自动化部署实现方案如下:
1.CRD扩展:利用K8S CRD来自定义ServiceBundle(算子部署包)等对象,通过controller机制让在PaaS等外部系统执行部署等操作。ServiceBundle包含了算子需要的所有子服务部署信息,以及其拓扑关系。调度创建算子服务时,会从最底层开始逐层创建子服务,上层子服务可以通过通信托管机制获得下游子服务地址。
2.通信托管:通信托管机制是基于配置中心和模型服务框架实现,服务启动命令会带有远程配置地址和AppID,通过加载远程配置可以实现下游服务地址启动时变更。其实更理想方案是使用ServiceMesh等技术将架构能力和业务策略解耦,但考虑我们要在多PaaS部署,而在各个PaaS都部署ServiceMesh SideCar等组件成本较高,集成到框架又过于重,因此,先建设基于配置中心的方案,后续时机成熟再考虑迁移。
3.2.2.2 调度设计
调度是个非常复杂的问题,在我们场景,其复杂性主要体现在以下几方面:
1.算子调度:算子(复合服务)可承载流量取决于其最短板的子服务容量,调度时需要整体考虑,避免长板服务资源浪费。
2.流量分布变化:部分算子的性能会受输入数据分布影响,如视频OCR会受视频时长、画面文字比例影响,调度时需要自适应调整。
3.多异构硬件:算子有些能支持多种异构硬件(昆仑/GPU/CPU等),有些只能绑定一种,怎么分配才能保证全局资源最有效利用。
4.其他因素:作业优先级、资源优先级、资源波动等因素也都会影响调度,实际调度要考虑的因素非常多元化。
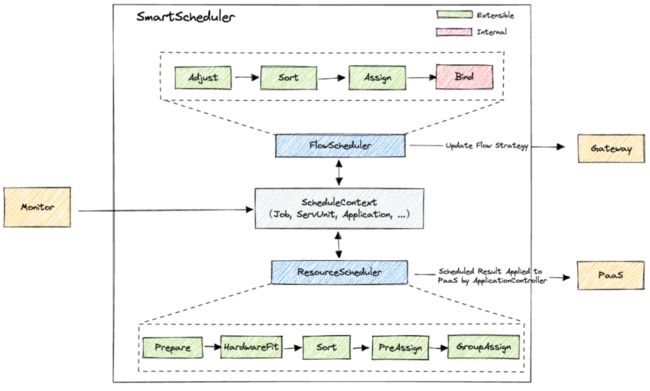
基于以上因素考虑,我们的调度设计方案如下:
1.两阶段调度:分流量调度和资源调度两阶段,各自独立调度。流量调度负责对当前算子服务容量分配到各个作业,并结果同步到网关,调整流量策略;资源调度负责根据资源空闲情况和算子容量缺口等进行调度,最终对算子服务实例进行扩缩容。
2.流量调度:流量调度Adjust阶段会根据任务运行指标等调整归一化系数,再用系数将任务所需Qps映射成NormalizedQps,NormalizedQps是后续所有调度的依据,从而解决流量分布变化影响问题。在Sort阶段会根据作业优先级等排序,在Assign阶段会根据Sort结果,按优先级将现有算子容量分配到各个作业。Bind阶段会将结果执行,同步路由等到网关。
3.资源调度:资源调度Prepare阶段会先将作业的容量缺口转换成对应服务实例数缺口;接着进行HardwareFit,将要扩容的服务分配到合适的硬件资源队列,并根据资源稀缺性、计算性价比等进行Sort;然后进行PreAssign,对各子服务进行资源预分配,最后GroupAssign阶段考虑复合服务的各子服务调度满足度,对复合服务的各子服务容量进行细调,避免资源浪费。
3.2.3 批量计算平台
批量计算平台要解决的问题:弹性资源比较充裕时(如夜间),对Table(分布式表格系统)的Scan吞吐瓶颈,以及怎么尽可能地优化离线任务效率,下面介绍具体解决方案。
3.2.3.1 HTAP存储设计
先分析对Table Scan慢的原因,主要如下:
1.读写混合:OLTP(抓取更新等)和OLAP(特征批量计算等)需求都访问Table,多种读写方式混合,而底层采用HDD存储,大量读写混合使磁盘IO吞吐严重下滑
2.Scan放大:Table采用宽表结构存储,不同任务Scan时通常只需要其中的某几列,但Table Scan时需要读取整行数据再过滤,IO放大严重。
3.扩容成本高:由于OLTP和OLAP混合读写,要为Scan单独扩容成本高,同时因读写比例难以固定,也很难预估扩容资源。
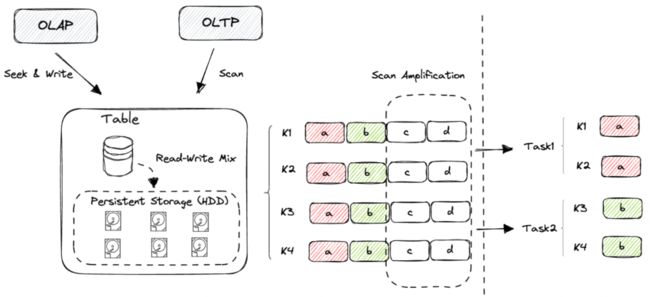
通过上述分析可知,关键问题还是OLTP/OLAP混合使用Table。参考业界实践,采用单一存储引擎难以同时满足OLTP和OLAP场景,但为了存储系统易用性,又希望一套存储系统同时支持两种场景。因此,我们结合业务场景和业界经验,实现一个HTAP存储方案,具体方案如下:
1.OLAP/OLTP存储分离 :针对批量计算等OLAP场景建设高效OLAP存储,减少因OLAP/OLTP混合使用Table带来的读写混合问题,也可根据需求单独扩容。
2.高效OLAP存储设计:自研OLAP存储基于Rocksdb、AFS(百度类HDFS)构建,采用增量同步、行数据分区、列数据动态合并存储的设计,将Table全量数据划分成N个数据物理分区,利用Table的增量Snapshot定期高效同步更新OLAP存储数据(由于Table底层采用LSM存储,增量Snapshot效率远高于全量Scan)。列存储根据字段访问热点重新组织,将热点列在物理层一起存储,降低IO放大,也支持动态调整。方案会存在数据同步延时问题,但在我们场景,时效性要求不高,问题可以忽略。
3.HTAP SDK:提供统一的SDK同时支持对Table和OLAP存储访问,用户基于SDK可以同时执行自己的OLAP和OLTP任务。

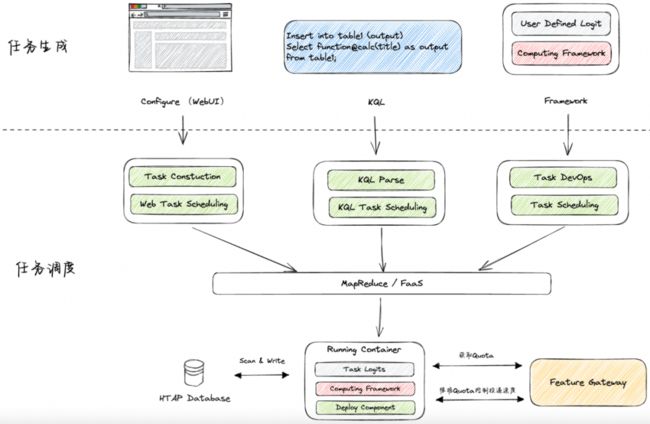
3.2.3.2 任务生成与调度
为了简化批量计算任务的开发,平台目前提供了三种任务开发模式:配置化、KQL、离线框架,开发自由度/成本由低到高,易用性由高到低:
-
配置化:针对通用并频繁使用的任务类型,平台对这些任务进行高度封装,只需要在Web界面上配置即可生成任务。
-
KQL:KQL是自研的类SQL语言,提供多种通用函数,并支持自定义函数(类似Spark UDF),用户可以通过KQL查询和处理数据。
Function classify = {
def classify(cbytes, ids):
unique_ids=set(ids)
classify=int.from_bytes(cbytes, byteorder='little', signed=False)
while classify != 0:
tmp = classify & 0xFF
if tmp in unique_ids:
return True
classify = classify >> 8
return False
}
declare ids = [2, 8];
select * from my_table
convert by json outlet by row filter by function@classify(@cf0:types, @ids);
- 离线框架:框架提供包括数据读写、通用转换等功能,用户按照框架规范自定义逻辑并生成离线任务部署包提交平台,平台进行任务调度。
除了以下几种方式,平台也在尝试结合大模型实现基于自然语言的任务生成。实际上,无论采用哪种方式,最后生成的离线任务都是基于离线框架,只是根据更具体的场景提供了更高度的封装而已。
任务生成后,会将任务调度到MapReduce或者FaaS平台执行,不同任务生成方式在调度前的预处理有所不同,比如KQL任务需要先做KQL解析再生成实际任务做调度,而业务通过框架开发的任务比较容易出现各种非预期问题,所以走自动化准入等DevOps流程。任务执行时,会先向计算调度系统提交需要的算子以及期望吞吐,之后不断向网关获取要可用Quota,并结合当前任务实例数、失败率等,自适应调整请求投递速度。
04 总结
当前系统支持搜索出图、视频搜索、图片搜索等十多个业务方向,支持数百个算子的研发和上线,天级数百亿的计算调用,支持全网万亿规模内容特征的例行更新。随着AI大模型时代的到来,带来很多新的场景和挑战,有很多点值得重新思考,后续我们将结合大模型进行更多的探索。
招聘
部门多个职位火热招聘,ANN检索工程师、模型优化工程师、分布式计算研发工程师等,欢迎愿意拥抱挑战,具备优秀分析问题、解决问题能力的人才加入~
招聘邮箱:[email protected]
——END——
推荐阅读
通过Python脚本支持OC代码重构实践(三):数据项使用模块接入数据通路的适配
百度搜索智能化算力调控分配方法
百度搜索深度学习模型业务及优化实践
UBC SDK日志级别重复率优化实践
文生图大型实践:揭秘百度搜索AIGC绘画工具的背后故事!